Learn DevOps: Start devOps with Docker(二)
一、Docker image commands
docker images
查看本地计算机中所有存在的image

docker pull mysql
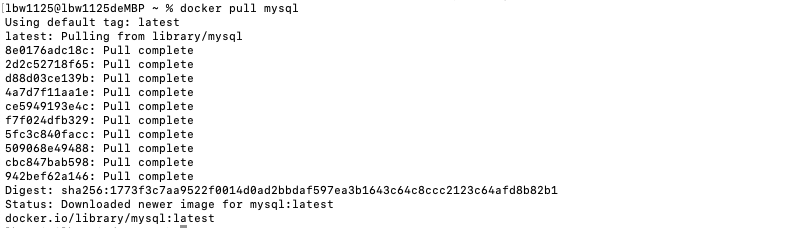
可以看到如果我们不提供标记,它会使用默认的最新的标记,它会查看是否有标记为latest的mysql映像,并将其汇集下来。pull只会拉取image使其本地可用,不会启动container。

可以看到mysql已经被下载到本地,如果我们此时查看运行的container,可以看到没有mysql容器:

现在我们可能想搜索一些image:
docker search mysql
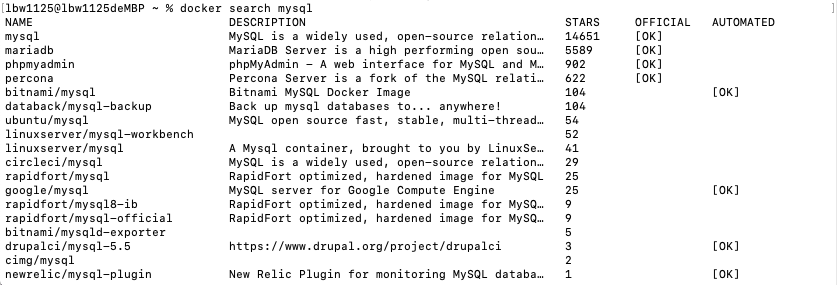
我们可以看到结果中返回了很多image,其中第一个是官方的。因此,如果运行任何软件比如MySQL、Tomecat或者Java作为一个docker容器,我们需要做一个搜索,确保我们使用的是一个官方的形象。Docker有一个团队,会检查所有的image,确保他们符合一定的标准,确保所有的东西是安全的,然后把这些image作为官方image发布,因此官方的image更加可靠。
另一个有趣的事情是,Docker image是在许多层中构建的,有一个包含操作系统的层,一个包含软件的层,一个包含特定应用程序(二进制)的层。那么如何查看所有的层呢?以“hello-world-java”为例:
docker image history in28min/hello-world-java:0.0.1.RELEASE
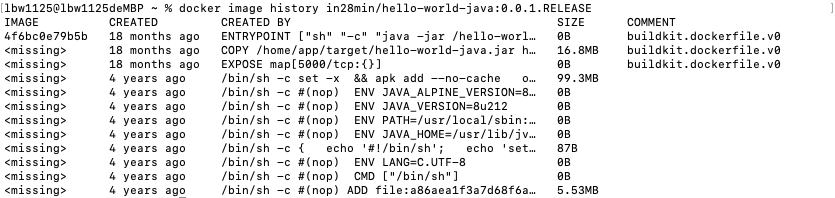
我们可以看到这个image的历史记录,最底层是一个非常小的操作系统层(最后一行),99.3MB的是一个大型的Java层,是java安装的位置。我们expose端口5000,然后复制文件。我们可以看到每一个都是作为一个单独的层添加进来的。
除此之外,我们其实不需要使用特定的tag,直接使用image的ID即可。

