深度学习入门(4)
原文参考链接🔗:https://developer.aliyun.com/article/91436
机器学习的三个层次
机器学习的学习对象是数据,数据是否有标签,就是机器学习所处的“环境”,“环境”不一样,“环境”不一样,其表现出来的“性情”也有所不同,大致分为三类:
(1)监督学习(Supervised Learning):监督学习基本上就是“分类”的代名词。它从有标签的训练数据中学习,然后给定某个新数据,预测它的标签。这里的标签,其实就是某个事物的分类。
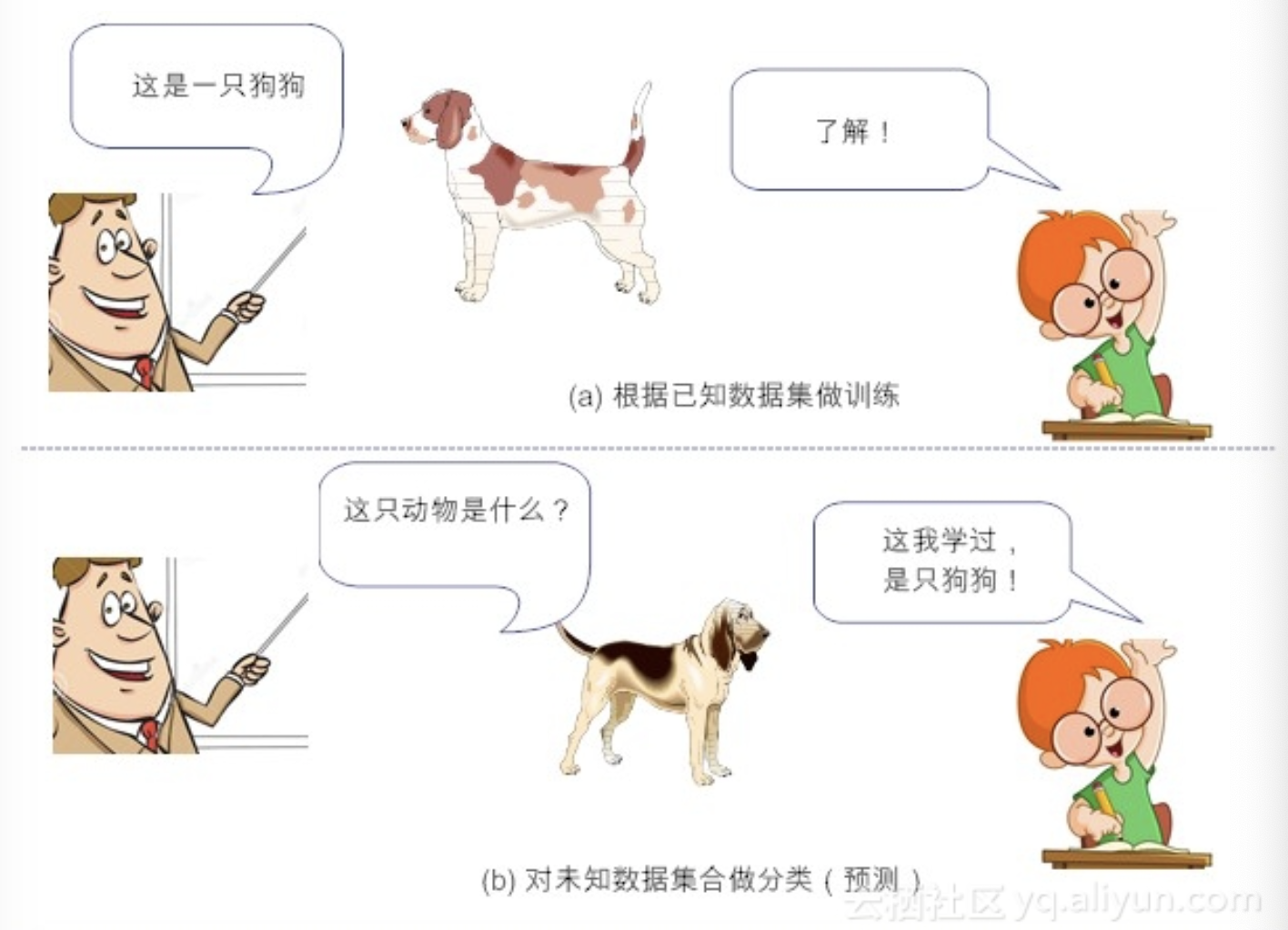
简单来说,监督学习的工作,就是通过有标签的数据训练,获得一个模型,然后通过构建的模型,给新数据添加上特定的标签。
事实上,整个机器学习的目标,都是使学习得到的模型,能很好地适用于“新样本”,而不是仅仅在训练样本上工作得很好。通过训练得到的模型,适用于新样本的能力,称之为“泛化能力”。
(2)非监督学习(Unsupervised Learning):与监督学习相反的是,非监督学习所处的学习环境,都是非标签的数据。非监督学习,本质上,就是“聚类”的近义词。
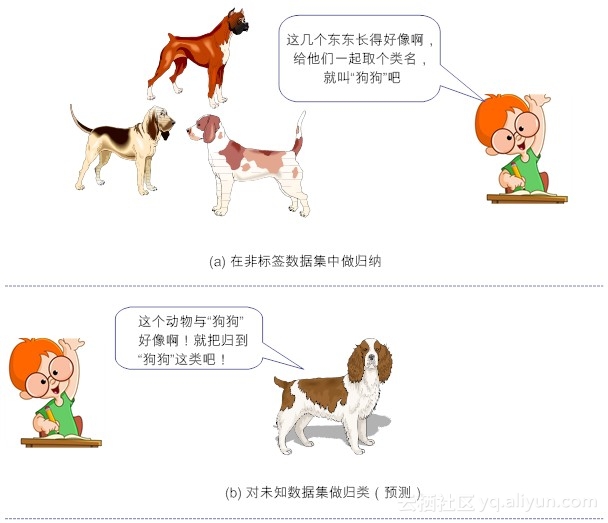
简单来说,给定数据,从数据中学,能学到什么,就看数据本身具备什么特性了。我们常说的“物以类聚,人以群分”说的就是“非监督学习”。这里的“类”也好,“群”也罢,事先我们是不知道的,一旦我们归纳出“类”或“群”的特征,从而完成新数据的“分类”或“分群”功能。
(3)半监督学习(Semi-supervised Learning):这类学习方式,既用到了标签数据,又用到了非标签数据。以下给出它的形式化定义:
给定一个来自某未知分布的有标记示例集L={(x1, y1), (x2, y2), ..., (xl, yl)},其中xi是数据,yi是标签。对于一个未标记示例集U = {xl+1, x l+1, ... , xl+u},l<<u,于是,我们期望学得函数 f:X→Y 可以准确地对未标识的数据xi预测其标记yi。这里均为d维向量, yi∈Y为示例xi的标记。

形式化的定义比较抽象,下面我们列举一个现实生活中的例子,来辅助说明这个概念。假设我们已经学习到:
(1)马晓云同学(数据1)是个牛逼的人(标签:牛逼的人)
(2)马晓腾同学(数据2)是个牛逼的人(标签:牛逼的人)
(3)假设我们并不知道李晓红同学(数据3)是谁,也不知道他牛不牛逼,但是考虑他经常和两位同学共同出没于高规格大会,都经常会被达官贵人接见(也就是说他们虽然独立,但是同分布),我们很容易根据“物以类聚,人以群分”的思想,把李晓红同学打上标签:他也是个很牛逼的人!
