理论篇-Java中一些零碎的知识点

1. Java中length,length方法,size方法区别
2. isEmpty方法
3. Queue中 add/offer,element/peek,remove/poll方法
4. Set用法
5. static代码块、构造代码块和构造方法
- static代码块:类加载时就会调用,仅执行一次,没有名字、参数和返回值。
- 构造代码块:在对象初始化时执行,有几个对象执行几次,晚于static代码块,早于构造函数,没有名字、参数和返回值。
- 构造方法:在对象初始化时执行,有几个对象执行几次,没有返回值。
1 public class Constructor { 2 3 public static void main(String[] args) { 4 System.out.println("创建第一个对象:"); 5 Test test1 = new Test(); 6 } 7 } 8 9 class Test { 10 // 静态代码块1 11 static { 12 System.out.println("静态代码块1"); 13 } 14 // 构造代码块1: 15 { 16 System.out.println("构造代码块1"); 17 } 18 19 // 构造函数1 20 public Test() { 21 System.out.println("无参构造函数"); 22 } 23 24 }
运行结果:
1 创建第一个对象: 2 静态代码块1 3 构造代码块1 4 无参构造函数
6. 重写equals和hashcode方法
7. 序列化与反序列化
8. transient关键字
9. 枚举enum
- 是什么:枚举是一个特殊的类,有实例字段、构造器和方法, 因此它是可拓展的。
- 何时用:定义固定常量集合的时候,等价于public static final 变量名,如下所示:
1 public enum Index { 2 ZERO(0), 3 ONE(1), 4 TWO(2); 5 6 private int index; 7 8 Index(int index) { 9 this.index = index; 10 } 11 12 public int getIndex() { 13 return index; 14 } 15 }
10. ThreadLocal局部变量实现线程同步
11. 原子类Automic
12. 线程池
- 每次新建对象性能差。
- 线程缺乏统一的管理,可能无限制的新建线程,相互竞争,可能占用过多的资源导致OOM。
- 缺乏更多功能,如定时执行、定期执行、线程中断。
- 重用存在的线程,减少对象创建、消亡的开销,提高响应速度。
- 可有效控制最大并发线程数,降低资源消耗,同时避免过多资源竞争。
- 提高线程的可管理性,可以进行统一的分配,调优和监控。
- 提供定时执行、定期执行、单线程、并发数控制等功能。
- newFixedThreadPool和newSingleThreadExecutor:
- newCachedThreadPool和newScheduledThreadPool:
1 public class ScheduledThreadPoolTest { 2 public static void main(String[] args) throws InterruptedException { 3 // 创建大小为5的线程池 4 ScheduledExecutorService scheduledThreadPool = Executors.newScheduledThreadPool(5,new BasicThreadFactory.Builder().namingPattern("schedule-pool-%d").daemon(false).build()); 5 6 for (int i = 0; i < 3; i++) { 7 Task worker = new Task("task-" + i); 8 // 只执行一次 9 // scheduledThreadPool.schedule(worker, 5, TimeUnit.SECONDS); 10 // 周期性执行,每5秒执行一次 11 scheduledThreadPool.scheduleAtFixedRate(worker, 0,5, TimeUnit.SECONDS); 12 } 13 Thread.sleep(10000); 14 System.out.println("Shutting down executor..."); 15 // 关闭线程池 16 scheduledThreadPool.shutdown(); 17 boolean isDone; 18 // 等待线程池终止 19 do { 20 isDone = scheduledThreadPool.awaitTermination(1, TimeUnit.DAYS); 21 System.out.println("awaitTermination..."); 22 } 23 while(!isDone) 24 System.out.println("Finished all threads"); 25 } 26 }
