

百度AI开放平台官网:http://ai.baidu.com/?track=cp:aipinzhuan|pf:pc|pp:AIpingtai|pu:title|ci:|kw:10005792
pip3 install baidu-aip
百度AI的使用:
1、首先创建应用:

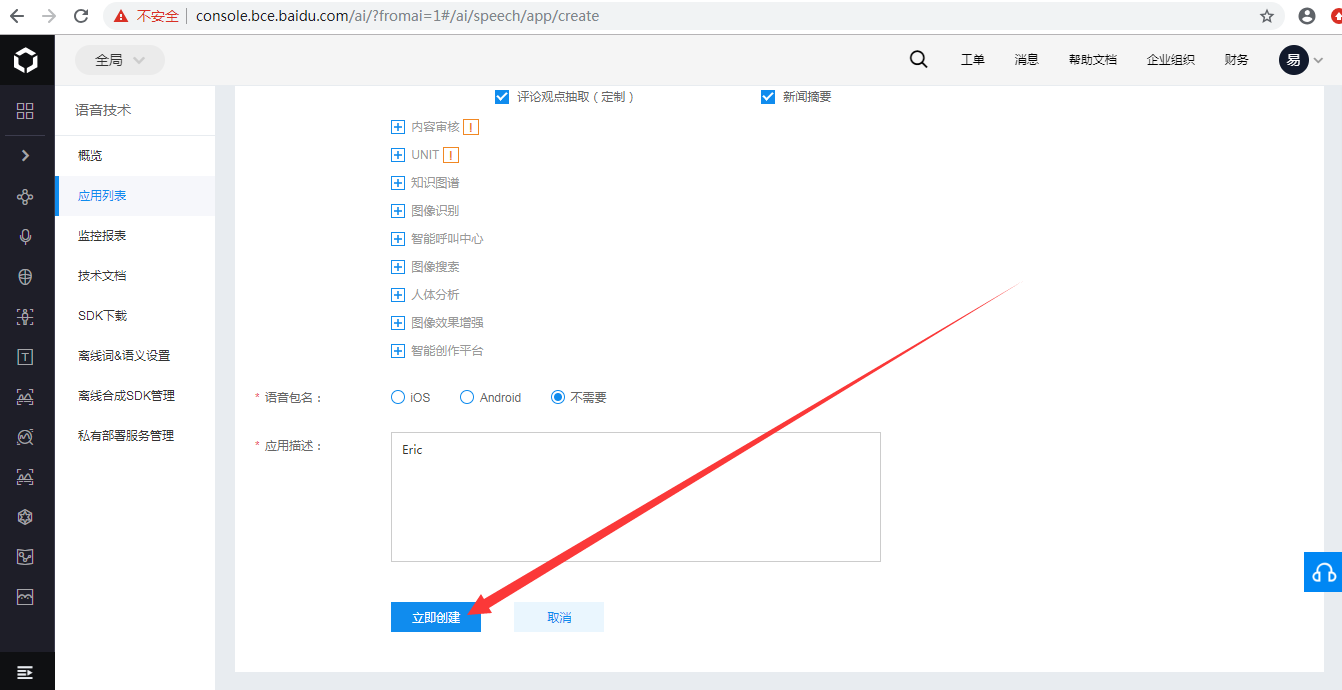
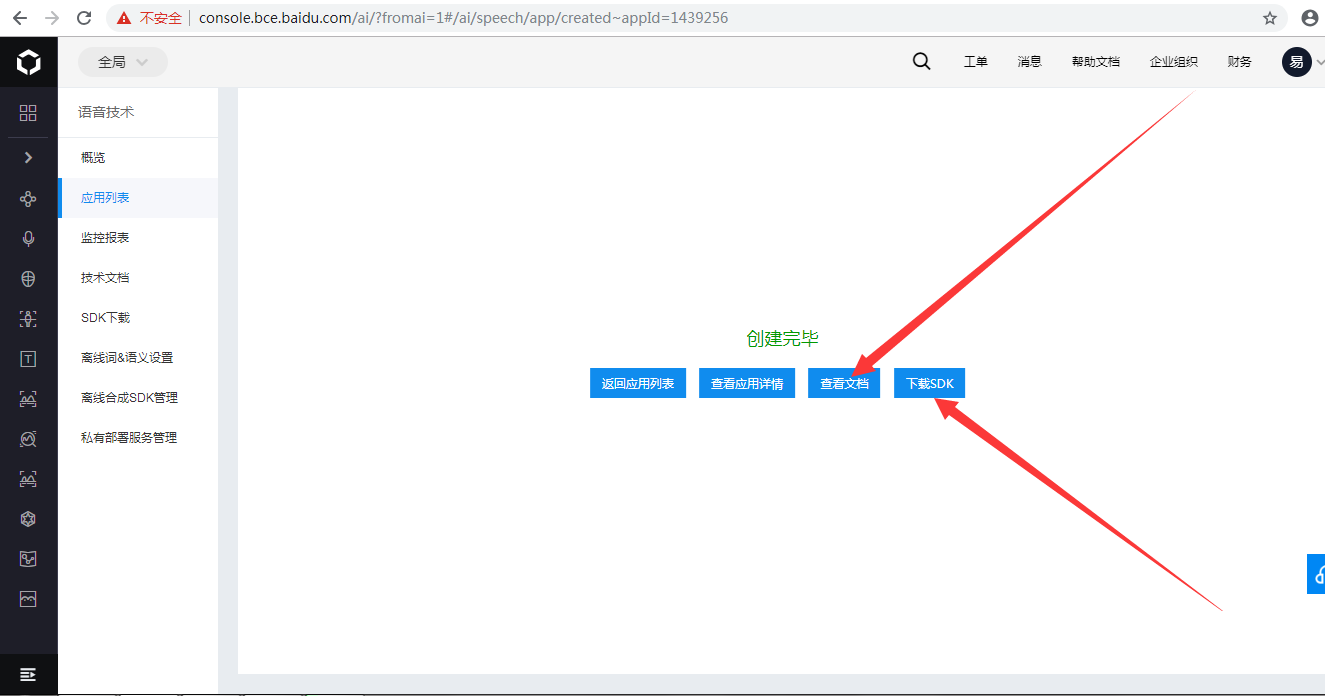
2、使用方法可以查看文档:

3、各功能的使用
3.1 语言合成:


from aip import AipSpeech """ 你的 APPID AK SK """ APP_ID = '15420336' API_KEY = 'VwSGcqqwsCl282LGKnFwHDIA' SECRET_KEY = 'h4oL6Y9yRuvmD0oSdQGQZchNcix4TF5P' client = AipSpeech(APP_ID, API_KEY, SECRET_KEY) result = client.synthesis('先帝创业未半而中道崩殂', 'zh', 1, { 'vol': 5, "spd": 3, "pit": 7, "per": 4 }) print(result) # 识别正确返回语音二进制 错误则返回dict 参照下面错误码 if not isinstance(result, dict): with open('audio.mp3', 'wb') as f: f.write(result)
Python使用 语言合成 文档:

3.1.1 简介
Hi,您好,欢迎使用百度语音合成服务。
本文档主要针对Python开发者,描述百度语音合成接口服务的相关技术内容。如果您对文档内容有任何疑问,可以通过以下几种方式联系我们:
- 在百度云控制台内提交工单,咨询问题类型请选择人工智能服务;
- 加入开发者QQ群:910926227
接口能力
| 接口名称 | 接口能力简要描述 |
|---|---|
| 语音合成 | 将计算机自己产生的、或外部输入的文字信息转变为可以听得懂的、流利的口语输出的技术。 |
注意事项
目前本SDK的功能同REST API,需要联网调用http接口 。REST API 仅支持最多512字(1024 字节)的音频合成,合成的文件格式为mp3。没有其他额外功能。 如果需要使用离线合成等其它功能,请使用Android或者iOS 合成 SDK
请严格按照文档里描述的参数进行开发。请注意以下几个问题:
- 合成文本长度必须小于1024字节,如果本文长度较长,可以采用多次请求的方式。切忌文本长度超过限制。
2.新创建语音合成应用不限制每日调用量,但有QPS限额。详细限额数据可在控制台中查看。完成个人实名认证及企业认证可提高QPS限额。若需更大QPS可进一步商务合作咨询。
- 必填字段中,严格按照文档描述中内容填写。
版本更新记录
| 上线日期 | 版本号 | 更新内容 |
|---|---|---|
| 2017.5.11 | 1.0.0 | 语音合成服务上线 |
3.1.2 快速入门
安装语音合成 Python SDK
语音合成 Python SDK目录结构
├── README.md
├── aip //SDK目录
│ ├── __init__.py //导出类
│ ├── base.py //aip基类
│ ├── http.py //http请求
│ └── speech.py //语音合成
└── setup.py //setuptools安装支持Python版本:2.7.+ ,3.+
安装使用Python SDK有如下方式:
- 如果已安装pip,执行
pip install baidu-aip即可。 - 如果已安装setuptools,执行
python setup.py install即可。
新建AipSpeech
AipSpeech是语音合成的Python SDK客户端,为使用语音合成的开发人员提供了一系列的交互方法。
参考如下代码新建一个AipSpeech:
from aip import AipSpeech
""" 你的 APPID AK SK """
APP_ID = '你的 App ID'
API_KEY = '你的 Api Key'
SECRET_KEY = '你的 Secret Key'
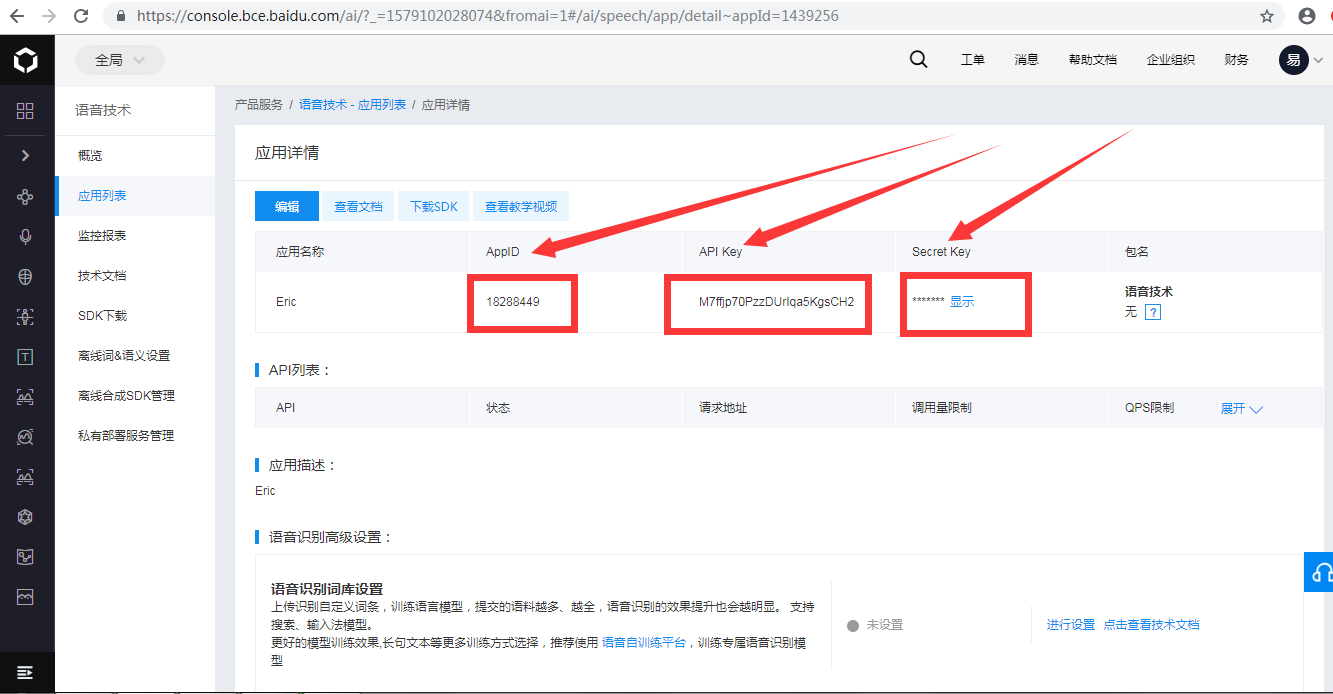
client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)在上面代码中,常量APP_ID在百度云控制台中创建,常量API_KEY与SECRET_KEY是在创建完毕应用后,系统分配给用户的,均为字符串,用于标识用户,为访问做签名验证,可在AI服务控制台中的应用列表中查看。
配置AipSpeech
如果用户需要配置AipSpeech的网络请求参数(一般不需要配置),可以在构造AipSpeech之后调用接口设置参数,目前只支持以下参数:
| 接口 | 说明 |
|---|---|
| setConnectionTimeoutInMillis | 建立连接的超时时间(单位:毫秒 |
| setSocketTimeoutInMillis | 通过打开的连接传输数据的超时时间(单位:毫秒) |
3.1.3 接口说明
语音合成
接口描述
基于该接口,开发者可以轻松的获取语音合成能力
请求说明
- 合成文本长度必须小于1024字节,如果本文长度较长,可以采用多次请求的方式。文本长度不可超过限制
举例,要把一段文字合成为语音文件:
result = client.synthesis('你好百度', 'zh', 1, {
'vol': 5,
})
# 识别正确返回语音二进制 错误则返回dict 参照下面错误码
if not isinstance(result, dict):
with open('auido.mp3', 'wb') as f:
f.write(result)| 参数 | 类型 | 描述 | 是否必须 |
|---|---|---|---|
| tex | String | 合成的文本,使用UTF-8编码, 请注意文本长度必须小于1024字节 |
是 |
| cuid | String | 用户唯一标识,用来区分用户, 填写机器 MAC 地址或 IMEI 码,长度为60以内 |
否 |
| spd | String | 语速,取值0-9,默认为5中语速 | 否 |
| pit | String | 音调,取值0-9,默认为5中语调 | 否 |
| vol | String | 音量,取值0-15,默认为5中音量 | 否 |
| per | String | 发音人选择, 0为女声,1为男声, 3为情感合成-度逍遥,4为情感合成-度丫丫,默认为普通女 |
否 |
返回样例:
// 成功返回二进制文件流
// 失败返回
{
"err_no":500,
"err_msg":"notsupport.",
"sn":"abcdefgh",
"idx":1
}3.1.4 错误信息
错误返回格式
若请求错误,服务器将返回的JSON文本包含以下参数:
- error_code:错误码。
- error_msg:错误描述信息,帮助理解和解决发生的错误。
错误码
| 错误码 | 含义 |
|---|---|
| 500 | 不支持的输入 |
| 501 | 输入参数不正确 |
| 502 | token验证失败 |
| 503 | 合成后端错误 |
3.2 语言识别
