如何理解SQL中的自连接
参考链接:https://developer.aliyun.com/article/870215
自连接是什么?
自连接其实就是两张结构和数据内容完全相同的表,在做数据处理时,我们通常会给他们分别重命名加以区分,然后进行关联。
示例表内容:
加入有如下一张表,结构和数据如下:

当我们进行自连接时,不加任何过滤条件。具体如下:
SELECT s1.Sname AS Sname1, s2.Sname AS Sname2 FROM Student s2,Student s1

其实就是我们学过的数学排列,大致方式如下:

但是我们常见的自连接大多数是有条件的,在上边的结果上进行过滤,比如我们想找到一一对应的数据,可以这样写:
SELECT s1.Sname AS Sname1, s2.Sname AS Sname2 FROM Student s2,Student s1 WHERE s1.Sname=s2.Sname
得到的结果如下:

但是我们工作中,使用自连接的目的并不是自己和自己连接,更多的时候是和表里的其他进行组合:
SELECT s1.Sname AS Sname1, s2.Sname AS Sname2 FROM Student s2,Student s1 WHERE s1.Sname<>s2.Sname

此外,如果我们想进一步排除掉重复的数据行,比如张三,李四和李四,张三。我们默认这两行是重复数据,尽管他们顺序不同,但是在数学集合上,这两行可以看作是相同的数据集。只想保留一种的话,可以这样:
SELECT s1.Sname AS Sname1, s2.Sname AS Sname2 FROM Student s2,Student s1 WHERE s1.Sname>s2.Sname
该查询的目的是获取那些在 "Student" 表中具有字典序较大姓名的学生对。通过使用自联结,可以将同一表中的不同行进行比较。查询结果将包含两列,分别是字典序较大的学生姓名和字典序较小的学生姓名。

现在我们就得到了不重复的三行数据,这个与数学上的组合是一样的。
自连接实战
上边我们使用自连接处理连续性问题,现在我们再用自连接来删除重复数据。
下边是一张Student表,表的结构和数据如下:

我们想删除表中重复的行,如何写SQL呢?
这个表是没有主键ID的,如果我们想区分他们的话,需要增加一个虚列主键,可以这样写:
SELECT IDENTITY(INT) ID, Sname, Score INTO Student_Tmp FROM Student
在SQL Server中,如果想要给表添加一个虚拟的自增主键列,可以使用IDENTIFY属性。这里我们使用自增长函数IDENTIFY()来生成了一个类似于自增主键的ID,并将结果插入到Student_Tmp,其中Student_Tmp的具体内容如下:

然后我们可以通过保留最大值或最小值的方法来删除重复项,具体如下:
DELETE FROM Student_Tmp WHERE Student_Tmp.ID< ( SELECT Max(s2.ID) FROM Student_Tmp s2 WHERE Student_Tmp.Sname=s2.Sname AND Student_Tmp.Score=s2.Score );
这样我们就可以删除ID为3和4的列了,查询一下Student_Tmp的内容如下:
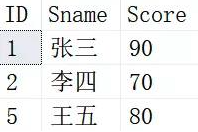
注意:由于SQL Server的一些限制,我们对源表不能进行上述操作,为了给大家演示自连接的作用,做了一定的调整。
如果想在SQL Sever中删除原表中的重复行,可以使用如下方法:
SELECT DISTINCT * INTO Student_Tmp FROM Student TRUNCATE TABLE Student INSERT INTO Student SELECT * FROM Student_Tmp DROP TABLE Student_Tmp
通过上述的办法,我们使用自连接的方式删除了Student_Tmp里面的重复行。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号