工具篇-Spark-Streaming获取kafka数据的两种方式(转载)
转载自:https://blog.csdn.net/weixin_41615494/article/details/7952173
一、基于Receiver的方式
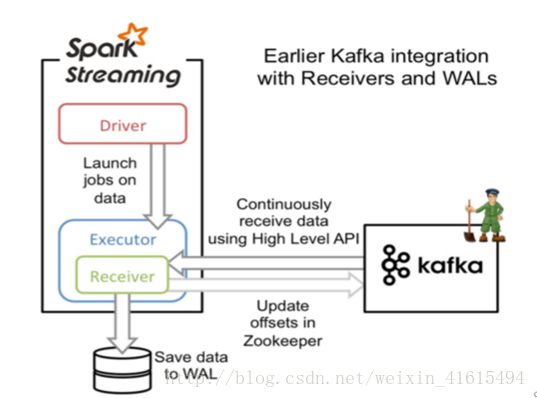
原理
Receiver从Kafka中获取的数据存储在Spark Executor的内存中,然后Spark Streaming启动的job会去处理那些数据,如果突然数据暴增,大量batch堆积,很容易出现内存溢出的问题。
在默认的配置下,这种方式可能会因为底层失败而丢失数据。如果要让数据零丢失,就必须启用Spark Streaming的预写日志机制(Write Ahead Log,WAL),该机制会同步地将接收到的Kafka数据写入分布式文件系统(比如HDFS)上的预写日志中,即使底层节点出现了失败,也可以使用预写日志中的数据进行恢复。
要点
1. Kafka中Topic的Partition与Spark中RDD的Partition没有关系。所以,在KafkaUtils.createStream()中,提高partition的数量只会增加一个Receiver中读取Partition线程的数量,不会增加Spark处理数据的并行度。可以创建多个Kafka输入DStream,使用不同的Consumer Group和Topic,来通过多个Receiver并行接收数据。
2. 如果基于容错的文件系统,比如HDFS,启用了预写日志机制,接收到的数据都会被复制一份到预写日志中。此时在KafkaUtils.createStream()中,设置的持久化级别是StorageLevel.MEMORY_AND_DISK_SER。
这部分代码虽然整理了但没测试,代码如下:
1 import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream} 2 import org.apache.spark.streaming.kafka.KafkaUtils 3 import org.apache.spark.streaming.{Seconds, StreamingContext} 4 import org.apache.spark.{SparkConf, SparkContext} 5 6 import scala.collection.immutable 7 8 9 object KafkaReceiver { 10 11 def main(args: Array[String]): Unit = { 12 //1、创建sparkConf 13 val sparkConf = new SparkConf().setMaster("local[2]").setAppName("SparkStreamingKafka_Receiver").set("spark.streaming.receiver.writeAheadLog.enable","true") 14 // 开启wal预写日志,保存数据源的可靠性 15 16 val sc = new SparkContext(sparkConf) 17 sc.setLogLevel("WARN") 18 //3、创建StreamingContext 19 val ssc = new StreamingContext(sc, Seconds(5)) 20 21 //设置checkpoint 22 ssc.checkpoint("./Kafka_Receiver_test") 23 //4、定义zk地址 24 val zkQuorum="127.0.0.1:2181" 25 //5、定义消费者组 26 val groupId="spark_receiver_test" 27 //6、定义topic相关信息 Map[String, Int] 28 // 这里的value并不是topic分区数,它表示的topic中每一个分区被N个线程消费 29 val topics=Map("druid-monitor-data" -> 2) 30 31 //7、通过KafkaUtils.createStream对接kafka 32 //这个时候相当于同时开启3个receiver接受数据 33 val receiverDstream: immutable.IndexedSeq[ReceiverInputDStream[(String, String)]] = (1 to 3).map( 34 x => { 35 val stream: ReceiverInputDStream[(String, String)] = KafkaUtils.createStream(ssc, zkQuorum, groupId, topics) 36 stream 37 } 38 ) 39 //使用ssc.union方法合并所有的receiver中的数据 40 val unionDStream: DStream[(String, String)] = ssc.union(receiverDstream) 41 //8、获取topic中的数据 42 val topicData: DStream[String] = unionDStream.map(_._2) 43 //9、切分每一行,每个单词计为1 44 val wordAndOne: DStream[String] = topicData.flatMap(_.split(" ")) 45 //10、打印输出 46 wordAndOne.print() 47 48 //开启计算 49 ssc.start() 50 ssc.awaitTermination() 51 } 52 }
pom文件部分内容为:
1 <properties> 2 <spark.version>2.4.2</spark.version> 3 <scala.version>2.11</scala.version> 4 </properties> 5 6 7 <!--<repositories> 8 <repository> 9 <id>SparkPackagesRepo</id> 10 <url>http://dl.bintray.com/spark-packages/maven</url> 11 </repository> 12 </repositories>--> 13 14 15 <dependencies> 16 <dependency> 17 <groupId>org.apache.spark</groupId> 18 <artifactId>spark-core_${scala.version}</artifactId> 19 <version>${spark.version}</version> 20 </dependency> 21 <dependency> 22 <groupId>org.apache.spark</groupId> 23 <artifactId>spark-streaming_${scala.version}</artifactId> 24 <version>${spark.version}</version> 25 </dependency> 26 <dependency> 27 <groupId>org.apache.spark</groupId> 28 <artifactId>spark-sql_${scala.version}</artifactId> 29 <version>${spark.version}</version> 30 </dependency> 31 <dependency> 32 <groupId>org.apache.spark</groupId> 33 <artifactId>spark-hive_${scala.version}</artifactId> 34 <version>${spark.version}</version> 35 </dependency> 36 <dependency> 37 <groupId>org.apache.spark</groupId> 38 <artifactId>spark-mllib_${scala.version}</artifactId> 39 <version>${spark.version}</version> 40 </dependency> 41 <!--<dependency> 42 <groupId>org.apache.spark</groupId> 43 <artifactId>spark-streaming-kafka-0-10_${scala.version}</artifactId> 44 <version>${spark.version}</version> 45 </dependency>--> 46 <dependency> 47 <groupId>org.apache.spark</groupId> 48 <artifactId>spark-streaming-kafka-0-8_${scala.version}</artifactId> 49 <version>${spark.version}</version> 50 </dependency> 51 <dependency> 52 <groupId>com.alibaba</groupId> 53 <artifactId>fastjson</artifactId> 54 <version>1.2.47</version> 55 </dependency> 56 57 </dependencies> 58 59 <build> 60 <plugins> 61 62 <plugin> 63 <groupId>org.scala-tools</groupId> 64 <artifactId>maven-scala-plugin</artifactId> 65 <version>2.15.2</version> 66 <executions> 67 <execution> 68 <goals> 69 <goal>compile</goal> 70 <goal>testCompile</goal> 71 </goals> 72 </execution> 73 </executions> 74 </plugin> 75 76 <plugin> 77 <artifactId>maven-compiler-plugin</artifactId> 78 <version>3.6.0</version> 79 <configuration> 80 <source>1.8</source> 81 <target>1.8</target> 82 </configuration> 83 </plugin> 84 85 <plugin> 86 <groupId>org.apache.maven.plugins</groupId> 87 <artifactId>maven-surefire-plugin</artifactId> 88 <version>2.19</version> 89 <configuration> 90 <skip>true</skip> 91 </configuration> 92 </plugin> 93 </plugins> 94 </build>
二、基于Direct的方式
原理
该方式在Spark 1.3中引入,来确保更加健壮的机制。这种方式会周期性地查询Kafka,获取每个Topic+Partition的最新的Offset,从而定义每个batch的offset的范围。当处理数据的job启动时,就会使用Kafka的简单consumer api来获取Kafka指定offset范围的数据。
优点
1. 简化并行读取:在Kafka Partition和RDD Partition之间,有一个一对一的映射关系,所以如果要读取多个partition,不需要创建多个输入DStream然后对它们进行Union操作,Spark会创建跟Kafka Partition一样多的RDD Partition,并且会并行从Kafka中读取数据。
2. 高性能:如果要保证零数据丢失,在基于Receiver的方式中,需要开启WAL机制,这种方式数据实际上被复制了两份效率低下,Kafka自己本身就有高可靠的机制,会对数据复制一份。而基于Direct的方式,不依赖Receiver,不需要开启WAL机制,只要Kafka中作了数据的复制,就可以通过Kafka的副本进行恢复。
对比(在实际生产环境中大都用Direct方式):
基于Receiver的方式,使用Kafka的高阶API在ZooKeeper中保存消费过的offset的,这是消费Kafka数据的传统方式。这种方式配合WAL机制可以保证数据零丢失的高可靠性,但是却无法保证数据被处理一次且仅一次,可能会重复处理。因为Spark和ZooKeeper之间可能是不同步的。
基于Direct的方式,使用Kafka的简单API,Spark Streaming自己就负责追踪消费的Offset,并保存在Checkpoint中,Spark自己一定是同步的,因此可以保证数据是消费一次且仅消费一次。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号