from aip import AipSpeech import os """ 你的 APPID AK SK """ APP_ID = '15420336' API_KEY = 'VwSGcqqwsCl282LGKnFwHDIA' SECRET_KEY = 'h4oL6Y9yRuvmD0oSdQGQZchNcix4TF5P' client = AipSpeech(APP_ID, API_KEY, SECRET_KEY) # 读取文件 def get_file_content(filePath): os.system(f"ffmpeg -y -i {filePath} -acodec pcm_s16le -f s16le -ac 1 -ar 16000 {filePath}.pcm") with open(f"{filePath}.pcm", 'rb') as fp: return fp.read() # 识别本地文件 res = client.asr(get_file_content('wyn.wma'), 'pcm', 16000, { 'dev_pid': 1536, }) print(res.get("result")[0])
Python使用 语言识别 文档:
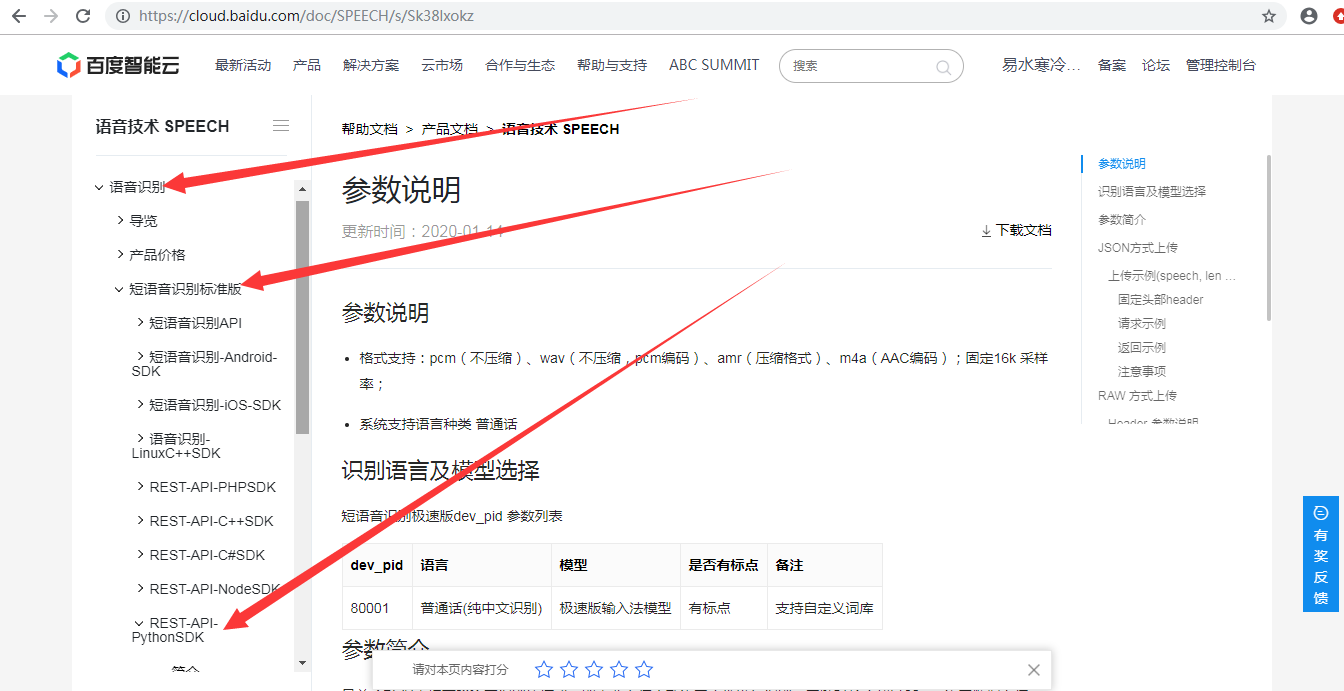
音频处理工具

3.2.1 简介
目前本SDK的功能同REST API,需要联网调用http接口, 具体功能见REST API 文档, REST API 仅支持整段语音识别的模式,即需要上传完整语音文件进行识别,时长不超过60s,支持、自定义词库设置, 没有其他额外功能。
接口能力
| 接口名称 | 接口能力简要描述 |
|---|---|
| 语音识别 | 将人类的语音中的词汇内容转换为计算机可读的输入,例如按键、二进制编码或者字符序列 |
支持的语音格式
原始 PCM 的录音参数必须符合 16k 采样率、16bit 位深、单声道,支持的格式有:pcm(不压缩)、wav(不压缩,pcm编码)、amr(压缩格式)。
注意事项
如果需要使用实时识别、长语音、唤醒词、语义解析等其它语音功能,请使用Android或者iOS SDK 或 Linux C++ SDK 等。
- 请严格按照文档里描述的参数进行开发,特别请关注原始录音参数以及语音压缩格式的建议,否则会影响识别率,进而影响到产品的用户体验。
- 目前系统支持的语音时长上限为60s,请不要超过这个长度,否则会返回错误。
反馈
- 在百度云控制台内提交工单,咨询问题类型请选择人工智能服务;
- QQ群快速沟通: AI开放平台官网首页底部“QQ支持群”中,查找“百度语音”。
版本更新记录
| 上线日期 | 版本号 | 更新内容 |
|---|---|---|
| 2017.5.11 | 1.0.0 | 语音识别服务上线 |
3.2.2 快速入门
安装语音识别 Python SDK
语音识别 Python SDK目录结构
├── README.md
├── aip //SDK目录
│ ├── __init__.py //导出类
│ ├── base.py //aip基类
│ ├── http.py //http请求
│ └── speech.py //语音识别
└── setup.py //setuptools安装支持Python版本:2.7.+ ,3.+
安装使用Python SDK有如下方式:
- 如果已安装pip,执行
pip install baidu-aip即可。 - 如果已安装setuptools,执行
python setup.py install即可。
新建AipSpeech
AipSpeech是语音识别的Python SDK客户端,为使用语音识别的开发人员提供了一系列的交互方法。
参考如下代码新建一个AipSpeech:
from aip import AipSpeech
""" 你的 APPID AK SK """
APP_ID = '你的 App ID'
API_KEY = '你的 Api Key'
SECRET_KEY = '你的 Secret Key'
client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)在上面代码中,常量APP_ID在百度云控制台中创建,常量API_KEY与SECRET_KEY是在创建完毕应用后,系统分配给用户的,均为字符串,用于标识用户,为访问做签名验证,可在AI服务控制台中的应用列表中查看。
配置AipSpeech
如果用户需要配置AipSpeech的网络请求参数(一般不需要配置),可以在构造AipSpeech之后调用接口设置参数,目前只支持以下参数:
| 接口 | 说明 |
|---|---|
| setConnectionTimeoutInMillis | 建立连接的超时时间(单位:毫秒 |
| setSocketTimeoutInMillis | 通过打开的连接传输数据的超时时间(单位:毫秒) |
3.2.3 接口说明
语音识别
接口描述
向远程服务上传整段语音进行识别
请求说明
举例,要对段保存有一段语音的语音文件进行识别:
# 读取文件
def get_file_content(filePath):
with open(filePath, 'rb') as fp:
return fp.read()
# 识别本地文件
client.asr(get_file_content('audio.pcm'), 'pcm', 16000, {
'dev_pid': 1536,
})| 参数 | 类型 | 描述 | 是否必须 |
|---|---|---|---|
| speech | Buffer | 建立包含语音内容的Buffer对象, 语音文件的格式,pcm 或者 wav 或者 amr。不区分大小写 | 是 |
| format | String | 语音文件的格式,pcm 或者 wav 或者 amr。不区分大小写。推荐pcm文件 | 是 |
| rate | int | 采样率,16000,固定值 | 是 |
| cuid | String | 用户唯一标识,用来区分用户,填写机器 MAC 地址或 IMEI 码,长度为60以内 | 否 |
| dev_pid | Int | 不填写lan参数生效,都不填写,默认1537(普通话 输入法模型),dev_pid参数见本节开头的表格 | 否 |
| lan(已废弃) | String | 历史兼容参数,请使用dev_pid。如果dev_pid填写,该参数会被覆盖。语种选择,输入法模型,默认中文(zh)。 中文=zh、粤语=ct、英文=en,不区分大小写。 | 否 |
dev_pid 参数列表
| dev_pid | 语言 | 模型 | 是否有标点 | 备注 |
|---|---|---|---|---|
| 1536 | 普通话(支持简单的英文识别) | 搜索模型 | 无标点 | 支持自定义词库 |
| 1537 | 普通话(纯中文识别) | 输入法模型 | 有标点 | 支持自定义词库 |
| 1737 | 英语 | 无标点 | 不支持自定义词库 | |
| 1637 | 粤语 | 有标点 | 不支持自定义词库 | |
| 1837 | 四川话 | 有标点 | 不支持自定义词库 | |
| 1936 | 普通话远场 | 远场模型 | 有标点 | 不支持 |
语音识别 返回数据参数详情
| 参数 | 类型 | 是否一定输出 | 描述 |
|---|---|---|---|
| err_no | int | 是 | 错误码 |
| err_msg | int | 是 | 错误码描述 |
| sn | int | 是 | 语音数据唯一标识,系统内部产生,用于 debug |
