高频SQL 50题(基础版):连接
SQL的各种join
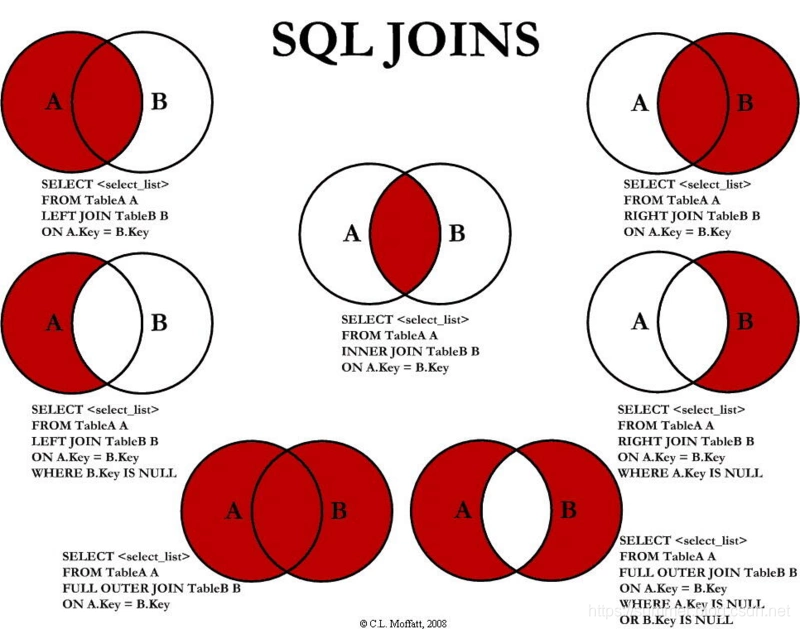
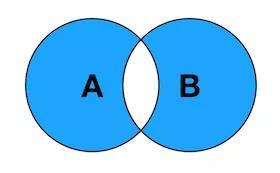
1. INNER JOIN
内连接,将左表(表A)和右表(表B) 中能关联起来的数据连接后返回。
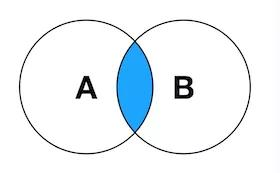
SELECT <select_list> FROM TableA A INNER JOIN TableB B ON A.Key = B.Key
2. LEFT JOIN
左连接,也写作LEFT OUTER JOIN。这个连接会返回左表中的所有记录,不管右表中有没有关联的数据。在右表中找到的关联数据也会被一起返回。
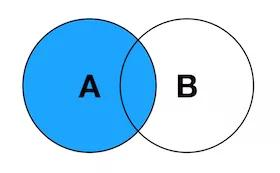
SELECT <select_list> FROM TableA A LEFT JOIN TableB B ON A.Key = B.Key
3. RIGHT JOIN
右连接,也写作RIGHT OUTER JOIN。这个连接返回右表中的所有记录,不管左表中有没有关联的数据。在左表中找到的关联数据列也会被一起返回。
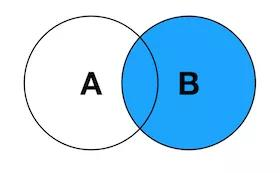
SELECT <select_list> FROM TableA A RIGHT JOIN TableB B ON A.Key = B.Key
4. FULL OUTER JOIN
外连接,也称为全连接,可以写作FULL OUTER JOIN或FULL JOIN。返回左右表中所有记录,左右表里能关联的记录被连接后返回。
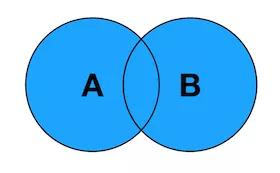
SELECT <select_list> FROM TableA A FULL OUTER JOIN TableB B ON A.Key = B.Key
5. LEFT JOIN EXCLUDING INNER JOIN
返回左表有但是右表没有关联数据的记录集。
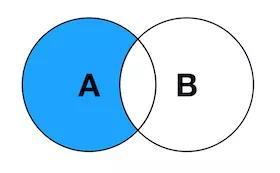
SELECT <select_list> FROM TableA A FULL OUTER JOIN TableB B ON A.Key = B.Key WHERE B.Key IS NULL;
6. RIGHT JOIN EXCLUDING INNER JOIN
返回右表有但是左表没有关联数据的记录集。
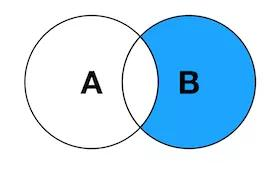
SELECT <select_list> FROM TableA A RIGHT JOIN TableB B ON A.Key = B.Key WHERE A.Key IS NULL;
7. FULL OUTER JOIN EXCLUDING INNER JOIN
返回左表和右表中没有相互关联的记录集。
SELECT <select_list> FROM TableA A FULL OUTER JOIN TableB B ON A.Key = B.Key WHERE A.Key IS NULL OR B.Key IS NULL;
让我们逐步解释这个查询:
-
SELECT <select_list>: 这是一个占位符,代表你想要选择的列,用于指定查询结果中应包含哪些列。 -
FROM TableA A: 这指定了查询的主要表是TableA,将其别名为A,以便在查询中引用它。 -
FULL OUTER JOIN TableB B ON A.Key = B.Key: 这是一个外连接(FULL OUTER JOIN),它返回两个表中的所有行,以及两个表中匹配键的行。连接条件是A.Key = B.Key,表示两个表中的Key列的值相等。 -
WHERE A.Key IS NULL OR B.Key IS NULL: 这是一个筛选条件,用于选择在连接条件中没有匹配项的记录。具体来说,它选择那些在TableA中的Key列为NULL或在TableB中的Key列为NULL的记录。这是因为在FULL OUTER JOIN中,如果在其中一个表中找不到匹配项,那么相应的列将为NULL。
综合起来,这个查询的结果将包括那些在 TableA 中的 Key 列在 TableB 中没有匹配项的记录,以及在 TableB 中的 Key 列在 TableA 中没有匹配项的记录。
1378. 使用唯一标识码替换员工ID


