一个完整的大作业
1.选一个自己感兴趣的主题。
2.网络上爬取相关的数据。
3.进行文本分析,生成词云。
4.对文本分析结果解释说明。
5.写一篇完整的博客,附上源代码、数据爬取及分析结果,形成一个可展示的成果。
要爬取一个网站的内容首先我们要选择一个要浏览的网站,本次实验选取的是http://news.ycwb.com/n_gd_jd.htm---金羊网,而我们本次实验可以索取的数据包括一条新闻的详细信息以及在这个网站中所有滚动新闻的数据,主要分为以下步骤:
步骤一:首先我们可以获取一条新闻的信息数据,代码如下:
def getdetail(url): rs=requests.get(url) rs.encoding='utf-8' soupd=BeautifulSoup(rs.text,'html.parser') news={} news['title']=soupd.select('.title > h1 ')[0].text.strip(' \r\n')#标题 news['url']=url#链接 #news['source']=soupd.select('.title > .source ')[0].text.strip('\n') return(news) #print(getdetail('http://news.ycwb.com/2017-10/26/content_25625280.htm'))#详细一条新闻主页
效果如图:
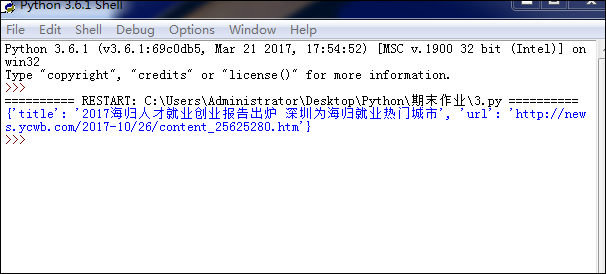
步骤二:获取一页新闻的数据信息,代码如下:
def apage(pageurl): res=requests.get(pageurl) res.encoding='utf-8' soup=BeautifulSoup(res.text,'html.parser') newsls=[] for news in soup.select('.list_l > li'): if len(news.select('a')) > 0: #newsls['title']=news.select('a')[0].text #newsls['link']='http://news.ycwb.com/'+news.select('a')[0]['href'] #print(newsls) newsls.append(getdetail('http://news.ycwb.com/'+news.select('a')[0]['href'])) return(newsls) #print(apage('http://news.ycwb.com/n_gd_jd_.htm'))#一页新闻的各条
效果如下:

步骤三:获取首页和2-4页新闻的信息数据,代码如下:
newstotal=[] gzccurl='http://news.ycwb.com/n_gd_jd.htm' newstotal.extend(apage(gzccurl)) #print(newstotal) res=requests.get(gzccurl) res.encoding='utf-8' soup=BeautifulSoup(res.text,'html.parser') #pages=int(soup.select('center > a')[0].text)#页码 for i in range(2,4): listurl='http://news.ycwb.com/n_gd_jd_{}.htm'.format(i) newstotal.extend(apage(listurl)) #print(newstotal)#首页及2-3页所有新闻的条数
效果如下:

步骤四:将获取的数据以Excel表格以及数据库的形式保存下来,方便应用,代码如下:
df=pandas.DataFrame(newstotal) df.to_excel('xinwen.xlsx') with sqlite3.connect('xinwendb1.sqlite') as db: df.to_sql('xinwendb1',con=db)
效果如图:


步骤五:将所得的部分数据进行分词、排序。代码如下:
for i in range(10): if i>0: t=t+newstotal[i].get('title') else: t=newstotal[i].get('title')#返回10条标题形成的文本 for i in ',。:?!“”() ': t=t.replace(i,'') title=list(jieba.cut(t))#分词形成列表
效果如图:
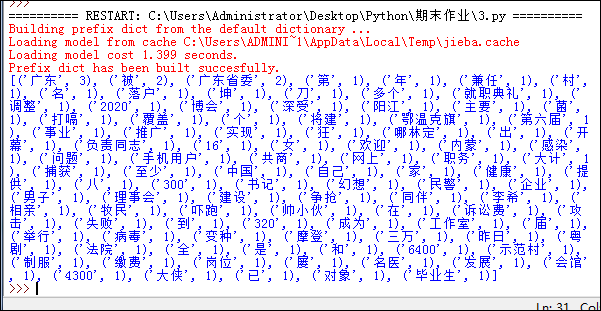
步骤六:进行词频统计,生成词云。代码如下:
k={} keys=set(title) for i in keys: k[i]=title.count(i) wc=list(k.items()) wc.sort(key=lambda x:x[1],reverse=True)#字典返回列表并排序 #print(wc) mywc=WordCloud().generate_from_frequencies(k)#传入一个字典,返回词云 plt.imshow(mywc) plt.show()
得到效果如图:

最后完整的代码如下所示:
import requests from bs4 import BeautifulSoup import pandas import sqlite3 import jieba from wordcloud import WordCloud import matplotlib.pyplot as plt def getdetail(url): rs=requests.get(url) rs.encoding='utf-8' soupd=BeautifulSoup(rs.text,'html.parser') news={} news['title']=soupd.select('.title > h1 ')[0].text.strip(' \r\n')#标题 news['url']=url#链接 #news['source']=soupd.select('.title > .source ')[0].text.strip('\n') return(news) #print(getdetail('http://news.ycwb.com/2017-10/26/content_25625280.htm'))#详细一条新闻主页 def apage(pageurl): res=requests.get(pageurl) res.encoding='utf-8' soup=BeautifulSoup(res.text,'html.parser') newsls=[] for news in soup.select('.list_l > li'): if len(news.select('a')) > 0: #newsls['title']=news.select('a')[0].text #newsls['link']='http://news.ycwb.com/'+news.select('a')[0]['href'] #print(newsls) newsls.append(getdetail('http://news.ycwb.com/'+news.select('a')[0]['href'])) return(newsls) #print(apage('http://news.ycwb.com/n_gd_jd_.htm'))#一页新闻的各条 newstotal=[] gzccurl='http://news.ycwb.com/n_gd_jd.htm' newstotal.extend(apage(gzccurl)) #print(newstotal) res=requests.get(gzccurl) res.encoding='utf-8' soup=BeautifulSoup(res.text,'html.parser') #pages=int(soup.select('center > a')[0].text)#页码 for i in range(2,4): listurl='http://news.ycwb.com/n_gd_jd_{}.htm'.format(i) newstotal.extend(apage(listurl)) #print(newstotal)#首页及2-3页所有新闻的条数 ''' df=pandas.DataFrame(newstotal) #print(df.head()) #print(df['title']) df.to_excel('xinwen.xlsx') with sqlite3.connect('xinwendb1.sqlite') as db: df.to_sql('xinwendb1',con=db) ''' for i in range(10): if i>0: t=t+newstotal[i].get('title') else: t=newstotal[i].get('title')#返回10条标题形成的文本 for i in ',。:?!“”() ': t=t.replace(i,'') title=list(jieba.cut(t))#分词形成列表 #print(title) k={} keys=set(title) for i in keys: k[i]=title.count(i) wc=list(k.items()) wc.sort(key=lambda x:x[1],reverse=True)#字典返回列表并排序 #print(wc) mywc=WordCloud().generate_from_frequencies(k)#传入一个字典,返回词云 plt.imshow(mywc) plt.show()


 浙公网安备 33010602011771号
浙公网安备 33010602011771号