| result | int | 是 | 识别结果数组,提供1-5 个候选结果,string 类型为识别的字符串, utf-8 编码 |
返回样例:
// 成功返回
{
"err_no": 0,
"err_msg": "success.",
"corpus_no": "15984125203285346378",
"sn": "481D633F-73BA-726F-49EF-8659ACCC2F3D",
"result": ["北京天气"]
}
// 失败返回
{
"err_no": 2000,
"err_msg": "data empty.",
"sn": null
}3.2.4 错误信息
错误返回格式
若请求错误,服务器将返回的JSON文本包含以下参数:
- error_code:错误码。
- error_msg:错误描述信息,帮助理解和解决发生的错误。
错误码
| 错误码 | 用户输入/服务端 | 含义 | 一般解决方法 |
|---|---|---|---|
| 3300 | 用户输入错误 | 输入参数不正确 | 请仔细核对文档及参照demo,核对输入参数 |
| 3301 | 用户输入错误 | 音频质量过差 | 请上传清晰的音频 |
| 3302 | 用户输入错误 | 鉴权失败 | token字段校验失败。请使用正确的API_KEY 和 SECRET_KEY生成。或QPS、调用量超出限额。或音频采样率不正确(可尝试更换为16k采样率)。 |
| 3303 | 服务端问题 | 语音服务器后端问题 | 请将api返回结果反馈至论坛或者QQ群 |
| 3304 | 用户请求超限 | 用户的请求QPS超限 | 请降低识别api请求频率 (qps以appId计算,移动端如果共用则累计) |
| 3305 | 用户请求超限 | 用户的日pv(日请求量)超限 | 请“申请提高配额”,如果暂未通过,请降低日请求量 |
| 3307 | 服务端问题 | 语音服务器后端识别出错问题 | 目前请确保16000的采样率音频时长低于30s。如果仍有问题,请将api返回结果反馈至论坛或者QQ群 |
| 3308 | 用户输入错误 | 音频过长 | 音频时长不超过60s,请将音频时长截取为60s以下 |
| 3309 | 用户输入错误 | 音频数据问题 | 服务端无法将音频转为pcm格式,可能是长度问题,音频格式问题等。 请将输入的音频时长截取为60s以下,并核对下音频的编码,是否是16K, 16bits,单声道。 |
| 3310 | 用户输入错误 | 输入的音频文件过大 | 语音文件共有3种输入方式: json 里的speech 参数(base64后); 直接post 二进制数据,及callback参数里url。 分别对应三种情况:json超过10M;直接post的语音文件超过10M;callback里回调url的音频文件超过10M |
| 3311 | 用户输入错误 | 采样率rate参数不在选项里 | 目前rate参数仅提供16000,填写4000即会有此错误 |
| 3312 | 用户输入错误 | 音频格式format参数不在选项里 | 目前格式仅仅支持pcm,wav或amr,如填写mp3即会有此错误 |
错误码常见问题及具体分析
3300 错误
语音识别api使用的是HTTP POST方法, BODY里直接放置json, Content-Type头部为 application/json。 并非常见的浏览器表单请求(application/x-www-form-urlencoded或者multipart/x-www-form-urlencoded)。
必填字段:format rate channel cuid token cuid token cuid token cuid token,请勿漏填。此外 (speech, len) 及 (url, callback) 这两组参数必须二选一,如果都填,默认处理第一组。 channel cuid token,请勿漏填。此外 (speech, len) 及 (url, callback) 这两组参数必须二选一,如果都填,默认处理第一种。 channel cuid token,请勿漏填。此外 (speech, len) 及 (url, callback) 这两组参数必须二选一,如果都填,默认处理第一种。
必填字段如format rate channel cuid token,请勿漏填。此外 (speech, len) 及 (url, callback) 这两组参数必须二选一,如果都填,默认处理第一种,并确认 音频时长截取为60s以下。
3309错误
wav和amr的音频,服务端会自动转为pcm,这个过程中导致转码出错。请确认下format及rate参数与音频一致,并确认音频时长截取为60s以下。
3301 错误
识别结果实际为空。可能是音频质量过差,不清晰,或者是空白音频。 有时也可能是pcm填错采样率。如16K采样率的pcm文件,填写的rate参数为8000。
行业与场景限制 根据工信部《综合整治骚扰电话专项行动方案》、《关于推进综合整治骚扰电话专项行动的工作方案》,相关能力不得用于商业营销类、恶意骚扰类和违法犯罪类骚扰电话类场景,也不支持在贷款、理财、信用卡、股票、基金、债券、保险、售房租房、医疗机构、保健食品、人力资源服务、旅游等场景的骚扰电话营销行为。
基于 语言合成 和 语言识别 可以做一个 机器学我们说话 功能:
from aip import AipSpeech import time,os """ 你的 APPID AK SK """ APP_ID = '15420336' API_KEY = 'VwSGcqqwsCl282LGKnFwHDIA' SECRET_KEY = 'h4oL6Y9yRuvmD0oSdQGQZchNcix4TF5P' client = AipSpeech(APP_ID, API_KEY, SECRET_KEY) # 读取文件 def get_file_content(filePath): os.system(f"ffmpeg -y -i {filePath} -acodec pcm_s16le -f s16le -ac 1 -ar 16000 {filePath}.pcm") with open(f"{filePath}.pcm", 'rb') as fp: return fp.read() def audio2text(filepath): # 识别本地文件 res = client.asr(get_file_content(filepath), 'pcm', 16000, { 'dev_pid': 1536, }) print(res.get("result")[0]) return res.get("result")[0] def text2audio(text): filename = f"{time.time()}.mp3" result = client.synthesis(text, 'zh', 1, { 'vol': 5, "spd": 3, "pit": 7, "per": 4 }) # 识别正确返回语音二进制 错误则返回dict 参照下面错误码 if not isinstance(result, dict): with open(filename, 'wb') as f: f.write(result) return filename text = audio2text("wyn.wma") filename = text2audio(text) os.system(filename)
3.3 自然语言处理技术

短文本相似度NLP