思路:返回左表中所有记录,以及与右表有关联的记录,没有匹配的用null填充,注意返回结果的列需要通过select选择。
SELECT EmployeeUNI.unique_id, Employees.name FROM Employees LEFT JOIN EmployeeUNI ON Employees.id = EmployeeUNI.id;
1068. 产品销售分析 I


SELECT Product.product_name, Sales.year, Sales.price FROM Sales LEFT JOIN Product ON Sales.product_id = Product.product_id
1581. 进店却未进行过交易的顾客


思路:题目有点难理解,主要是统计交易次数。一种思路是利用visit_id进行左连接,则会出现一些id的transaction_id为空的情况,我们就是要找出为null的用户,然后计数customer_id出现的次数。
SELECT customer_id, count(customer_id) as count_no_trans FROM Visits LEFT JOIN Transactions ON Visits.visit_id = Transactions.visit_id WHERE transaction_id IS NULL GROUP BY customer_id;
注意:
1. count和as指定计数列并指定别名;
2. GROUP BY分组后,count根据分组后的信息进行计算。
第二种思路是使用NOT IN,找出在Transactions表出现的不重复的visit_id,然后在Visits表去掉这些id,就找到了只访问不交易的id。
SELECT customer_id, count(visit_id) as count_no_trans FROM Visits WHERE visit_id NOT IN (SELECT DISTINCT visit_id FROM Transactions) GROUP BY customer_id;
注意:
1. count和group by的应用,对于不交易的id分组计数,分组按照customer_id,计数是visit_id;
2. 子查询的应用,找出不在交易表中的id。
197. 上升的温度

