集合(五) TreeMap
4.TreeMap
SortedMap接口继承Map接口,是排序键值对的接口,实现排序的的方法是Comparator。而NavigableMap接口继承于SortedMap,新增了一些导航方法。而TreeMap继承AbstractMap并实现NavigableMap接口,不同于HashMap的无序集合,TreeMap是有序的集合,通过红黑树实现。此外由于树的引入,各种操作的复杂度将为O(logn)。另外,TreeMap是非同步的。 因此它的遍历Iterator方法返回的迭代器是fail-fast的。
(1)红黑树
TreeMap基于红黑树实现,因此简单介绍一下红黑树的性质,有一个基本的了解。但是并不在此详细展开,之后应该会单独开篇讲解。
 图片来源:https://www.imooc.com/article/21650?block_id=tuijian_wz
图片来源:https://www.imooc.com/article/21650?block_id=tuijian_wz
红黑树的性质有如下几条:
- 节点是红色或黑色。
- 根是黑色。
- 所有叶子都是黑色(叶子是NIL节点)。
- 每个红色节点必须有两个黑色的子节点。(从每个叶子到根的所有路径上不能有两个连续的红色节点。)
- 从任一节点到其每个叶子的所有简单路径都包含相同数目的黑色节点。
(2)构造函数
TreeMap常用的构造函数有以下四种:
// 默认构造函数。使用该构造函数,TreeMap中的元素按照自然排序进行排列。 TreeMap()
// 指定Tree的比较器
TreeMap(Comparator<? super K> comparator)
// 创建的TreeMap包含Map TreeMap(Map<? extends K, ? extends V> copyFrom)
TreeMap(SortedMap<K, ? extends V> copyFrom)
后面两个构造函数很很明显参数一个是Map对象,一个是SortedMap对象。而第一个是默认构造函数,key的排列顺序将按照自然的排序,这里Java有一套默认的排序机制,这里先按下不表。第二个构造函数拥有一个Comparator对象的参数,可以自己设定key排序的机制。下面展示TreeMap对比于HashMap的排序功能。
public static void main(String []args) { TreeMap <Integer, String> tm = new TreeMap(); HashMap <Integer, String> hm = new HashMap(); for(int i = 5; i >= 0; i--) { char b = (char) (i+48+16); tm.put(i*i, String.valueOf(b)); hm.put(i*i, String.valueOf(b)); } System.out.println(hm); System.out.println(tm); }
这里不需要遍历,因此查看键值对直接打印即可,他们已经重写了toString()方法,结果如下
{16=D, 0=@, 1=A, 4=B, 25=E, 9=C}
{0=@, 1=A, 4=B, 9=C, 16=D, 25=E}
可以看出,TreeMap已经将键按照从小到大的顺序排列好了,而HashMap则是无序的键值对。自然而然的,如果java自带的排序不满足我们的需求呢?比如我们想要的是降序而不是升序呢?这是就需要第二个构造函数出场了。
TreeMap <Integer, String> tm1 = new TreeMap(Comparator.reverseOrder()); TreeMap <Integer, String> tm2 = new TreeMap(); for(int i = 5; i >= 0; i--) { char b = (char) (i+48+16); tm1.put(i, String.valueOf(b)); tm2.put(i, String.valueOf(b)); } System.out.println(tm1); System.out.println(tm2);
{5=E, 4=D, 3=C, 2=B, 1=A, 0=@}
{0=@, 1=A, 2=B, 3=C, 4=D, 5=E}
可以看出参数为Comparator.reverseOrder()的结果和默认正好相反.那么除此之外,我们还可以自定义的实现Comparator,比如按照value值排序(只能按照key排序,改为按照key的平方降序排序),我们只需重写Comaprator的接口中的compare()方法即可。
// Comparator实现 class Com implements Comparator <Integer> { public int compare(Integer t1, Integer t2) { if (t1*t1<t2*t2) return 1; else return -1; } }
// main function TreeMap <Integer, String> tm1 = new TreeMap(); TreeMap <Integer, String> tm2 = new TreeMap(new Com()); int flag =1; for(int i = 5; i >= 0; i--) { flag = - flag; char b = (char) (i+48+16); tm1.put(i*flag, String.valueOf(b)); tm2.put(i*flag, String.valueOf(b)); } System.out.println(tm1); System.out.println(tm2);