1 class Task implements Runnable { 2 private String name; 3 4 public Task(String name) { 5 this.name = name; 6 } 7 8 @Override 9 public void run() { 10 System.out.println("name = " + name + ", startTime = " + new Date()); 11 try { 12 Thread.sleep(1000); 13 } catch (InterruptedException e) { 14 e.printStackTrace(); 15 } 16 System.out.println("name = " + name + ", endTime = " + new Date()); 17 } 18 }
13. Java中自动装箱与拆箱(autoboxing and unboxing)
1 Integer total = 99;//自动装箱 2 int totalprim = total;//自动拆箱
自动装箱拆箱的类型为八种基本类型:
 基本类型和包装器类型有许多不同点。
基本类型和包装器类型有许多不同点。
14. Java中的隐式转换和强制转换
-
由低到高
1 byte a = 1; 2 short b = a; 3 int c = b; 4 long d = c; 5 6 float f = 2f; 7 double g = f;
-
由高到低
默认强制转换
15. Java中String、StringBuffer、StringBuilder
String:不可变长的字符序列;
StringBuffer:可变的字符序列,线程安全,效率低;
StringBuilder:可变的字符序列,线程不安全,效率高。
16. 向下转型和向上转型
为了共用一套代码:
1 public class PetFactory { 2 private PetFactory() { 3 } 4 public static Pet getPet(String type) throws Exception { 5 Pet pet = null; 6 switch (type) { 7 case "dog": 8 pet = new Dog(); 9 break; 10 case "cat": 11 pet = new Cat(); 12 break; 13 default: 14 throw new Exception(); 15 } 16 return pet; 17 } 18 } 19 public void example(String type){ 20 Pet pet = PetFactory.getPet(type); //向上转型 21 playWithPet(pet);//公共的 22 if(pet instanceOf Dog){ 23 Dog snoopy = (Dog) pet; //向下转型 24 snoopy.sitDown(); 25 } else { 26 Cat white = (Cat) pet; //向下转型 27 white.climb(); 28 } 29 }
17. String hashCode 方法选择数字31作为乘子
- 31是一个不大不小的质数,质数的特性(只有1和自己是因子)能够使得它和其他数相乘后得到的结果比其他方式更容易产成唯一性,降低哈希算法的冲突率;
- 31可以被 JVM 优化,31 * i = (i << 5) - i。
18. Java内部类访问外部类局部变量必须声明为final
编译后的内部类和外部类各一个class文件,内部类访问外部类局部变量实际是复制了一份,为了避免数据的不一致性,设置局部变量为final。
19. 类的加载
Class文件由类装载器装载后,在JVM中将形成一份描述Class结构的元信息,通过该元信息可以获知Class的结构信息:如构造函数,属性和方法等,Java允许用户通过元信息间接调用Class对象的功能。
在Java中,类装载器把一个类装入JVM中,要经过以下步骤:
- 装载:查找和导入Class文件;
- 链接:把类的二进制数据合并到JRE中; (a)校验:检查载入Class文件数据的正确性; (b)准备:给类的静态变量分配存储空间; (c)解析:将符号引用转成直接引用;
- 初始化:对类的静态变量,静态代码块执行初始化操作
20. 双亲委派模式
- 原理
类加载器有加载类的需求时,先请求父加载器帮忙加载,直到传到顶层启动类加载器,父加载不了再由子加载器加载;
- 使用原因
为了避免重复加载,父加载器加载过了子加载器就没必要再加载了,否则我们可以随时使用自定义的类代替Java核心API中的类型,好阔怕
21. volatile关键字
- 使用volatile关键字修饰变量,会强制将修改值立即写入主存,当一个线程修改时,会导致其他线程工作内存中的变量缓存无效,其他线程再读取变量时会去主存读取;
- volatile 修饰的变量会禁止指令重排序。
与synchronized对比:
- volatile只能修饰变量。synchronized还可修饰方法;
- volatile只能保证数据的可见性,不能用来同步,多个线程并发访问volatile修饰的变量不会阻塞。synchronized不仅保证可见性,而且还保证原子性,多个线程争夺synchronized锁对象的时候,会出现阻塞。
22. synchronized与Lock的区别
- synchronized是java内置关键字,在JVM层面,而Lock是个java类;
- synchronized无法判断是否获取到锁,Lock可以判断是否获取到锁;
- synchronized会自动释放锁(执行完同步代码会释放锁 ;执行过程中发生异常会释放锁),Lock须在finally中使用unlock()方法手工释放锁,否则容易造成线程死锁;
- 用synchronized关键字的线程,如果一个线程获得了锁,其他线程等待。如果线程阻塞,其他线程会一直等待,而Lock锁就不一定会等待下去,如果尝试获取不到就结束了。
23. 深拷贝和浅拷贝
这个问题纠结了好久,在看原型模式之前终于要解决一下子了。上定义:
- 浅拷贝:浅拷贝是指在拷贝对象时,对于八大基本类型(byte,short,int,long,char,double,float,boolean)的变量重新复制一份,而对于引用类型的变量只是对直接引用进行拷贝,没有对直接引用指向的对象进行拷贝;
- 深拷贝:深拷贝是指在拷贝对象时,不仅把基本数据类型的变量会重新复制一份,同时会对引用指向的对象进行拷贝,注意拷贝的时候值也拷贝过来。
在 Java 中,所有的 Class 都继承自 Object ,而在 Object 中有一个clone()方法,它被声明为了 protected ,所以我们可以在其子类中使用它。它限制所有调用clone()方法的对象,都必须实现Cloneable接口,否者将抛出 CloneNotSupportedException 这个异常。先看浅拷贝,
1 private class Father implements Cloneable { 2 public String name; 3 public int age; 4 public Child child; 5 6 @Override 7 public Object clone() { 8 try { 9 return super.clone(); 10 } catch (CloneNotSupportedException ignore) { 11 e.printStace(); 12 } 13 return null; 14 } 15 }
如果使用该方法去clone,克隆出的Father对象的hashcode跟被克隆的对象的hashcode不同,但成员变量child的hashcode是一样的,说明引用对象使用的是同一个,再看深拷贝,
1 private class Father implements Cloneable { 2 public String name; 3 public int age; 4 public Child child; 5 6 @Override 7 public Object clone() { 8 try { 9 Father cloneFather =(Father)super.clone(); 10 cloneFather.child = (Child)super.clone(); 11 return cloneFather; 12 } catch (CloneNotSupportedException ignore) { 13 e.printStace(); 14 } 15 return null; 16 } 17 } 18 private class Child implements Cloneable { 19 public String name; 20 public int age; 21 22 @Override 23 public Object clone() { 24 try { 25 return super.clone(); 26 } catch (CloneNotSupportedException ignore) { 27 e.printStace(); 28 } 29 return null; 30 } 31 }
