Java I/O(二)其他常用的输入输出流PrintStream等、标准流重定向
四、FilterOutputStream、PrintStream
PrintStream是继承自FilterStream类的,例如标准输出流System.out就是著名的PrintStream类对象。相比较于FileOutputStream,有以下三个有点:
(1)输出类型灵活,可以是int、float、char,还包括char []和String类型,格式也比较多变
(2)成员方法大多不抛异常
(3)可以选择是否需要采用自动强制输出特性。
PrintStream类构造函数常用的有四个,参数可以是(1)OutputStream及其子类,当然包括FileOutputStream类;(2)File类;(3)String文件名;(4)OutputStream类型加autoflush,没有这个参数默认为false。这个参数的意义在于强制调用flush方法,即往PrintStream里写入数据都会立即调用flush()函数。
输出的API方法主要有以下几种:
void write(int b)方法可以b的低8位组成的1字节写入文件
void append(char c)
void print(X x)参数可以是int、double、String、char[]等
void println(X x)参数同上,但是会有换行
void println()只换行
void PrintStream format(String Format,Object …args)
void PrintStream printf(String Format,Object …args)按相应格式输出


——————上述都是写入方法——————
void flush () 强制输出
void close () 关闭流
package filter; import java.io.FileNotFoundException; import java.io.IOException; import java.io.PrintStream; public class Pstream { public static void main(String [] args) { /*PrintStream*/ byte [] o="floyd".getBytes(); try { PrintStream ps=new PrintStream("G:\\home\\dir\\test.txt"); ps.write(o); ps.println(); ps.println("int"); ps.format("%S", "are you OK?"); ps.close(); } catch (FileNotFoundException e) { // TODO Auto-generated catch block e.printStackTrace(); } catch(IOException e) { e.printStackTrace(); } /**/ } }
文件test.txt内容为:
floyd
int
ARE YOU OK?
这里还是想学习一下format相关知识(注:printf()函数和format()功能完全一致):
%[参数索引$][字符集类型][宽度][.精度]变换类型
中括号内是可有可无内容,也即只有%和变换类型是必须的,如上面程序中的例子便是,参数索引$容易理解,是选择第几个来替代这个地方,如2$就是第2个参数,举个例子
ps.format("%2$S", "are you OK?","Yes, I am fine.");
将上文中程序代码改为这个,输出就会变为YES, I AM FINE.但是没有的话就会默认是第一个。
宽度指得是最少输出字符数(不是最多哦),格式需要是大于0的十进制整数,例如
ps.format("%2$20S", "are you OK?","Yes, I am fine.");
最少要输出20个字符,但是只有15个,那么怎么办呢?看一下文件立马清楚,就是在左端补齐空格,以上为例就会补齐5个空格:

.精度表示转换精度,也是大于0的十进制整数,:
ps.format("%2$20.3S", "are you OK?","Yes, I am fine.");
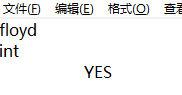 可以看出只输出前3位,但是若是浮点类型,会变成保留小数点后3位。但是用在int上就会报错,其余类型暂时还没试过。MARK
可以看出只输出前3位,但是若是浮点类型,会变成保留小数点后3位。但是用在int上就会报错,其余类型暂时还没试过。MARK
还有最后一项字符集类型,具体所指意涵我不是很清楚,但是我觉得应该是指转换符,例如:
ps.format("%2$+20.3f", 100.0/3,-10000.0/6);
例如这里我用的是+,代表要分正负,最终结果
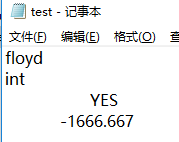
当然转换符还有很多
 来源:https://kgd1120.iteye.com/blog/1293633
来源:https://kgd1120.iteye.com/blog/1293633
五、DataOutputStream DataInputStream
称为数据输入输出流,学过PrintStream之后,在看数据的输入输出流就会亲切很多,因为它们主要功能很相似,都是为了提供仰视灵活的输入 or 输出。当然也有一些不同。
DataOutputStream与PrintStream的相同点:都是为了解决FileOutputStream的一些局限性,这两个能够提供更丰富的输出(写入)功能.