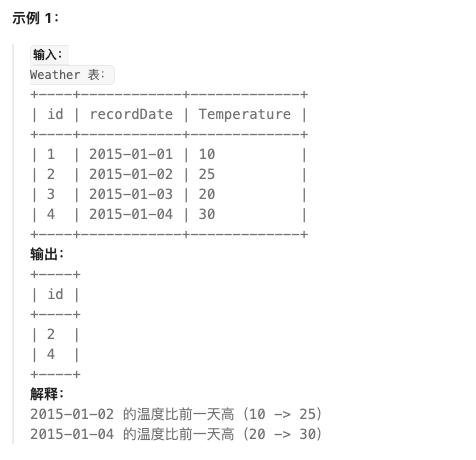
思路:
第一种思路:lag()+datediff()
lag()和lead(0函数可以查询我们得到的结果集上下偏移相应行数的相应的结果。
lag()函数:查询当前行向上偏移n行对应的结果,函数有三个参数:第一个为待查询的参数列名,第二个为向上偏移的位数,第三个参数为超出最上面边界的默认值。
lead()函数:查询当前行向下偏移n行对应的结果,函数有三个参数:第一个为待查询的参数列名,第二个为向下偏移的位数,第三个参数为超出下面边界的默认值。
DATEDIFF()函数:返回两个日期之间的时间。
# Write your MySQL query statement below SELECT id FROM (SELECT id, temperature, recordDate, LAG(recordDate,1) OVER(ORDER BY recordDate) as last_date, LAG(temperature,1) OVER(ORDER BY recordDate) as last_temperature FROM weather) a WHERE temperature > last_temperature and DATEDIFF(recordDate, last_date) = 1;
注意:
1. 窗口函数LAG和LEAD的使用,OVER确定窗口函数的操作范围,as确定别名。
2. 子查询需要给派生表指定一个a,如果不指定,则会报错。
3. 代码的逻辑实现,利用DATEDIFF日期函数计算两个日期之间的时间差。
第二种思路:笛卡尔积
笛卡尔积指的是数学中,两个集合X和Y的笛卡尔积,又称直积,表示为X×Y,第一个对象是X的成员而第二个对象是Y的所有可能有序对象的其中一个成员。
假设集合A={a, b},集合B={0, 1, 2},则两个集合的笛卡尔积为{(a,0), (a,1), (a,2), (b,0), (b, 1), (b, 2)}。
inner join只返回两个表中联结字段相等的行,on表示链接条件。
SELECT b.id FROM weather a INNER JOIN weather b WHERE DATEDIFF(b.recordDate, a.recordDate)=1 AND b.temperature > a.temperature;
具体步骤如下:

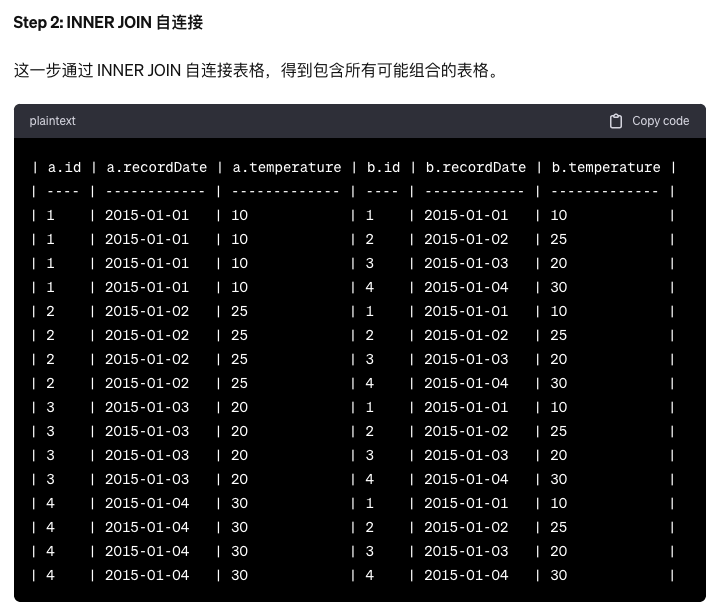

注意:MySQL只支持left join、right join和inner join,但是不支持full join。
第三种思路:adddate()函数
这个函数用于将日期与一个指定的时间间隔相加,返回一个新的日期。
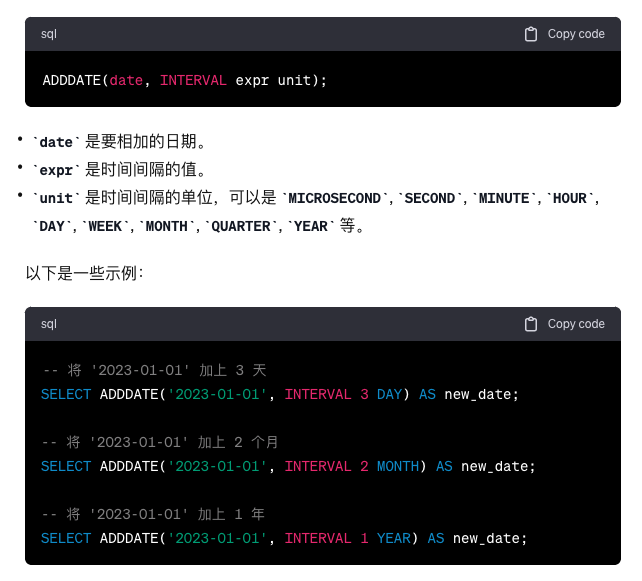
SELECT a.id FROM weather a INNER JOIN weather b ON (a.recordDate = adddate(b.recordDate, INTERVAL 1 day)) WHERE a.temperature > b.temperature;
注意:自连接的话用inner join和join都行。adddate()和date_add()等价。
第四种思路:TIMESTAMPDIFF()

SELECT b.id FROM weather a, weather b WHERE TIMESTAMPDIFF(DAY, a.RecordDate, b.RecordDate) = 1 AND b.temperature > a.temperature;
第五种思路:外连接+子查询+Date_ADD()
SELECT a.id FROM weather a JOIN( SELECT recordDate, temperature FROM weather ) b ON a.recordDate = adddate(b.recordDate, INTERVAL 1 day) WHERE a.temperature > b.temperature;
1661. 每台机器的进程的平均运行时间


SELECT a1.machine_id, ROUND(AVG(a2.timestamp - a1.timestamp), 3) AS processing_time FROM Activity AS a1 JOIN Activity AS a2 ON a1.machine_id = a2.machine_id AND a1.process_id = a2.process_id AND a1.activity_type = 'start' AND a2.activity_type = 'end' GROUP BY machine_id;
注意:
1. round()函数,四舍五入,两个参数,第一个参数为要进行四舍五入的数字,第二个参数为要保留的小数位数。
2. avg()函数,参数为要计算平均值的列,经常和group by一起使用,group by对数据进行分组,avg计算每个组的聚合值。
577. 员工奖金


SELECT a1.name, a2.bonus FROM employee a1 LEFT JOIN bonus a2 ON a1.empId = a2.empId WHERE a2.bonus < 1000 OR a2.bonus IS NULL;
1280. 学生们参加各科测试的次数



思路:
这个题目有点绕,做到最后提交发现没有考虑所有的科目,每个人都修了这些科目,但是exam表里只是参加过考试的科目。
首先我们通过一个子查询创建表grouped,统计每个学生参加每个科目的考试次数。
SELECT student_id, subject_name, COUNT(*) AS attened_exams FROM Examinations GROUP BY student_id, subject_name
group by先按照学生id进行分组,接着在每个学生id组内,根据科目名称进一步分组,具有相同科目名称的行被归为同一子组。count(*)计算的是每个组内的行数,每个组对应一个学生和一个科目的组合,返回考试的次数。
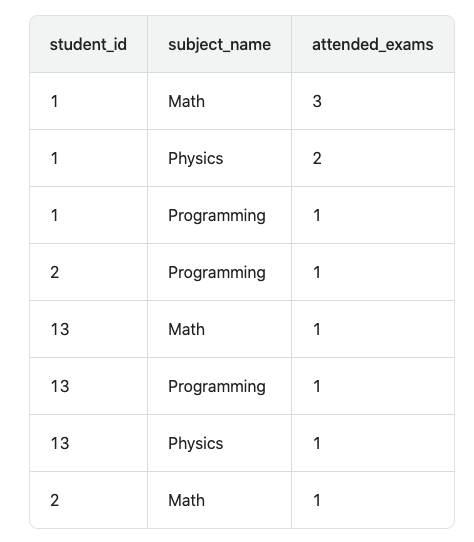
为了获得(subject_id, subject_name)的所有组合,我们使用交叉连接将表student中的每一行与表Subject中的每一行组合在一起,从而得到两个表中的student_id和subject_name的所有可能组合。
SELECT * FROM Students s CROSS JOIN Subjects sub