在克隆Father对象时,又对成员对象Child(里边的成员变量是基本类型)进行了克隆,这就是深拷贝,层级拷贝,直到基本类型,这样代码量不可估计,所以有了序列化拷贝的方式,就是把对象放到流里,再拿出来,前提是没有transient对象,对象以及对象内部所有引用到的对象都是可串行化的,简单地讲,序列化就是将对象写到流中,写到字节流里就等于复制了对象,原来的对象并没有动,然后写到另个内存地址中去。。
1 public Object deepClone() 2 { 3 //写入对象 4 ByteArrayOutoutStream bo=new ByteArrayOutputStream(); 5 ObjectOutputStream oo=new ObjectOutputStream(bo); 6 oo.writeObject(this); 7 //读取对象 8 ByteArrayInputStream bi=new ByteArrayInputStream(bo.toByteArray()); 9 ObjectInputStream oi=new ObjectInputStream(bi); 10 return(oi.readObject()); 11 }
24. Java为什么取消多继承
子类继承多个父类有两个问题:
- 多个父类中有相同名字的变量,子类在调用的时候不知道调用哪一个;
- 多个父类中有相同名字的方法,子类未重写,子类在调用的时候不知道调用哪一个。
25. Java IO和装饰类模式
Java IO这块流比较多,以前也没看过,最近在看装饰者模式(https://www.cnblogs.com/lcmichelle/p/10854871.html),正好梳理了一下。Java应用程序通过输入流(InputStream)的Read方法从源地址处读取字节,然后通过输出流(OutputStream)的Write方法将流写入到目的地址。
首先,流的来源主要有五种:文件(File)、字节数组、StringBuffer、其他线程和序列化的对象,因此,Java中有FileInputStream处理文件,ByteArrayInputStream处理字节数组,StringBufferInputStream处理StringBuffer,PipedInput-Stream处理线程间的输入流,ObjectInputStream处理被序列化的对象。还有一个SequenceInputStre-am处理包裹有多种数据来源的业务。
后来,这些流在使用过程中出现了一些问题:FileInputStream读磁盘速度慢;读出的数据都是byte[]类型,需要用户自己转换成基本类型;从Stream读出来的数据无法推回去。针对这些问题,Java需要增加拥有缓存的BufferedInputStream,把byte转换成JAVA基本类型的DataInput-Stream和回写数据到stream的Push-backInput-Stream。直接增加类的话,排列组合形成的子类太多,因此,Java采用了装饰者模式。
如下图所示,最里边的实心是处理文件读取的FileInputStream,外面套一个BufferedInputStream的壳,那么这部分就是带buffer的FileInputStream。如果再套一个DataInputStream,那么就成了能输出int这样java 基本类型并且带buffer的FileInputStream。搭配由客户去决定,我们只需要提供套壳和最里面的实心InputStream(InputStream的6个孩子)。客户在搭配的时候必须有一个实心,否则就没有数据来源。 BufferedInputStream,DataInputStream,PushbackInputStream都继承自InputStream类,这样才能实现嵌套。这3个套娃壳有着共同的特点都是用来装饰,在他们上层在抽象一个FilterInputStream,让FilterInputStream继承自InputStream,以后所有的装饰类都从FilterInputStream继承。
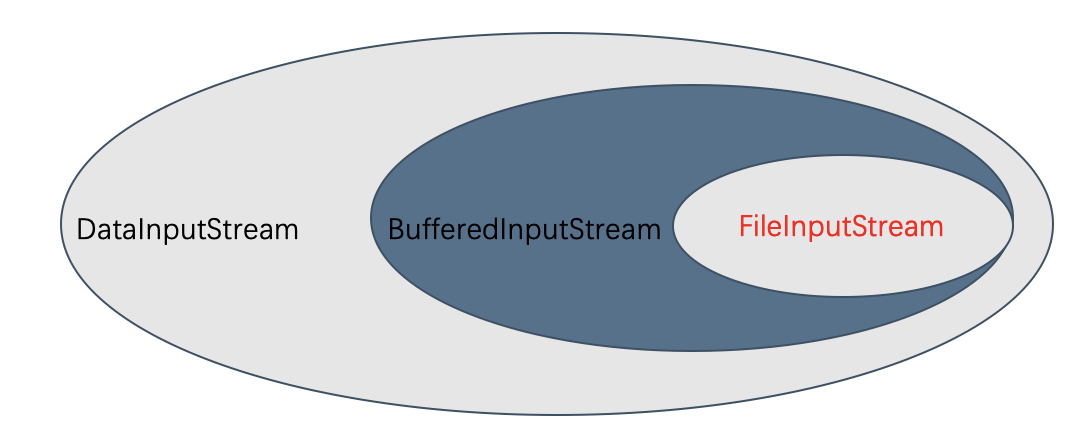