这样一来,我们的已知领域(标签数据)就扩大了(由两个扩大到三个),这也就完成了半监督学习。事实上,半监督学习就是以“已知之认知(标签化的分类信息)”,扩大“未知之领域(通过聚类思想将未知事物归类为已知事物)”。但这里隐含了一个基本假设--“聚类假设”,其核心要义就是:“相似的样本,拥有相似的输出”。
事实上,我们对半监督学习的现实需求,是非常强烈的。其原因很简单,就是因为人们能收集到的标签数据十分有限,而手工标记数据需要耗费大量的人力物力成本,但非标签数据却大量存在且触手可及,这个现象在互联网数据中更为凸显,“半监督学习”就显得尤为重要性。
人类的知识,其实都是这样,以“半监督”的滚雪球的模式,越扩越大。“半监督学习”既用到了“监督学习”,也吸纳了“非监督学习”的优点,二者兼顾。
如此一来,“半监督学习”就有点类似于我们中华文化的“中庸之道”了。
接下来聊聊机器学习中的“中庸之道”。
从“中庸之道”看机器学习
“中庸”就是告诉我们“在变化中保持不变”。所谓“变化”,就是我们所处的环境变化多端,所以我们也要“随机应变,伺机而动”。而所谓“不变”就是要我们“守住心中底线,中心原则不变”。二者在一起,“中庸之道”就是要告诉我们在灵活性和原则性之间,保持一个最佳的平衡。
“监督学习”,就是告诉你“正误之道”,即有“不变”之原则。而“非监督学习”,就有点“随心所欲,变化多端”,不易收敛,很易“无根”。
那“中庸之道”的机器学习应该是怎样的呢?自然是“半监督学习”,做有弹性的坚定学习。这里的“坚定”自然就是“监督学习”,而“有弹性”自然就是“非监督学习”。
“有弹性”的变化,不是简单的加加减减,而是要求导数(变化),而且还可能是导数的导数(变化中的变化)。只有这样,我们才能达到学习最本质的需求--性能的提升。在机器学习中,不正是以提高性能为原则,用梯度(导数)递减的方式来完成的吗?
小结
在本小节中,我们主要回顾了机器学习的三种主要形式:监督学习、非监督学习和半监督学习。他们之间的核心区别在于是否(部分)使用了标签数据。
然后我们又从“中庸之道”,谈了谈机器学习的发展方向,“半监督学习”一定是未来机器学习的大趋势。
在下一小节中,我们会聊一聊具体的神经网络学习算法。我们知道“人之初。性本善”,那么“神经”之初,是什么呢?自然是“感知机”了。下一小节中,我们就非常务实地聊一聊“感知机”的学习算法(并附上源代码),他可是一切网络学习(包括深度学习)的基础。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号