工具篇-Flink里边的一些实用知识点
1. 自定义Sink写入hbase?
使用的是原生的hbase客户端,可以自己控制每多少条记录刷新一次。遇到了几个坑导致数据写不到hbase里边去:
- 集群hbase版本和客户端版本不一致(版本1和版本2相互之间会有冲突)
- Jar包冲突
例如protobuf-java版本冲突,常见的是两个关键错误,java.io.IOException: java.lang.reflect.InvocationTargetException 和 Caused by: java.lang.NoClassDefFoundError: Could not initialize class org.apache.hadoop.hbase.protobuf.ProtobufUtil。
2. Flink 消费Kafka偏移量
Flink读写Kafka,如果使用Consumer08的话,偏移量会提交Zk,下边这个配置可以写在Conf文件中,提交偏移量的Zk可以直接指定。Consumer09以后版本就不向Zk提交了,Kafka自己会单独搞一个Topic存储消费状态。
1 xxxx08 { 2 bootstrap.servers = "ip:9092" 3 zookeeper.connect = "ip1:2181,ip2/vio" 4 group.id = "group1" 5 auto.commit.enable = true 6 auto.commit.interval.ms = 30000 7 zookeeper.session.timeout.ms = 60000 8 zookeeper.connection.timeout.ms = 30000 9 }
1 final Properties consumerProps = ConfigUtil 2 .getProperties(config, “xxxx08");// 使用自己编写的Util函数读取配置 3 4 final FlinkKafkaConsumer08<String> source = 5 new FlinkKafkaConsumer08<String>(topic, new SimpleStringSchema(), consumerProps);
3. Flink 的日志打印
Flink打印日志的时候,日志打印到哪,日志文件是不是切块,并不是在工程resource下配置文件里指定的!!!而是在flink/conf中指定的,比如我安装的Flink On Yarn模式,只需要在安装的机器上flink/conf文件夹下修改对应的配置文件即可,如下:
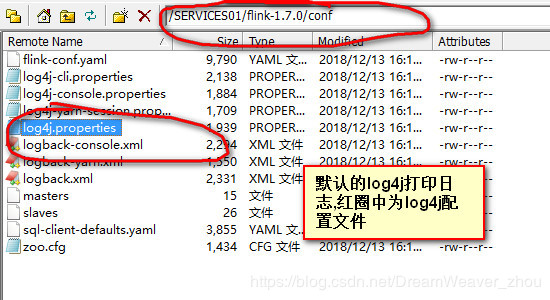
具体可以参考:Flink日志配置
4. Flink 的akka时间超时
这个问题比较常见,碰见过两次,总结下:
首先是集群机器负载比较高,有的机器负载百分之几万都有,在这时候taskmanager、jobmanager就会报akka超时的异常,可以适当增大akka超时时间扛过这段时间;
然后最常见的是程序里调用外部接口,延迟较高,有的是5秒甚至10秒,这种时候akka就会超时
5. Flink 的读HDFS写Kafka
flink读hdfs的时候用了DataSet,自己在中间map里边已经写到kafka里边了,所以不想要sink,但flink要求必须有sink,所以只能加个.output(new DiscardingOutputFormat<>()),这样对程序不会造成影响。
6. 本地测试Flink
本地测试Flink偶尔会报错,记录下:
(1)本地Apache flink集群没有运行,会报下面连接被拒绝的错误,你只需要启动它:./bin/start-cluster.sh
org.apache.flink.shaded.netty4.io.netty.channel.AbstractChannel $ AnnotatedConnectException:拒绝连接:localhost / 127.0.0.1:8081
7. Flink on YARN
8. Flink并行度设置


java.io.IOException: Insufficient number of network buffers: required 4, but only 0 available. The total number of network buffers is currently set to 6472 of 32768 bytes each. You can increase this number by setting the configuration keys 'taskmanager.network.memory.fraction', 'taskmanager.network.memory.min', and 'taskmanager.network.memory.max'.
at org.apache.flink.runtime.io.network.buffer.NetworkBufferPool.createBufferPool(NetworkBufferPool.java:272)
at org.apache.flink.runtime.io.network.buffer.NetworkBufferPool.createBufferPool(NetworkBufferPool.java:257)
at org.apache.flink.runtime.io.network.NetworkEnvironment.setupInputGate(NetworkEnvironment.java:278)
at org.apache.flink.runtime.io.network.NetworkEnvironment.registerTask(NetworkEnvironment.java:224)
at org.apache.flink.runtime.taskmanager.Task.run(Task.java:608)
at java.lang.Thread.run(Thread.java:748)
并行度设置不合理,按报的错设置即可:
source.parallelism = 40
map.parallelism = 40
sink.parallelism = 40
9. Flink常见报错
- java.lang.Exception: Container released on a lost node
异常原因是 Container 运行所在节点在 YARN 集群中被标记为 LOST,该节点上的所有 Container 都将被 YARN RM 主动释放并通知 AM,JobManager 收到此异常后会 Failover 自行恢复(重新申请资源并启动新的 TaskManager),遗留的 TaskManager 进程可在超时后自行退出
- Could not build the program from JAR file.
