mysql索引
一、 索引的介绍
索引是一种特殊的文件(InnoDB数据表上的索引是表空间的一个组成部分),它们包含着对数据表里所有记录的引用指针。MySQL把同一个数据表里的索引总数限制为16个(不建议在一张表建立过多索引,索引数量过多会影响insert,update,delete效率)。
只有当数据库里已经有了足够多的测试数据时,数据库的性能测试结果才有实际参考价值。如果在测试数据库里只有几百条数据记录,在执行完第一条查询命令之后就被全部加载到内存里,这将使后续的查询命令都执行得非常快–不管有没有使用索引。只有当数据库里的数据总量超过了 MySQL服务器上的内存总量时,数据库的性能测试结果才有意义。
二、 索引的限制
1.如果WHERE子句的查询条件里有不等号(WHERE coloum != …),MySQL将无法使用索引。
2.如果WHERE子句的查询条件里使用了函数(WHERE DAY(column) = …),MySQL也将无法使用索引。
3.如果WHERE子句的查询条件里使用比较操作符LIKE和REGEXP,MySQL只有在搜索模板的第一个字符不是通配符的情况下才能使用索引。比如说,如果查询条件是LIKE ‘abc%’,MySQL将使用索引;如果查询条件是LIKE ‘%abc’,MySQL将不使用索引。
四、索引的建立
(1)直接创建索引
CREATE INDEX index_name ON table(column(length))
CREATE UNIQUE INDEX zipindex on ec_address(FIRST_LETTER(3))
(2)修改表结构的方式添加索引
普通索引
ALTER TABLE table_name ADD INDEX index_name (column(length))
唯一索引
ALTER TABLE ec_address add UNIQUE INDEX suoyin (FIRST_LETTER(3))
主键
alter table ec_address add primary key(ID)
(3)创建表的时候同时创建索引
CREATE TABLE `table` (
`id` varchar(8) ,
`title` varchar(8) ,
`content` varchar(8) ,
`time` int(10) ,
PRIMARY KEY (`id`),
UNIQUE KEY `suoyin` (`time`),
INDEX index_name (title(3))
)
ENGINE=InnoDB
DEFAULT CHARACTER SET=utf8mb4 COLLATE=utf8mb4_general_ci
ROW_FORMAT=DYNAMIC
(4)删除索引
DROP INDEX index_name ON table
alter TABLE ec_address drop INDEX zipindex
alter table ec_address drop primary key
1、普通索引
在最经常出现在查询条件(WHERE column = …)或排序条件(ORDER BY column)中的数据列创建索引。
2、唯一索引
与普通索引类似,不同的就是:索引列的值必须唯一,但允许有空值。在为这个数据列创建索引的时候就应该用关键字UNIQUE把它定义为一个唯一索引。
3、主键
主键与唯一索引的唯一是:前者在定义时使用的关键字是 PRIMARY而不是UNIQUE。一个表中可以有多个唯一性索引,但只能有一个主键,主键列不允许空值,而唯一性索引列允许空值。
4、复合索引(组合索引)
索引可以覆盖多个数据列,如像INDEX(columnA, columnB)索引。这种索引的特点是MySQL可以有选择地使用一个这样的索引。如果查询操作只需要用到columnA数据列上的一个索引,就可以使用复合索引INDEX(columnA, columnB)。不过,这种用法仅适用于在复合索引中排列在前的数据列组合。比如说,INDEX(columnA, columnB, columnC)可以当做columnA或(columnA, columnB)的索引来使用,但不能当做columnB、columnC或(columnB, columnC)的索引来使用。
5、全文索引(关键字FULLTEXT )
主要用来查找文本中的关键字,而不是直接与索引中的值相比较。fulltext索引跟其它索引大不相同,它更像是一个搜索引擎,而不是简单的where语句的参数匹配。fulltext索引配合match against操作使用,而不是一般的where语句加like。它可以在create table,alter table ,create index使用,不过目前只有char、varchar,text 列上可以创建全文索引。值得一提的是,在数据量较大时候,现将数据放入一个没有全局索引的表中,然后再用CREATE index创建fulltext索引,要比先为一张表建立fulltext然后再将数据写入的速度快很多
五、慢查询日志查看
show variables like '%quer%';
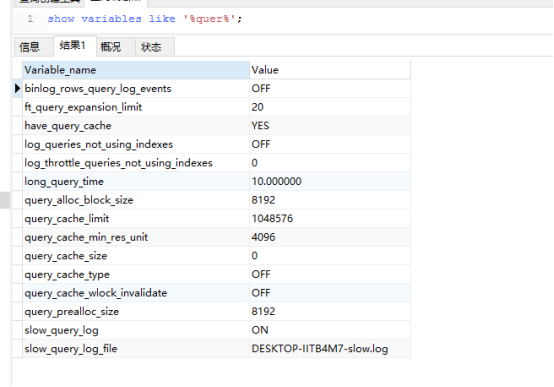
1、binlog_rows_query_log_events
开启该参数,将把sql语句打印到binlog日志里面.默认是0(off)
2、ft_query_expansion_limit
full text(全文索引) 默认为20,范围0 .. 1000;进行全文搜索的最大匹配数
3、have_query_cache:该MySQL 是否支持Query Cache;
show variables like '%query_cache%'; 查看是否开启了 query cache
4、log_queries_not_using_indexes 如果值设置为ON,则会记录所有没有利用索引的查询(注意:如果只是将log_queries_not_using_indexes设置为ON,而将slow_query_log设置为OFF,此时该设置也不会生效,即该设置生效的前提是slow_query_log的值设置为ON),一般在性能调优的时候会暂时开启。
5、log_throttle_queries_not_using_indexes