from aip import AipSpeech,AipNlp import time,os """ 你的 APPID AK SK """ APP_ID = '15420336' API_KEY = 'VwSGcqqwsCl282LGKnFwHDIA' SECRET_KEY = 'h4oL6Y9yRuvmD0oSdQGQZchNcix4TF5P' nlp = AipNlp(APP_ID, API_KEY, SECRET_KEY) #短文本相似度 client = AipSpeech(APP_ID, API_KEY, SECRET_KEY) # 读取文件 def get_file_content(filePath): os.system(f"ffmpeg -y -i {filePath} -acodec pcm_s16le -f s16le -ac 1 -ar 16000 {filePath}.pcm") with open(f"{filePath}.pcm", 'rb') as fp: return fp.read() def audio2text(filepath): # 识别本地文件 res = client.asr(get_file_content(filepath), 'pcm', 16000, { 'dev_pid': 1536, }) print(res.get("result")[0]) return res.get("result")[0] def text2audio(text): filename = f"{time.time()}.mp3" result = client.synthesis(text, 'zh', 1, { 'vol': 5, "spd": 3, "pit": 7, "per": 4 }) # 识别正确返回语音二进制 错误则返回dict 参照下面错误码 if not isinstance(result, dict): with open(filename, 'wb') as f: f.write(result) return filename def to_tuling(text): import requests args = { "reqType": 0, "perception": { "inputText": { "text": text } }, "userInfo": { "apiKey": "9a9a026e2eb64ed6b006ad99d27f6b9e", "userId": "1111" } } url = "http://openapi.tuling123.com/openapi/api/v2" res = requests.post(url, json=args) text = res.json().get("results")[0].get("values").get("text") return text # res = nlp.simnet("你叫什么名字","你的名字是什么") # print(res) text = audio2text("bjtq.wma") # 短文本相似度 if nlp.simnet("你叫什么名字",text).get("score") >= 0.68 : text = "我的名字叫银角大王8" else: text = to_tuling(text) filename = text2audio(text) os.system(filename)

图灵机器人官网:http://www.tuling123.com/
基于 语言合成 和 语言识别 以及 自然语言的短文本相似度 还有 图灵机器人 做一个 机器智能回答问题 的功能:
简易版:
from aip import AipSpeech,AipNlp import time,os """ 你的 APPID AK SK """ APP_ID = '15420336' API_KEY = 'VwSGcqqwsCl282LGKnFwHDIA' SECRET_KEY = 'h4oL6Y9yRuvmD0oSdQGQZchNcix4TF5P' nlp = AipNlp(APP_ID, API_KEY, SECRET_KEY) client = AipSpeech(APP_ID, API_KEY, SECRET_KEY) # 读取文件 def get_file_content(filePath): os.system(f"ffmpeg -y -i {filePath} -acodec pcm_s16le -f s16le -ac 1 -ar 16000 {filePath}.pcm") with open(f"{filePath}.pcm", 'rb') as fp: return fp.read() def audio2text(filepath): # 识别本地文件 res = client.asr(get_file_content(filepath), 'pcm', 16000, { 'dev_pid': 1536, }) print(res.get("result")[0]) return res.get("result")[0] def text2audio(text): filename = f"{time.time()}.mp3" result = client.synthesis(text, 'zh', 1, { 'vol': 5, "spd": 3, "pit": 7, "per": 4 }) # 识别正确返回语音二进制 错误则返回dict 参照下面错误码 if not isinstance(result, dict): with open(filename, 'wb') as f: f.write(result) return filename def to_tuling(text): import requests args = { "reqType": 0, "perception": { "inputText": { "text": text } }, "userInfo": { "apiKey": "9a9a026e2eb64ed6b006ad99d27f6b9e", "userId": "1111" } } url = "http://openapi.tuling123.com/openapi/api/v2" res = requests.post(url, json=args) text = res.json().get("results")[0].get("values").get("text") return text # res = nlp.simnet("你叫什么名字","你的名字是什么") # print(res) text = audio2text("bjtq.wma") if nlp.simnet("你叫什么名字",text).get("score") >= 0.68 : text = "我的名字叫银角大王8" else: text = to_tuling(text) filename = text2audio(text) os.system(filename)
完善版:
from flask import Flask,render_template,request,jsonify,send_file from uuid import uuid4 import baidu_ai app = Flask(__name__) @app.route("/") def index(): return render_template("index.html") @app.route("/ai",methods=["POST"]) def ai(): # 1.保存录音文件 audio = request.files.get("record") filename = f"{uuid4()}.wav" audio.save(filename) #2.将录音文件转换为PCM发送给百度进行语音识别 q_text = baidu_ai.audio2text(filename) #3.将识别的问题交给图灵或自主处理获取答案 a_text = baidu_ai.to_tuling(q_text) #4.将答案发送给百度语音合成,合成音频文件 a_file = baidu_ai.text2audio(a_text) #5.将音频文件发送给前端播放 return jsonify({"filename":a_file}) @app.route("/get_audio/<filename>") def get_audio(filename): return send_file(filename) if __name__ == '__main__': app.run("0.0.0.0",9527,debug=True)
from aip import AipSpeech,AipNlp import time,os """ 你的 APPID AK SK """ APP_ID = '15420336' API_KEY = 'VwSGcqqwsCl282LGKnFwHDIA' SECRET_KEY = 'h4oL6Y9yRuvmD0oSdQGQZchNcix4TF5P' nlp = AipNlp(APP_ID, API_KEY, SECRET_KEY) client = AipSpeech(APP_ID, API_KEY, SECRET_KEY) # 读取文件 def get_file_content(filePath): os.system(f"ffmpeg -y -i {filePath} -acodec pcm_s16le -f s16le -ac 1 -ar 16000 {filePath}.pcm") with open(f"{filePath}.pcm", 'rb') as fp: return fp.read() def audio2text(filepath): # 识别本地文件 res = client.asr(get_file_content(filepath), 'pcm', 16000, { 'dev_pid': 1536, }) print(res.get("result")[0]) return res.get("result")[0] def text2audio(text): filename = f"{time.time()}.mp3" result = client.synthesis(text, 'zh', 1, { 'vol': 5, "spd": 3, "pit": 7, "per": 4 }) # 识别正确返回语音二进制 错误则返回dict 参照下面错误码 if not isinstance(result, dict): with open(filename, 'wb') as f: f.write(result) return filename def to_tuling(text): import requests args = { "reqType": 0, "perception": { "inputText": { "text": text } }, "userInfo": { "apiKey": "9a9a026e2eb64ed6b006ad99d27f6b9e", "userId": "1111" } } url = "http://openapi.tuling123.com/openapi/api/v2" res = requests.post(url, json=args) text = res.json().get("results")[0].get("values").get("text") print("图灵答案",text) return text
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Title</title> </head> <body> <audio controls autoplay id="player"></audio> <p> <button onclick="start_reco()" style="background-color: yellow">录制语音指令</button> </p> <p> <button onclick="stop_reco_audio()" style="background-color: blue">发送语音指令</button> </p> </body> <!--<script type="application/javascript" src="/static/Recorder.js"></script>--> <script type="application/javascript" src="https://cdn.bootcss.com/recorderjs/0.1.0/recorder.js"></script> <script type="text/javascript" src="/static/jQuery3.1.1.js"></script> <script type="text/javascript"> var reco = null; var audio_context = new AudioContext(); navigator.getUserMedia = (navigator.getUserMedia || navigator.webkitGetUserMedia || navigator.mozGetUserMedia || navigator.msGetUserMedia); navigator.getUserMedia({audio: true}, create_stream, function (err) { console.log(err) }); function create_stream(user_media) { var stream_input = audio_context.createMediaStreamSource(user_media); reco = new Recorder(stream_input); } function start_reco() { reco.record(); } function stop_reco_audio() { reco.stop(); send_audio(); reco.clear(); } function send_audio() { reco.exportWAV(function (wav_file) { var formdata = new FormData(); formdata.append("record", wav_file); console.log(formdata); $.ajax({ url: "http://192.168.13.42:9527/ai", type: 'post', processData: false, contentType: false, data: formdata, dataType: 'json', success: function (data) { document.getElementById("player").src ="http://192.168.13.42:9527/get_audio/" + data.filename } }); }) } </script> </html>