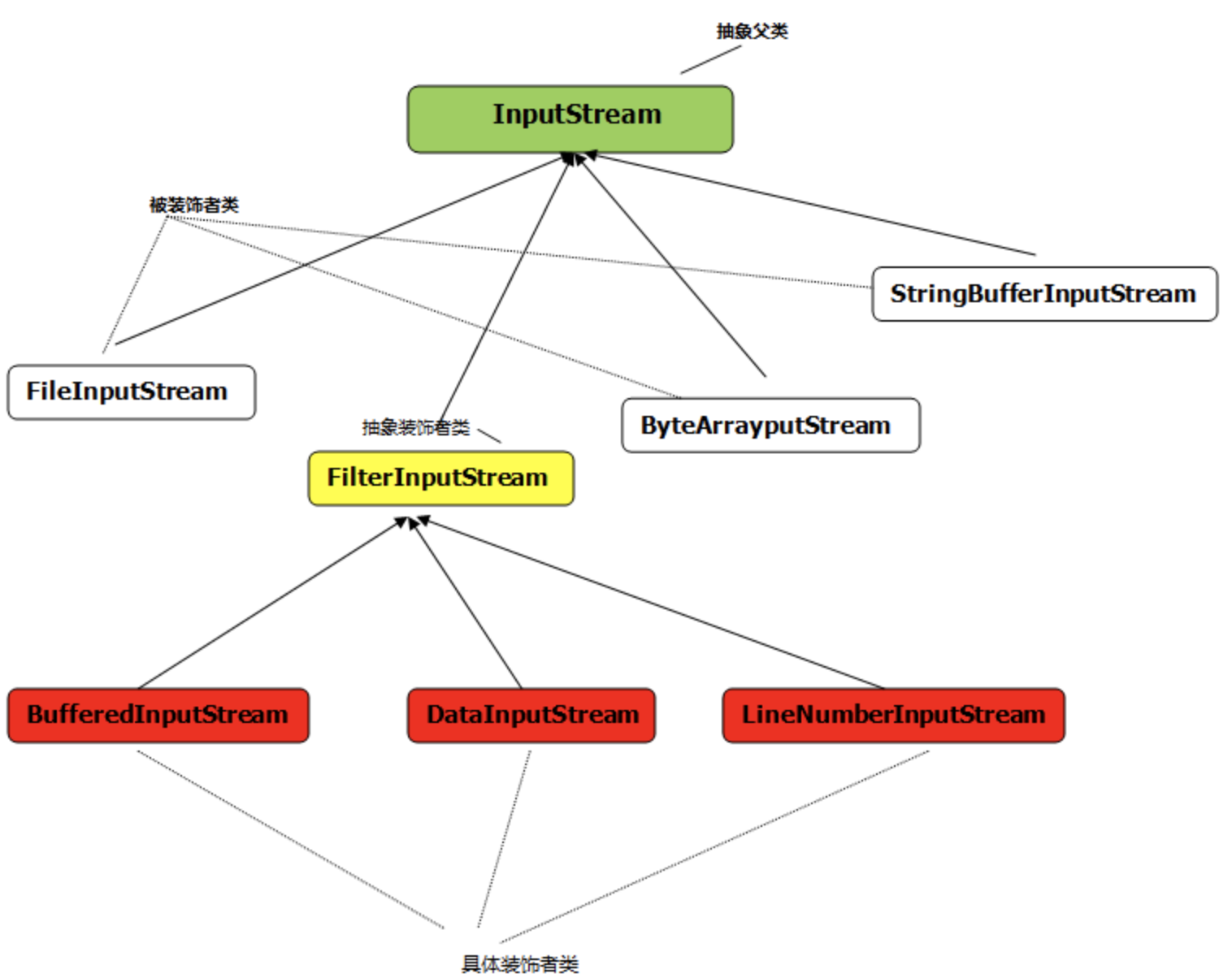
26. Comparable和Comparator接口
相同点:
- 都是Java util下的两个接口,都是对自定义的数据结构比较大小,比如Person类。
不同点:
- Comparable是内部比较器,定义在类的内部,而Comparator是外部比较器,定义在类的外边,不修改实体类;
- Comparable需要实现compareTo()方法,传一个外部参数进行比对;Comparator接口需要实现compare()方法,对外部传入的两个类进行比较;
- 实现Comparator接口代码采用策略模式,可以定义某个类的多个比较器,在排序时根据实际场景自由调用,而Comparable接口实现后不方便改动,扩展性不好。
举例:
comparable
1 class Person implements Comparable<Person>{//该接口强制让人具有比较性 2 private String name; 3 private int age; 4 public Person(String name,int age) { 5 this.name = name; 6 this.age=age; 7 } 8 public String getName() { 9 return name; 10 } 11 public void setName(String name) { 12 this.name = name; 13 } 14 public int getAge() { 15 return age; 16 } 17 public void setAge(int age) { 18 this.age = age; 19 } 20 @Override 21 public int compareTo(Person o) { 22 if(this.age>o.age){ 23 return 1; 24 }else if(this.age<o.age){ 25 return -1; 26 }else{ 27 return this.name.compareTo(o.name); 28 } 29 } 30 @Override 31 public String toString() { 32 return "Person [name=" + name + ", age=" + age + "]"; 33 } 34 }
1 import java.util.Iterator; 2 import java.util.TreeSet; 3 4 public class Demo { 5 public static void main(String[] args) { 6 Person p0 = new Person("张三",3); 7 Person p = new Person("张三",1); 8 Person p1 = new Person("张三",2); 9 Person p2 = new Person("张四",2); 10 Person p3 = new Person("张四",2); 11 12 TreeSet<Person> treeSet=new TreeSet<Person>(); 13 treeSet.add(p0); 14 treeSet.add(p); 15 treeSet.add(p1); 16 treeSet.add(p2); 17 treeSet.add(p3); 18 19 Iterator<Person> iterator = treeSet.iterator(); 20 while(iterator.hasNext()){ 21 Person next = iterator.next(); 22 System.out.println(next); 23 } 24 } 25 }
comparator
1 class Com implements Comparator<Person>{//该接口强制让集合具有比较性 2 @Override 3 public int compare(Person o1, Person o2) { 4 if(o1.getAge()>o2.getAge()){ 5 return 1; 6 }else if(o1.getAge()<o2.getAge()){ 7 return -1; 8 }else{ 9 return o1.getName().compareTo(o2.getName()); 10 } 11 } 12 } 13 14 class Person{ 15 private String name; 16 private int age; 17 