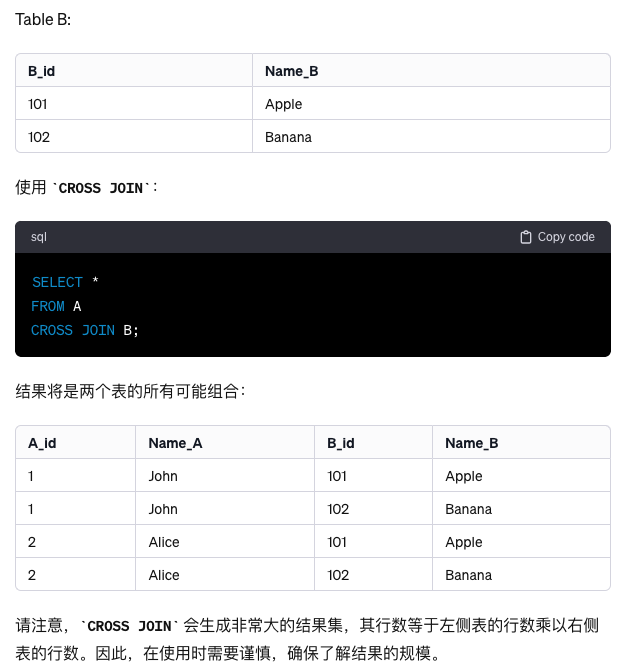
这一步之后,得到下边的表
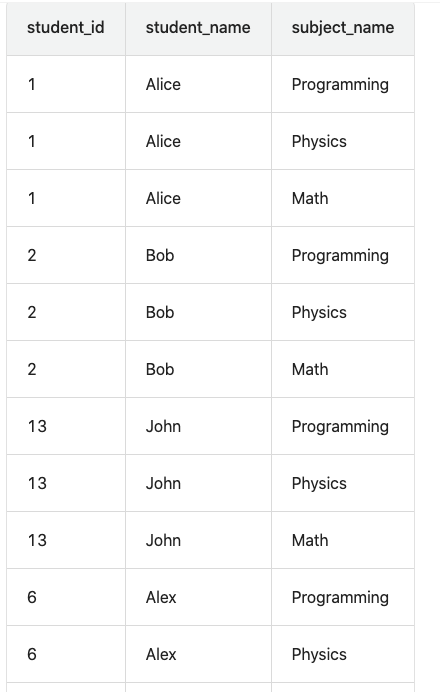
然后将这个表与表grouped执行左连接,在左连接之后,attended_exams可能有null值,我们使用IFNULL()函数将其替换为0。
SELECT s.student_id, s.student_name, sub.subject_name, IFNULL(grouped.attended_exams, 0) AS attended_exams FROM Students s CROSS JOIN Subjects sub LEFT JOIN ( SELECT student_id, subject_name, COUNT(*) AS attended_exams FROM Examinations GROUP BY student_id, subject_name ) grouped ON s.student_id = grouped.student_id AND sub.subject_name = grouped.subject_name ORDER BY s.student_id, sub.subject_name;
注意:
1. 一步一步分析,分步创表,会使思路更加清晰;
2. 笛卡尔积可以通过cross join实现,实现两个表联合;
3. IFNULL函数检查一个表达式是否为NULL,如果是NULL就返回指定的替代值,否则返回原始值。
4. 注意表的命名,应该使其更容易理解。
570. 至少有5名直接下属的经理


