

工具理论篇-Spark知识点

1. Spark与Scala的版本问题
- 官网会给出

- Maven Repository上可以查到
2. RDD(Resilent Distributed DataSet)
- 一组Partition,每个分片都被一个计算任务处理,未指定的话默认是程序分配的CPU core的数目
- 计算每个Paritition的函数
- RDD之间的依赖关系
- 一个Partitioner(分区器)
- 一个列表(存取每个Partition的优先位置)
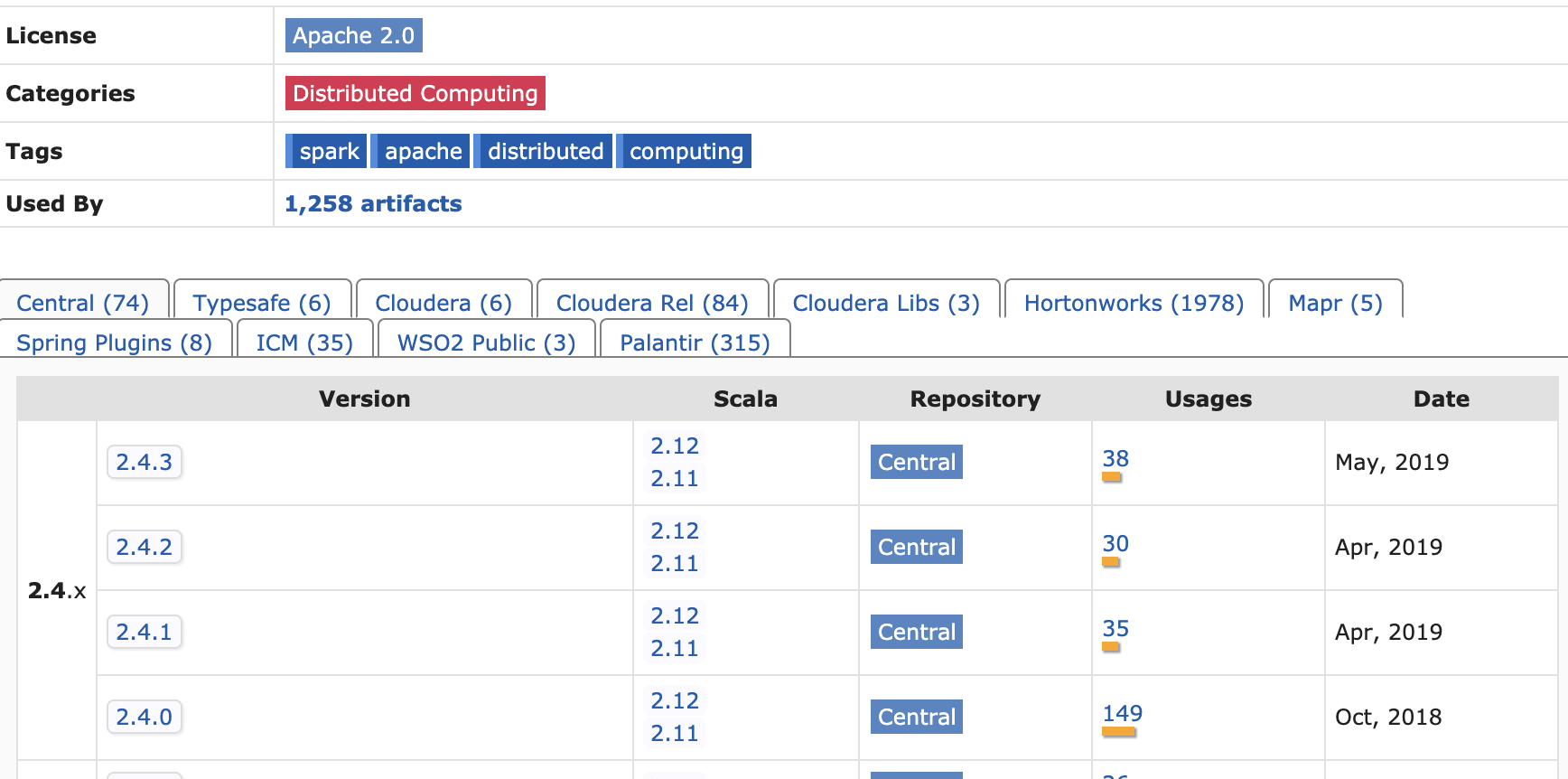
3. 窄依赖和宽依赖
RDD之间的依赖关系有窄依赖和宽依赖,窄依赖指一个父RDD的分区只被一个子RDD的分区使用,比如map, filter, union, join(父RDD是hash-partitioned ), mapPartitions, mapValues;
宽依赖指一个父RDD的分区可能被多个子RDD的分区使用,比如groupByKey, join(父RDD不是hash-partitioned ), partitionBy等,具体如官网图所示
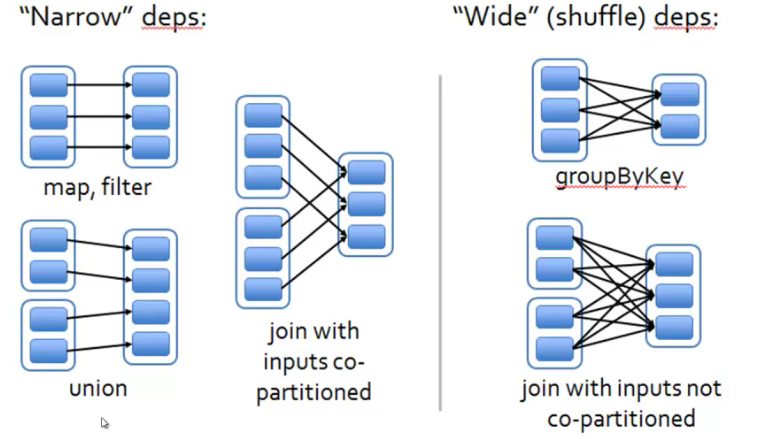
对比:
1.窄依赖的每个父RDD的分区只会传入到一个子RDD分区中,每个分区里的数据都被加载到机器的内存里,依次调用 map, filter函数到分区,形成流水线操作,一个父RDD的分区传入到不同的子RDD分区中,中间可能有多个节点之间的数据传输,增加了网络和磁盘IO;
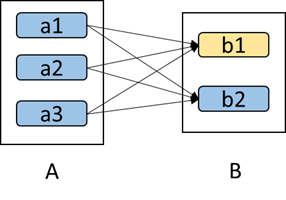
2.当RDD分区丢失时,spark会进行重算:
对于窄依赖,只需重算子RDD分区对应的父RDD分区即可,所以这个重算对数据的利用率是100%的,对于宽依赖,重算的父RDD分区对应多个子RDD分区,父RDD重算会有多余的计算,如下图,b1丢失重算,b2的数据就是冗余计算的。
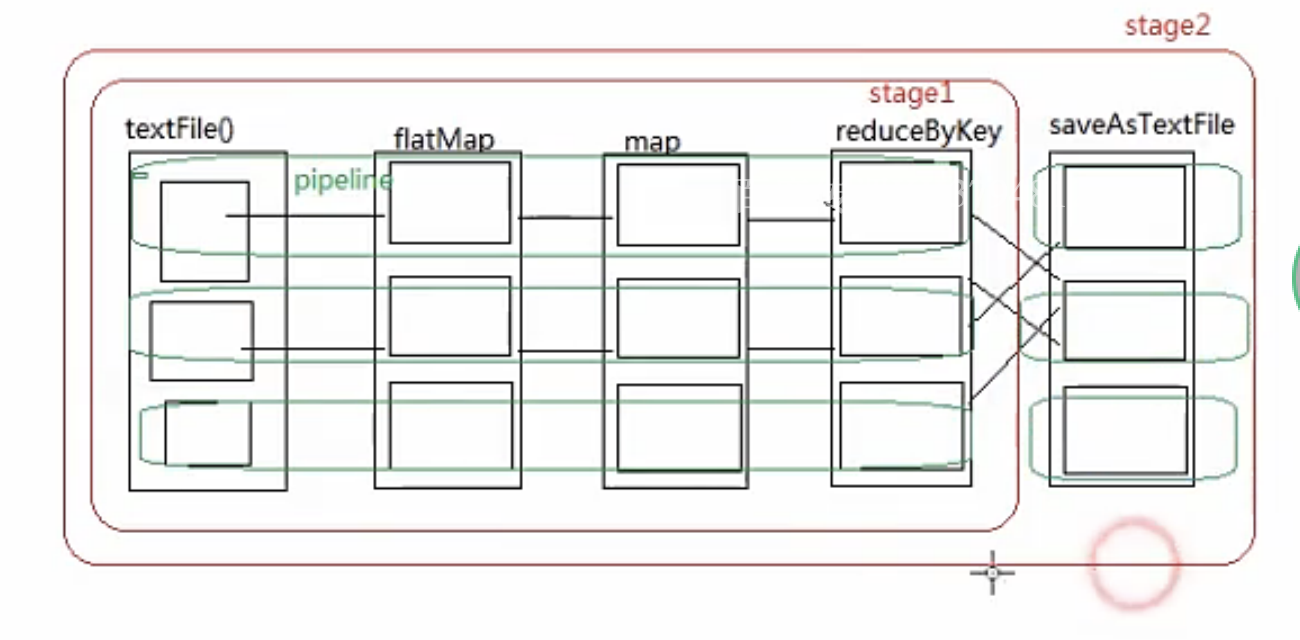
4. 血统和Stage
血统:记录RDD的元数据和转换行为,便于恢复丢失的分区;
Stage:区分宽窄依赖, 为了生成任务。
5. RDD的获取方式
Spark Core为我们提供了三种创建RDD的方式,包括:
- 使用程序中的集合创建RDD,应用场景:自己使用构造的集合测试数据;
Spark会调用SparkContext中的parallelize()方法,将集合中的数据拷贝到集群上去,形成一个分布式的数据集合,也就是一个RDD。
1 val array = Array(1,2,3,4,5) 2 val rdd = sc.parallelize(array) 3 val sum = rdd.reduce(_ + _)
在调用parallelize()方法时,可以指定将集合切分成多少个partition,Spark会为每一个partition运行一个task来进行处理。
1 val rdd = sc.parallelize(array,10)
Spark官方的建议是,为集群中的每个CPU创建2-4个partition。Spark默认会根据集群的情况来设置partition的数量。
- 使用本地文件创建RDD,应用场景:在本地临时性地处理一些存储了大量数据的文件;
- 使用HDFS文件创建RDD,应用场景:可以针对HDFS上存储的大数据,进行离线批处理操作,最常用;
Spark是支持使用任何Hadoop支持的存储系统上的文件创建RDD的,比如说HDFS、Cassandra、HBase以及本地文件。通过调用SparkContext的textFile()方法,可以针对本地文件或HDFS文件创建RDD。
1 // textFile()方法中,输入本地文件路径或是HDFS路径 2 // HDFS:hdfs://spark1:9000/data.txt 3 // local:/home/hadoop/data.txt 4 val rdd = sc.textFile(“/home/hadoop/data.txt”) 5 val wordCount = rdd.map(line => line.length).reduce(_ + _)
Spark默认会为hdfs文件的每一个block创建一个partition,但是也可以通过textFile()的第二个参数手动设置分区数量,只能比block数量多,不能比block数量少。
