
Paraview学习笔记(2)
Exercise 2 - A Tornado simulation
Importing and preparing the data
在这个练习中,我们将看一看模拟龙卷风中的风的结果。相关数据集包含常规3D网格(所谓的流场)上的速度向量。数据包含在一个简单的文件格式中:众所周知的逗号分隔值格式(CSV)。CSV的优点是它是一种简单的、人类可读的格式,可以被许多应用程序编写和读取。然而,它并不总是存储(大型)数据集的有效方法。
包含在CSV文件中的数据不能被ParaView自动识别和正确理解,它根本没有足够的信息。因此,当我们打开CSV文件时,我们首先必须应用一些过滤器来将数据映射到我们可以操作的正确数据数组。完成这些之后,我们可以在上面使用一个气流跟踪过滤器来获得模拟中气流的良好印象。
- 首先要做的事建立一个新的视图,使用工具栏中的disconnect按钮,或者使用File栏中的Disconnect选项,清除现有的pipeline。
- 打开数据集点击apply,选择CSV Reader,然后点击Apply加载数据。一个包含数据表表示的新视图窗格将被添加到现有的3D视图旁边。这个表格类似于Excel表格。
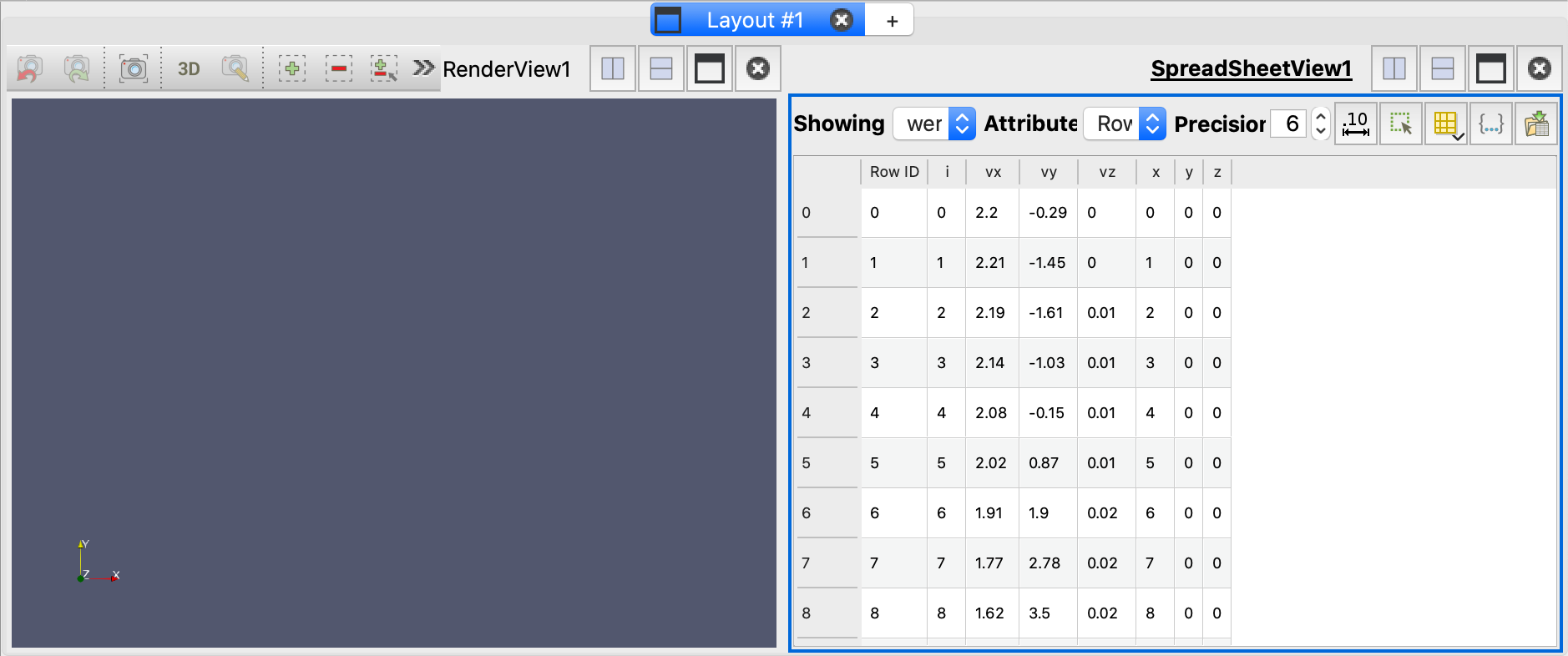
这些值是:
i是每个点的唯一标识符,
x,y和z定义了三位笛卡尔网格上的位置,
vx,vy和vz表示(x, y, z)位置的三维速度向量
ParaView不知道这些单独的变量如何与它的数据模型中的点和单元格相关联,所以我们必须自己提供映射。
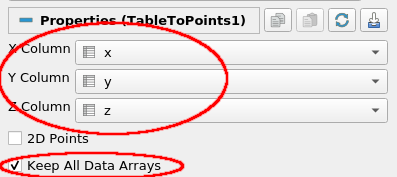
- 第一步是在数据源中添加TableToPoints过滤器,这个筛选器根据选择的一组表值为表中的每一行创建一个3D点。可以通过Filters->Alphabetical->TableToPoints创建过滤器,并且将x,y和z正确对应,点击Keep All Data Arrays之后点击Apply。
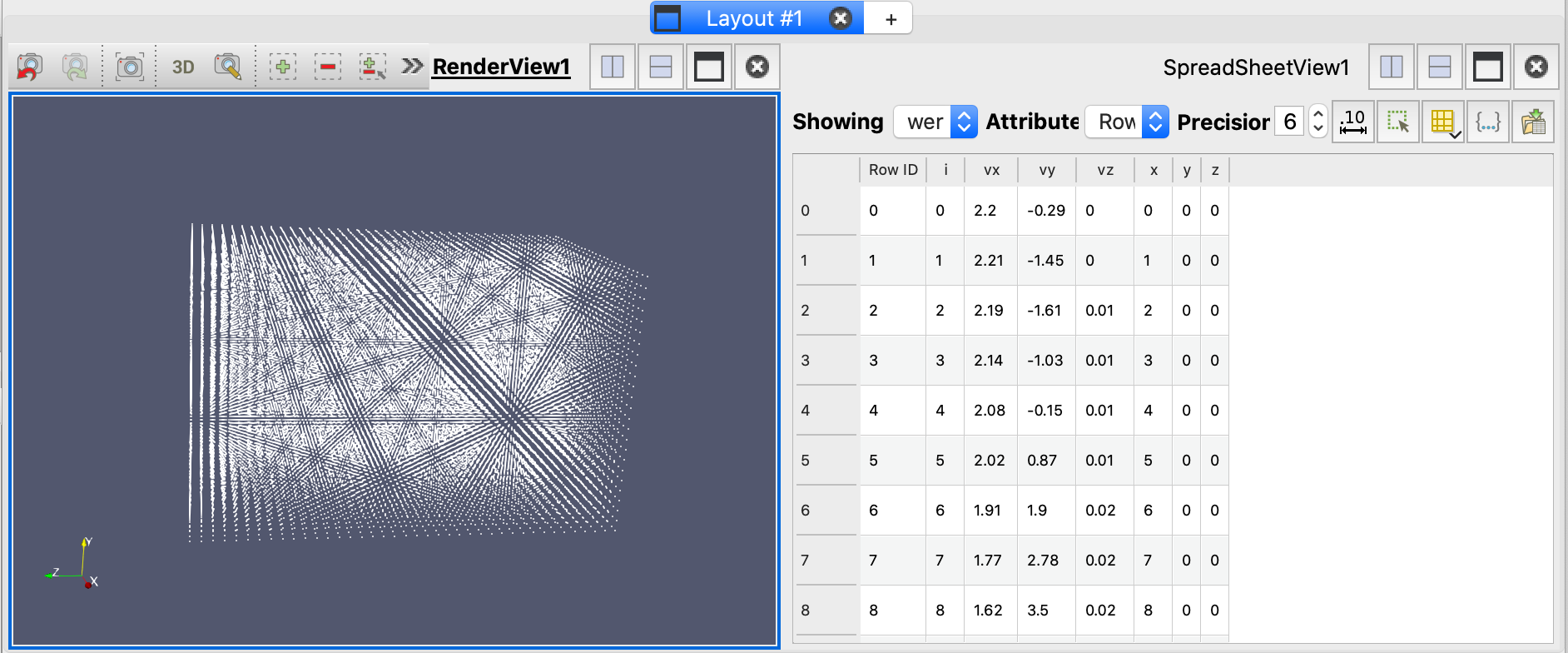
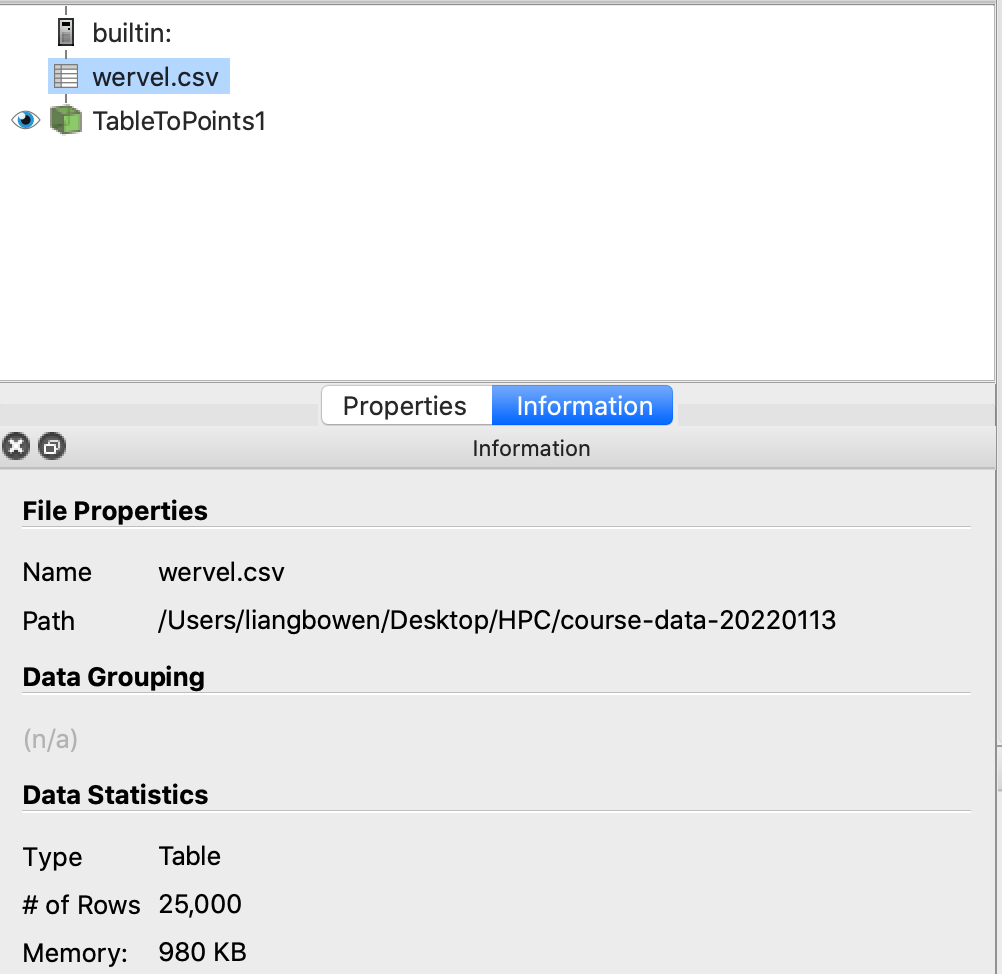
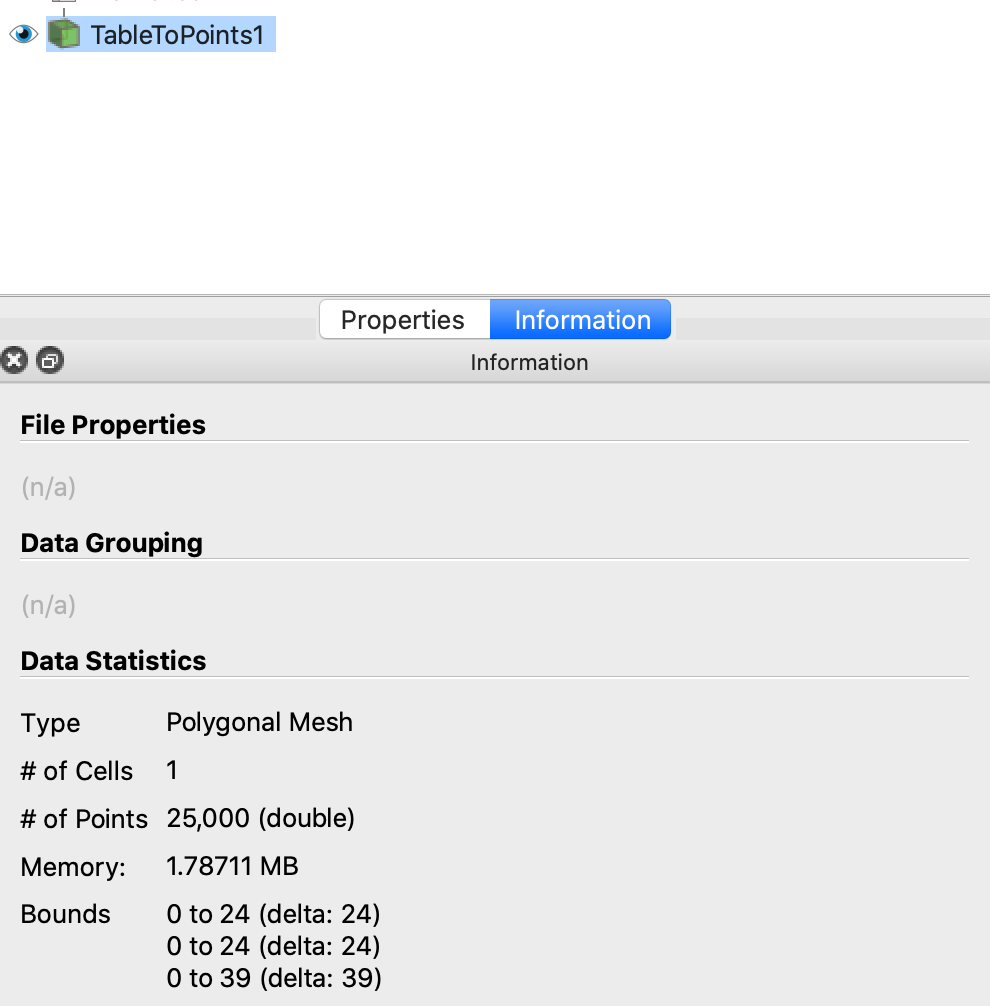
- 比较wervel.csv源和TableToPoints过滤器的Information选项卡,以查看输出数据是如何变化的(类型、点/单元格的数量等),并验证TableToPoints过滤器生成的数据数组是否与wervel.csv源的数据数组匹配,可以看到数据的类型和点的个数都已经改变。
