Pandas 分组聚合操作详解
Pandas 是 Python 中用于数据分析的重要工具,它提供了丰富的数据操作方法。在数据分析过程中,经常需要对数据进行分组聚合操作。本文将介绍 Pandas 中的数据分组方法以及不同的聚合操作,并结合代码示例进行说明。
完整Excel数据
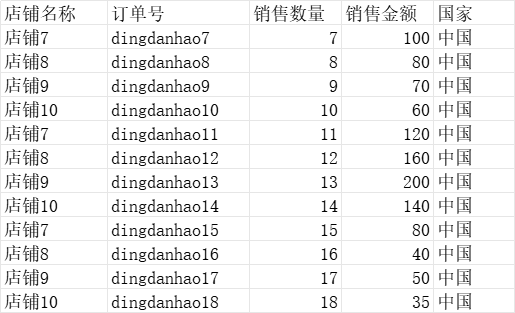
读取数据并进行简单分组
首先,我们通过 Pandas 读取 Excel 文件,并使用单个列进行分组,并应用聚合函数。示例代码如下:
df1 = pd.read_excel('C:\\Users\\liuchunlin2\\Desktop\\数据1.xlsx') df = df1.groupby('店铺名称', as_index=False).sum() print(df)
多列分组及聚合函数应用
接着,我们演示了如何使用多个列进行分组,并应用聚合函数:
df2 = df1.groupby(['店铺名称','订单号'], as_index=False).sum() print(df2)
自定义聚合函数的应用
在这个示例中,我们定义了一个自定义聚合函数 custom_agg,并将其应用在分组聚合操作中:
def custom_agg(x): return x.max() - x.min() result = df1.groupby('店铺名称', as_index=False)['销售数量'].agg(custom_agg) print(result)
同时应用多个聚合函数
我们还可以同时应用多个聚合函数,示例如下:
df3 = df1.groupby('店铺名称', as_index=False).agg({'销售数量': 'sum', '销售金额': 'mean'}) print(df3)
迭代分组
Pandas 支持迭代分组的操作,通过以下示例可以看到迭代分组的效果:
for group, data in df1.groupby('店铺名称'): print(group) # 分组的键值 print(data) # 所有属于该分组的数据
条件过滤
根据条件过滤分组:
df4 = df1.groupby('店铺名称').filter(lambda x: x['销售金额'].sum() > 300) print(df4)
转换分组及分组排序
最后,我们演示了分组数据的转换以及分组排序的操作:
df1['NewColumn'] = df1.groupby('店铺名称')['销售数量'].transform(lambda x:x.sum()) print(df1)

排序
df5 = df1.groupby('店铺名称').sum().sort_values('销售数量', ascending=True) print(df5)
以上就是关于 Pandas 分组聚合操作的详细介绍,通过这些示例代码和解释,相信读者对 Pandas 中的分组聚合操作有了更深入的理解。
总结:在数据分析中,对数据进行分组聚合是一项常见且重要的操作,Pandas 提供了丰富的功能来实现这一目的,包括单列分组、多列分组、自定义聚合函数、迭代分组、数据导出、条件过滤、分组转换以及分组排序等操作,能够满足大部分数据分析需求。
完整代码
import pandas as pd import numpy as np # 读取两个 Excel 文件 df1 = pd.read_excel('C:\\Users\\liuchunlin2\\Desktop\\数据1.xlsx') #使用单个列进行分组,并应用聚合函数 df=df1.groupby('店铺名称', as_index=False).sum() #df=df1.groupby('店铺名称', as_index=False).aggregate({'销售数量': 'sum'}) print(df) #使用多个列进行分组,并应用聚合函数: df2=df1.groupby(['店铺名称','订单号'], as_index=False).sum() print(df2) # 定义自定义聚合函数 def custom_agg(x): return x.max() - x.min() # 使用自定义聚合函数对 'Column2' 进行聚合 result = df1.groupby('店铺名称', as_index=False)['销售数量'].agg(custom_agg) print(result) # 同时应用多个聚合函数 df3=df1.groupby('店铺名称', as_index=False).agg({'销售数量': 'sum', '销售金额': 'mean'}) print(df3) # 迭代分组 for group, data in df1.groupby('店铺名称'): print(group) # 分组的键值 print(data) # 所有属于该分组的数据 df3.to_excel('merged.xlsx', index=False) print('这是一条数据分割线') #根据条件过滤分组 df4=df1.groupby('店铺名称').filter(lambda x: x['销售金额'].sum() > 300) print(df4) #转换分组 df1['NewColumn'] = df1.groupby('店铺名称')['销售数量'].transform(lambda x:x.sum()) # 对 'Column2' 在每个分组内进行转换操作 #df=df1.groupby('店铺名称', as_index=False)['销售数量'].transform('sum') print(df1) #分组排序 df5=df1.groupby('店铺名称').sum().sort_values('销售数量', ascending=True) # ascending=True 升序 ascending=False 降序 print(df5)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号