我们可以执行的另一个命令是查看这些图像背后的详细信息,依旧是传入image id:
docker image inspect 4f6bc0e79b5b

我们可以看到许多有关特定图像的详细信息,例如:
tags


创建的时间戳

容器

环境变量

程序入口

操作系统

不同的层

现在我们执行如下的命令:
docker images remove mysql


可以看到此时已经没有mysql映像了,接下来我们试图删除nodejs的image。

可以发现报错了,因为有一个容器正在引用这个image,所以不能删除。如果想要删除已经存在容器的image,首先要删除这个container。在删除container之前,首先要停止运行的container。
docker stop 4a77
docker container rm 4a77

查看特定镜像的所有容器
docker ps -a --filter "ancestor=<镜像名称或ID>"
删除特定映像的所有容器
docker ps -a --filter "ancestor=<镜像名称或ID>" -q | xargs docker rm
从下图可以看出,在我们试图删除这个nodejs映像时又遇到了错误,原因是还有container在使用这个image,因此我们可以使用上边的命令,来删除所有对应的container。

现在执行删除image的命令就可以成功执行了


可以看到nodejs的image已经被删除了,因此为了删除image,不应该有任何正在运行的容器与之关联,也不应该有任何已经停止的容器与之关联。
二、Docker container command
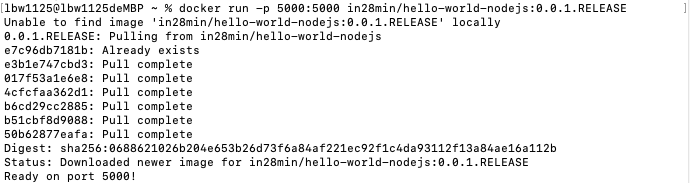
首先加载nodejs应用程序,这个命令实际上是一个简写,完整的命令是:
docker container run -p 5000:5000 in28min/hello-world-nodejs:0.0.1.RELEASE
接下来是一些我们之前用过的命令:
docker container ls
docker container ls -a
接下来我们看一下暂停容器的命令:

查看当前的container状态,可以看到容器已经被暂停:

这意味着容器不为任何请求提供服务,此时刷新网页不会得到任何响应,它只会挂起,然后过一会就超时。与暂停相反的命令是取消暂停:
docker container unpause a1d3

可以看到container恢复运行,此时刷新网页也可以得到响应。
接下来我们停止容器:
docker container stop a1d3
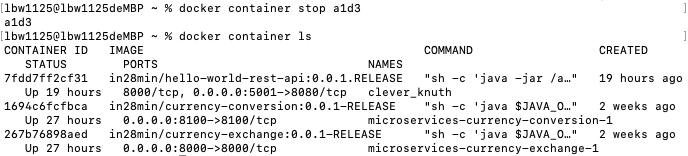
可以看到此刻容器已经被停止,不在运行容器列表中出现。
另一个有趣的命令是docker kill,这个命令和docker stop有什么区别呢?接下来我们创建一个实例来试验一下。

我们创建了一个java的container,接下来我们分别进行一次stop和kill,来观察有什么区别。在此期间我们讲使用如下命令跟踪日志,并打开一个新的窗口进行命令操作。
docker logs -f bb6
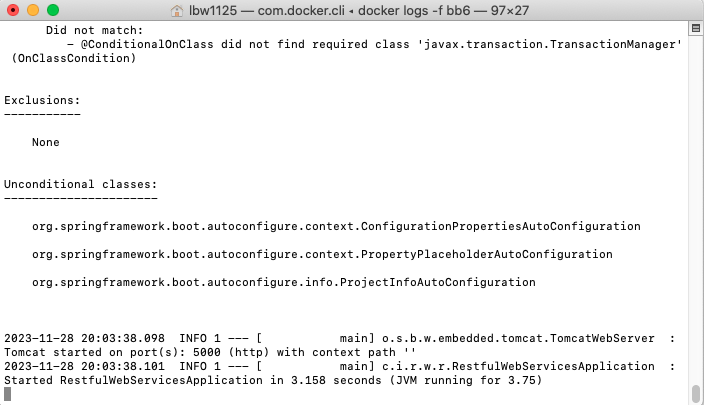
在新的窗口执行下边的命令来停止container:
docker container stop bb6

