
一次多进程的小尝试
年前的一次任务,被插队帮别的组做,需要一批兑换码存起来,配合新年活动在某应用中,让用户抽奖领取,数量在1000w。俺首先当然是怀疑一次活动能有这么多用户?但人家为了噱头。
由于只是配合别人做一次活动,无需事后统计数据啥的,因此俺把它放到缓存里边(一条兑换码就几个字符,1000w个也占不了多少空间),有点意思的就是如何导入这1000w兑换码了。
如果是c/c++这种天生跑的快的,不做什么连接数据库等复杂操作,1000w次循环,是可以1秒钟完成的,但是服务器上跑脚本,得考虑到当前服务器运行着其他任务,在脚本程序运行过程中,还可能连接/断开、读写数据库,读写缓存等,本身也要花时间,需要分配大量的CPU时间才能搞定。肯定得命令行窗口运行了,时间也不能设限制,但是如果只是单独写一个for循环跑1000w次,这样也得跑个几天才行,因此一个简单的多进程脚本就可以大大加快速度了。
既然大数据量非常耗时,可能得几个小时运行完成,这里应该以后台作业的形式执行脚本,具体是在执行时最后加上&(如 /usr/bin/php test1.php &),而为了防止运行过程中丢失shell会话,最好在执行前加上nohup,这样可防止进程在执行时被系统挂起而停止,然后重定向一下输出,命令执行时类似于这样
/usr/bin/php test1.php > test1.log 2>1& &
整个思路也比较简单,将兑换码整理成一个一行,放在一个原始文件中,比如名字叫original_code_1.txt
程序一行行读取,设定一个行数,比如10w,每读取这么多行就换一个新文件写入,即将这个大文件分成许多小文件,用一个数组保存这些小文件的路径名(如../../data/proc/proc_3d423v348k_1.txt)。
文件劈分完成后,开启多个进程处理,这个进程是实际执行导入操作的脚本,比如可命名为import_code_into_cache.php,每次导入一个兑换码成功,就把它写到一个中间文件中,比如../../data/mid/mid_cwe8422ici_1.txt
所有的文件跑完后,将中间数据(mid目录下的额)汇总到end目录下(../../data/end/end_1.txt),这样如果导入中间某种原因有丢失的,可以将最终文件数据与原来的总数据对比、整理后,再次导入,可以叫original_code_2.txt。
proc目录:存放将大文件切分后的小文件,文件名类似proc_uniqid()_导入编号.txt
mid目录:存放将小文件导入缓存,若成功则写入这个文件,文件名类似mid_uniqid()_导入编号.txt
end目录:存放最后导入汇总数据,文件名类似end_导入编号.txt
针对上面的简单版本,在自己的机子上重写了下,首先是配置文件config.php,规定程序执行过程中的必要参数
<?php /** config.php 设置各项脚本执行参数 */ $num = isset($ARGV[1]) ? $ARGV[1] : 1; // 第几次导入 define('DS', DIRECTORY_SEPARATOR); define('ROOT_PATH', realpath(dirname(__FILE__))); // 当前文件所在根目录 $original_dir = ROOT_PATH.DS.'original'.DS; // 存放原始兑换码数据目录 $proc_dir = ROOT_PATH.DS.'data'.DS.'proc'.DS; // 待处理兑换码文件目录,存放切分后的文件 $mid_dir = ROOT_PATH.DS.'data'.DS.'mid'.DS; // 生成的中间数据目录 $end_dir = ROOT_PATH.DS.'data'.DS.'end'.DS; // 最终汇总数据目录 $original_file = $original_dir.'original_code_'.$num.'.txt'; // 原始兑换码大文件 if(!file_exists($original_file)) { echo "file {$original_file} not exist!\n"; } $import_script = 'import_code_into_cache.php'; // 执行导入脚本的文件名 $exec_import_file = ROOT_PATH.DS.$import_script; // 执行导入的脚本的路径名 if(!file_exists($exec_import_file)) { echo "the script that execute importion [{$exec_import_file}] not exist!\n"; } $max_proc_num = 5; // 最大并发进程数,测试 $max_file_line = 5; // 切分后单文件最大数据行数,这里是测试 $is_del_mid = true; // 汇总时是否删除中间数据
$num是本次导入的编号,即第几次,通过脚本参数传,然后是其他存放原来大文件、切分后的数据目录、中间数据目录以及最终数据汇总结果等,并且规定了最大并发进程数,这里写的是5,每个切分文件的行数,这里因为是本机测试我写的是5。以及最终将中间数据删除。
通过以上思路,在程序开始之前,可以先将切分数据目录,或者称之为当前处理数据目录的proc_dir、中间数据目录mid_dir以及汇总目录end_dir进行一次初始化,比如清空原有文件,不存在就新建这个目录等。第二个函数是对大文件的切分,在一行行读取原始兑换码数据,写到proc_dir目录下,具体代码如下:
<?php /** tool.php 需用到的公共函数 */ function init_dir($dir, $del = false) { if(!file_exists($dir)) { mkdir($dir, 0777, true); } else { chmod($dir, 0777); if($del) { $cmd = 'rm -rf '.$dir.'*'; exec($cmd); } } } // 初始化各个文件目录 function init_workspace() { global $proc_dir, $mid_dir, $end_dir; init_dir($proc_dir, true); init_dir($mid_dir, true); init_dir($end_dir); } // 劈分原始数据文件 function get_split_file_list() { global $original_file, $proc_dir, $max_file_line, $num; $file_list = array(); if(!file_exists($original_file)) { return $file_list; } $i = 0; $handle = fopen($original_file, 'r'); if(!$handle) return $file_list; $proc_handle = null; while(!feof($handle)) // 循环读取大文件 { $line_code = trim(fgets($handle)); if(empty($line_code)) continue; // 过滤空白行及fread读取的文件空的末尾 if($i % $max_file_line == 0) // 写入一个新文件,每个文件行数最大为$max_file_line { if(isset($proc_handle)) fclose($proc_handle); $filename = $proc_dir.'proc_'.uniqid().'_'.$num.'.txt'; // 切分文件的命名:proc_随机串_导入编号.txt $file_list[] = $filename; if($proc_handle = fopen($filename, 'w')) { chmod($filename, 0777); fwrite($proc_handle, $line_code."\n"); // 写入新的待处理文件,每个文件行数是$max_file_line } } else // 写入一个已存在的文件 { fwrite($proc_handle, $line_code."\n"); } ++ $i; } fclose($handle); fclose($proc_handle); return $file_list; }