- 选择TableToPoints filter,添加一个Calculator filter(Filter->Common->Caculator)。在Result Array Name输入“Velocity”,然后在文本框中输入表达式点击Apply。这将创建一个Velocity数组,其中每个点的向量值为(vx,vy,xz)。同样,可以通过Information中数据的内容来验证这一点。
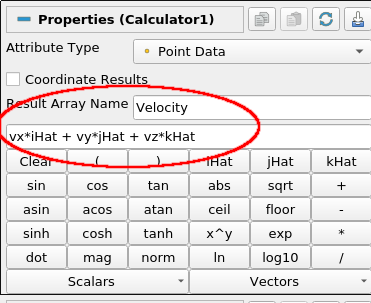
你可能已经发现iHat表示向量î,即(1,0,0)。使用Calculator filter,复杂的表达式可以用新的有用的值(包括标量和向量)来增加现有的数据集。
- 选中Calculator filter,再添加另一个Calculator filter,用于创建数组VelocityMag和表达式mag(Velocity)。
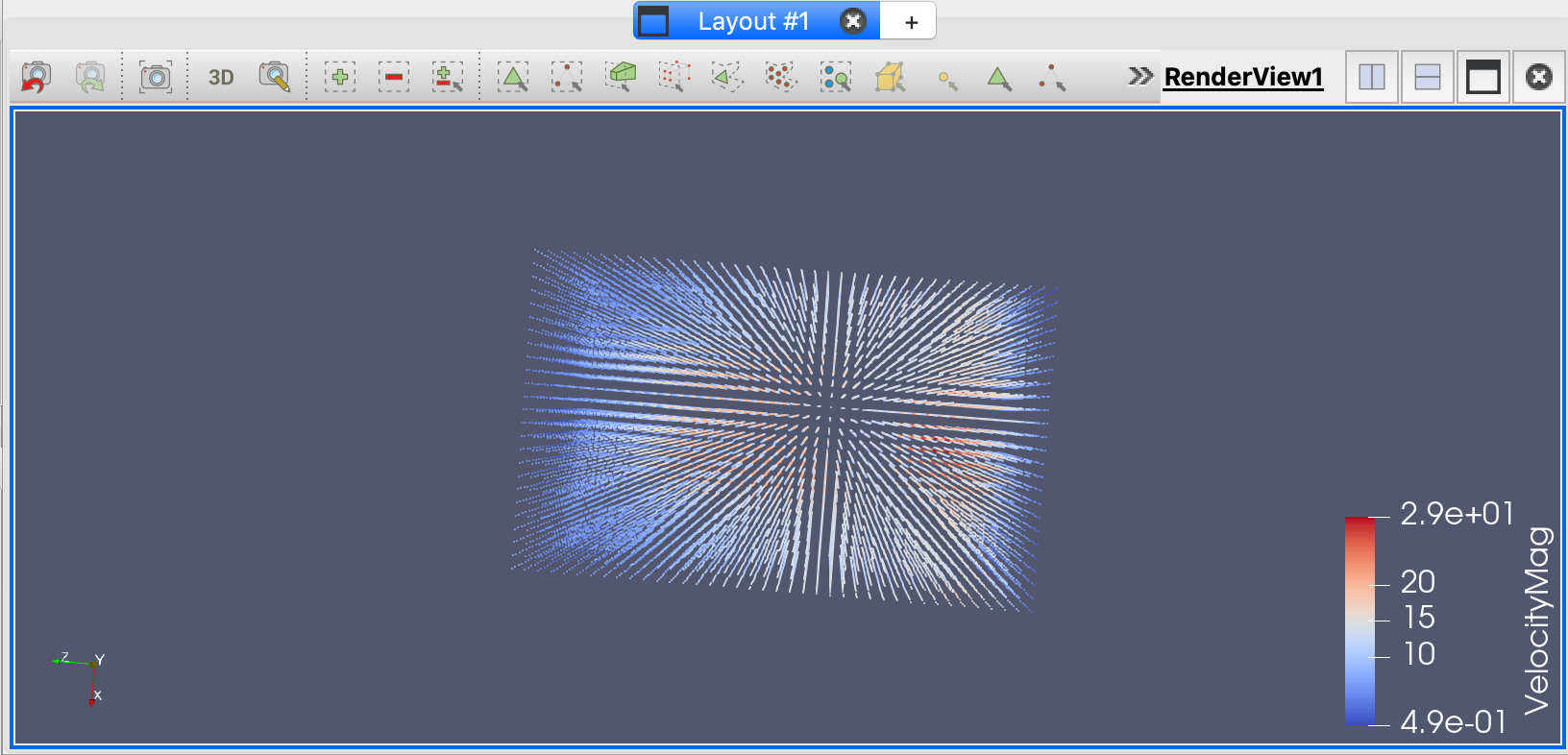
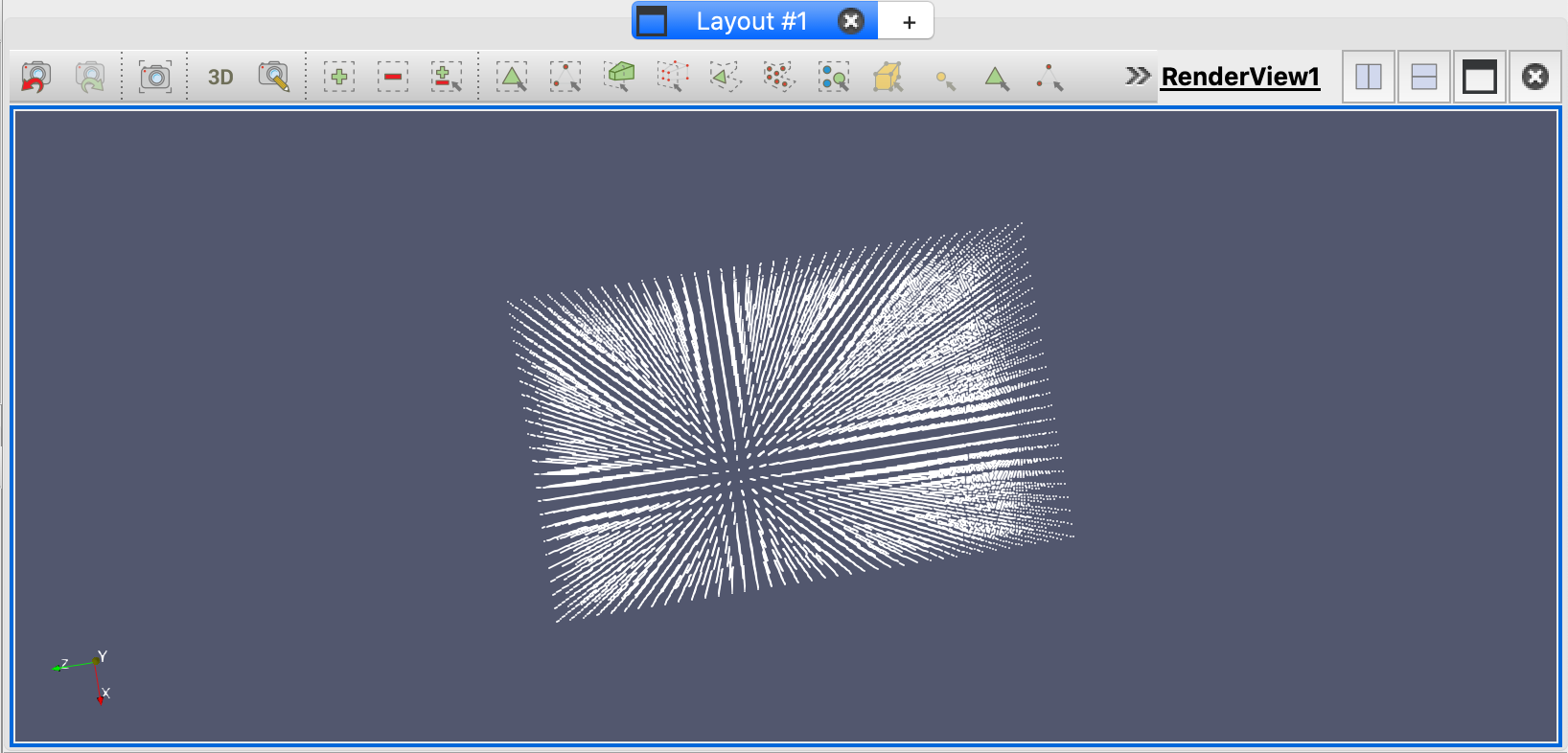
