
Es中fuzzy和match_phrase的区别
match_phrase:短语模糊查询
match用于分词模糊查询,比如说我们查询”一共多少个词语”,但我们需要查询“共多“的时候,如果没有指定分词器,使用默认分词的话,会将共多分成”共”,”多”进行模糊查询,但不符合我们的业务需求,那么我们就需要使用ik分词器配置词典”共多”
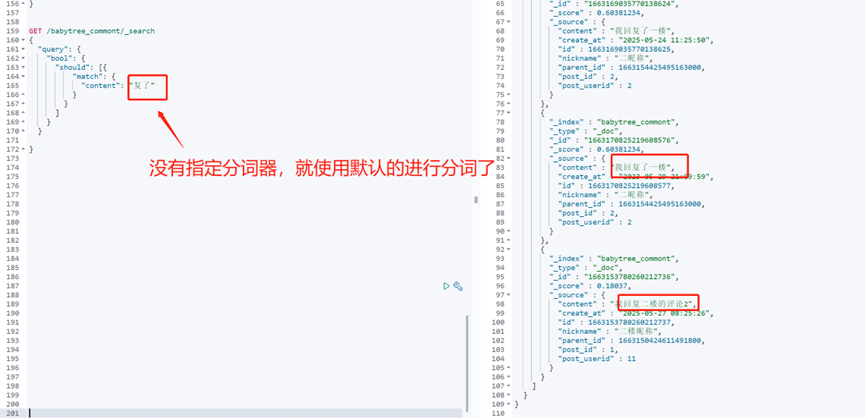
但是,这样的话我们对于这种业务场景可能会配置大量的词典,所以我们可以采用match_phrase进行短语模糊查询
match_phrase用于短语模糊查询,还是查询”一个多少个词语”,即它会将给定的短语”共多”当成一个完整的查询条件,然后查出含有该查询条件的内容
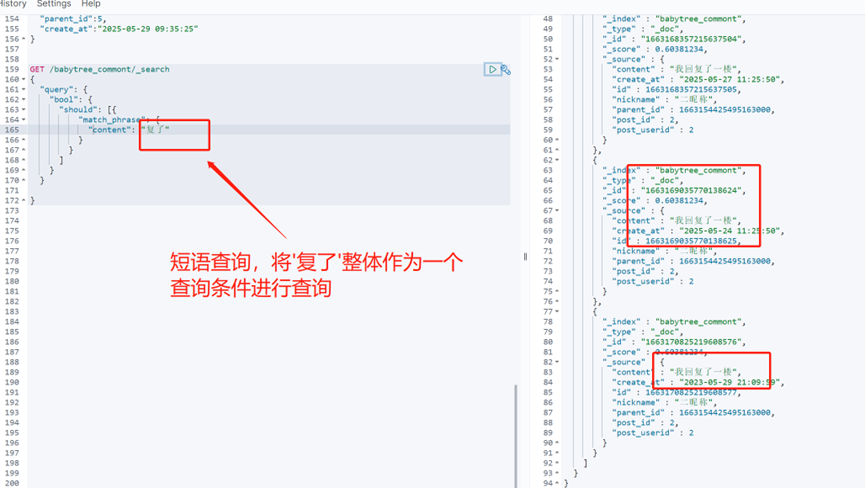
还可以通过slop参数告诉match_phrase查询词条能够相隔多远时仍然将文档视为匹配,默认是0。为0时 必须相邻才能被检索出来
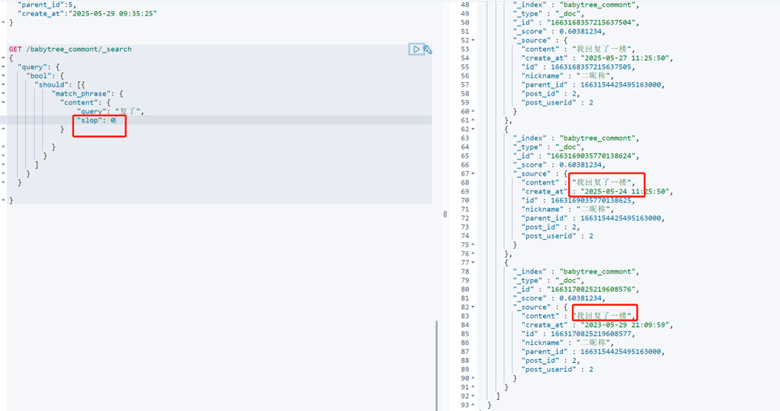
注意:我们实际上可能会用不同的分词器,但是建议使用match_phrase时使用标准的一个个分词,这样是方便进行邻近搜索的控制的,如果使用ik等分词,执行match_phrase时分词是不可控的,所以结果也是不可控。match使用ik,match_phrase用standard结合一起使用也是可以的
搜索的词必须有且仅有["","方","宾","馆"]这几个词(对于中文是字)的一个或者多个,如果有其他的词(对于中文是字)是不会匹配到的,slop不是完全等同于莱文斯坦距离,可以理解成字符的偏移
es fuzzy的使用场景:
在我们平时开发场景中,有可能会出现文本拼写错误的情况,那么查询的时候可以使用fuzzy搜索技术---->可以自动将拼写错误的搜索文本,进行纠正,纠正以后去匹配索引中的数据
如果我们索引映射字段为:ik_smart,那么使用match_phrase查询的时候,是按照ik_smart分词后的结果进行查询的
PUT /xiaoshuo
{
"mappings": {
"properties": {
"title":{
"type":"text",
"analyzer": "ik_smart",
"search_analyzer": "ik_smart"
}
}
}
}
如果我们索引映射字段为:ik_max_word,那么使用match_phrase查询的时候,是按照ik_max_word分词后的结果进行查询的
PUT /xiaoshuo
{
"mappings": {
"properties": {
"title":{
"type":"text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word"
}
}
}
}
match查询属于全文查询,在查询时,ES会先分析查询字符串,然后根据分词构建查询。
match_phrase在查询时也会先分析查询字符串,然后对这些词项进行搜索,不同的是match_phrase查询只会保留包含全部查询字符串的文档
在实际应用中,如果需要搜索文本中包含特定顺序的一组词语或短语,则可以考虑使用match_phrase查询。
在实际应用中,如果需要对文本字段进行关键字和模糊搜索,可以考虑使用match查询。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号