

Python利用pandas进行数据合并
当使用Python中的pandas库时,merge函数是用于合并(或连接)两个数据框(DataFrame)的重要工具。它类似于SQL中的JOIN操作,允许你根据一个或多个键(key)将两个数据框连接起来。
merge函数的基本语法如下:
pd.merge( left, # 要合并的左侧 DataFrame right, # 要合并的右侧 DataFrame how='inner', # 连接方式,包括 'left', 'right', 'outer', 'inner',默认为 'inner' on=None, # 用于连接的列名,必须存在于左侧和右侧 DataFrame 中 left_on=None, # 左侧 DataFrame 用于连接的列名 right_on=None, # 右侧 DataFrame 用于连接的列名 left_index=False, # 如果为 True,则使用左侧 DataFrame 的索引作为连接键 right_index=False, # 如果为 True,则使用右侧 DataFrame 的索引作为连接键 suffixes=('_x', '_y'), # 字符串后缀,用于重叠列名的处理 sort=False, # 根据连接键对合并后的数据进行排序 copy=True, # 如果为 False,可以提高性能,但是在某些情况下会修改原始数据 )
下面详细解释每个参数的用法:
left和right:要连接的左右两个数据框,可以是DataFrame对象、Series对象或者带有相同列名的字典。on:指定用于连接的列名,如果两个数据框中的列名相同,可以直接指定为列名,如果列名不同,可以通过left_on和right_on参数分别指定左右两个数据框的列名。how:指定连接的方式,默认为'inner'。可选的取值有:- 'inner':内连接,只返回两个数据框中键匹配的行。
- 'outer':外连接,返回两个数据框中所有的行,并用NaN填充缺失的值。
- 'left':左连接,返回左侧数据框中所有的行,并用NaN填充右侧数据框中缺失的值。
- 'right':右连接,返回右侧数据框中所有的行,并用NaN填充左侧数据框中缺失的值。
left_on和right_on:如果要连接的列名不同,可以使用这两个参数分别指定左右两个数据框中用于连接的列名。left_index和right_index:如果要根据索引进行连接,可以将这两个参数设为True。sort:指定是否按照键对数据进行排序,默认为True。suffixes:如果两个数据框中存在重复的列名,可以使用这个参数为它们添加后缀以区分,默认为('_x', '_y')。copy:指定是否复制数据,默认为True。如果设置为False,可以避免复制数据而提高性能。indicator:指定是否在结果数据框中添加一个表示连接方式的特殊列,默认为False。validate:指定连接操作的有效性检查方式,可选的取值有None、'one_to_one'、'one_to_many'、'many_to_one'和'many_to_many'。
基本用法
merged_df = pd.merge(left_df, right_df, how='outer', on=['店铺名称']) # 连接方式,包括 'left', 'right', 'outer', 'inner',默认为 'inner' print(merged_df)
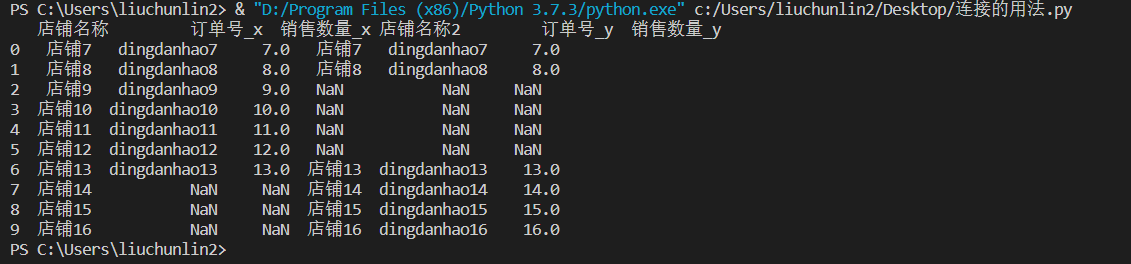
指定不同的列名
merged_df = pd.merge(left_df, right_df, how='outer', left_on='店铺名称', right_on='店铺名称2') print(merged_df)

处理重复列名,相同列名加后缀
merged_df = pd.merge(left_df, right_df, how='outer', on=['店铺名称'], suffixes=('_left', '_right')) print(merged_df)

根据索引进行合并
merged_df = pd.merge(left_df, right_df, how='outer', left_index=True, right_index=True) print(merged_df)

开启一列标记列,标记数据来源
merged_df = pd.merge(left_df, right_df, how='outer', on=['店铺名称','订单号'], indicator=True) print(merged_df)

完整代码
import pandas as pd # 读取两个 Excel 文件 left_df = pd.read_excel('C:\\Users\\liuchunlin2\\Desktop\\数据1.xlsx',sheet_name='Sheet2') right_df = pd.read_excel('C:\\Users\\liuchunlin2\\Desktop\\数据2.xlsx',sheet_name='Sheet2') #基本用法 merged_df = pd.merge(left_df, right_df, how='outer', on=['店铺名称']) # 连接方式,包括 'left', 'right', 'outer', 'inner',默认为 'inner' print(merged_df) #指定不同的列名 merged_df = pd.merge(left_df, right_df, how='outer', left_on='店铺名称', right_on='店铺名称2') print(merged_df) #处理重复列名,相同列名加后缀 merged_df = pd.merge(left_df, right_df, how='outer', on=['店铺名称'], suffixes=('_left', '_right')) print(merged_df) #根据索引进行合并 merged_df = pd.merge(left_df, right_df, how='outer', left_index=True, right_index=True) print(merged_df) #开启一列标记列,标记数据来源 merged_df = pd.merge(left_df, right_df, how='outer', on=['店铺名称','订单号'], indicator=True) print(merged_df)
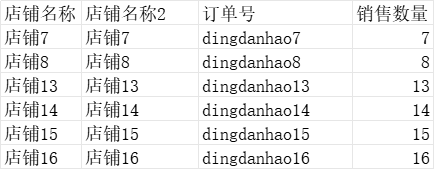
数据一:

数据二:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号