{-5=E, -3=C, -1=A, 0=@, 2=B, 4=D}
{-5=E, 4=D, -3=C, 2=B, -1=A, 0=@}
(3)操作方法
其实作为吃瓜群众最关心的还是增删改查遍历等基础功能,接下来就展示一下这些方法的操作。
增加元素前面已经使用过了,就是put(K,V)方法;或者putAll(Map map)直接添加一个Map;
删除元素则是使用remove(K)根据key删除数据;clear()清空;
System.out.println(tm1); System.out.println(tm2); /* API - add*/ tm1.put(new Integer(1),"wu"); tm2.putAll(tm1); System.out.println(tm1); System.out.println(tm2); /* API - remove */ tm1.remove(-5); // I don't want to test the clear() System.out.println(tm1);
结果如下:
{-5=E, -3=C, -1=A, 0=@, 2=B, 4=D}
{-5=E, 4=D, -3=C, 2=B, -1=A, 0=@}
{-5=E, -3=C, -1=A, 0=@, 1=wu, 2=B, 4=D}
{-5=E, 4=D, -3=C, 2=B, -1=wu, 0=@}
{-3=C, -1=A, 0=@, 1=wu, 2=B, 4=D}
基本在意料之中,但是有一点需要额外说明一下,putAll()方法使用之后,发现被添加的tm2对象反而拥有更少的元素,原因在于上一段代码中的Com类被我修改成了:
public int compare(Integer t1, Integer t2) { if (t1*t1<t2*t2) return 1; else if (t1*t1>t2*t2) return -1; else return 0; }
发现区别了吗?没错!正是添加了返回值为0的情况,当两个值相等时我们返回0,经过我的测试后发现,返回0时,即代表认为这两个节点相同,则会发生覆盖现象。那值怎么保留呢?我觉得应该是随机的(未经证实),所以如果不想发生覆盖,那就补要返回0值,还是按照上面代码中的((2)中的Comparator实现)
再来查操作,
boolean containsKey(K),containsValue(V)查找是否有含有对应参数的节点;Map.Entry<K,V> firstEntry()返回该TreeMap的第一个(最小的)映射;K firstKey()返回该TreeMap的第一个(最小的)映射的key;Map.Entry <K,V> lastEntry()返回该TreeMap的最后一个节点;K lastKey()返回该TreeMap的最后一个节点的key ;
V get(K)获得键值为K的值;SortedMap <K,V> headMap(K)返回在参数key之前的节点集合;SortedMap <K,V> submap(K,K)返回两个参数之间的节点集合;
System.out.println(tm1); /* API - search */ Map.Entry me = tm1.firstEntry(); System.out.println("The first key is "+me.getKey()+ " and the first value is "+ me.getValue()); Integer j =tm1.lastKey(); System.out.println("The last key is "+j); String s = tm1.get(3); System.out.println(s); SortedMap sm = tm1.headMap(3); System.out.println("The new map sm is \n"+sm); SortedMap sm2 = tm1.subMap(-4,5); System.out.println("The new map sm2 is \n"+sm2);
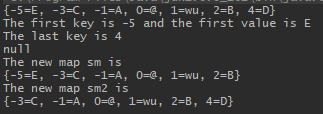
基本不出意料,值得一提的时=是,如果getKey方法中没有对应键,则会返回null;
还有改,V replace(K,V)替换指定key对应的value值为参数;boolean replace(K,V,V)当指定key的对应的value为指定值时,替换该值为新值;
遍历也是很重要的一个功能,Set<Map<K,V>> entrySet()返回由该TreeMap中的所有节点的组合为的Set对象;keySet()获得键组成的集合;而values()返回由该TreeMap中所有值构成的集合;
除了增删改查和遍历之外,还有一些其他功能,比如comparator()返回排序的Comparator对象;int size()返回长度;以下是这些API使用实例,先来增删,
