深度学习入门(2)
参考原文链接🔗:https://developer.aliyun.com/article/88300
前面的小节中,我们仅仅泛泛而谈了机器学习、深度学习等概念,在这一小节,我们将给出他的更加准确的形式化描述。
人工智能的“江湖定位”
宏观上来看,人类科学和技术的发展,大致都遵循这样的规律:现象观察、理论提取和人工模拟(或重现)。
简单来说,人工智能就是为机器人赋予人类的智能。由于目前的机器核心部件是由晶体硅构成,所以可称之为“硅基大脑”。而人类的大脑主要由碳水化合物构成,因此可称为“碳基大脑”。
人工智能,通俗来讲,大致就是用“硅基大脑”模拟或重现“碳基大脑”。
深度学习的归属
当下,虽然深度学习领跑人工智能,但是人工智能的研究领域很广,包括计算机视觉、专家系统、机器学习、语音识别等。而机器学习又包括深度学习、监督学习、无监督学习等。简单来讲,机器学习是实现人工智能的一种方法,而深度学习仅仅是实现机器学习的一种技术而已。

对人工智能做任何形式的划分,都可能是有缺陷的。人工智能的各类技术分支,彼此泾渭分明,但实际上,他们之间却可能是阡陌纵横,比如深度学习是无监督的。语音识别可以用深度学习的方法来完成。再比如,图像处理、机器视觉更是当前深度学习的拿手好戏。
人工智能的分支并不是一个有序的树,而是一个彼此缠绕的灌木丛。有时候一个分藤蔓比另一个分藤蔓长的快,并且处于显要地位,那么他就是当时的研究热点。深度学习的前生--神经网络的发展,就是这样的大起大落。
既然我们把深度学习和传统的监督学习单列出来,自然是有一定道理的,因为,深度学习是高度数据依赖型的算法,他的性能通常随着数据量的增加而不断增强,也就是说他的可扩展性显著优于传统的机器学习算法。
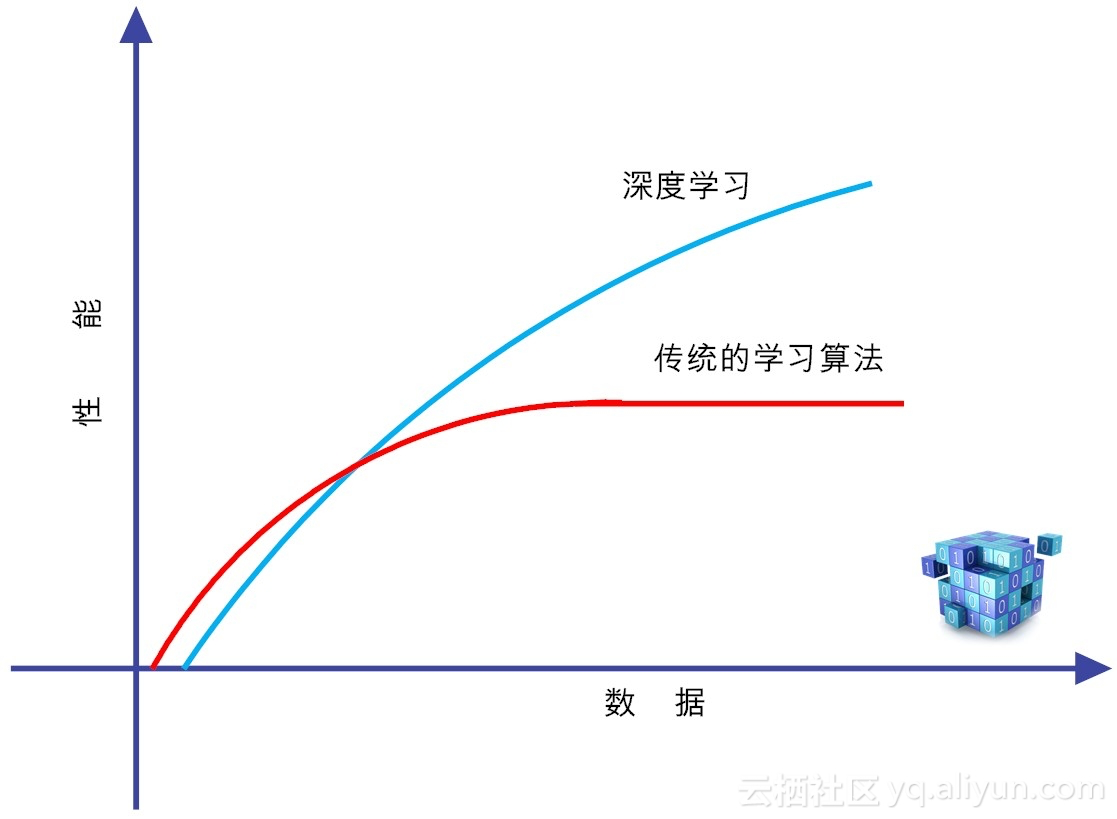
但如果训练数据比较少,深度学习的性能并不见得比传统机器学习好,潜在原因在于,作为复杂系统代表的深度学习算法,只有数据量足够多,才能通过训练,在神经网络中,恰当地把蕴含于数据之中的复杂模式表征出来。
不论机器学习,还是他的特例深度学习,在大致上,都存在两个层面的分析:

机器学习的两层作用:
(1)面向过去(对于收集到的历史数据,用作训练),发现潜藏在数据之下的模式,我们称为描述性分析。
(2)面向未来,基于已经构建的模型,对于新输入数据对象实施预测,我们称之为预测性分析。
前者主要使用了“归纳”,而后者更侧重于“演绎”。对历史现象的归纳,可以让人获得新洞察、新知识,而对新对象实施演绎和预测,可以使机器更加智能,或者说让机器的某些性能得以提高。二者相辅相成,均不可或缺。
前面的部分,我们给出了机器学习的概念性描述,下面我们给出机器学习的形式化定义。
机器学习的形式化定义
人工智能实际上就是找到一种高效的“电子算法”,用以代替或在某项指标上超越人类的“生物算法”。任何一个“电子算法”都要实现一定的功能。