- 我们构建到这一点的管道(如上所示)创建了一个多边形网格数据集,其中只包含点:输入点位置及其各自的3D速度向量。可以在pipeline中Calculator的Information选项卡上看到这一点。注意,这里只有一个单元格,它包含了所有的25,000个点。我们还从输入数据中添加了两个量,一个速度矢量和它的大小。
Visualizing the flow field
现在我们的数据已经从CSV输入转换为ParaView数据模型,我们可以开始查看流场了。为此,我们希望使用stream-tracer filter。用这个过滤器,我们模拟在流场的特定位置注入颗粒。基于网格中的速度向量,让这些粒子跟随流动,并随着时间的推移跟踪它们,我们就能在模型中得到流体流动的印象。
stream-tracer filter基于通过数据集的单元跟踪虚拟粒子,即使用3D点定义的模型空间区域。然后,过滤器使用由向量值指示的单元内的流动方向来集成粒子随时间的位置,从而通过数据集创建粒子的轨迹。
但如上所述,目前在我们的数据集中只有一个单元格保存所有的点,这没有提供跟踪粒子的有意义的方法。因此我们需要将数据集域划分为小的单元格。此外,流向量值目前只与数据集的点相关联,而我们需要为每个单元格提供这些值,以便流跟踪器工作。