在java程序中,假设我们正在与一个数据库对话,可能有一个已经打开的链接,因此,这实际上是给应用程序一个关闭所有这些东西的机会。例如关闭JMX-exposed beans,并关闭ExecutorService,应用程序正在正常关闭。
现在让我们再启动一个container,并执行docker kill命令。
docker container run -d -p 5000:5000 in28min/hello-world-java:0.0.1.RELEASE
docker logs -f da7

接下来我们观察日志的变化

可以看到日志中后边没有内容直接停止,因此,应用程序实际上没有时间正常关闭。
所以我们可以看到二者的差别,docker stop可以给程序足够的时间关闭,而kill会立刻杀死容器,没有正常终止。实际上,如果我们用技术术语来表述,当我们停止Docker容器时,会向容器发送一个信号,称为“sigterm”。当我们执行docker kill时,发送的信号是“sigkill”。
和image一样,我们也可以使用inspect来查看container的详细信息:
docker container inspect 7fdd

还可以看到网络是桥接网络:
当我们做如下命令查看不同状态的container时,会看到很多停止的容器,那么我们应该怎样删除这些容器呢?
docker container ls -a

我们可以通过如下命令删除所有停止的容器:
docker container prune

此时查看所有的container,停止的容器已经被删除:

三、System and stats commands
最后我们看两个有趣的命令,docker system和docker stats。
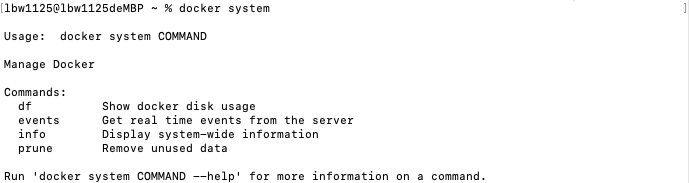
如果我们输入“docker system”,会得到一个错误,显示了所有指令,现在让我们使用如下命令,显示docker的磁盘使用情况。
docker system df

我们可以使用volume来存储持久性的数据,还可以使用build cache,当我们构建大量image时,就会用到build cache。这个命令对于查看容器或者与docker相关的所有内容使用了所有磁盘空间十分有用。
下一个有趣的命令是:
docker system events
当我们运行这个命令时,发现没有输出,因此我们需要trigger some events。让我们打开一个新的窗口,做如下命令:
docker container ls
docker container stop 7fdd
此时我们再去看events,就会看到如下结果:

我们可以看到container die,一段时间后消失,并且断开网络连接,container被停止。
接下来剩下最后一个命令:
docker system prune -a
在此之前,我们先查看现有的image和container。

我们可以看到有很多停止的容器和没有容器关联的image,现在我们希望删掉这些没用的东西,就可以使用上边的命令。

可以看到如果我们系统空间不足并且不想删除所有的docker image,这是一个非常有用的命令。它删除所有已经停止的容器,以及所有没有容器与之关联的image。它还会删除网络和build cache。

接下来有趣的命令是docker top和docker stats。
docker stats 1694c6fcfbca
![]()
可以看到指定容器的所有统计信息,显示了使用多少CPU、内存等信息。现在我们stop这个container。我们希望用少一点的CPU来启动容器,指定特定容器可以使用多少CPU和内存。我们重新启动一个java container并且指定所使用的内存。
docker container run -p 5000:5000 -d -m 512m in28min/hello-world-java:0.0.1.RELEASE
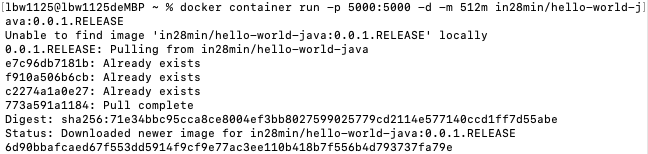
现在我们查看统计信息,可以看到内存最大只有512mb。
![]()
我们还可以指定分配多少CPU,假如我们想分配50%的CPU,首先停掉上边的container。

