Windows如何安装spark
Apache Spark是一个开源的大数据处理框架,旨在提供高效、通用和易用的大数据处理引擎。它最初由加州大学伯克利分校AMPLab开发,并于2010年开源。
Spark提供了一个基于内存的计算引擎,可以在大规模数据集上执行高速的数据处理任务。相比传统的MapReduce模型,Spark具有更高的性能和更丰富的功能集。它支持多种数据处理任务,包括批处理、交互式查询、流式处理和机器学习。
Spark的核心组件包括:
1、Spark Core: 提供了Spark的基本功能,包括任务调度、内存管理、错误恢复等。
2、Spark SQL: 提供了用于处理结构化数据的SQL查询接口,允许用户在Spark上执行SQL查询。
3、Spark Streaming: 提供了用于实时数据流处理的API,使用户能够在Spark中处理实时数据。
4、MLlib(Machine Learning Library): 提供了用于机器学习的各种算法和工具,使用户能够在Spark中进行分布式的机器学习任务。
5、GraphX: 提供了用于图形处理的API,使用户能够在Spark中执行图形计算任务。
Spark通常与Hadoop生态系统中的其他工具(如HDFS、Hive、HBase等)配合使用,但它也可以独立运行。
1、安装jdk
Windows安装JDK请看这篇文章安装链接
2、安装scala
Windows安装JDK请看这篇文章安装链接
3、安装hadoop
Windows安装hadoop请看这篇文章安装链接
4、安装spark
4.1下载spark链接: 点击这里下载
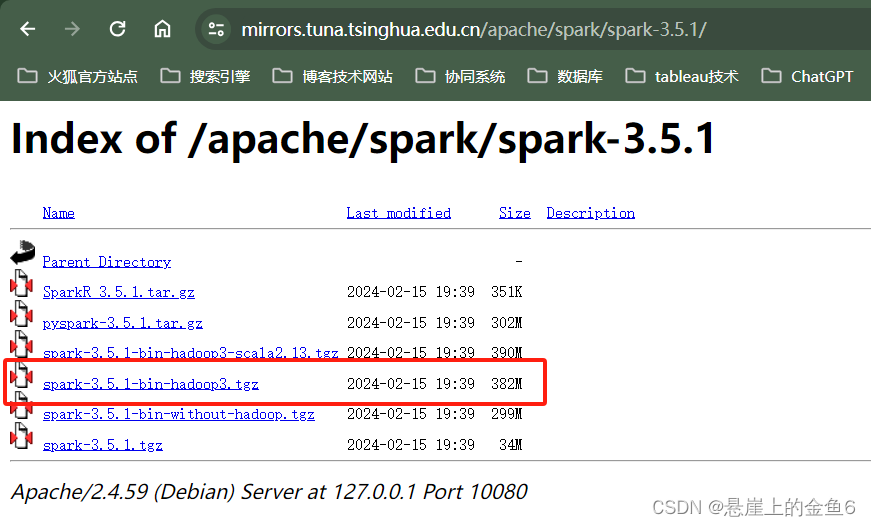
4.2下载之后加压缩到对应的位置
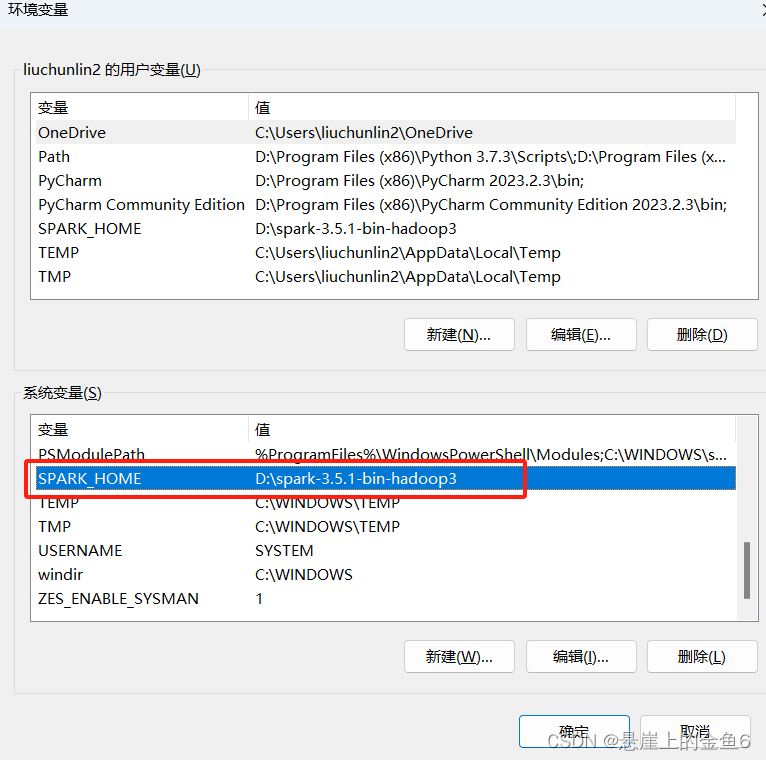
4.3配置环境变量
4.3.1新建系统变量》变量名:SOARK_HOME 变量值:spark安装的路径
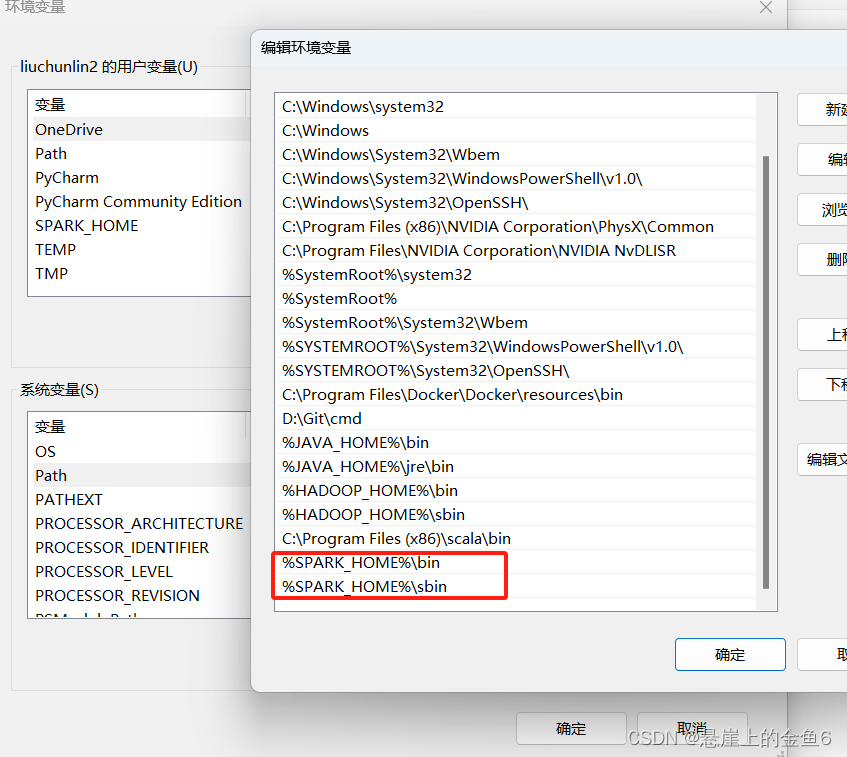
4.3.2系统变量path中新建两个变量值 %SPARK_HOME%\bin %SPARK_HOME%\sbin
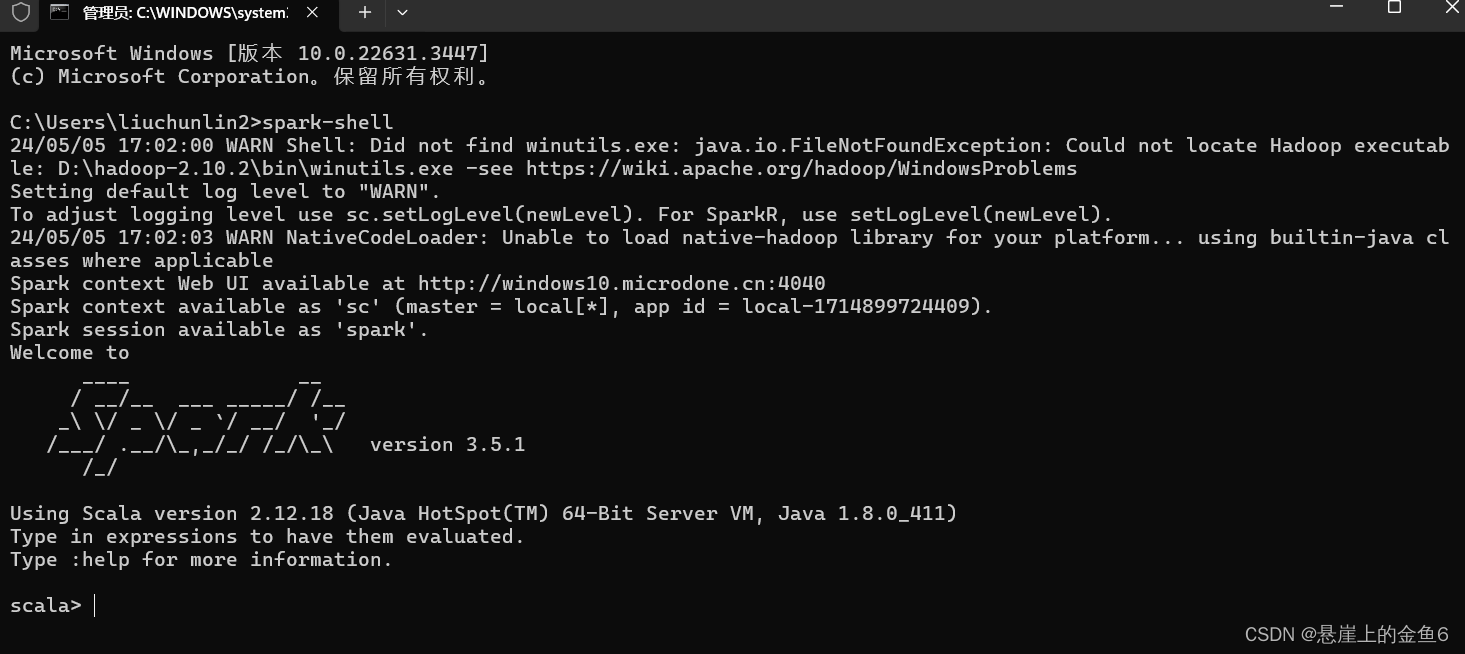
5、检查spark是否安装成功
win+r 输入cmd 在输入spark-shell

 浙公网安备 33010602011771号
浙公网安备 33010602011771号