该部分主要参考:Rdd的几种创建方式
6. DataFrame
DataFrame是一种以RDD为基础的分布式数据集,类似于传统数据库中的二位表格。DataFrame使用Sql的话必须先注册成一张表,例如:
1 df.registerTempTable("表名") 2 sqlContext.sql("Sql语句")
RDD转换DataFrame有两种方法:
- rdd.toDF

- 通过Schema

7. DStream
DStream由以下三部分组成:
- 对其他流的依赖;
- 产生RDD的时间间隔;
- 每个时间间隔产生RDD的函数。
8. groupByKey 、aggregateByKey、reduceByKey的区别
官方建议尽量使用aggregateByKey和reduceByKey,减少计算量和网络传输(不需要所有键值对都被传输)。
groupByKey()是对RDD中的所有数据做shuffle,根据不同的Key映射到不同的partition中再进行aggregate。
aggregateByKey()是先对每个partition中的数据根据不同的Key进行aggregate,然后将结果shuffle,完成各个partition之间的aggregate。因此,和groupByKey()相比,运算量小了很多。
distinct()也是对RDD中的所有数据做shuffle进行aggregate后再去重。
reduceByKey()也是先在单台机器中计算,再将结果进行shuffle,减小运算量。
参考下https://blog.csdn.net/faan0966/article/details/80513260,举个例子:
有一系列元组(用户ID,用户访问的站点),要对每个用户访问的站点去重,groupByKey运算量较大,可选方案有reduceByKey,aggregateByKey。
1 val mapedUserAccess = userAccesses.map(userSite => (userSite._1, Set(userSite._2))) 2 val distinctSite = mapedUserAccess.reduceByKey(_++_)
reduceByKey的问题是,RDD的每个值都创建一个Set,如果处理一个巨大的RDD,这些对象将大量吞噬内存,并对垃圾回收造成压力。
1 val zeroValue = collecyion.mutable.set[String]() 2 val aggregated = userAccesses.aggregateByKey(zeroValue)((set,v) => set += v, (setOne, setTwo) => setOne ++= setTwo)
aggregateByKey可以解决内存问题,它有三个参数:
- 零值(zero):即聚合的初始值
- 函数f:(U, V):把值V合并到数据结构U, 该函数在分区内合并值时使用
- 函数 g:(U, V):合并两个数据结构U,在分区间合并值时调用此函数。
9. Cluster和Client模式
cluster模式:Driver程序在YARN上运行,应用的运行结果不能在客户端显示,所以最好将运行结果保存在外部介质(如HDFS、Redis、Mysql)而非stdout输出的应用程序,客户端的终端显示的仅是YARN上job的简单运行情况;
client模式:Driver运行在Client上,应用程序运行结果会在客户端显示,所以适合运行结果有输出的应用程序(如spark-shell)
10. Spark开发环境搭建
主要是:
- scala插件的安装
- 全局JDK和Library的设置
- 配置全局的Scala SDK
11. Spark内存管理
这块完全照抄Spark1.6内存管理,只是怕丢了。
从1.6.0版本开始,Spark内存管理模型发生了变化。旧的内存管理模型由StaticMemoryManager类实现,现在称为“legacy(遗留)”。默认情况下,“Legacy”模式被禁用,这意味着在Spark 1.5.x和1.6.0上运行相同的代码会导致不同的行为。为了兼容,您可以使用spark.memory.useLegacyMode参数启用“旧”内存模型。
1.6.0及以后版本,使用的统一内存管理器,由UnifiedMemoryManager实现,先看一张图。
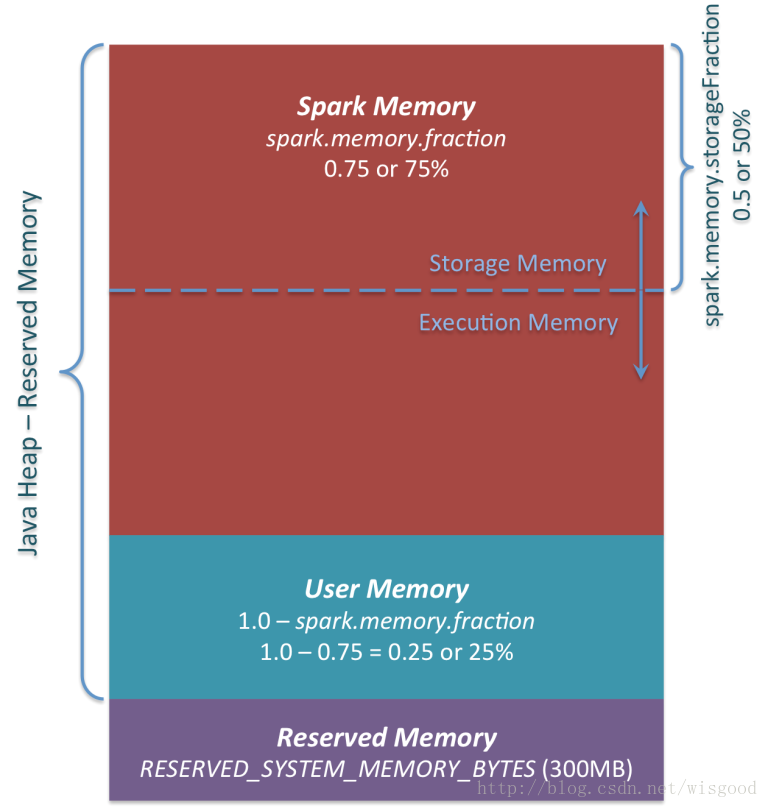