不同点:(1)构造函数不同 DataOutputStream的构造函数只有一个:DataOutputStream(OutputStream out),而PrintStream有很多。
(2)PrintStream能够使用format的输出形式,而DataOutpuStream没有。
(3)异常处理机制不同 等
API使用大都很简单,但是注意DataInputStream要和DataOutputStream配套使用,因为在文件中可能不是你真正的写入内容:
public static void main(String []args) { try { PrintStream ps=new PrintStream("G:\\home\\dir\\data.txt"); //文件不存在也没事,会自动创建一个,这就是输出流的特性,但是没有路径可不行啊! DataOutputStream dos=new DataOutputStream(ps); //也可以以PrintStream对象位参数 dos.writeInt(456); DataInputStream dis=new DataInputStream(new FileInputStream("G:\\home\\dir\\data.txt")); System.out.println(dis.readInt()); //注意配套使用 } catch (FileNotFoundException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } }
左中程序读得了int数据456并成功输出,但是打开文件来看,却是乱码:
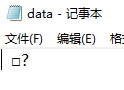
但是注意到一个方法writeUTF()比较与众不同,使用起来倒是没什么困难:
public static void main(String []args) { try { PrintStream ps=new PrintStream("G:\\home\\dir\\data.txt"); DataOutputStream dos=new DataOutputStream(ps); String s="Wuyiming"; dos.writeUTF(s); DataInputStream dis=new DataInputStream(new FileInputStream("G:\\home\\dir\\data.txt")); System.out.println(dis.readUTF()); } catch (FileNotFoundException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } }
查看文件内容: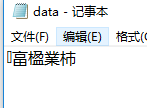
补:抛去代码不讲,倒是想看一看关于UTF等编码的事情。有时间另开一篇(拖延ing......)
六、BufferedInputStream和BufferedOutputStream
称为缓冲输入输出流,和PrintStream、DataOutputStream同样属于FilteOutrStream的子类(针对输出来说),它是为了解决FileOutputStream另一些问题,即效率问题。通过设置缓冲区进行交互来提升效率
先从两者的构造函数讲起,输入输出都有两个构造函数:
public BufferedOutputStream(OutputStream out) //默认缓冲大小位
public BufferedOutputStream(OutputStream out,int size) //指定缓冲大小
BufferedOutputStream在使用方面和OutputStream完全相同,只是重写了一些方法。下面讨论一下关于缓冲区的问题:
package filter; import java.io.BufferedOutputStream; import java.io.DataOutputStream; import java.io.FileNotFoundException; import java.io.FileOutputStream; import java.io.IOException; import java.io.PrintStream; public class BufferedStream { public static void main(String [] args) { FileOutputStream ps; try { byte []b= {50,50,51,52,53,54,55,56}; ps = new FileOutputStream("\\data.txt"); BufferedOutputStream bos=new BufferedOutputStream(ps,6); bos.write(120); bos.write(b,0,3); } catch (FileNotFoundException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } } }
从程序中可以看出指定缓冲区大小为6,而写入了4个字节,小于缓冲区长度,因此文件中不会写入任何东西,但是加入flush()或者close()方法,会强制输出在缓冲区的内容到文件中。如果写入的长度大于或者等于6呢?将代码中的改为:
bos.write(-200);
bos.write(b,0,5);
文件中仍没任何输出,可见等于和小于的效果是一样的,都不会自动输出,但若是:
bos.write(-200);
bos.write(b,0,6);
文件中会写入”8223456“,只要写入的内容大于缓冲区大小,就会强制从缓冲区输出。
看到一段flush()方法讲解,觉得不错,复制过来:
