解决:kubernetes 集群DNS配置及容器内CoreDNS解析外部域名配置问题
近期devops过程中发现在kubernetes 中启动Jenkins master 执行job 启动slave时 出现概率事件解析不到gitlab的域名。第一时间反射到的是dns问题,具体是DNS哪里的配置问题 慢慢刨根。

排查过程:
1.首先在kubernetes 集群中run起来一个容器busybox 尝试解析gitlab的域名:
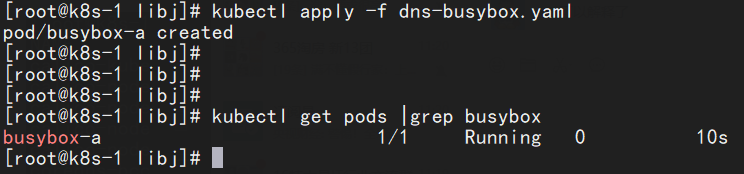
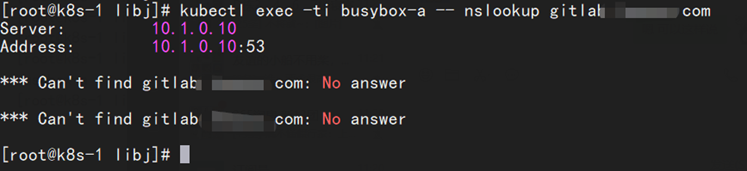
[root@k8s-1 libj]# kubectl delete -f dns-busybox.yaml pod "busybox-a" deleted [root@k8s-1 libj]# [root@k8s-1 libj]# [root@k8s-1 libj]# [root@k8s-1 libj]# kubectl apply -f dns-busybox.yaml pod/busybox-a created [root@k8s-1 libj]# [root@k8s-1 libj]# [root@k8s-1 libj]# [root@k8s-1 libj]# kubectl get pods |grep busybox busybox-a 1/1 Running 0 10s [root@k8s-1 libj]# [root@k8s-1 libj]# kubectl exec -ti busybox-a -- nslookup gitlab.手动马赛克.com Server: 10.1.0.10 Address: 10.1.0.10:53 *** Can't find gitlab.手动马赛克.com: No answer *** Can't find gitlab.手动马赛克.com: No answer [root@k8s-1 libj]#
发现无法解析。
此官方文档繁琐的说明了两件事,1.可以自己自定义配置coredns 的configmap文件 添加需要转发and需要解析的主机地址;2.可以配置pod模版文件中单独设置一个容器的dns设置。
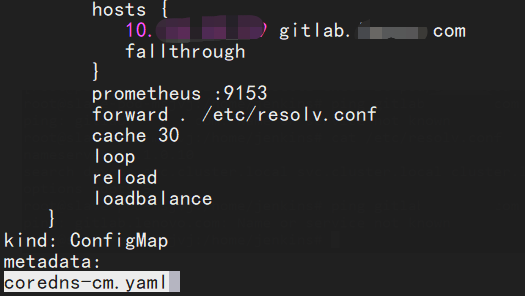
几经波折,我们这里尝试了配置cm文件的hosts
[root@k8s-1 libj]# cat coredns-cm.yaml
apiVersion: v1
data:
Corefile: |
.:53 {