然后我们使用如下命令,相比于之前的命令我们增加了“--cpu-quota”。
docker container run -p 5000:5000 -d -m 512m --cpu-quota=50000 in28min/hello-world-java:0.0.1.RELEASE
总的CPU配额为100000,我们如果分配一半的话就是50000。
![]()
现在我们看一下他的统计数据是什么:
![]()
可以看到,在启动时间时,它只有一半的CPU可用,所以他需要多一点时间启动,在一段时间后CPU利用率大幅下降,程序已经启动。
四、Import Docker Projects into VS code
现在我们到GitHub网址克隆一下代码文件夹,下载到本地,网址为:
https://github.com/in28minutes/devops-master-class
现在让我们把注意力转移到构建docker image上,我们如何为项目构建image呢?现在我们用vs code打开刚才下载的文件夹。

我们首先为python构建image。
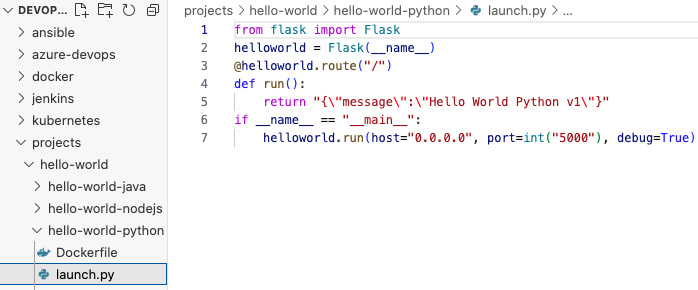
可以看到launch.py中,我们定义了一个简单的路径,当理由url被执行时,端口5000会返回信息。
另一个重要的文件是requirements:
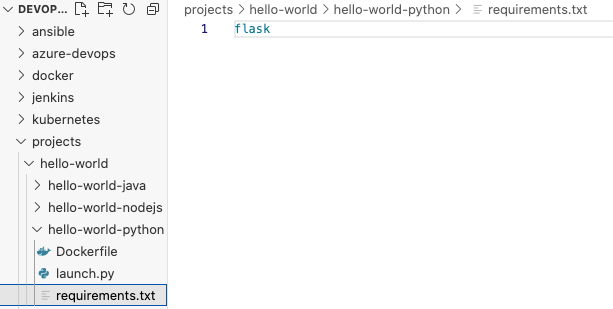
这个rest api使用一个名为Flask的框架,我们需要下载flask,这就是我们指定依赖关系的地方。
接下来是docker file,什么是docker file?
Docker file是我们指定Docker image所有指令的地方。

首先我们使用一个已经包含python的image,alpine是Linux的一个特定版本,,非常非常小,非常适合与docker image一起使用。第一行被称为“Base image”,
下一行是工作目录,指定应用程序的工作目录。
第三行是复制python代码,“.”是复制当前目录中的所有文件到“/app”文件夹。
接下来我们需要安装flask,也就是requirements中的内容。为了运行这个命令,我们使用“RUN”,这将在命令行中运行这个命令。
接着我们指定端口5000,然后运行launch.py文件。
综上,这是一个非常简单的文件,我们指定了一个基本的映像,然后下载所有的依赖,最后启动python程序。那么我们如何使用这个docker文件创建一个docker image呢?
现在让我们来启动一个终端窗口,进入到当前目录,使用如下命令,并且把launch.py中的“v1”改成“v2”。
docker build -t in28min/hello-world-python:0.0.2.RELEASE .
此处的“-t”是tag的意思,我们为创建的image做一个标记。注意不要忘记命令最后的“.”,这十分重要,这是在构建上下文,构建上下文是发送在当前目录中存在的任何信息,以便能够基于该信息构建映像。