第一种思路:
首先查询每个人的下属员工数,将两份Employee表用join连接,Manager表代表经理,Report表代表下属,每对Manager.Id = Report.ManagerId的情况代表此经理的一名下属。再根据Manager.Id分组,对Report.Id求和得到每个经理对应的下属数量,接着筛选cnt>=5的数据即可。
select name from ( select Manager.name as name, count(Report.Id) as cnt from Employee as Manager join Employee as Report on Manager.id = Report.ManagerId group by Manager.id ) as ReportCount where cnt >= 5;
第二种思路:
不用子查询,直接使用having子句筛选大于5的数据:
select Manager.name as name from Employee as Manager join Employee as Report on Manager.id = Report.ManagerId group by Manager.id having count(Manager.id) >= 5
注意:
1. 注意having和where过滤条件的区别:
- 用途
- where子句用于在对表中的行进行过滤之前指定条件,在数据分组前应用,用于筛选行。
- having子句用于在对分组的结果应用聚合函数后指定条件,在数据分组后,对分组结果进行过滤。
- 使用位置
- where出现在查询的from之后,group by之前。
- having出现在group by之后。
- 应用范围
- where过滤的是行级数据,用于筛选表中的行,不涉及聚合函数。
- having过滤的是分组级别的数据,用于筛选进行了聚合的分组,通常涉及聚合函数(例如count、sum、avg等)。
2. 正确使用join,有些时候cross join和inner join用起来差不多。
第三种思路:
上边的查询为了得到经理的名字,首先对两份employee表进行了连接,但是我们其实可以先对经理进行筛选,再通过连接操作得到经理的名字。要筛选员工数大于5的经理,直接将employee表根据managerId进行分组,每组中的id即为每个经理对应的下属,取下属数量大于5的条目。然后与employee表进行连接,得到manager的姓名。
select Employee.name from ( select managerId as id from Employee group by managerId having count(id) >= 5 ) as Manager join Employee on Manager.id = Employee.id;
1934. 确认率

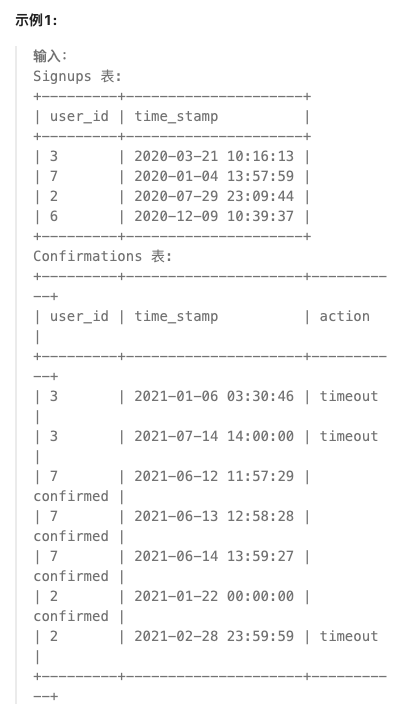

select s.user_id, round(sum(if(action='confirmed', 1, 0)) / count(s.user_id), 2) as confirmation_rate from Signups s left join Confirmations c on s.user_id = c.user_id group by s.user_id;
思路:
数值计算部分:
1. 首先‘if(action='confirmed', 1, 0)’使用if函数,检查action列的值是否等于confirmed,如果是则返回1,否则返回0;
2. 接着sum函数对上述条件表达式的结果进行求和;
3. count(s.user_id)计算id列的总行数;
4. sum(...) / count(s.user_id)相除得到确认率;
5. round(..., 2)将结果四舍五入到小数点后两位。
表部分:
signup表和confirmations表左连接

分母可以通过计算count(user_id)实现,分子通过sum和if的结合计算。很巧妙地解决了null的情况。
此外也可以通过AVG()函数来实现:
1. 使用AVG函数计算confirmed平均值,如果不存在则为null;
2. 使用IFNULL把null转化为0;
3. 使用ROUND精确小数点位数。
SELECT s.user_id, ROUND(IFNULL(AVG(c.action='confirmed'), 0), 2) AS confirmation_rate FROM Signups AS s LEFT JOIN Confirmations AS c ON s.user_id = c.user_id GROUP BY s.user_id
AVG(c.action='confirmed'):这部分计算了确认动作(action 列的值为 'confirmed')的平均值。这是一个聚合函数,用于计算符合条件的行的平均值。如果没有符合条件的行,平均值可能为 NULL。
注意:
1. 函数的应用考察,if条件过滤,第二种思路会存在null的情况,因此需要使用ifnull进行处理;
2. 表格的命名;
3. 表格join的思路。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号