errors
health
kubernetes cluster.local in-addr.arpa ip6.arpa {
pods insecure
upstream
fallthrough in-addr.arpa ip6.arpa
ttl 30
}
hosts {
10.120.20.x gitlab.yourname.com
fallthrough
}
prometheus :9153
forward . /etc/resolv.conf
cache 30
loop
reload
loadbalance
}
kind: ConfigMap
metadata:
creationTimestamp: "2019-09-18T06:24:26Z"
name: coredns
namespace: kube-system
resourceVersion: "44405526"
selfLink: /api/v1/namespaces/kube-system/configmaps/coredns
uid: f81c618d-e6b0-4a4b-801d-04c8b840b6f7
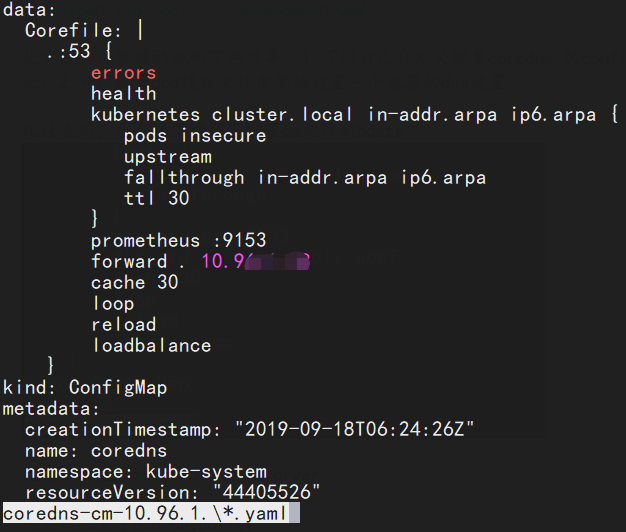
还尝试配置了forward . Nameserver
[root@k8s-1 libj]# cat coredns-cm-10.96.1.\*.yaml
apiVersion: v1
data:
Corefile: |
.:53 {
errors
health
kubernetes cluster.local in-addr.arpa ip6.arpa {
pods insecure
upstream
fallthrough in-addr.arpa ip6.arpa
ttl 30
}
prometheus :9153
forward . 10.96.1.18
cache 30
loop
reload
loadbalance
}
kind: ConfigMap
metadata:
creationTimestamp: "2019-09-18T06:24:26Z"
name: coredns
namespace: kube-system
resourceVersion: "44405526"
selfLink: /api/v1/namespaces/kube-system/configmaps/coredns
uid: f81c618d-e6b0-4a4b-801d-04c8b840b6f7
[root@k8s-1 libj]#
还尝试配置了pod dnspolicy