所谓机器学习,在形式上,可近似等同于在数据对象中,通过统计或推理的方法,寻找一个适用特定输入和预期输出的功能函数。习惯上,我们把输入变量写作大写的X,而把输出变量写作大写的Y。所谓的机器学习,在形式上,就是完成如下变换:Y=f(X)。机器学习近似于找一个好用的函数。
每个具体的输入,都是一个实例(instance),它通常由特征向量(feature vector)构成。所有特征向量存在的空间称为特征空间(feature space),特征空间的每个维度,对应于实例的一个特征。
我们需要建立一个评估体系,来辨别函数的好坏。当然,这中间自然需要训练数据来“培养”函数的好品质。学习的核心就是性能改善,通过训练数据,我们把f1改善成f2的样子,性能(判定的准确度)得以改善了,这就是学习。很自然,这个学习的过程如果是在机器上完成的,那就是“机器学习”了。
具体说,机器学习要想做的好,需要走好三大步:
(1)如何找一系列函数来实现预期的功能,这就是建模问题。
(2)如何找出一组合理的评价标准,来评估函数的好坏,这是评价问题。
(3)如何快速找到性能最佳的函数,这就是优化问题(比如说,机器学习中梯度下降法干的就是这个活)。
为什么要用神经网络?
深度学习的概念源于人工神经网络的研究,含多隐层的多层感知机就是一种深度学习结构。说到深度学习就不能不提神经网络。
什么是神经网络呢?
神经网络,是一种由具有自适应性的简单单元构成的广泛并行互联的网络,它的组织结构能够模拟生物神经系统对真实世界所作出的交互反应。
在机器学习中,我们常常提到“神经网络”,实际上是指“神经网络学习”。
为什么要使用神经网络学习呢?
在人工智能领域,有两大主流门派。第一个门派是符号主义。符号主义的理念是,知识是信息的一种表达形式,人工智能的核心任务,就是处理好知识表示、知识推理和知识运用。这个门派核心方法论是,自顶向下设计规则,然后通过各种推理,逐步解决问题。
还有一个门派,就是试图编写一个通用模型,然后通过数据训练,不断改善模型中的参数,知道输出的结果符合预期,这个门派就是连接主义。连接主义认为,人的思维就是某些神经元的组合。因此,可以在网络层次上模拟人的认知功能,用人脑的并行处理模式,来表征认知过程。这种受神经科学启发的网络,被称之为人工神经网络(ANN)。目前,这个网络的升级版,就是深度学习。
机器学习在本质上就是寻找一个好用的函数。人工神经网络最强的地方在于,他可以在理论上证明:只需一个包含足够多神经元的隐藏层,多层前馈网络能以任意精度逼近任意复杂度的连续函数。这个定理也被称之为通用近似定理。神经网络可以在理论上解决任何问题,这就是目前深度学习能够十分强大的最底层逻辑。
小结
本小节中,我们首先指出深度学习仅仅是人工智能研究的一个很小的分支,接着我们给出了机器学习的形式化定义。最后我们回答了为什么人工神经网络能“风起云涌”,在理论上可以证明,它能以任意精度逼近任意形式的连续函数,而机器学习的本质,不就是要找到一个好用的函数吗?
在下一小节,我们将深度解读什么是激活函数,什么是卷积?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号