FileOutPutStream继承outputStream,并不提供flush()方法的重写所以无论内容多少write都会将二进制流直接传递给底层操作系统的I/O,flush无效果而Buffered系列的输入输出流函数单从Buffered这个单词就可以看出他们是使用缓冲区的,应用程序每次IO都要和设备进行通信,效率很低,因此缓冲区为了提高效率,当写入设备时,先写入缓冲区,等到缓冲区有足够多的数据时,就整体写入设备。
原文:https://blog.csdn.net/aa8568849/article/details/52974619
补:
关于BufferedInputStream其实也是加了缓冲的FileInputStream类,本没什么可讲的,但是前面的FileInputStream由于健忘少讲了几个API,就在这里补一下,就相当于学习ByteArrayOutputStream和ByteArrayInputStream类了,但是很少有对缓冲输入流讨论关于缓冲区大小的影响,我也先在此不表,主要讨论available()、mark()、marksupport()、reset()、skip()等方法的使用。
顺便详细回顾(其实前面没好好学,手动尴尬)write()和read()的使用方法。
write()方法共有三种,分别是:void write(int i);void write(byte []b);void write(byte []b,int off,int len)。
也就是说未经修饰的流只支持这几种数据类型的写方法,整数类型并不是真正的写入这个整数,而是这个整数对应的编码。下面代码是以整数为参数示例,
public static void main(String []args) { try { FileOutputStream fos=new FileOutputStream("\\test.txt"); int a=65; fos.write(a); fos.close(); //以字节读出,然后以字符型输出 FileInputStream fis=new FileInputStream("\\test.txt"); int i=fis.read(); while(i!=-1) { byte b=(byte) i; System.out.print((char)b); i=fis.read(); } fis.close(); } catch (FileNotFoundException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } }
文件显示‘A’,输出也是‘A’。
再来参数为byte[],
byte []b1= {-50,-28};
fos.write(b1);
fos.close();
有趣的是在文件中写入的是汉字“武”,字符输出输出为两个乱码:
 输入输出应该是完全一致,那么问题就牵涉到文件是如何显示的了。(现在还不懂)
输入输出应该是完全一致,那么问题就牵涉到文件是如何显示的了。(现在还不懂)
最后参数是byte数组。但是可以指定开始位置和长度:
byte [] b2= {65,66,67,68,69,70,71,72,73,74,75,76,77,78,79,80};//对应ABCDEFGHIJKLMNOP fos.write(b2,5,5); fos.close();
输出和文件一致,均为“FGHIJ”,由此可见开始位置为5意思就是从b2[5]开始(即第6个元素),往后5个元素结束。
read()同样有三种:int read();int read(byte []b);int read(byte [] b,int off,int len)。
上面的程序使用的方法就是无参的方法,简单的与write(int )一一对应。直接来看参数为byte数组,作用是将内容读出文件到数组中,
FileOutputStream fos=new FileOutputStream("\\test.txt"); byte [] b2= {65,66,67,68,69,70,71,72,73,74,75,76,77,78,79,80};//对应ABCDEFGHIJKLMNOP fos.write(b2); fos.close(); FileInputStream fis=new FileInputStream("\\test.txt"); byte []b3=new byte[4]; byte []b4=new byte[5]; fis.read(b3); //读出前4个 fis.read(b4); //继续读5个 for(byte r:b4) System.out.print((char)r); //输出EFGHI,注意是继续接着读,直到流关闭。 fis.close();
最后3个参数的版本:
byte []b5=new byte[4]; byte []b6=new byte[5]; fis.read(b5,2,2); // ‘ ’ ‘ ’ ‘A' 'B' fis.read(b6,1,3); // ' ' 'C' 'D' 'E' ' ' for(byte r:b6) System.out.println((char)r); fis.close();
第二参数是指写入到数组中从第几个开始,例如b5是2就是从b5[2]开始(第三个元素,这里是下标),b6是从b6[3]开始。第三个参数是读的长度,b5是2,就读两个字节,同样的b6是3个字节。
来看一下其他方法的使用情况:
public static void main(String [] args) { try { /*BufferedOutputStream*/ BufferedOutputStream bos=new BufferedOutputStream(new FileOutputStream("\\test.txt")); byte [] b2= {65,66,67,68,69,70,71,72,73,74,75,76,77,78,79,80};//对应ABCDEFGHIJKLMNOP bos.write(b2); bos.close(); /*BufferedInputStream*/ BufferedInputStream bis=new BufferedInputStream(new FileInputStream("\\test.txt")); byte []b7=new byte[4]; byte []b8=new byte[4]; byte []b9=new byte[4]; System.out.println(bis.available()); //共16个 bis.read(b7); //读取ABCD System.out.println(bis.available()); //16-4=12 if(!bis.markSupported()) { System.out.println("mark not support"); } bis.mark(0); //参数无实际意义,在E处标记 bis.skip(5); //跳过5个,从E跳到J bis.read(b8); //读取JKLM bis.reset(); //回到E处 bis.read(b9); //读取EFGH for(byte r:b7) System.out.print((char)r); System.out.println(); for(byte r:b8) System.out.print((char)r); System.out.println(); for(byte r:b9) System.out.print((char)r); bis.close(); } catch (FileNotFoundException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } }
输出:
16
12
ABCD
JKLM
EFGH
注意只有BufferedInputStream和ByteArrayInputStream这两种类才支持marksupported()方法,之前用FileInputStream类一直报mark not support!available()输出剩余可读数,原有16个字母,读了4个字母到b7后,只剩12个。mark()和reset()配对使用,做标记和返回标记位置。skip(int n)跳过n个字节。
七 标准流重定向
标准流一共有三种,分别是标准输入流System.in,标准输出流System.out,标准错误流System.err
| 属性 | 类型 | 变量 | 说明 |
| static | java.io.BufferedInputStream | System.in | 标准输入流 |
| static | java.io.PrintStream | System.out | 标准输出流 |
| static | java.io.PrintStream | System.err | 标准错误流 |
那么什么是重定向呢?比如要想与用户交互,获得其输入,一般情况是使用Scanner类进行输入,这就很简单了,下面举一个例子:
public static void main(String []args) { Scanner sc=new Scanner (System.in); String s=sc.nextLine(); System.out.println(s); }
你输什么回车之后就打印什么字符串。但是需要人工手动输入,这样有时间会很麻烦,我们有时间想直接从文件中读取,这时间就需要将文件输入流重定向至标准输入流,需要使用到System的成员方法setIn(InputStream in)。
public static void main(String []args) { InputStream is; try { is = new BufferedInputStream(new FileInputStream("\\test.txt")); System.setIn(is); //使用System.in读取就等于从is中读取 Scanner sc=new Scanner (System.in); String s=sc.next(); System.out.println(s); sc.close(); } catch (FileNotFoundException e) { // TODO Auto-generated catch block e.printStackTrace(); } }
上面代码的功能就是将test.txt文件中的内容输出到控制台上。
再来一段重定向标准输出流的
public static void main(String []args) { try { int []A= {1,2,3,4}; PrintStream out = System.out; PrintStream ps1=new PrintStream("\\log.txt"); PrintStream ps2 = new PrintStream("\\text.txt"); System.out.println(A[0]); System.setOut(ps1); System.out.println(A[1]); System.setOut(ps2); System.out.println(A[2]); System.setOut(out); System.out.println(A[3]); } catch (FileNotFoundException e) { e.printStackTrace(); } }
上面代码的流程介绍一下,先是打印A[0],没有任何操作下,System.out会默认打印到控制台上。然后冲重定向至文件log,txt中,接下来的System.out会将A[1]写入(打印到)文件log.txt中。又重定向至text.txt,同样的A[2]会写入该文件中。最后再重定向回标准输出流,会在控制台打印A[3]。
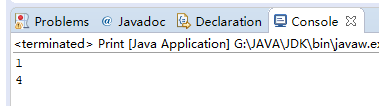 控制台。
控制台。
 log.txt
log.txt
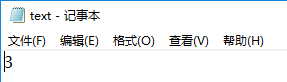 text.txt
text.txt

 浙公网安备 33010602011771号
浙公网安备 33010602011771号