Hive中知识点

一、hive的执行命令
1 hive -S :进入hive的静默模式,只显示查询结果,不显示执行过程; 2 hive -e ‘show tables’ :直接在操作系统命令下执行hive语句,不需要进入hive交互模式; 3 source /root/my.sql; :在hive模式下使用source命令执行.sql文件;
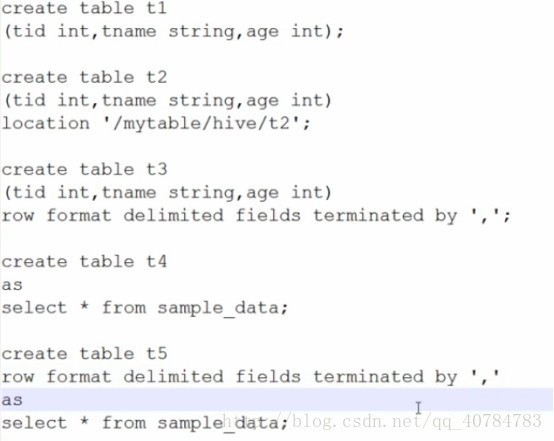
t1:创建普通表;
t2:在hdfs中的指定目录创建表;
t3:创建列分隔符为“,”的表;
t4:使用查询语句创建有数据的表;
t5:使用查询语句创建列以“,”分隔有数据的表;
来自https://blog.csdn.net/qq_40784783/article/details/79168896
desc formatted 表名; 显示表结构
describe database 数据库;显示数据库所在存储路径
二、hive的.hiverc文件
在${HIVE_HOME}/bin目录下建.hiverc文件,加入:
1 set hive.cli.print.header=true;
就可以显示表头。可以显示当前数据库:
1 set hive.cli.print.current.db=true;
使用本地模式运行语句
1 set hive.exec.mode.local.auto=true;
三、自定义的udf包
由于需要满足一个hive中不等值连接的需求,必须得自己手工写udf。以前也没有试过,所以今天尝试了下自己写了个ToLowerCase.java
1 mkdir -p com/alibaba/hive/udf
1 vim com/alibaba/hive/udf
1 package com.alibaba.hive.udf; 2 import org.apache.hadoop.hive.ql.exec.UDF; 3 4 public class ToLowerCase extends UDF{ 5 // 必须是 public,并且 evaluate 方法可以重载 6 public String evaluate(String field) { 7 String result = field.toLowerCase(); 8 return result; 9 } 10 }
1 javac -classpath /usr/local/hadoop-2.7.5/share/hadoop/common/lib/*.jar:/usr/local/hive/lib/hive-exec-2.3.2.jar ./ToLowerCase.java
1 jar -cvf ToLowerCase.class
1 create temporary function tolowercase as 'com.alibaba.hive.udf.ToLowerCase'; 2 hive (default)> select tolowercase('HELLO'); 3 OK 4 _c0 5 hello
四、hive RegexSerDe使用详解
五、复制hive表结构
1 CREATE TABLE b LIKE a;
六、导入文本文件到hive
有时候会有把文本文件导入hive的需要,一般分两种,分别记录下:
- 把本地文件导入hive表
先创建hive表
1 create database if not exists test; 2 create table test.test(key int,value string) row format delimited fields terminated by ','stored as textfile;
然后搞个文本文件1.txt


100,val_100 298,val_298 9,val_9 341,val_341 498,val_498 146,val_146 458,val_458 362,val_362 186,val_186
导入hive表
1 LOAD DATA LOCAL INPATH '/opt/datas/1.txt' OVERWRITE INTO TABLE test;
最后,可以select * from test查询下
- 把HDFS上文件导入hive表
1 LOAD DATA INPATH '/home/hadoop/testhive/1.txt' OVERWRITE INTO TABLE test;
七、小表Join大表
预留
八、hive安装
在hive安装过程中出现错误:Missing Hive Execution Jar: /root/hive/bin/lib/hive-exec-*.jar
可以发现目录/bin/lib这两个目录是并列的,说明hive在centos系统配置文件中的路径有误,打开 /etc/profile修改hive的配置路径 :
1 export HIVE_HOME=$PWD/hive 2 export PATH=$PATH:$HIVE_HOME
九、时间格式化
1. 把需要转换的时间转换为时间戳
select unix_timestamp('2018-03-05 17:22:57.784','yyyy-MM-dd HH:mm:ss.SSS');
2. 把时间戳转换为时间
select from_unixtime(1520241777,'yyyyMMddHHmm');
十、hive中的and和or
hive中and的执行优先级比or高,下面是测试语句:
select 1 from student where 1=0 or 1=1 and 1 = 0;
执行结果为空
select 1 from student where 1=0 or 1=1 and 1 =1;
执行结果为1
第二个select语句毫无疑问where语句后面的值返回为true,无论and或者or的优先级如何都一样,但是第一个select语句缺不是从左到右执行的,相当于select 1 from student where 1 = 0 or (1=1 and 1 = 0);
十一、hive的子查询
Hive只在FROM字句支持子查询,子查询必须给一个名字 。
SELECT col FROM ( SELECT a+b AS col FROM t1 ) t2
十二、orderby null值的处理
order by 时,desc NULL 值排在首位,ASC时NULL值排在末尾 可以通过NULLS LAST、NULLS FIRST 控制
RANK() OVER (ORDER BY column_name DESC NULLS LAST)
十三、json数据的解析
Hdfs上有text文件
{
"name":"Qian Xu",
"age":16,
"money":120000,
"friends":[
{
"name":"Qing Huai",
"age":5,
"money":18000
}
]
}
有三种方法可以解析数据:
- hive函数get_json_object解析json数据
select get_json_object(jsonStr, '$.name') name, get_json_object(jsonStr, '$.age') age, get_json_object(jsonStr, '$.money') money, get_json_object(jsonStr, '$.friends[0].name') friend_name from test_user1;
但是对于friends这种字段解析不太友好
- hive 4.0.0以后可以在创建hive表时通过指定STORE AS JSONFILE自动解析
- hive 3.0.0以后JsonSerDe已经添加到Hive Serde中了,以前需要自己下载jar包放到libs下
ROW FORMAT SERDE 'org.apache.hive.hcatalog.data.JsonSerDe' STORED AS TESTFILE
create external table test_user2 { name string, age int, money bigint,
friends array<struct<`name`: string, `age`: int, `money`: bigint>> } ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.JsonSerDe' STORED AS TESTFILE location "/test/user1"

 浙公网安备 33010602011771号
浙公网安备 33010602011771号