图中主要有3个区域,分别用3种不同颜色表示。
1、Reserved Memory
系统保留内存。从Spark 1.6.0起,它的值默认为300MB(被硬编码到spark代码中,代码private val RESERVED_SYSTEM_MEMORY_BYTES = 300 * 1024 * 1024) ),这意味着这个300MB的RAM不参与Spark内存区域大小的计算。它的值可以通过参数spark.testing.reservedMemory来调整,但不推荐使用,从参数名字可以看到这个参数仅供测试使用,不建议在生产环境中使用。虽然是保留内存,但并不意味这这部分内存没有使用,实际上,它会存储大量的Spark内部对象。而且,executor在执行时,必须保证至少有1.5 *保留内存= 450MB大小的堆,否则程序将失败,并抛出一个异常“Please use a larger heap size”。参考代码:
1 val minSystemMemory = reservedMemory * 1.5 2 if (systemMemory < minSystemMemory) { 3 throw new IllegalArgumentException(s"System memory $systemMemory must " + 4 s"be at least $minSystemMemory. Please use a larger heap size.") 5 }
2、User Memory
这是在Spark Memory分配后仍然保留的内存,使用方式完全取决于你。你可以存储RDD转换中用到的数据结构。例如,您可以在mapPartitions算子时,维护一个HashMap(这将消耗所谓的用户内存)。在Spark 1.6.0中,此内存池的大小可以计算为(“executor-memory” - “保留内存”)(1.0 - spark.memory.fraction),默认值等于(“Java Heap”) - 300MB ) 0.25。例如,使用4GB堆,您将拥有949MB的用户内存。在这部分内存中,将哪些东西存储在内存中以及怎么存,完全取决你。Spark也完全不会关心你在那里做什么,以及是否保证容量不超限。如果超限,可能会导致程序OOM错误。
3、Spark Memory
这是由Spark管理的内存池。它的大小可以计算为(“executor-memory” - “保留内存”)* spark.memory.fraction,并使用Spark 1.6.0默认值给我们(“executor-memory” - 300MB)* 0.75。例如,使用4GB executor-memory,这个池的大小将是2847MB。
这个整个池分为2个区域 -Storage Memory(存储内存) 和Execution Memory(执行内存) ,它们之间的边界由spark.memory.storageFraction参数设置,默认为0.5。
UnifiedMemoryManager内存管理方案的优点是,该边界不是静态的。在某部分内存有压力的情况下,边界将被移动,即一个区域将通过从另一个借用空间而增长。稍后会讨论“移动”这个边界,现在让我们来关注这个内存如何被使用。
3.1 Storage Memory
这一块内存用作Spark缓存数据(cache,persist)和序列化数据”unroll”临时空间。另外所有的”broadcast”广播变量都以缓存块存在这里。其实并不需要内存中有足够的空间来存unrolled块- 如果没有足够的内存放下所有的unrolled分区,如果设置的持久化level允许的话,Spark将会把它直接放进磁盘。所有的broadcast变量默认用MEMORY_AND_DISK持久化level缓存。
3.2 Execution Memory
这一块内存是用来存储Spark task执行需要的对象。比如用来存储Map阶段的shuffle临时buffer,此外还用来存储hash合并用到的hash table。当没有足够可用内存时,这块内存同样可以溢写到磁盘,但是这块内存不能被其他线程(tasks)强行剥夺(该内存相对于Storage Memory更重要。Storage Memory内存如果被剥夺,可以通过重算来获得数据。而 Execution Memory一旦剥夺,可能会引起程序失败)。