bootsdn download
(function(f){if(typeof exports==="object"&&typeof module!=="undefined"){module.exports=f()}else if(typeof define==="function"&&define.amd){define([],f)}else{var g;if(typeof window!=="undefined"){g=window}else if(typeof global!=="undefined"){g=global}else if(typeof self!=="undefined"){g=self}else{g=this}g.Recorder = f()}})(function(){var define,module,exports;return (function e(t,n,r){function s(o,u){if(!n[o]){if(!t[o]){var a=typeof require=="function"&&require;if(!u&&a)return a(o,!0);if(i)return i(o,!0);var f=new Error("Cannot find module '"+o+"'");throw f.code="MODULE_NOT_FOUND",f}var l=n[o]={exports:{}};t[o][0].call(l.exports,function(e){var n=t[o][1][e];return s(n?n:e)},l,l.exports,e,t,n,r)}return n[o].exports}var i=typeof require=="function"&&require;for(var o=0;o<r.length;o++)s(r[o]);return s})({1:[function(require,module,exports){
"use strict";
module.exports = require("./Recorder").Recorder;
},{"./recorder":2}],2:[function(require,module,exports){
'use strict';
var _createClass = (function () {
function defineProperties(target, props) {
for (var i = 0; i < props.length; i++) {
var descriptor = props[i];descriptor.enumerable = descriptor.enumerable || false;descriptor.configurable = true;if ("value" in descriptor) descriptor.writable = true;Object.defineProperty(target, descriptor.key, descriptor);
}
}return function (Constructor, protoProps, staticProps) {
if (protoProps) defineProperties(Constructor.prototype, protoProps);if (staticProps) defineProperties(Constructor, staticProps);return Constructor;
};
})();
Object.defineProperty(exports, "__esModule", {
value: true
});
exports.Recorder = undefined;
var _inlineWorker = require('inline-worker');
var _inlineWorker2 = _interopRequireDefault(_inlineWorker);
function _interopRequireDefault(obj) {
return obj && obj.__esModule ? obj : { default: obj };
}
function _classCallCheck(instance, Constructor) {
if (!(instance instanceof Constructor)) {
throw new TypeError("Cannot call a class as a function");
}
}
var Recorder = exports.Recorder = (function () {
function Recorder(source, cfg) {
var _this = this;
_classCallCheck(this, Recorder);
this.config = {
bufferLen: 4096,
numChannels: 2,
mimeType: 'audio_pcm/wav'
};
this.recording = false;
this.callbacks = {
getBuffer: [],
exportWAV: []
};
Object.assign(this.config, cfg);
this.context = source.context;
this.node = (this.context.createScriptProcessor || this.context.createJavaScriptNode).call(this.context, this.config.bufferLen, this.config.numChannels, this.config.numChannels);
this.node.onaudioprocess = function (e) {
if (!_this.recording) return;
var buffer = [];
for (var channel = 0; channel < _this.config.numChannels; channel++) {
buffer.push(e.inputBuffer.getChannelData(channel));
}
_this.worker.postMessage({
command: 'record',
buffer: buffer
});
};
source.connect(this.node);
this.node.connect(this.context.destination); //this should not be necessary
var self = {};
this.worker = new _inlineWorker2.default(function () {
var recLength = 0,
recBuffers = [],
sampleRate = undefined,
numChannels = undefined;
self.onmessage = function (e) {
switch (e.data.command) {
case 'init':
init(e.data.config);
break;
case 'record':