public Person(String name,int age) { 18 this.name = name; 19 this.age=age; 20 } 21 public String getName() { 22 return name; 23 } 24 public void setName(String name) { 25 this.name = name; 26 } 27 public int getAge() { 28 return age; 29 } 30 public void setAge(int age) { 31 this.age = age; 32 } 33 @Override 34 public String toString() { 35 return "Person [name=" + name + ", age=" + age + "]"; 36 } 37 }
1 import java.util.Comparator; 2 import java.util.Iterator; 3 import java.util.TreeSet; 4 5 6 public class Demo { 7 public static void main(String[] args) { 8 Person p0 = new Person("张三",3); 9 Person p = new Person("张三",1); 10 Person p1 = new Person("张三",2); 11 Person p2 = new Person("张四",2); 12 Person p3 = new Person("张四",2); 13 14 TreeSet<Person> treeSet=new TreeSet<>(new Com()); 15 treeSet.add(p0); 16 treeSet.add(p); 17 treeSet.add(p1); 18 treeSet.add(p2); 19 treeSet.add(p3); 20 21 Iterator<Person> iterator = treeSet.iterator(); 22 while(iterator.hasNext()){ 23 Person next = iterator.next(); 24 System.out.println(next); 25 } 26 } 27 }
可以看到comparator方法中是将Com对象作为参数传给treeset等需要进行排序的集合容器的构造函数中了。
最后,如果实现类没有实现Comparable接口,又想对两个类进行比较(或者实现类实现了Comparable接口,但是对compareTo方法内的比较算法不满意),那可以实现Comparator接口,自定义一个比较器。
27. JVM调优总结 -Xms -Xmx -Xss -XX
Xms是指设定程序启动时占用内存大小,就是JVM默认堆的大小。一般来讲,大点,程序会启动的快一点,但是也可能会导致机器暂时间变慢。
Xmx是指设定程序运行期间最大可占用的内存大小。如果程序运行需要占用更多内存,超出了这个值,就会抛出OutOfMemory异常。
Xss是指设定每个线程的堆栈大小。这个就要依据你的程序,看一个线程大约需要占用多少内存,可能会有多少线程同时运行等。
-XX:PermSize用于设置非堆内存初始值,默认是物理内存的1/64;由XX:MaxPermSize设置最大非堆内存的大小,默认是物理内存的1/4。
上面四个参数的设置都是默认以Byte为单位的,也可以在数字后面添加[k/K]或者[m/M]来表示KB或者MB。而且,超过机器本身的内存大小也是不可以的,否则就等着机器变慢而不是程序变慢了。
28. 同步和异步
- 同步:发送一个请求,等待返回,然后再发送下一个请求,比如电话,需要接通对方
- 同步好处:按顺序修改可以避免出现死锁,读脏数据的发生
- 异步:发送一个请求,不等待返回,随时可以再发送下一个请求,比如广播
- 异步好处:多线程并发可以提高效率
29. 大端和小端
计算机的内存最小单位是是BYTE(字节)。
一个大于BYTE的数据类型在内存中存放的时候要有先后顺序。
高内存地址放整数的高位,低内存地址放整数的低位,这种方式叫倒着放,术语叫小端对齐。电脑X86和手机ARM都是小端对齐的。
高内存地址放整数的低位,低内存地址放整数的高位,这种方式叫正着放,术语叫大端对齐。很多Unix服务器的cpu都是大端对齐的。
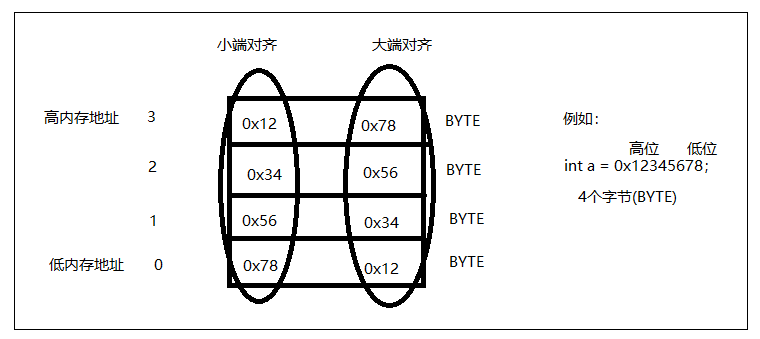
30. Lambda表达式的意义
类似匿名类,具体参见:做了这么久的程序员,你知道为什么会有Lambda表达式吗?