现在我们查看image可以看到已经成功建立:

现在让我们运行一下这个image:
![]()
我们发现端口已经被占用,让我们来终止一下这个容器:

现在可以成功运行,去网页刷新查看,可以发现程序返回消息:

现在让我们继续使用上边的上边的看看后台发生了什么。

我们可以看到每一个实际上都与docker文件中的一条指令相匹配,现在让我们查看一下history。

从最后一行开始看,我们会发现这是它的起点,在构建这一特定映像的过程中有很多个层面。
五、Running with Docker hub
上面我们为python创建了一个image,并且在本地机器运行了。现在我们希望可以与其他人共享这个图像,应该怎么做呢?那就是把它推送到Docker hub。任何人都可以在公共的注册表中推送镜像。在企业中,人们通常使用私有的Docker存储库,或者使用云中的某个存储库。
现在,让我们使用Docker hub,注册Docker hub的账户,由于我之前已经注册过了,在这里不再赘述,不清楚的可以上网查教程。
Docker id是十分重要的,在前边的实验中,我们一直都在使用“in28min”,在此处,我们需要改成自己的Docker id,否则我们无法进行push操作。我们要做的是用自己的id重新构建image,然后将image推送到Docker hub。
push的命令十分简单:
docker push lbwtju520/hello-world-python:0.0.2.RELEASE

可以看到我们现在已经成功创建image并且push到Docker hub的存储库上。

接下来我们为Nodejs也做相同的操作,package.json中有如下内容:

我们希望使用express来运行REST API框架,接着我们再看看docker文件,同样是先指定基础image,npm将为我们下载所有的依赖项。
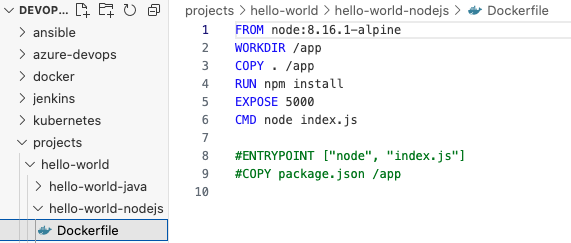
最后我们将index.js中的“v1”改成“v2”:

现在我们直接在vs code中的终端进行操作,会更加方便,cd到当前的目录:
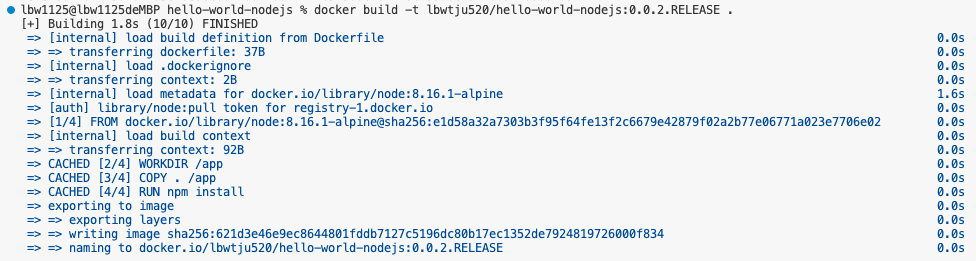
现在我们查看本地的映像,发现构建成功:

现在让我们运行一下这个image:
docker run -d -p 5000:5000 lbwtju520/hello-world-nodejs:0.0.2.RELEASE
可以看到成功运行:

接下来我们停止这个container,把image推送到Docker hub。
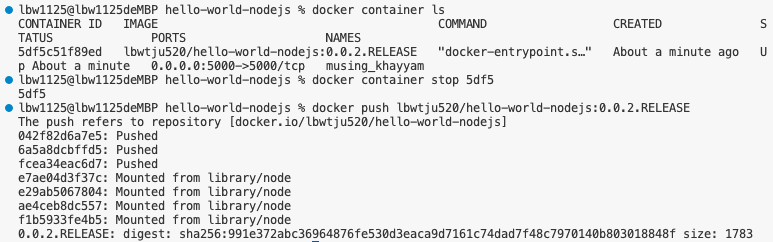
可以看到我们成功推送,现在到网站上查看。