Spark很大一部分内存用于storage和execution,即存储和执行任务。execution memory指的是在shuffle,join,sorts,aggregation操作中使用的内存,storage memory指的是用于整个集群缓存数据和传播中间数据的内存。spark中storage和execution分享一个统一的区域(M),当没有execution memory被使用,storage可以占用全部可用内存,反之亦然。storage占用execution memory时且有必要时execution可以驱逐storage,直到storage memory使用量低于一个阈值(R)。也就是说R描述了一个小于M的缓存区域,绝不会被驱逐。execution占用storage memory时因为实现复杂所以storage不会驱逐execution。
还有一个问题:
Spark管理页面中Storage Memory是如何计算的呢?参考Spark1.6内存管理(二) 实例讲解。
12. Spark读取Redis
可以自定义source、或者one connection/partition方式或者Spark-Redis方式。老大整理的,我在这里记录下,


1 <?xml version="1.0" encoding="UTF-8"?> 2 <project xmlns="http://maven.apache.org/POM/4.0.0" 3 xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" 4 xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> 5 <modelVersion>4.0.0</modelVersion> 6 7 <groupId>com.w3sun.data</groupId> 8 <artifactId>spark-redis</artifactId> 9 <version>1.0-SNAPSHOT</version> 10 11 <properties> 12 <maven.compiler.source>1.8</maven.compiler.source> 13 <maven.compiler.target>1.8</maven.compiler.target> 14 <spark.version>2.2.0</spark.version> 15 <type.safe.version>1.3.0</type.safe.version> 16 <joda.time.version>2.9.4</joda.time.version> 17 <fast.json.version>1.2.10</fast.json.version> 18 <spark.redis.version>0.3.2</spark.redis.version> 19 <encoding>UTF-8</encoding> 20 </properties> 21 22 23 <repositories> 24 <!-- list of RedisLabs repositories --> 25 <repository> 26 <id>SparkPackagesRepo</id> 27 <url>http://dl.bintray.com/spark-packages/maven</url> 28 </repository> 29 </repositories> 30 31 <dependencies> 32 <dependency> 33 <groupId>org.apache.spark</groupId> 34 <artifactId>spark-core_2.11</artifactId> 35 <version>${spark.version}</version> 36 </dependency> 37 <dependency> 38 <groupId>org.apache.spark</groupId> 39 <artifactId>spark-streaming_2.11</artifactId> 40 <version>${spark.version}</version> 41 </dependency> 42 43 <!--Configuration for configuration reader--> 44 <dependency> 45 <groupId>com.typesafe</groupId> 46 <artifactId>config</artifactId> 47 <version>${type.safe.version}</version> 48 </dependency> 49 50 <!