大规模并行系统编程(一)Introduction
概述
本课程将讨论如何编写可以在大量处理器上并行运行的计算机程序,主要目标是减少执行的时间并解决无法适应单个节点的大型问题。我们将学习如何设计此类并行算法以最大限度减少通信开销和负载不平衡,如何如何使用不同的并行计算模型来实现它们,以及如何分析生成的代码和底层硬件的性能。在可用于高性能计算(HPC)的所有并行编程模型和环境中,本课程重点关注分布式内存并行化。我们将学习成熟的技术,例如如何使用MPI进行消息传递,而且还将学习更现代的方法,例如Julia编程语言提供的基于任务的分布式计算模型。
学习成果
课程结束时,我们应该能够掌握
高性能计算的主要原理
在分布式内存并行计算机上设计和实现高效的并行算法
识别并比较不同的并行计算机体系结构
利用不同的并行编程模型和环境,例如MPI和Julia的基于任务的分布式计算模型
分析并行应用和网络拓扑的性能
确定选定的并行计算应用程序中的主要计算挑战
使用Julia编程语言设计并行算法
课程资料
jupyter讲义,包含课程中讨论的几种并行算法在Julia中的实现:https://www.francescverdugo.com/XM_40017/dev/julia_basics/
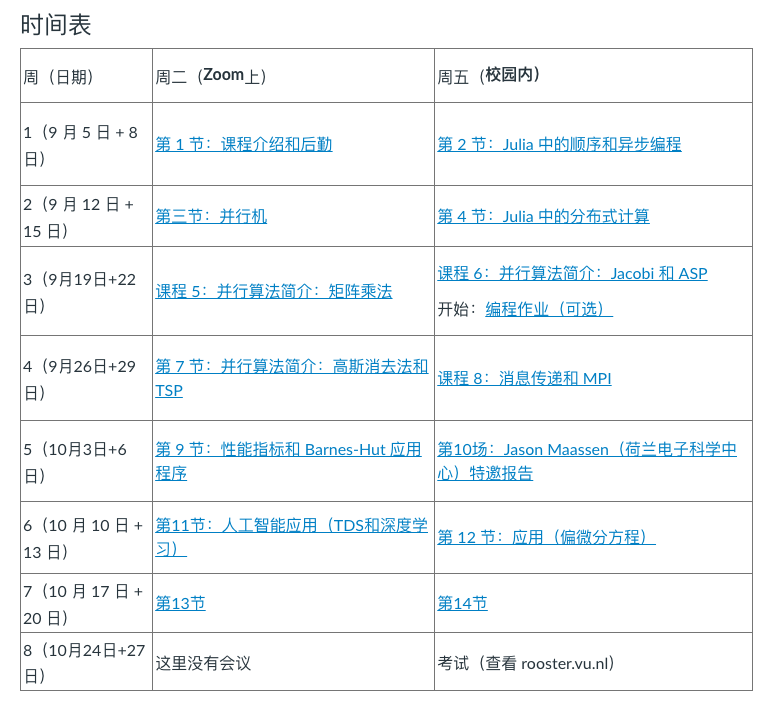
家庭作业
现代CPU 使用多个核心,但单个核心的速度(时钟频率)几乎不再增加。有人声称这表明摩尔定律不再成立。解释这个说法是真是假
回答:这是假的。摩尔定律不是关于速度的增加,而是关于晶体管的数量。在多核时代,晶体管的数量不断增长,但它们被用来构建多个核心,而不是使单核更快。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号