

中国爬虫违法违规案例汇总:
https://github.com/HiddenStrawberry/Crawler_Illegal_Cases_In_China


第一章 爬虫介绍 爬虫的分类 通用爬虫 聚焦爬虫 增量式爬虫 robots协议 反爬机制 反反爬策略 第二章 http和https协议 协议概念:基于clinet和server之间的一种通信协议 常用请求头信息: User-Agent:请求载体的身份标识 Connection: 常用响应头信息: Content-Type: 三种加密方式: 对称秘钥加密: 非对称秘钥加密: 证书加密: 第三章 requests模块 请求数据方式(两个方法+四种方式) UA伪装(反反爬策略) 爬取基于ajax请求数据的流程 使用抓包工具捕获ajax请求对应的数据包 从数据包中提取url和对应的请求参数 请求的发送(处理参数) 获取响应数据(json) response.json() 爬取图片数据的方式 urllib.request.urlretrive(url,filename) 实现模拟登陆 需要获取基于用户的用户信息 处理cookie(反反爬策略) requests.Session() 设置代理(反反爬策略) get(proxies = {'http/https':'ip:port'} ) 使用线程池(multiprocessing.dummy.Pool)实现数据爬取 pool = Pool(5) list = pool.map(func,list) 第四章 数据解析 正则解析 解析原理: 标签的定位 取数据 xpath解析 xpath插件 li.xpath('./') 数据加密-煎蛋网(反反爬策略) 爬取全国所有城市名称(xpath表达式的特殊使用 | ) 常见错误处理:HTTPConnectionPool(host:XX)Max retries exceeded with url ip被禁,连接池资源满了,请求频率过高 Connection:'close',使用代理ip,sleep bs4解析 soup.elementName find() findall() select('选择器') .string .text .get_text() ['href'] 第五章 验证码处理 第六章 动态数据加载 - selenium+phantomjs: - get(),find_xxx,click,send_keys() excute_script('js') - switch_to.frame(id):iframe 第七章 移动端数据爬取 第八章 scrapy框架基础+持久化存储 - name start_urls parse - 持久化存储方式: - 基于终端指令 - 基于管道: - 获取解析的数据 - 将解析的数据封装到item类型的对象中 - 向管道提交item - 在管道的process_item方法中执行持久化存储操作 - 在配置文件中开启管道 - 注意:process_item会被调用多次.process_item的返回值 第九章 递归解析和post请求 - 手动请求发送 -yield scrapy.Request(url,callback) - start_request():yield scrapy.FormRequest(url,callback,formdata) 第十章 日志等级和请求传参 - LOG_LEVEL LOG_FILE - 什么时候会用到请求传参:当解析的数据不在同一张页面的情况下. - scrapy.Request(url,callback,meta={}) - response.meta['key'] 第十一章 UA池和代理池 - 下载中间件:拦截请求和响应 - process_request(request): request.headers['User-Agent'] = 'xxxx' - process_response - process_exception: - request.meta['proxy'] = 'http://ip:port' 第十二章 scrapy中selenium的应用 - spider的init中实例化一个浏览器对象(bro) - spider的closed(self,spider)执行关闭浏览器操作 - 在中间件的process_response执行浏览器自动化的操作 (get,page_source) - 实例化一个新的响应对象 (scrapy.http.HTMLResponse(body=page_source)) - 返回响应对象 - 在配置文件中开启中间件 第十三章 全站数据爬取 - CrawlSpider:scrapy genspider -t crawl xxx www.xxx.com - 连接提取器:LinkExtactor(allow='xxxx') - 规则解析器:Rule(link,callback,follow=True) 第十四章 分布式爬虫 第十五章 增量式爬虫 ### 数据分析 - numpy - 切片 arr[index,col] - 变形:reshape() - 级联:concatnate() - 切分: - 排序: - Series - 过滤空值 - 去重:unique() - DataFrame - 创建 - 索引 - 取列: - 取行: - 取元素: - 切片: - 切列:df.loc[:,col] - 切行:df[] - 空值检测和过滤 - 空值检测函数: - isnull.any(axis) notnull.all(axis) - 空值过滤思路: - 空值过滤函数: - dropna(axis=0) - 检测重复行: - drop_duplicated(keep) - 覆盖空值: - fillna(method,axis) - 过滤重复行: - 随机取样: - take([3,1,2,0],axis=1) - random.permutation(5) - 级联机制: - 合并机制: - 替换:replace(to_replace,value) - 映射:map() 充当运算工具:s.map(func) apply() - 分组:df.groupby(by)['xxx'].mean() - 分组聚合: - df.groupby(by)['xxx'].apply(func) - 条件查询函数:df.query('')
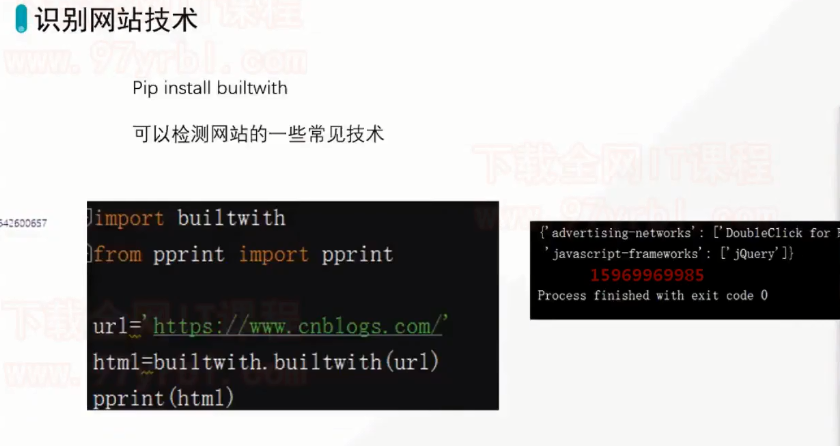
import builtwith from pprint import pprint url = 'https://www.cnblogs.com/' html = builtwith.builtwith(url) pprint(html)
当前我们所处的时代是大数据的时代,在大数据时代,要进行数据分析,首先要有数据源,而学习爬虫,可以让我们获取更多的数据源,并且这些数据源可以按我们的目的进行采集。
优酷推出的火星情报局就是基于网络爬虫和数据分析制作完成的。其中每期的节目话题都是从相关热门的互动平台中进行相关数据的爬取,然后对爬取到的数据进行数据分析而得来的。另一方面,优酷根据用户实时观看视频时的前进,后退等行为数据,能够推测计算出观众的兴趣点和爱好点,这样有助于节目的剪辑和后期的节目方案的编写。
今日头条作为一个新闻推荐类的应用,其内部的新闻数据都是通过爬虫程序在各个新闻网站进行新闻数据的爬取,然后通过相应的处理和运算将用户感兴趣的新闻话题推送到用户的手机上。
从就业的角度来说,爬虫工程师目前来说属于紧缺人才,并且薪资待遇普遍较高;所以,深层次地掌握这门技术,对于就业来说,是非常有利的。有些人学习爬虫可能为了就业或者跳槽。从这个角度来说,爬虫工程师是不错的选择之一。随着大数据时代的来临,爬虫技术的应用将越来越广泛,在未来会拥有更好的发展空间。
目录:
- 爬虫简介
- 爬虫分类
- robots协议
- 反爬机制
- 反反爬机制
-
什么是爬虫
爬虫就是通过编写程序模拟浏览器上网,然后让其去互联网上抓取数据的过程。 -
哪些语言可以实现爬虫
1.php:可以实现爬虫。php被号称是全世界最优美的语言(当然是其自己号称的,就是王婆卖瓜的意思),但是php在实现爬虫中支持多线程和多进程方面做的不好。
2.java:可以实现爬虫。java可以非常好的处理和实现爬虫,是唯一可以与python并驾齐驱且是python的头号劲敌。但是java实现爬虫代码较为臃肿,重构成本较大。
3.c、c++:可以实现爬虫。但是使用这种方式实现爬虫纯粹是是某些人(大佬们)能力的体现,却不是明智和合理的选择。
4.python:可以实现爬虫。python实现和处理爬虫语法简单,代码优美,支持的模块繁多,学习成本低,具有非常强大的框架(scrapy等)且一句难以言表的好!没有但是!