[root@k8s-1 libj]# cat dns-busybox-default.yaml
apiVersion: v1
kind: Pod
metadata:
name: busybox
namespace: default
spec:
containers:
- name: busybox
image: busybox
command:
- sleep
- "3600"
imagePullPolicy: IfNotPresent
restartPolicy: Always
dnsPolicy: Default
[root@k8s-1 libj]#
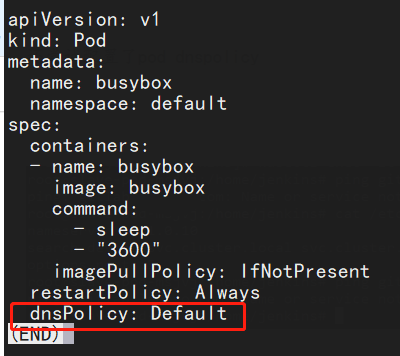
以上的各种尝试配置都还有有几率性问题,Dnspolicy 设置之后貌似立竿见影的好使了。但是我们觉得单独设置Jenkins slave 不太现实。这里还有一个小配置插曲 是在Jenkins 的pod模版设置的时候有使用host network 选项打勾。也是可以解决这个解析的问题。
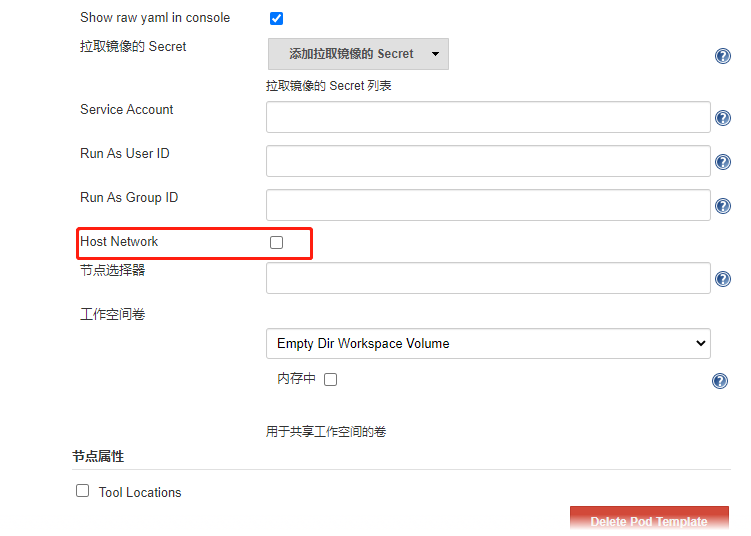
Jenkins pod template 这个地方打勾。
3.最后经过一顿操作 得出大致三种方法可以解决容器内解析外部DNS问题,,1配置kube-dns的configmap文件 添加host记录 已到达解析目的,2.配置k8s服务器集群的resolv.conf 增加dns服务器,然后刷新k8s集群kube-dns 重建 ,已到达解析目录,3,就是配置Jenkins pod模版使用hostnetwork,已达到解析目的 。
这里我们选择了第二种方案,重整kubernetes集群内所有node节点nameserver配置然后重建kubernetes coredns。
检查集群内部resolv.confg文件就不贴图了。一定要保证集群内所有dns配置都一致。
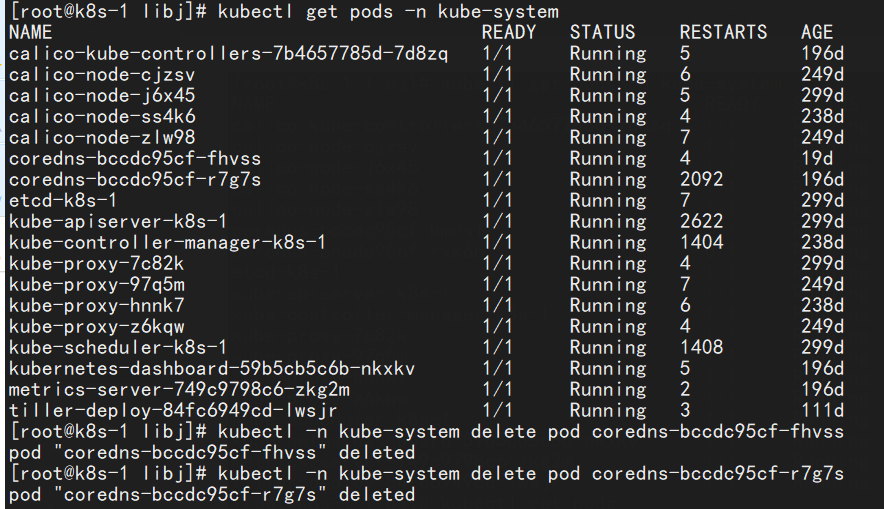
下图是获取kubernetes 集群内 coredns容器,然后delete coredns pods。
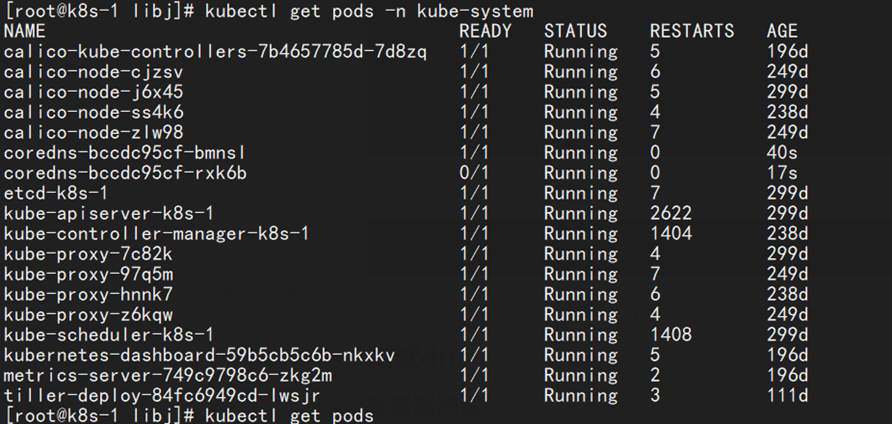
等待kube-coredns重新拉起。
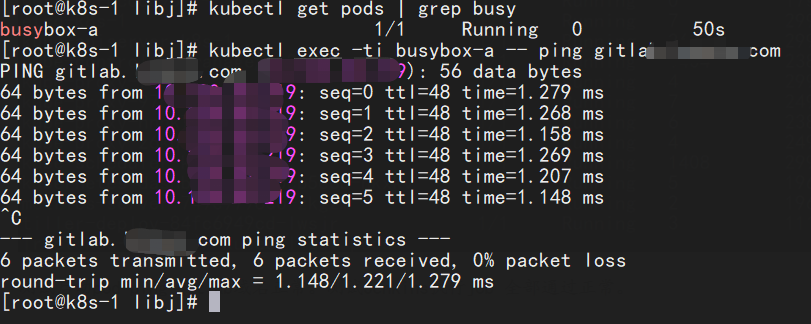
测试启动pod ping gitlab域名正常。测试Jenkins执行job 全部通过正常。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号