/* API - replace & traversal */ tm1.replace(0,"yi"); Set meAll = tm1.entrySet(); Iterator it = meAll.iterator(); while (it.hasNext()) { Map.Entry Node = (Map.Entry)it.next(); // System.out.println(Node); System.out.println("Key: "+Node.getKey()+" Value: "+Node.getValue()+" "); } System.out.println("________________________________________"); tm1.replace(-1,"A","ming"); Set keySet = tm1.keySet(); for (Object o: keySet) { Integer a =(Integer) o; System.out.print(a+" "); } System.out.println("\n________________________________________"); Collection values = tm1.values(); Iterator it2 = values.iterator(); while (it2.hasNext()) { System.out.print(it2.next()+" "); } /* API - others */ System.out.println("\n"); System.out.println("The length is "+tm1.size());
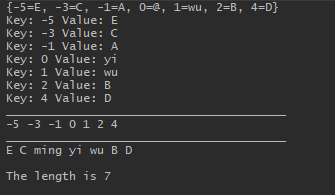
需要提的,keySet()和entrySet()返回的都是Set集合,前者集合中元素是Map.Entry对象,而后者是Object对象,因此需要转换为key相应的类;而values()方法返回的是Collection对象,集合中每个元素是Object对象;
另外,replace(K,V1,V2)指将V1替换为V2,但是如果V1并不存在的情况下,不执行任何操作,仅返回false;至于compartor()将会返回Com类的实例对象(你构造时使用的参数,不过我们使用的是匿名的,没有返回null)。
(4)Comparable和Comparator
i)实现方法不同
Comparator接口实现compare(obj1,obj2)方法,依赖于两个参数互相比较,需要一个新类来实现接口;而Comparable接口实现compareTo(obj),靠的是参数与this的成员域之间进行比较,因此一般只需要在比较的类中实现覆盖的方法即可。
ii)调用形式不同
Comparable既然在类中实现,那么sort()方法调用只需要一个待比较的对象就好;Comparator则需要两个参数,除了待比较的对象还需要实现Comparator接口本身的对象;
iii)具体示例
Comparator和Comparable一般的使用场景,可能就是sort()方法(当然还有其他地方出现,例如Comparator在TreeMap中的应用),这是一个在java.util.Collection中的方法。
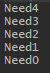
package Compare; import static java.util.Arrays.sort; public class Need implements Comparable<Need>{ int score; public Need(int i) { score = i; } @Override public int compareTo(Need o) { // Only one parameter if(this.score>o.score) return -1; //From big to small else return 1; } @Override public String toString() { return "Need"+score; } public static void main(String []args) { Need [] n = new Need[5]; for (int i = 0; i<5;i++) { n[i] = new Need(i); } sort(n); //Also one parameter for(Need ne:n) System.out.println(ne.toString()); } }
以上,即是Comparable接口实现排序的基本操作,结果
还有Comparator
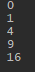
package Compare; import java.util.Comparator; import static java.util.Arrays.sort; class Com implements Comparator<Need2> { @Override public int compare(Need2 o1, Need2 o2) { //Two parameter if(o1.getScore()>o2.getScore()) { return 1; //From small to big } else { return -1; } } } public class Need2 { private int score; public void setScore(int score) { this.score = score; } public int getScore() { return this.score; } public static void main(String []args) { Need2 [] n = new Need2[5]; for (int i = 0; i<5;i++) { n[i]=new Need2(); n[i].setScore(i*i); } sort(n,new Com()); //Also two parameter for(Need2 ne:n) System.out.println(ne.getScore()); } }
本例通过从小到大排序score的平方来简单的实现Comapator的功能,通过对比,两者的区别会更加impressed

 浙公网安备 33010602011771号
浙公网安备 33010602011771号