
分布式并行计算MapReduce
1.用自己的话阐明Hadoop平台上HDFS和MapReduce的功能、工作原理和工作过程。
HDFS的概念: Hadoop分布式文件系统(HDFS)被设计成适合运行在通用硬件(commodity hardware)上的分布式文件系统、HDFS是一个高度容错性的系统,适合部署在廉价的机器上。HDFS能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。
HDFS的系统结构:

Master和Slave结构。
分为三个角色:NameNode、SecondaryNameNode、DataNode。
Master节点:1. 管理数据块映射;2. 处理客户端的读写请求;3. 配置副本策略;4. 管理HDFS的名称空间。5. namenode 内存中存储的是 = fsimage + edits。
Slave节点:1. 存储client发来的数据块block;2. 执行数据块的读写操作。

HDFS的文件读取原理,详细解析如下:
1、首先调用FileSystem对象的open方法,其实获取的是一个DistributedFileSystem的实例。
2、DistributedFileSystem通过RPC(远程过程调用)获得文件的第一批block的locations,同一block按照重复数会返回多个locations,这些locations按照Hadoop拓扑结构排序,距离客户端近的排在前面。
3、前两步会返回一个FSDataInputStream对象,该对象会被封装成 DFSInputStream对象,DFSInputStream可以方便的管理datanode和namenode数据流。客户端调用read方 法,DFSInputStream就会找出离客户端最近的datanode并连接datanode。
4、数据从datanode源源不断的流向客户端。
5、如果第一个block块的数据读完了,就会关闭指向第一个block块的datanode连接,接着读取下一个block块。这些操作对客户端来说是透明的,从客户端的角度来看只是读一个持续不断的流。
6、如果第一批block都读完了,DFSInputStream就会去namenode拿下一批blocks的location,然后继续读,如果所有的block块都读完,这时就会关闭掉所有的流。
MapReduce的概念:MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算,是面向大数据并行处理的计算模型、框架和平台,用Map和Reduce两个函数编程实现基本的并行计算任务,提供了抽象的操作和并行编程接口,以简单方便地完成大规模数据的编程和计算处理.
MapReduce的工作原理:
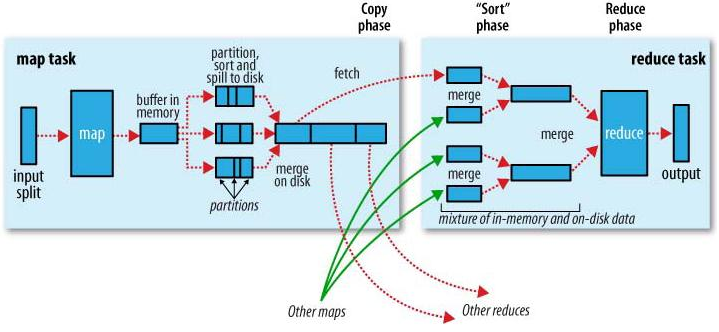
reduce task
2.HDFS上运行MapReduce
1.查看是否已经安装python:

2.在/home/hadoop/路径下建立wc文件夹,在文件夹内新建mapper.py、reducer.py、run.sh和文本文件HarryPotter.txt:

3.查看mapper.py reducer.py run.sh的内容:

4)修改mapper.py和reducer.py文件的权限:

4.在本地运行测试map函数和reduce函数

5.启动Hadoop:HDFS, JobTracker, TaskTracker

6.streaming的jar文件的路径写入环境变量,让环境变量生效


7.source run.sh来执行mapreduce
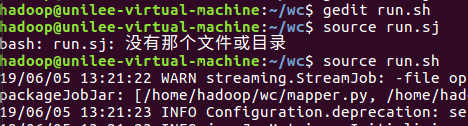
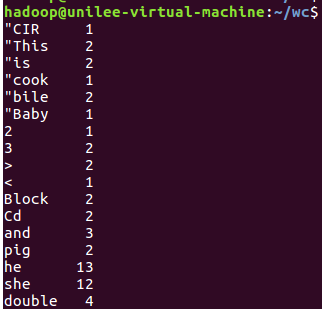
8.查看运行结果:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号