设定每分钟记录到日志的未使用索引的语句数目,超过这个数目后只记录语句数量和花费的总时间 ,该值默认为0,表示没有限制
6、long_query_time 指定了慢查询的阈值,即如果执行语句的时间超过该阈值则为慢查询语句,默认值为10秒。
7、query_alloc_block_size
为查询分析和执行过程中创建的对象分配的内存块大小
8、query_cache_limit
指定单个查询能够使用的缓冲区大小,缺省为1M。
9、query_cache_min_res_unit
默认4096;范围512.. 18446744073709547520的查询缓存分配的块的最小大小(以字节为单位)
10、query_cache_size查询缓存占用的内存大小,具体大小是多少取决于查询的实际情况,但最好设置为1024的倍数,参考值32M。
11、query_cache_type参数用于控制缓存的类型
如果设置为0,那么可以说,你的缓存根本就没有用,相当于禁用了。
如果设置为1,将会缓存所有的结果,除非你的select语句使用SQL_NO_CACHE禁用了查询缓存。
如果设置为2,则只缓存在select语句中通过SQL_CACHE指定需要缓存的查询
12、query_cache_wlock_invalidate
默认为false,如果某个数据表被其他的连接锁住,是否仍然从查询缓存中返回结果。
13、query_prealloc_size
默认值8192,范围为8192.. 18446744073709547520,用于查询分析和执行的固定缓冲区的大小
14、slow_query_log的值为ON为开启慢查询日志,OFF则为关闭慢查询日志。
15、slow_query_log_file 的值是记录的慢查询日志到文件中(注意:默认名为主机名.log,慢查询日志是否写入指定文件中,需要指定慢查询的输出日志格式为文件,相关命令为:
show variables like ‘%log_output%’;去查看输出的格式)。
如何开启慢查询日志
在my.ini配置文件的[mysqld]选项下增加:
slow-query-log=false
slow_query_log_file="slow_query_log.txt"
如何开启mysql的binlog日志呢?
[mysqld]下添加一个binlog配置就可以了
log_bin=mysql-bin
六、mysql查询语句分析
explain select * from ec_address WHERE name='北京';
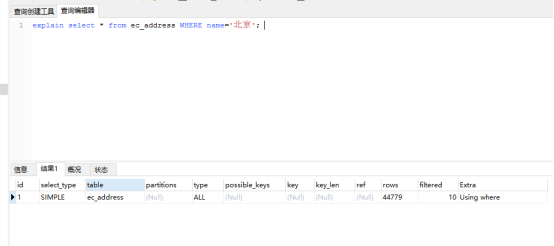
1、Id select查询的序列号
2、select_type
select查询的类型,主要是区别普通查询和联合查询、子查询之类的复杂查询。
SIMPLE: 简单表,不使用连接或子查询的
PRIMARY: 主查询,即外层的查询
UNION: UNION中的第二个或者后面的查询语句
SUBQUERY: 子查询中的第一个SELECT
union result:包含union的结果集,在union和union all语句中,因为它不需要参与查询,所以id字段为null
3、table 输出的行所引用的表。
4、type
表示表的连接类型,性能由好到差的连接类型为下面顺序:
system > const > eq_ref > ref> ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
一般来说,得保证查询至少达到range级别,最好能达到ref。
1.system:表只有一行记录。且只能用于myisam和memory表
2.const:表中最多只有一行匹配的记录,它在查询一开始的时候就会被读取出来。const表查询起来非常快,因为只要读取一次!
3.eq_ref:这个索引是一个primary key 或 unique 类型 索引是唯一索引,对于每个索引键值,表中只有一条记录匹配,就是多表连接中使用primary key或者 unique key作为关联条件
4.ref: 普通索引
5.ref_or_null: 这种连接类型类似 ref,不同的是mysql会在检索的时候额外的搜索包含null 值的记录。
6.range: 这种类型时 ref 字段值是 null。使用>,<,is null,between ,in ,like等运算符的查询中。例如
select * from tbl_name where key_column between 10 and 20; select * from tbl_namewhere key_column in (10,20,30); select * from tbl_name wherekey_part1= 10 and key_part2 in (10,20,30);
7.all: MySQL将遍历全表以找到匹配的行
5、possible_keys
possible_keys字段是指 mysql在搜索表记录时可能使用哪个索引。注意,这个字段完全独立于explain 显示的表顺序。这就意味着 possible_keys里面所包含的索引可能在实际的使用中没用到。如果这个字段的值是null,就表示没有索引被用到。这种情况下,就可以检查 where子句中哪些字段那些字段适合增加索引以提高查询的性能。就这样,创建一下索引,然后再用explain 检查一下。想看表都有什么索引,可以通过 show index from tbl_name来看。
6、key
key字段显示了mysql实际上要用的索引。如果没有索引被选择,键是NULL。
7、key_len
key_len 字段显示了mysql使用索引的长度。当 key 字段的值为 null时,索引的长度就是 null。key_len的值可以告诉你在联合索引中mysql会真正使用了哪些索引。
8、ref
显示哪个字段或常数与key一起被使用。
如果是使用的常数等值查询,这里会显示const,如果是连接查询,被驱动表的执行计划这里会显示驱动表的关联字段,如果是条件使用了表达式或者函数,或者条件列发生了内部隐式转换,这里显示为func
9、rows
这个数表示mysql要遍历多少数据才能找到
10、Extra 查询中mysql的附加信息

 浙公网安备 33010602011771号
浙公网安备 33010602011771号