我们可以通过应用3D Delaunay triangulation来解决这两个问题。这将根据现有点从数据集中创建单元格。创建的单元格足够小和详细,以便我们的stream-tracer filter可以合理地工作。过滤器还为每个创建的单元添加了一个新的流向量值,这是基于对其角落的现有每个点值进行插值。
- 选中Calculator2然后添加一个Delaunay 3D filter,通过Filters->Alphabetical->Delaunay3D点击Apply。在3D视图中,数据的表示现在将变成一个块,而不是点,这表明现在有单元格占据了3D空间的区域。
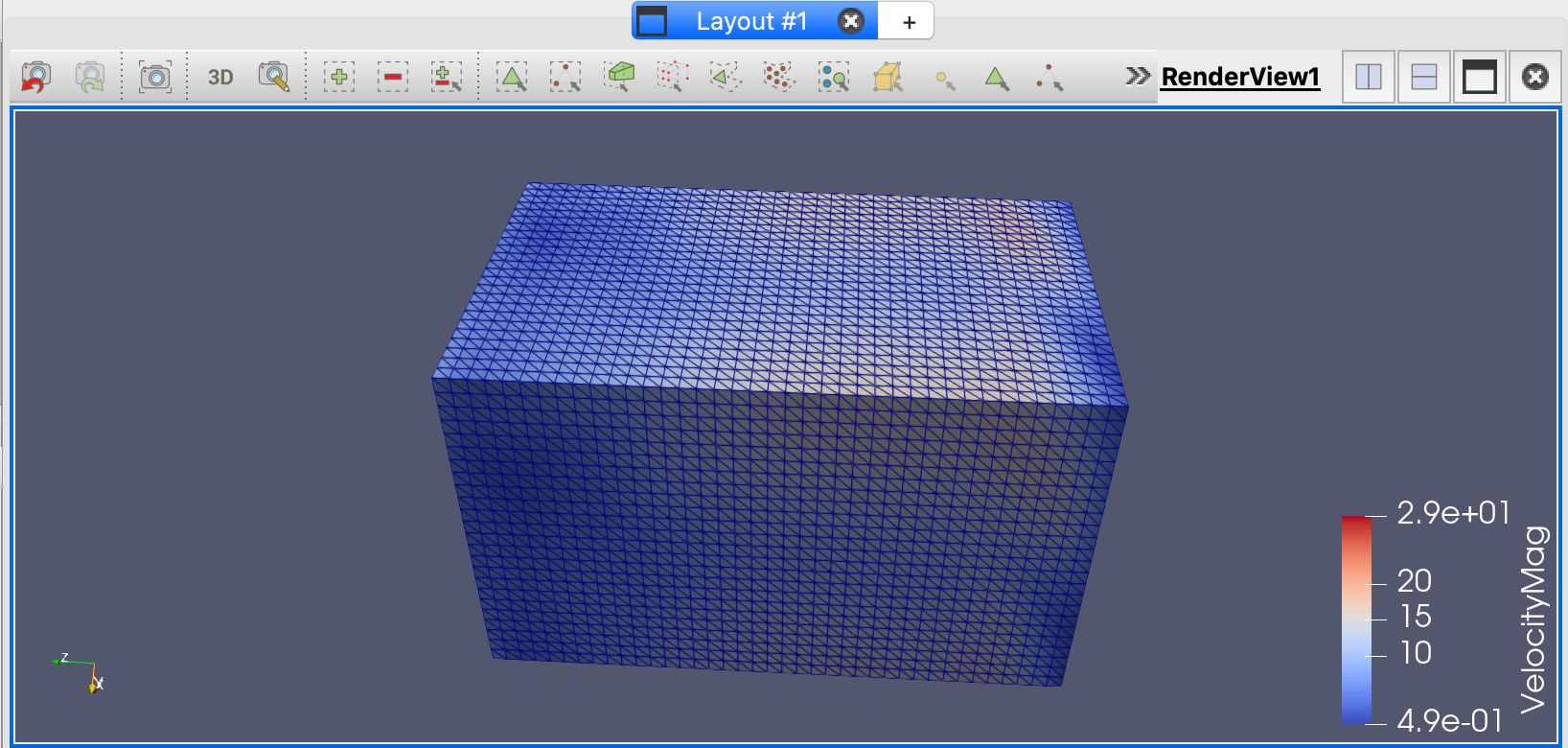
- 检查过滤器的Information选项卡,并切换到Surface with Edges,以查看数据在类型、单元格和点方面的变化情况。还可以使用Clip filter剪辑数据集的一部分,以查看数据集内部的单元格结构。

现在让我们使用stream tracer filter在流场中做一些初始粒子跟踪。
- 在管道中,选择Delaunay3D并添加一个Stream Tracer filter。你可以在Filters → Common → Stream Tracer下找到它,先不要点击Apply。