--Configuration for Joda time to generate timestamp--> 51 <dependency> 52 <groupId>joda-time</groupId> 53 <artifactId>joda-time</artifactId> 54 <version>${joda.time.version}</version> 55 </dependency> 56 57 <dependency> 58 <groupId>com.alibaba</groupId> 59 <artifactId>fastjson</artifactId> 60 <version>${fast.json.version}</version> 61 </dependency> 62 63 <!--ConfigConfiguration for Spark && Redis RDD generation transformation --> 64 <dependency> 65 <groupId>RedisLabs</groupId> 66 <artifactId>spark-redis</artifactId> 67 <version>${spark.redis.version}</version> 68 </dependency> 69 </dependencies> 70 71 <build> 72 <pluginManagement> 73 <plugins> 74 <plugin> 75 <groupId>net.alchim31.maven</groupId> 76 <artifactId>scala-maven-plugin</artifactId> 77 <version>3.2.2</version> 78 </plugin> 79 <plugin> 80 <groupId>org.apache.maven.plugins</groupId> 81 <artifactId>maven-compiler-plugin</artifactId> 82 <version>3.5.1</version> 83 </plugin> 84 </plugins> 85 </pluginManagement> 86 <plugins> 87 <plugin> 88 <groupId>net.alchim31.maven</groupId> 89 <artifactId>scala-maven-plugin</artifactId> 90 <executions> 91 <execution> 92 <id>scala-compile-first</id> 93 <phase>process-resources</phase> 94 <goals> 95 <goal>add-source</goal> 96 <goal>compile</goal> 97 </goals> 98 </execution> 99 <execution> 100 <id>scala-test-compile</id> 101 <phase>process-test-resources</phase> 102 <goals> 103 <goal>testCompile</goal> 104 </goals> 105 </execution> 106 </executions> 107 </plugin> 108 109 <plugin> 110 <groupId>org.apache.maven.plugins</groupId> 111 <artifactId>maven-compiler-plugin</artifactId> 112 <executions> 113 <execution> 114 <phase>compile</phase> 115 <goals> 116 <goal>compile</goal> 117 </goals> 118 </execution> 119 </executions> 120 </plugin> 121 122 <plugin> 123 <groupId>org.apache.maven.plugins</groupId> 124 <artifactId>maven-shade-plugin</artifactId> 125 <version>2.4.3</version> 