-
爬虫的分类
1.通用爬虫:通用爬虫是搜索引擎(Baidu、Google、Yahoo等)“抓取系统”的重要组成部分。主要目的是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份。 简单来讲就是尽可能的,把互联网上的所有的网页下载下来,放到本地服务器里形成备份,在对这些网页做相关处理(提取关键字、去掉广告),最后提供一个用户检索接口。- 搜索引擎如何抓取互联网上的网站数据?
- 门户网站主动向搜索引擎公司提供其网站的url
- 搜索引擎公司与DNS服务商合作,获取网站的url
- 门户网站主动挂靠在一些知名网站的友情链接中
- 搜索引擎如何抓取互联网上的网站数据?
2.聚焦爬虫:聚焦爬虫是根据指定的需求抓取网络上指定的数据。例如:获取豆瓣上电影的名称和影评,而不是获取整张页面中所有的数据值。
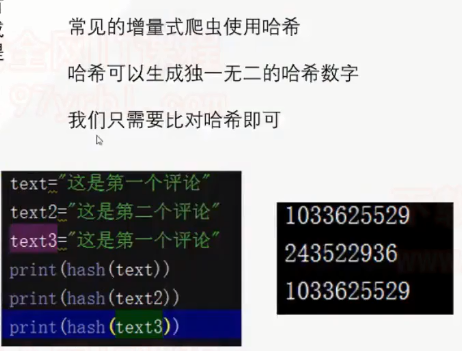
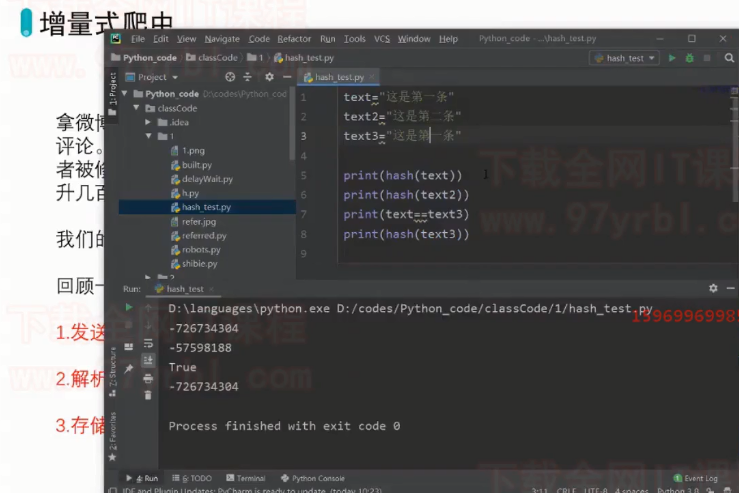
3.增量式爬虫:


-
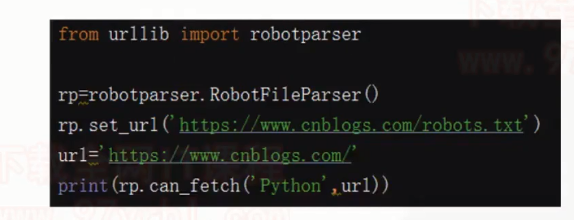
robots.txt协议
- 如果自己的门户网站中的指定页面中的数据不想让爬虫程序爬取到的话,那么则可以通过编写一个robots.txt的协议文件来约束爬虫程序的数据爬取。robots协议的编写格式可以观察淘宝网的robots(访问www.taobao.com/robots.txt即可)。但是需要注意的是,该协议只是相当于口头的协议,并没有使用相关技术进行强制管制,所以该协议是防君子不防小人。但是我们在学习爬虫阶段编写的爬虫程序可以先忽略robots协议。 ![]()
![]()
-
反爬虫机制
- 门户网站通过相应的策略和技术手段,防止爬虫程序进行网站数据的爬取。 -
反反爬虫机制
- 爬虫程序通过相应的策略和技术手段,破解门户网站的反爬虫手段,从而爬取到相应的数据。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号