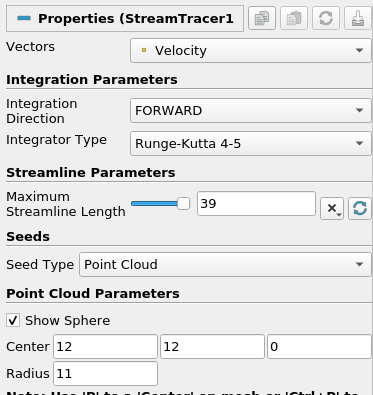
- Stream Tracer filter有很多参数。重要的是积分设置和粒子跟踪的种子位置。例如,将它们更改为下面的值,然后单击Apply:
这将显示一组线,每条线代表一个粒子的痕迹,因为它跟随龙卷风的流动。
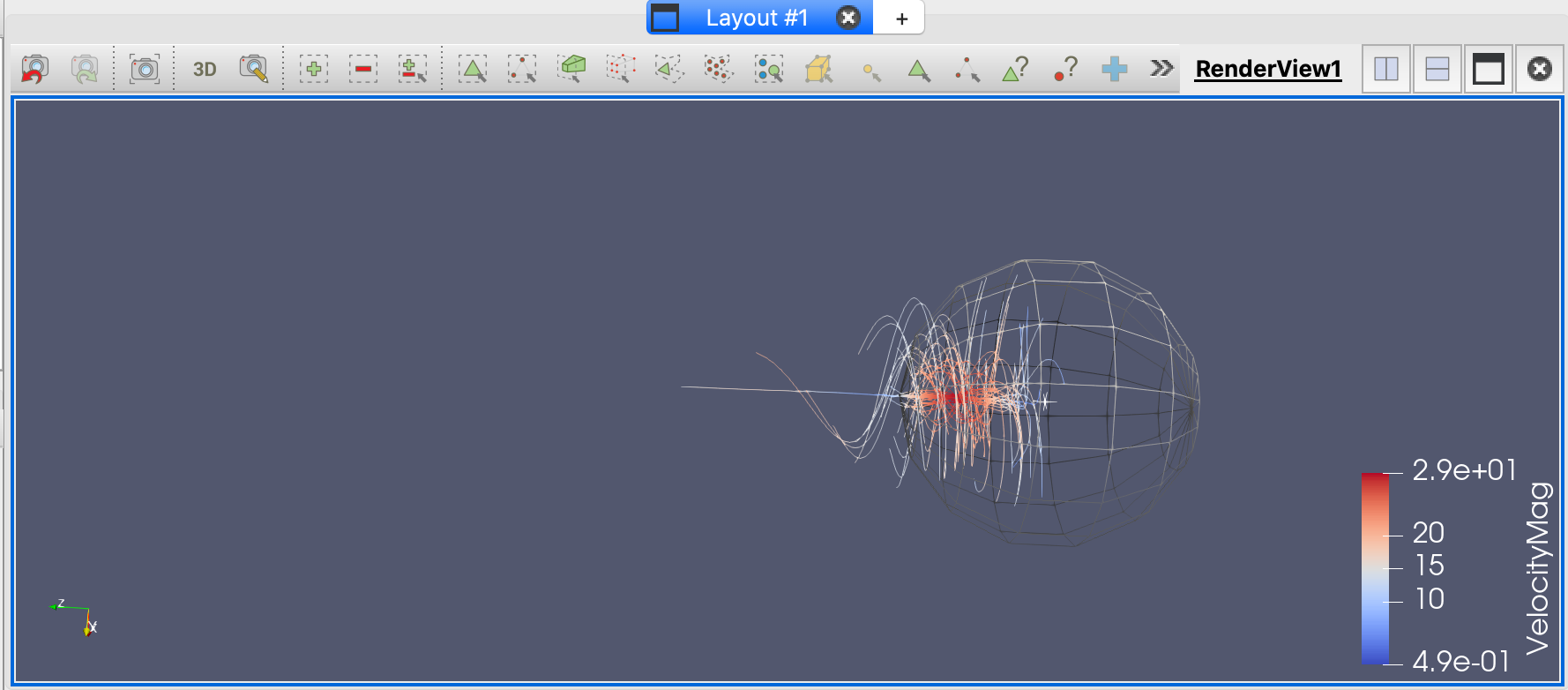
注意龙卷风底部的小的白色3D轴和大的球体:这是种子点(12,12,0)加上给定的半径,跟踪粒子开始围绕它开始。你可以尝试不同位置的种子点,看看这是如何影响流线。
- 为了使流线在视觉上更吸引人,我们在StreamTracer过滤器的输出上添加了另一个过滤器,即Tube filter(Filters → Alphabetical → Tube)。在过滤器的Properties中设置管的半径为0.1,并单击应用。注意这是如何改变流线的外观的。

如果你喜欢,在这一点上,你可以实验不同的颜色的管道,基于例如速度,角速度或旋转。使用“Coloring”下的着色控件。
Glyphs