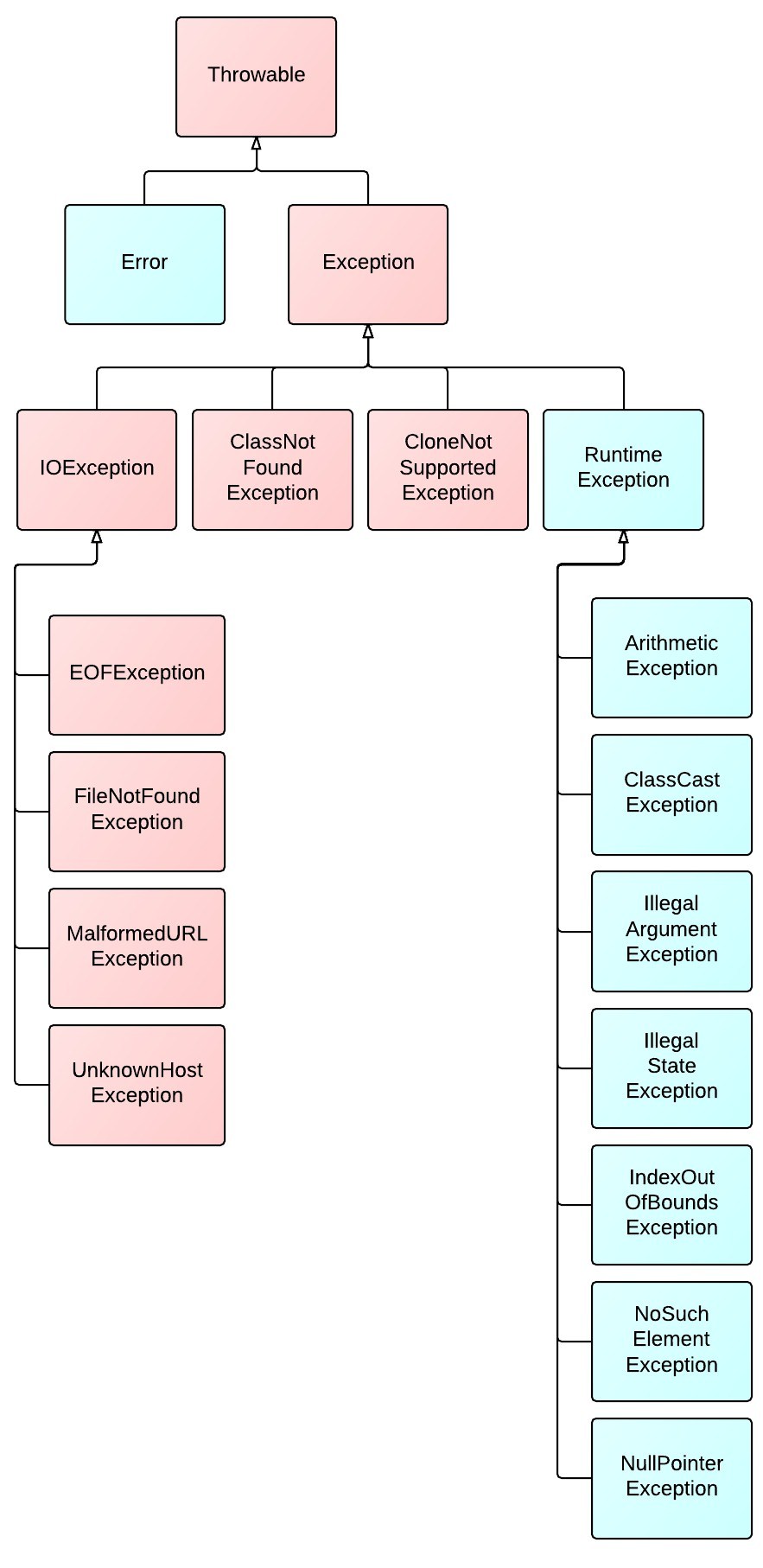
31. Exception
Java有异常都继承自java.lang.Throwable类。
Throwable有两个直接子类,Error类和Exception类。
Exception则可分为执行异常(RuntimeException)和检查异常(Checked Exceptions)两种。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号