接下来,让我们同样为Java进行相同的操作,记得把“v1”改成“v2”。

这里我们使用two-stage build,这是因为在java中的工作方式是当你有一个这样的Java文件时,试图部署到服务器上时,并不是真的运行这个Java文件,而是要先构建一个jar文件,然后才能在image中运行特定的jar文件。因此第一步就是创建需要的jar文件,这就用到一个称为Maven的工具,这与JS中的npm已经python中的pip十分相似。
我们使用maven映像来构建jar文件,构建完成后,我们要做的是将其复制到image中,那么如何将两个阶段练习起来呢?我们如何从第一个阶段获得输出,并且将其作为第二阶段的输入呢?
重要的部分是这里的copy命令,可以看到我们为第一个阶段取了一个名字“build”,接着我们利用COPY,“--from=build”从第一阶段将jar文件复制到第二阶段中。最后我们用Entrypoint运行这个文件。
现在让我们构建image:

push到Docker hub中,Docker push的好处在于,即使存储库不存在,它也会创建存储库,并且将标记作为第一个标记加入到存储库中:


大功告成!
六、高效构建image
现在让我们看一下如何高效构建image,我们再次为nodejs构建image,使用相同的命令。
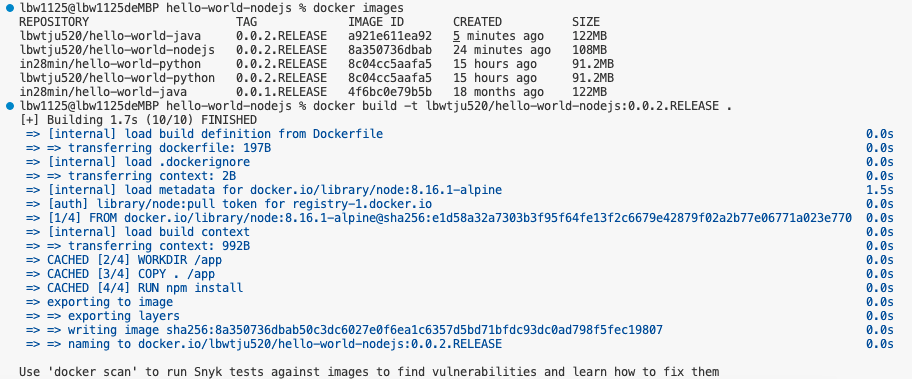
可以看到这次映像构建非常迅速,这是因为使用了缓存中的所有内容,如果之前的图层中没有任何更改,则将从cache中获取内容。现在让我们做一些改变,把index.js中改成“v2.1”。重新构建这个影像,观察有什么变化:
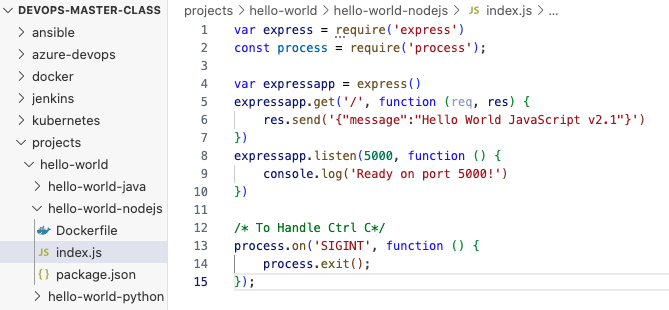
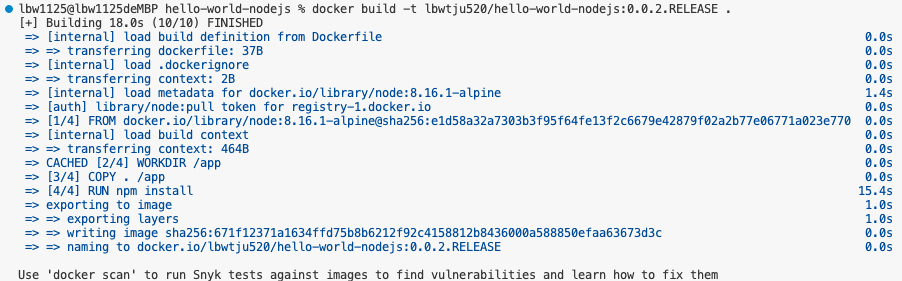
可以看到构建时间有变长了,这是因为在复制app文件夹时,它发现存在差异,因此无法使用缓存。如果我们熟悉应用程序构建的过程,可以知道应用程序需要一些依赖项,所有依赖项存在于一个名为package.json的文件中。
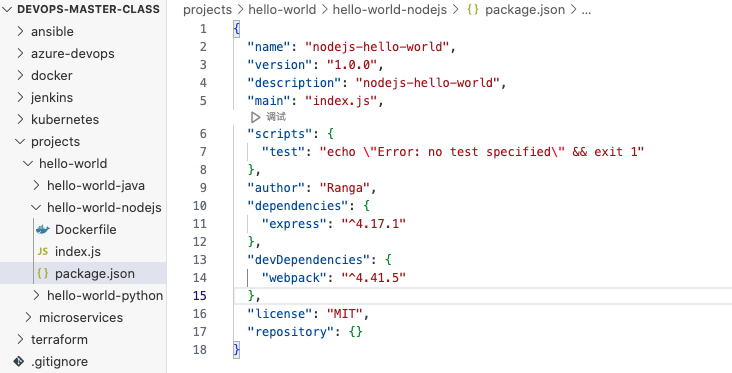
这个内容不会经常更改,经常更改的是我们的代码,即index.js中的内容。所以虽然代码一直在变,但是这个指定依赖关系的包几乎不改变。那么在这种情况下,我们将依赖关系构建成一个单独的层会发生什么呢?
依赖层也可以被缓存,如果我们在它上面有代码层,那么只有代码层会不断变化,我们不需要经常更改依赖层。那么我们如何将依赖层构建为单独的层呢?我们能做的就是在Docker file中进行修改。