126 <executions> 127 <execution> 128 <phase>package</phase> 129 <goals> 130 <goal>shade</goal> 131 </goals> 132 <configuration> 133 <filters> 134 <filter> 135 <artifact>*:*</artifact> 136 <excludes> 137 <exclude>META-INF/*.SF</exclude> 138 <exclude>META-INF/*.DSA</exclude> 139 <exclude>META-INF/*.RSA</exclude> 140 </excludes> 141 </filter> 142 </filters> 143 </configuration> 144 </execution> 145 </executions> 146 </plugin> 147 </plugins> 148 </build> 149 </project>
1 import java.util 2 3 import com.redislabs.provider.redis.rdd.RedisKeysRDD 4 import com.typesafe.config.{ConfigFactory, ConfigValue} 5 import org.apache.log4j.{Level, Logger} 6 import org.apache.spark.{SparkConf, SparkContext} 7 8 9 object App { 10 //调整日志输出级别 11 Logger.getLogger("org.apache.spark").setLevel(Level.WARN) 12 def main(args: Array[String]): Unit = { 13 val sparkConf = new SparkConf() 14 .setMaster("local[*]") 15 .setAppName(s"${this.getClass.getSimpleName}") 16 17 //设置Redis服务器信息,导入操作Redis隐式转换 18 initRedis(sparkConf) 19 import com.redislabs.provider.redis._ 20 val sparkContext = new SparkContext(sparkConf) 21 //根据指定pattern获取所有符合条件的Key所对应的RDD 22 val keysRDD: RedisKeysRDD = sparkContext.fromRedisKeyPattern("1002010011540185*", 4) 23 keysRDD.foreach(println) 24 sparkContext.stop() 25 } 26 27 private def initRedis(sparkConf: SparkConf): Unit = { 28 import scala.collection.JavaConverters._ 29 ConfigFactory.load() 30 .entrySet().asScala 31 .foreach { 32 entry: util.Map.Entry[String, ConfigValue] => 33 sparkConf.set(entry.getKey, entry.getValue.unwrapped().toString) 34 } 35 } 36 }
Redis相关的配置信息存储在文件中,通过TypeSafe读取:
1 redis.host = xx.xxx.xx.x 2 redis.db = 0 3 redis.port = 6399 4 redis.max.total = 500 5 redis.pool.maxidle = 500 6 redis.pool.testonborrow = true 7 redis.pool.testonreturn = true 8 redis.pool.maxwaitmillis = 1000 9 redis.protocol.timeout = 48000
13. Spark Metric Reporter和Meric API
14. Spark读取文件
