【多线程那些事儿】多线程的执行顺序如你预期吗?
一个简单的例子
先来看一个多线程的例子:
如图所示,我们将变量x和y初始化为0,然后在线程1中执行:
x = 1, m = y;
同时在线程2中执行:
y = 1, n = x;
当两个线程都执行结束以后,m和n的值分别是多少呢?
对于已经工作了n年、写过无数次并发程序的的我们来说,这还不是小case吗?让我们来分析一下,大概有三种情况:
- 如果程序先执行了x = 1, m = y代码段,后执行了y = 1, n = x代码段,那么结果是m = 0, n = 1;
- 如果程序先执行了y = 1, n = x代码段,后执行了x = 1, m = y代码段,那么结果是m = 1, n = 0;
- 如果程序的执行顺序先是 x = 1, y = 1, 后执行m = y, n = x, 那么结果是m = 1, n = 1;
所以(m, n)的组合一共有3种情况,分别是(0, 1), (1, 0)和(1, 1)。
那有没有可能程序执行结束后,(m, n)的值是(0, 0)呢?嗯...我们又仔细的回顾了一下自己的分析过程:在m和n被赋值的时候,x = 1和y = 1至少有一条语句被执行了...没有问题,那应该就不会出现m和n都是0的情况。
诡异的输出结果
不过人在江湖上混,还是要严谨一点。好在这代码逻辑也不复杂,那就写一段简单的程序来验证下吧:
#include <iostream>
#include <thread>
using namespace std;
int x = 0, y = 0, m = 0, n = 0;
int main()
{
while (1) {
x = y = 0;
thread t1([&]() { x = 1; m = y; });
thread t2([&]() { y = 1; n = x; });
t1.join(); t2.join();
if (m == 0 && n == 0) {
cout << " m == 0 && n == 0 ? impossible!\n";
}
}
return 0;
}
考虑到多线程的随机性,就写一个无限循环多跑一会吧,反正屏幕也不会有什么输出。我们信心满满的把程序跑了起来,但很快就发现有点不太对劲:
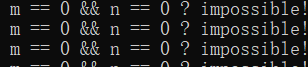
m和n居然真的同时为0了?不可能不可能...这难道是windows或者msvc的bug?那我们到linux上用g++编译试一下,结果程序跑起来之后,又看到了熟悉的输出:
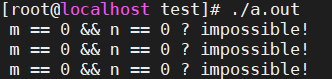
这...打脸未免来得也太快了吧!
你看到的执行顺序不是真的执行顺序
看来这不是bug,真的是有可能出现m和n都是0的情况。可是,到底是为什么呢?恍惚之间,我们突然想起曾经似乎在哪看过这样一个as-if规则:
The rule that allows any and all code transformations that do not change the observable behavior of the program.
也就是说,在不影响可观测结果的前提下,编译器是有可能对程序的代码进行重排,以取得更好的执行效率的。比如像这样的代码:
int a, b;
void test()
{
a = b + 1;
b = 1;
}
编译器是完全有可能重新排列成下面的样子的:
int a, b;
void test()
{
int c = b;
b = 1;
c += 1;
a = c;
}
这样,程序在实际执行过程中对a的赋值就晚于对b的赋值之后了。不过,有了前车之鉴,我们还是先验证一下在下结论吧。我们使用gcc的-S选项,生成汇编代码(开启-O2优化)来看一下,编译器生成的指令到底是什么样子的:
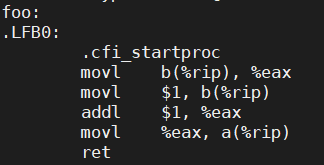
哈哈,果然如我们所料,对a的赋值被调整到对b的赋值后面了!那上面m和n同时为0也一定是因为编译器重新排序我们的指令顺序导致的!想到这里,我们的底气又渐渐回来了。那就生成汇编代码看看吧:
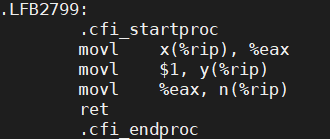
果然不出所料,因为我们在编译的时候开了-O3优化,赋值的顺序被重排了!代码实际的执行顺序大概是下面这个样子:
int t1 = y; x = 1; m = t1; //线程1
int t2 = x; y = 1; n = t2; //线程2
这就难怪会出现m = 0, n = 0这样的结果了。分析到这里,我们终于有点松了一口气,这多年的编程经验可不是白来的,总算是给出了一个合理的解释。
那我们在编译的时候把-O3优化选项去掉,尽量让编译器不要进行优化,保持原来的指令执行顺序,应该就可以避免m和n同时为0的结果了吧?试试,保险起见,我们还是先看一看汇编代码吧:

跟我们的预期一致,汇编代码保持了原来的执行顺序,这回肯定没有问题了。那就把程序跑起来吧。然而...不一会儿,熟悉的打印又出现了...
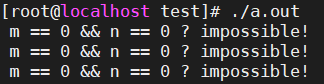
这...到底是怎么回事?!!!
你看到的执行顺序还不是真正的执行顺序
如果不是编译器重排了我们的指令顺序,那还会是什么呢?难道是CPU?!
还真是。实际上,现代CPU为了提高执行效率,大多都采用了流水线技术。例如:一个执行过程可以被分为:取指(IF),译码(ID),执行(EX),访存(MEM),回写(WB)等阶段。这样,当第一条指令在执行的时候,第二条指令可以进行译码,第三条指令可以进行取指...于是CPU被充分利用了,指令的执行效率也大大提高。一个标准的5级流水线的工作过程如下表所示(实际的CPU流水线远比这复杂得多):
| 序号/时钟周期 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | ... |
|---|---|---|---|---|---|---|---|---|
| 1 | IF | ID | EX | MEM | WB | |||
| 2 | IF | ID | EX | MEM | WB | |||
| 3 | IF | ID | EX | MEM | WB | |||
| 4 | IF | ID | EX | MEM | WB | |||
| 5 | IF | ID | EX | MEM | ||||
| 6 | IF | ID | EX |
上面展示的指令流水线是完美的,然而实际情况往往没有这么理想。考虑这样一种情况,假设第二条指令依赖于第一条指令的执行结果,而第一条指令恰巧又是一个比较耗时的操作,那么整个流水线就停止了。即使第三条指令与前两条指令完全无关,它也必须等到第一条指令执行完成,流水线继续运转时才能得已执行。这就浪费了CPU的执行带宽。乱序执行(Out-Of-Order Execution)就是被用来解决这一问题的,它也是现代CPU提升执行效率的基础技术之一。
简单来说,乱序执行是指CPU提前分析待执行的指令,调整指令的执行顺序,以期发挥更高流水线执行效率的一种技术。引入乱序执行技术以后,CPU执行指令过程大概是下面这个样子:
所以,上面的程序出现(m, n)结果为(0, 0)的情况,应该就是因为指令的执行顺序被CPU重排了!
C++多线程内存模型
我们通常将读取操作称为load,存储操作称为store。对应的内存操作顺序有以下几种:
- load->load(读读)
- load->store(读写)
- store->load(写读)
- store->store(写写)
CPU在执行指令的时候,会根据情况对内存操作顺序进行重新排列。也就是说,我们只要能够让CPU不要进行指令重排优化,那么应该就不会出现(m, n)为(0, 0)的情况了。但具体要怎么做呢?
实际上,在C++11之前,我们很难在语言层面做到这件事情。那时的C++甚至连线程都不支持,更别提什么内存模型了。在C++98的年代,我们只能通过嵌入汇编的方式添加内存屏障来达到这样的目的:
asm volatile("mfence" ::: "memory");
不过在现代C++中,要做这样的事情就简单多了。C++11引入了原子类型(atomic),同时规定了6种内存执行顺序:
- memory_order_relaxed: 松散的,在保证原子性的前提下,允许进行任务的重新排序;
- memory_order_release: 代码中这条语句前的所有读写操作, 不允许被重排到这个操作之后;
- memory_order_acquire: 代码中这条语句后的所有读写操作,不允许被重排到这个操作之前;
- memory_order_consume: 代码中这条语句后所有与这块内存相关的读写操作,不允许被重排到这个操作之前;注意,这个类型已不建议被使用;
- memory_order_acq_rel: 对读取和写入施加acquire-release语义,无法被重排;
- memory_order_seq_cst: 顺序一致性,如果是写入就是release语义,如果是读取是acquire语义,如果是读取-写入就是acquire-release语义;也是原子变量的默认语义。
所以,我们只需要将x和y的类型改为atmioc_int,就可以避免m和n同时为0的结果出现了。修改后的代码如下:
#include <iostream>
#include <thread>
#include <atomic>
using namespace std;
atomic_int x(0);
atomic_int y(0);
int m = 0, n = 0;
int main()
{
while (1) {
x = y = 0;
thread t1([&]() { x = 1; m = y; });
thread t2([&]() { y = 1; n = x; });
t1.join(); t2.join();
if (m == 0 && n == 0) {
cout << " m == 0 && n == 0 ? impossible!\n";
}
}
return 0;
}
现在编译运行一下,看看结果:

已经不会再出现"impossible"的打印了。我们再来看看生成的汇编代码:

原来编译器已经自动帮我们插入了内存屏障,这样就再也不会出现(m, n)为(0, 0)的情况了。
全文完。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号