COPY package.json /app
我们增加一个这个步骤,并且将之前的“COPY . /app”移动到后边,在第三行我们不再复制整个目录到app目录,而是只复制package.json,只有在第六行的时候,我们才复制可能改变的代码。所以package.json不会改变很多,它是npm安装最重要的文件之一。让我们再次构建image:

此时运行大概需要一段时间,因为我们对layer进行了大量更改。现在我们对代码进行更改,观察此时再次build需要多少时间。我们把index.js中的“v2.1”改成“v3”,然后进行构建,
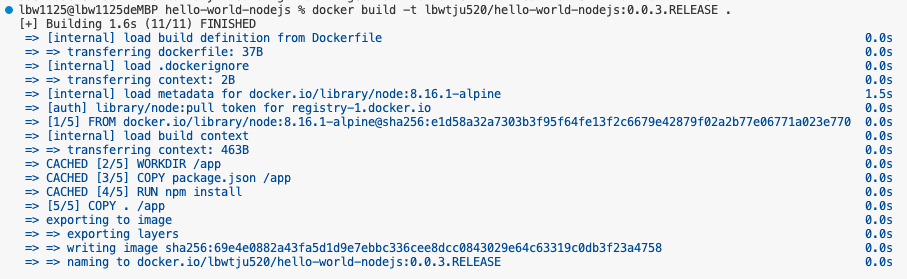
我们可以看到此时构建非常迅速,现在让我们运行一下:
docker run -d -p 5000:5000 lbwtju520/hello-world-nodejs:0.0.3.RELEASE
到网页刷新可以看到已经成功运行:

可以看到我们这次构建十分高效,当修改代码时,构建时间依旧非常短。
总结一下:
COPY package.json /app:这一行将主机机器上的 package.json 文件复制到容器内的 /app 目录。这是在运行 npm install 之前进行的,以便利用 Docker 层缓存。如果 package.json 文件没有发生变化,Docker 可以重用现有的镜像层。
COPY . /app:这一行将主机机器上的当前目录下的所有文件复制到容器内的 /app 目录。这包括应用程序的源代码和其他文件。
Docker 使用一种称为层缓存(Layer Caching)的机制来加速构建过程。每个 Dockerfile 指令都会生成一个层(Layer),并且这些层是可以被缓存的。当 Docker 构建一个镜像时,它会检查之前的构建步骤生成的层是否已经存在,如果存在且没有发生变化,Docker 就可以直接使用这些缓存的层,而不需要重新执行相同的步骤。
在这个背景下,`COPY package.json /app` 是为了将 `package.json` 文件复制到容器中,并运行 `npm install`。由于 `package.json` 很少变化,它的复制和安装步骤很可能在之前的构建中已经执行过。这就意味着,如果没有对 `package.json` 进行修改,Docker 将直接使用之前构建的缓存层,而不会重新下载和安装依赖项。
然后,`COPY . /app` 在 Dockerfile 的后面。因为这一步将整个当前目录下的所有文件都复制到容器中的 `/app` 目录,而这些文件可能包括了应用程序的源代码、配置文件等。这一步通常会在最后,因为这些文件的变化较为频繁,放在前面可能导致 Docker 无法充分利用缓存,从而增加构建时间。
我们也可以对python构建做同样的操作,实现的方法是通过复制requirements。

这会明显缩短构建时间。
我们需要记住的就是,如果缓存了layer,不仅可以更快地构建image,还可以更快的将image推送到Docker hub,并且将image pull到希望部署的位置,因此确保尽可能多的缓存layer是非常重要的。
说回上边的Java构建,为了启动程序,我们使用了Entrypoint,而在python和nodejs中我们使用的是CMD。那么这两个有什么区别呢?什么时候应该使用哪一个?
我们首先停止所有正在运行的container,然后运行下边的命令:
docker run -d -p 5000:5000 lbwtju520/hello-world-nodejs:0.0.3.RELEASE ping google.com

可以看到他在持续ping网站,但是到localhost:5000查看,我们发现程序没有正常运行:

现在让我们执行如下的命令:
docker run -d -p 5001:5000 lbwtju520/hello-world-java:0.0.2.RELEASE ping google.com

但是查看日志可以看到,ping Google.com没有成功运行,ping操作不会覆盖我们设置的任何启动设置。那么CMD和Entrypoint的区别是什么呢?
使用CMD,我们从命令行传递的任何内容都会被替换成要执行的指令,因此“ping google.com”会替换Docker file中的CMD后边的内容。但是Entrypoint不关心命令行参数,那么什么时候该用哪个命令呢?
让我们假设有一个新的文件,需要用于运行整个应用程序,例如index1.js,那么我们可以使用CMD来覆盖成我们想执行的命令。当我们不想覆盖命令,而是想静态执行,那就要使用Entrypoint。我们在这里也提供一下Entrypoint的Nodejs和python版本。
ENTRYPOINT ["python", "./launch.py"]
ENTRYPOINT ["node", "index.js"]
最后,Entrypoint也可以被覆盖,但是不会被命令行参数覆盖,我们要做的是实际传入一个选项,我们可以使用别名为Entrypoint的参数。
docker run -d -p --entrypoint 5001:5000 lbwtju520/hello-world-java:0.0.2.RELEASE
总结:如果我们每次希望启动相同的应用程序,Entrypoint是首选。如果我们希望覆盖之前的命令,则使用CMD。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号