最后,我们将添加一种不同的表示,而不是流线,称为字形。字形通常是小而简单的3D对象,如箭头或球体,它们被放置在数据集中的每个点位置以显示特定的值。然后根据该位置的标量或向量值对字形进行着色、缩放和/或定向。我们将使用箭头符号来显示龙卷风中的流速大小和方向。
- 通过单击相关的眼睛图标隐藏所有过滤器输出。
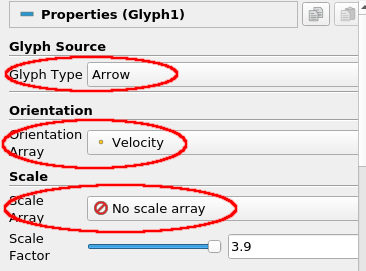
- 选择Calculator2过滤器并添加一个Glyph filter(Filters→Common→Glyphs)。将字形类型设置为Arrow,将Orientation Array设置为Velocity(即我们计算的速度向量),缩放模式设置为无缩放数组。单击Apply。注意,没有必要将Glyph过滤器建立在Delaunay 3D输出的基础上,因为Glyph过滤器只在原始数据集中的3D点上工作,而不是在我们用Delaunay 3D过滤器添加的单元格上。
- 现在应该看到大量的箭头分布在龙卷风数据集上,指示气流的方向。当我们将缩放模式设置为关闭时,所有的箭头都是相同的大小,没有风速的线索。
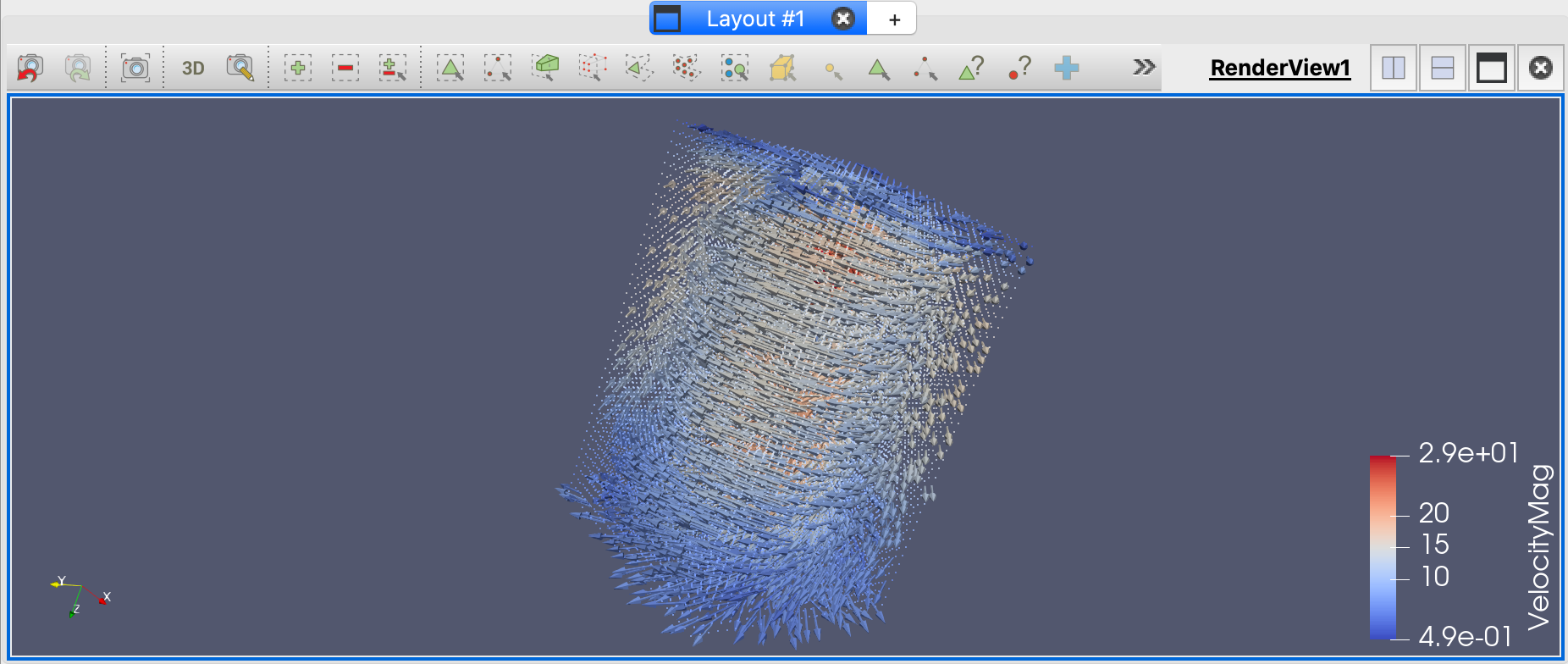
- 将Scale Array设置为Velocity,Scale Factor设置为0.2,点击Apply。