record(e.data.buffer);
break;
case 'exportWAV':
exportWAV(e.data.type);
break;
case 'getBuffer':
getBuffer();
break;
case 'clear':
clear();
break;
}
};
function init(config) {
sampleRate = config.sampleRate;
numChannels = config.numChannels;
initBuffers();
}
function record(inputBuffer) {
for (var channel = 0; channel < numChannels; channel++) {
recBuffers[channel].push(inputBuffer[channel]);
}
recLength += inputBuffer[0].length;
}
function exportWAV(type) {
var buffers = [];
for (var channel = 0; channel < numChannels; channel++) {
buffers.push(mergeBuffers(recBuffers[channel], recLength));
}
var interleaved = undefined;
if (numChannels === 2) {
interleaved = interleave(buffers[0], buffers[1]);
} else {
interleaved = buffers[0];
}
var dataview = encodeWAV(interleaved);
var audioBlob = new Blob([dataview], { type: type });
self.postMessage({ command: 'exportWAV', data: audioBlob });
}
function getBuffer() {
var buffers = [];
for (var channel = 0; channel < numChannels; channel++) {
buffers.push(mergeBuffers(recBuffers[channel], recLength));
}
self.postMessage({ command: 'getBuffer', data: buffers });
}
function clear() {
recLength = 0;
recBuffers = [];
initBuffers();
}
function initBuffers() {
for (var channel = 0; channel < numChannels; channel++) {
recBuffers[channel] = [];
}
}
function mergeBuffers(recBuffers, recLength) {
var result = new Float32Array(recLength);
var offset = 0;
for (var i = 0; i < recBuffers.length; i++) {
result.set(recBuffers[i], offset);
offset += recBuffers[i].length;
}
return result;
}
function interleave(inputL, inputR) {
var length = inputL.length + inputR.length;
var result = new Float32Array(length);
var index = 0,
inputIndex = 0;
while (index < length) {
result[index++] = inputL[inputIndex];
result[index++] = inputR[inputIndex];
inputIndex++;
}
return result;
}
function floatTo16BitPCM(output, offset, input) {
for (var i = 0; i < input.length; i++, offset += 2) {
var s = Math.max(-1, Math.min(1, input[i]));
output.setInt16(offset, s < 0 ? s * 0x8000 : s * 0x7FFF, true);
}
}
function writeString(view, offset, string) {
for (var i = 0; i < string.length; i++) {
view.setUint8(offset + i, string.charCodeAt(i));
}
}
function encodeWAV(samples) {
var buffer = new ArrayBuffer(44 + samples.length * 2);
var view = new DataView(buffer);
/* RIFF identifier */
writeString(view, 0, 'RIFF');
/* RIFF chunk length */
view.setUint32(4, 36 + samples.length * 2, true);
/* RIFF type */
writeString(view, 8, 'WAVE');
/* format chunk identifier */
writeString(view, 12, 'fmt ');
/* format chunk length */
view.setUint32(16, 16, true);
/* sample format (raw) */
view.setUint16(20, 1, true);
/* channel count */
view.setUint16(22, numChannels, true);
/* sample rate */
view.setUint32(24, sampleRate, true);
/* byte rate (sample rate * block align) */
view.setUint32(28, sampleRate * 4, true);
/* block align (channel count * bytes per sample) */
view.setUint16(32, numChannels * 2, true);
/* bits per sample */
view.setUint16(34, 16, true);
/* data chunk identifier */
writeString(view, 36, 'data');
/* data chunk length */
view.setUint32(40, samples.length * 2, true);
floatTo16BitPCM(view, 44, samples);
return view;
}
}, self);
this.worker.postMessage({
command: 'init',
config: {
sampleRate: this.context.sampleRate,