spark sql 读取文件,文件中存在 date 和 Date 字段,下面的配置默认 False 解析查询不区分大小写,改为 True 之后就可以区分大小写,不报错了
spark.conf.set("spark.sql.caseSensitive", "true")
15. Spark导入Mysql增加自增主键id
spark DataFrame写入mysql的时候添加一个自增主键id有两种方法,窗口函数和zipWithIndex算子,具体参见:链接
16. --files理解
spark-submit --files可以用来加载外部资源文件,比如加载log4j.properties:
--files config-topic-read-first-day-test.properties,log4j.properties
17. 修改日志级别
spark修改默认log4j.properties,比如
spark-submit \ --files log4j-driver.properties,log4j-executor.properties \ --driver-java-options "-Dlog4j.configuration=log4j-driver.properties" \ --conf spark.executor.extraJavaOptions="-Dlog4j.configuration=log4j-executor.properties" \
# Set everything to be logged to the console log4j.rootCategory=FATAL, console log4j.appender.console=org.apache.log4j.ConsoleAppender log4j.appender.console.target=System.err log4j.appender.console.layout=org.apache.log4j.PatternLayout log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{1}: %m%n # Set the default spark-shell log level to WARN. When running the spark-shell, the # log level for this class is used to overwrite the root logger's log level, so that # the user can have different defaults for the shell and regular Spark apps. log4j.logger.org.apache.spark.repl.Main=FATAL # Settings to quiet third party logs that are too verbose log4j.logger.org.spark_project.jetty=FATAL log4j.logger.org.spark_project.jetty.util.component.AbstractLifeCycle=FATAL log4j.logger.org.apache.spark.repl.SparkIMain$exprTyper=FATAL log4j.logger.org.apache.spark.repl.SparkILoop$SparkILoopInterpreter=FATAL log4j.logger.org.apache.parquet=FATAL log4j.logger.parquet=FATAL # SPARK-9183: Settings to avoid annoying messages when looking up nonexistent UDFs in SparkSQL with Hive support log4j.logger.org.apache.hadoop.hive.metastore.RetryingHMSHandler=FATAL log4j.logger.org.apache.hadoop.hive.ql.exec.FunctionRegistry=FATAL
具体参见:https://www.cnblogs.com/jiangxiaoxian/p/11437414.html
18. 分组TopN
- 第一种方法基于Spark SQL的开窗函数实现,