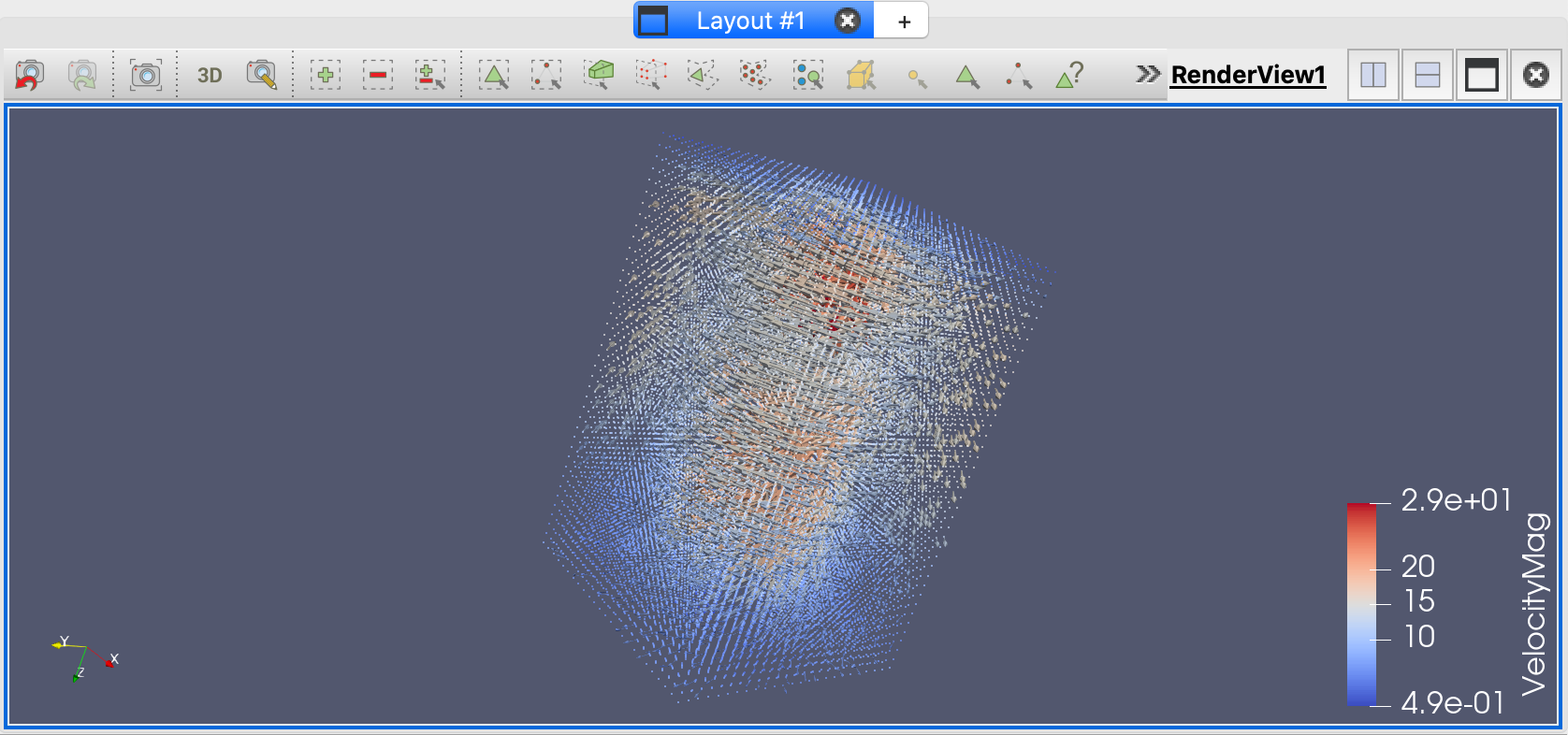
- 确保coloring设置为VelocityMag,并验证字形箭头的大小和颜色与其速度值是否相对应。
- 我们可能已经注意到,所放置的字形的数量比数据集中的点的数量要小得多。这实际上是有意义的,否则视图中会有太多重叠的字形,无法理解它们。但是仍然有相当多的字形,也许还是太多了。Masking下的设置控制放置的符号的数量和分布。看看当您为每10个点显示一个字形或仅均匀分布500个字形时,结果可视化会发生什么(以及为什么这意味着您需要小心选择这些类型的参数)。
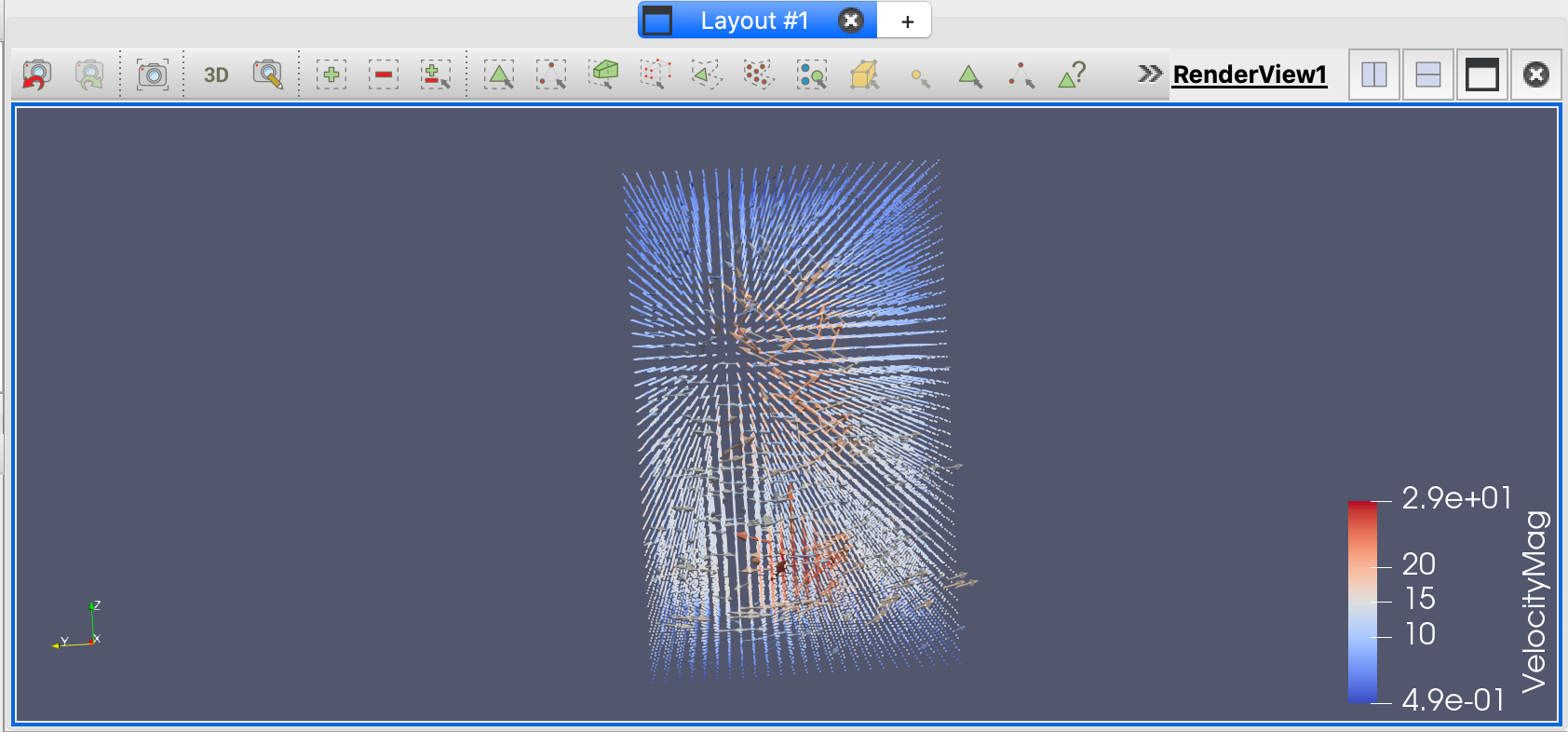
- 一个有用的变体是将glyphs应用到流跟踪过滤器的输出(通过创建第二个Stream Trace filter)。这是可能的,因为生成的流线本身就是多边形数据,其中每个流线由使用一组3D点的polyline单元格组成。由于字形过滤器使用点位置来放置字形,我们可以将字形添加到流线。尝试使用不同类型的符号,如球体和箭头。还可以尝试IntegrationTime着色,以验证流线“生长”的方向。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号