Redis数据结构概述
Redis数据结构
redis被广泛应用于缓存的原因就是它“快”:能在微秒的时间查询到数据。这么快有两方面原因,一是redis是内存数据库,所有的操作都基于内存。另一方面就要归功于redis的数据结构
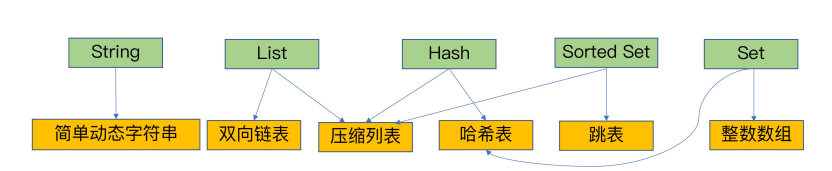
由上图可知,string的底层数据实现只有一种,而其他的数据结构至少为两种底层的实现结构
键和值的数据结构
redis键和值通过哈希表进行保存。一个哈希表其实就是一个数组,数组的每一个元素被称为一个哈希桶。每个哈希桶保存了键值对数据,这个数据不是本身,而是指向他们的指针。这样做的好处就是即使Value是一个集合,也可以通过指针进行访问

这个哈希表保存了全部的键值对,所以也被称为全局哈希表,好处是可以通过计算哈希值来获取桶的位置,这个操作的时间复杂度是O(1),也就是说在理论上10w条数据和100w条数据我们都只需要计算一次哈希值找到对应的键。但是随着redis数据的插入,查找数据的速度会下降,原因就是哈希表的冲突问题和rehash带来的操作阻塞
哈希冲突是指两个key拥有相同的hash值,redis解决hash冲突的方式是链式哈希:同一个桶的元素用链表保存(类似于Java的HashMap)
这样也会有一个新的问题,就是这个链表过长会造成redis查找性能的下降,因为遍历链表的时间复杂度是O(n),redis解决这个问题的方法就是rehash
所谓的rehash就是扩大哈希桶,让逐渐增多的entry元素能够更加分散的保存。redis为了方便rehash这个操作。其实有两个全局哈希表,我们将其称为哈希表1和哈希表2。当你插入数据时,是插入到哈希表1里面,哈希表2无动作。随着数据的不断增多,redis开始进行rehash。这个操作主要分为三步:
1、将哈希表2的大小扩充为哈希表1的两倍
2、将哈希表1的数据重新映射并拷贝到哈希表2中
3、释放哈希表1的空间
这个过程也存在着一些问题,当数据量很大的时候进行数据的迁徙可能会造成redis的线程阻塞。为了解决这个问题,redis采用了渐进式rehash
简单来讲,就是在第二步拷贝数据时,redis仍然正常处理请求。每处理⼀个请求时,从哈希表1中的第⼀个索引位置开始,顺带着将这个索引位置上的所有entries拷⻉到哈希表2中;等处理下⼀个请求时,再顺带拷⻉哈希表1中的下⼀个索引位置的entries。效果如图所示

双向链表
双向链表就是每个节点有两个指针,一个指向上一个节点,一个指向下一个节点
压缩列表
压缩列表是一种为节约内存而开发的顺序型数据结构。
压缩列表被用作列表键和哈希键的底层实现之一。
压缩列表可以包含多个节点,每个节点可以保存一个字节数组或者整数值。
添加新节点到压缩列表, 或者从压缩列表中删除节点, 可能会引发连锁更新操作, 但这种操作出现的几率并不高。
跳跃表
跳表的本质就是可以进行二分查找的有序链表,跳表在原本的有序链表上添加了多级索引来方便搜索,也同时提高了插入和删除操作的效率
示例如图所示


 浙公网安备 33010602011771号
浙公网安备 33010602011771号