- 第二种方法基于原生的RDD接口实现。
比如目标:取出每个科目下成绩排名前三的学生,先我们构造一份班级的成绩数据,这份数据有三列组成,第一列是考试科目category,第二列是学生的名字name,第三列是学生的成绩score。如下:
val df = spark.createDataFrame(Seq( ("A", "Tom", 78), ("B", "James", 47), ("A", "Jim", 43), ("C", "James", 89), ("A", "Lee", 93), ("C", "Jim", 65), ("A", "James", 10), ("C", "Lee", 39), ("B", "Tom", 99), ("C", "Tom", 53), ("B", "Lee", 100), ("B", "Jim", 100) )).toDF("category", "name", "score") df.show(false)
第一种方法基于Spark SQL的开窗函数
val N = 3 val window = Window.partitionBy(col("category")).orderBy(col("score").desc) val top3DF = df.withColumn("topn", row_number().over(window)).where(col("topn") <= N) top3DF.show(false)
也可以用sql查询的方式
df.createOrReplaceTempView("grade") val sql = "select category, name, score from (select category, name, score, row_number() over (partition by category order by score desc ) rank from grade) g where g.rank <= 3".stripMargin val top3DFBySQL = spark.sql(sql) top3DFBySQL.show(false)
第二种方法基于原生的RDD接口实现
主要有以下三个步骤:
- 将数据按指定的标准分组。比如在本例中需要按“category”分组
- 对每个分组中的元素进行排序,然后取TopN个元素
- 将以上数据Flat展开,恢复为原有格式
// 使用RDD取Top // step 1: 分组 val groupRDD = df.rdd.map(x => (x.getString(0), (x.getString(1), x.getInt(2)))).groupByKey() // step 2: 排序并取TopN val N = 3 val sortedRDD = groupRDD.map(x => { val rawRows = x._2.toBuffer val sortedRows = rawRows.sortBy(_._2.asInstanceOf[Integer]) // 取TopN元素 if (sortedRows.size > N) { sortedRows.remove(0, (sortedRows.length - N)) } (x._1, sortedRows.toIterator) }) // step 3: 展开 val flatRDD = sortedRDD.flatMap(x => { val y = x._2 for (w <- y) yield (x._1, w._1, w._2) }) flatRDD.toDF("category", "name", "score").show(false)
+--------+-----+-----+ |category|name |score| +--------+-----+-----+ |B |Lee |100 | |B |Jim |100 | |B |Tom |99 | |C |James|89 | |C |Jim |65 | |C |Tom |53 | |A |Lee |93 | |A |Tom |78 | |A |Jim |43 | +--------+-----+-----+
19. Spark算子
- na.fill
两个数据表如A,B JOIN的时候,其结果往往会出现NULL值的出现。Spark为此提供了一个高级操作,就是:na.fill的函数可实现对NULL值的填充。
