
1.继承


# 按照类的继承顺序,找下一个. class Foo(object): def f1(self): super().f1() print('3个功能') class Bar(object): def f1(self): print('6个功能') class Info(Foo,Bar): pass # obj = Foo() # obj.f1() #报错AttributeError: 'super' object has no attribute 'f1' obj = Info() obj.f1() #6个功能 #3个功能
2.class StarkConfig(object): list_display = [1,4] s1 = StarkConfig() s2 = StarkConfig() s1.list_display.append(3) print(s1.list_display) #[1, 4, 3] s2.list_display.append(9) print(s2.list_display) #[1, 4, 3, 9] # class StarkConfig(object): # list_display = 'dd' # s1 = StarkConfig() # s2 = StarkConfig() # s1.list_display = 'tt' # print(s1.list_display) #'tt' # print(s2.list_display) #'dd' class StarkConfig(object): list_display = 'dd's1 = StarkConfig()s2 = StarkConfig()StarkConfig.list_display = 'tt'print(s1.list_display) #'tt'print(s2.list_display) #'tt'
2.缩进
在缩进的时候,要么全部使用tab键,要么全部使用空格键。PEP8规范要求全部使用空格键,并且每层缩进使用2个空格,这个就要看每个公司的规范了。
3.异常处理(try...finally + return)
try...finally是用来捕获异常,并且不管有没有异常发生,都会执行finally中的代码。这样看起来会比较好理解,但是如果加上return语句,可能就会发生意想不到的事情。
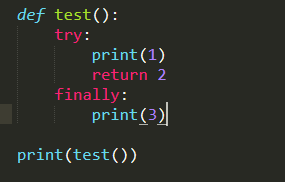
以上代码输出结果是1,3,2
如果try中包含了break、continue、return语句,在离开try块之前,会优先执行finally中的代码,然后才会执行return语句。这样就能理解,为什么结果是1,3,2了。
4.可变容器作为函数默认值
当我们在函数中使用了列表、字典等可变容器类型作为参数默认值的时候,会很容易出现问题。

我们可以看到,test()函数每执行一次,param这个列表中的值都会加1,这是因为默认参数会存储在函数的一个叫做__defaults__属性中,这个属性是函数属性,每次执行都是同一个对象,因此每次执行,param都会加一个新元素,并且还会保留之前添加的元素。正确的做法应该是把默认值设置成None,或者设置成不可变的数据类型,比如元组。
5.for...else...
这个语法可以说是Python独有的,他的作用是在for循环中每一项都循环到了,就会执行else,否则就不会执行else。举个例子:

因为0...9的所有数字都小于18,所以不执行到break,也就range中的每一项都执行到了。这时候就会执行else语句。但是如果我们把a改成8,就不会执行else中的语句了
6.Python闭包的变量
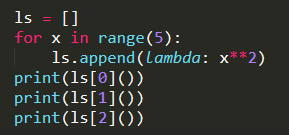
我们期望的结果应该是0,1,4,但实际上是16,16,16。原因是Python中的惰性求值。惰性求值,也就是延迟求值,表达式不会在它被绑定到变量之后就立即求值,而是等用到时再求值。x 实际不在 lambda 的作用域中。只有当 lambda 被调用时,x 的值才会被传给它。也就是最后的一次循环中 x 为 4,后面的 ls[1],ls[1],ls[2],ls[3]实际都是 16。
7.相同值的不可变对象
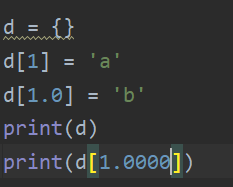
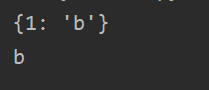
可以发现只有key为1,value为'b'的数据了。而原来的key为1,value为'a'的值凭空消失了。这是为什么呢?原因是Python字典是使用哈希表的思想实现的,Python 调用内部的散列函数,将键(Key)作为参数进行转换,得到一个唯一的地址,也就是哈希值。而Python 的哈希算法对相同的值计算得到的结果是一样的,这就很好地解释了上述情况出现的原因
8. is 和 ==
Python中的is代表两个对象的id值是否相同,而==则判断两个值是否相同。
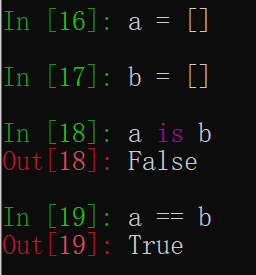
a和b都是一个空的列表,他们是存放到不同的内存空间,因此他们的id是不一样的,所以a is b为False,但是a==b是True,原因是他们两个的值是相等的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号