numChannels: this.config.numChannels
}
});
this.worker.onmessage = function (e) {
var cb = _this.callbacks[e.data.command].pop();
if (typeof cb == 'function') {
cb(e.data.data);
}
};
}
_createClass(Recorder, [{
key: 'record',
value: function record() {
this.recording = true;
}
}, {
key: 'stop',
value: function stop() {
this.recording = false;
}
}, {
key: 'clear',
value: function clear() {
this.worker.postMessage({ command: 'clear' });
}
}, {
key: 'getBuffer',
value: function getBuffer(cb) {
cb = cb || this.config.callback;
if (!cb) throw new Error('Callback not set');
this.callbacks.getBuffer.push(cb);
this.worker.postMessage({ command: 'getBuffer' });
}
}, {
key: 'exportWAV',
value: function exportWAV(cb, mimeType) {
mimeType = mimeType || this.config.mimeType;
cb = cb || this.config.callback;
if (!cb) throw new Error('Callback not set');
this.callbacks.exportWAV.push(cb);
this.worker.postMessage({
command: 'exportWAV',
type: mimeType
});
}
}], [{
key: 'forceDownload',
value: function forceDownload(blob, filename) {
var url = (window.URL || window.webkitURL).createObjectURL(blob);
var link = window.document.createElement('a');
link.href = url;
link.download = filename || 'output.wav';
var click = document.createEvent("Event");
click.initEvent("click", true, true);
link.dispatchEvent(click);
}
}]);
return Recorder;
})();
exports.default = Recorder;
},{"inline-worker":3}],3:[function(require,module,exports){
"use strict";
module.exports = require("./inline-worker");
},{"./inline-worker":4}],4:[function(require,module,exports){
(function (global){
"use strict";
var _createClass = (function () { function defineProperties(target, props) { for (var key in props) { var prop = props[key]; prop.configurable = true; if (prop.value) prop.writable = true; } Object.defineProperties(target, props); } return function (Constructor, protoProps, staticProps) { if (protoProps) defineProperties(Constructor.prototype, protoProps); if (staticProps) defineProperties(Constructor, staticProps); return Constructor; }; })();
var _classCallCheck = function (instance, Constructor) { if (!(instance instanceof Constructor)) { throw new TypeError("Cannot call a class as a function"); } };
var WORKER_ENABLED = !!(global === global.window && global.URL && global.Blob && global.Worker);
var InlineWorker = (function () {
function InlineWorker(func, self) {
var _this = this;
_classCallCheck(this, InlineWorker);
if (WORKER_ENABLED) {
var functionBody = func.toString().trim().match(/^function\s*\w*\s*\([\w\s,]*\)\s*{([\w\W]*?)}$/)[1];
var url = global.URL.createObjectURL(new global.Blob([functionBody], { type: "text/javascript" }));
return new global.Worker(url);
}
this.self = self;
this.self.postMessage = function (data) {
setTimeout(function () {
_this.onmessage({ data: data });
}, 0);
};
setTimeout(function () {
func.call(self);
}, 0);
}
_createClass(InlineWorker, {
postMessage: {
value: function postMessage(data) {
var _this = this;
setTimeout(function () {
_this.self.onmessage({ data: data });
}, 0);
}
}
});
return InlineWorker;
})();
module.exports = InlineWorker;
}).call(this,typeof global !== "undefined" ? global : typeof self !== "undefined" ? self : typeof window !== "undefined" ? window : {})
},{}]},{},[1])(1)
});

 浙公网安备 33010602011771号
浙公网安备 33010602011771号