这个问题的迷惑性较大,很多时候并非指定运行的 JAR 文件问题,而是提交过程中发生了异常,需要根据日志信息进一步排查。
10. Flink消费Kafka单条数据过大起Lag
可以在kafka consumer中设置下列参数:
pro.put("fetch.message.max.bytes", "8388608"); pro.put("max.partition.fetch.bytes", "8388608");
11. Flink CDC
flink实时获取数据库数据,提供的format有两种格式:canal-json和debesium-json。
在国内,用的比较多的是阿里巴巴开源的canal,我们可以使用canal订阅mysql的binlog日志,canal会将mysql库的变更数据组织成它固定的JSON或protobuf 格式发到kafka,以供下游使用。
{ "data": [ { "id": "111", "name": "scooter", "description": "Big 2-wheel scooter", "weight": "5.18" } ], "database": "inventory", "es": 1589373560000, "id": 9, "isDdl": false, "mysqlType": { "id": "INTEGER", "name": "VARCHAR(255)", "description": "VARCHAR(512)", "weight": "FLOAT" }, "old": [ { "weight": "5.15" } ], "pkNames": [ "id" ], "sql": "", "sqlType": { "id": 4, "name": 12, "description": 12, "weight": 7 }, "table": "products", "ts": 1589373560798, "type": "UPDATE" }
在国外,比较有名的类似canal的开源工具有debezium,它的功能较canal更加强大一些,不仅仅支持mysql。还支持其他的数据库的同步,比如 PostgreSQL、Oracle等,目前debezium支持的序列化格式为 JSON 和 Apache Avro 。
{ "before": { "id": 111, "name": "scooter", "description": "Big 2-wheel scooter", "weight": 5.18 }, "after": { "id": 111, "name": "scooter", "description": "Big 2-wheel scooter", "weight": 5.15 }, "source": {...}, "op": "u", "ts_ms": 1589362330904, "transaction": null }
12. Flink SQL中指定时间
首先,DDL时使用proctime AS PROCTIME()来生产一个新的计算列,可当作处理时间来对待。
CREATE TABLE user_address ( userId BIGINT, addressInfo VARCHAR, proctime AS PROCTIME() ) WITH ( 'connector' = 'kafka', 'properties.bootstrap.servers' = 'localhost:9092', 'topic' = 'tp02', 'format' = 'json', 'scan.startup.mode' = 'latest-offset' )
然后,在关联维表时通过for sysytem_time as of来指定时间,表示当左边表的记录与右边表join时,只匹配当前处理时间维表对应的快照数据,即当前最新状态。维表可能不断变化,join行为发生后,维表中的数据发生了变化,则已关联的维表数据不会被同步变化。
select t1.* from ( --临时队列 select *,PROCTIME() as proctime from real_tmp_order_info_from_kafka )t1 left join real_dim_order_info_to_hbase FOR SYSTEM_TIME AS OF t1.proctime t2 --维度关联最新订单状态 on t1.order_id = t2.order_id where t2.order_id is null or t2.order_status='待处理'
最后,事件会有乱序和延时到达的问题,事件时间可以通过WATERMARK语句进行定义。事件时间字段必须是TIMESTAMP(3)类型,即yyyy-MM-dd HH:mm:ss的形式,如果不是这种形式的数据,需要通过定义计算列进行转换。
CREATE TABLE user_behavior ( user_id BIGINT, -- 用户id item_id BIGINT, -- 商品id cat_id BIGINT, -- 品类id action STRING, -- 用户行为 province INT, -- 用户所在的省份 ts BIGINT, -- 用户行为发生的时间戳 proctime as PROCTIME(), -- 通过计算列产生一个处理时间列 eventTime AS TO_TIMESTAMP(FROM_UNIXTIME(ts, 'yyyy-MM-dd HH:mm:ss')), -- 事件时间 WATERMARK FOR eventTime as eventTime - INTERVAL '5' SECOND -- 在eventTime上定义watermark ) WITH ( 'connector.type' = 'kafka', -- 使用 kafka connector 'connector.version' = 'universal', -- kafka 版本,universal 支持 0.11 以上的版本 'connector.topic' = 'user_behavior', -- kafka主题 'connector.startup-mode' = 'earliest-offset', -- 偏移量,从起始 offset 开始读取 'connector.properties.group.id' = 'group1', -- 消费者组 'connector.properties.zookeeper.connect' = 'kms-2:2181,kms-3:2181,kms-4:2181', -- zookeeper 地址 'connector.properties.bootstrap.servers' = 'kms-2:9092,kms-3:9092,kms-4:9092', -- kafka broker 地址 'format.type' = 'json' -- 数据源格式为 json );

 浙公网安备 33010602011771号
浙公网安备 33010602011771号