get_split_file_list()函数功能为把大文件切分成小文件,将各个文件路径放入一个数组并返回。
接下来是启动进程,开始导入。我图简单写了一个类,这个类大概有这样几个方法:(1)get_uniq_mid_file_name,获取一个中间数据的文件路径名;(2)
merge_file,用于将中间数据汇总到最终数据中;(3)get_curr_proc_num,获取当前正在执行导入的进程数;(4)process_data,根据进程数数否达到上限而开启导入脚本进程,进行导入操作。代码如下
<?php /** model.php 根据进程数,调用导入脚本,开始导入 */ class proj_manger { public $num; // 第几次导入 public $max_proc_num; // 最大并发进程数 public $file_list; // 待处理劈分的文件(路径) public $mid_dir; // 中间数据目录 public $end_dir; // 最终汇总数据目录 public $comm_mid_file; // 中间数据文件的统称 public $import_script; // 执行导入的脚本名 public $exec_import_file; // 执行导入的脚本全路径 public $is_del_mid_file; // 是否删除中间数据 public function __construct($num, $max_proc_num, &$file_list, $mid_dir, $end_dir, $import_script, $exec_import_file, $is_del_mid_file) { $this->num = $num; $this->max_proc_num = $max_proc_num; $this->file_list = $file_list; $this->mid_dir = $mid_dir; $this->end_dir = $end_dir; $this->comm_mid_file = $this->mid_dir.'mid_*_'.$this->num.'.txt'; $this->import_script = $import_script; $this->exec_import_file = $exec_import_file; $this->is_del_mid_file = $is_del_mid_file; } // 获取一个中间数据文件路径名 public function get_uniq_mid_file_name() { return $this->mid_dir.'mid_'.uniqid().'_'.$this->num.'.txt'; } // 将中间数据合并到最终数据目录中的文件 private function merge_file() { $end_file = $this->end_dir.'end_'.$this->num.'.txt'; // 最终合并文件路径名 $cmd = "cat {$this->comm_mid_file} > {$end_file}"; exec($cmd); // 执行合并 echo "merge file, execute cmd=>{$cmd}\n"; if($this->is_del_mid_file) { $cmd = "rm -rf {$this->comm_mid_file}"; exec($cmd); echo "delete middle file, execute cmd=>{$cmd}\n"; } } // 获取当前进程数 public function get_curr_proc_num() { $cmd = "ps -ef | grep {$this->import_script} | grep -v grep | wc -l"; $handle = popen($cmd, 'r'); $pnum = trim(fread($handle, 512)); pclose($handle); echo "get current total import process num, execute cmd=>{$cmd}\n"; return (int)$pnum; } // 开启进程,处理数据 public function process_data() { while(true) { $curr_proc_num = $this->get_curr_proc_num(); // 获取当前正在执行导入脚本的进程数 if(count($this->file_list) > 0) // 如果存在需处理的文件数据 { if($curr_proc_num < $this->max_proc_num) { $curr_proc_file = array_pop($this->file_list); $curr_mid_file = $this->get_uniq_mid_file_name(); $cmd = "nohup /usr/bin/php {$this->exec_import_file} {$curr_proc_file} {$curr_mid_file} > import_code.log 2>&1 &"; // 开启一个新进程 echo "start new proc: {$cmd}\n"; exec($cmd); } else // 进程数已达规定最大数目 { echo "please wait......\n"; } } else { // 处理完毕,合并文件并退出 $this->merge_file(); break; } sleep(1); } } }
这一行:$cmd = "nohup /usr/bin/php {$this->exec_import_file} {$curr_proc_file} {$curr_mid_file} > import_code.log 2>&1 &",大概就是
/usr/bin/php import_code_into_cache.php proc_232dh2842_1.txt mid_c2382nxr335_1.txt > import_code.log 2>&1 &
真正执行导入的是import_code_into_cache.php这个脚本,传入的两个参数是两个问价名,一个是分配给当前这个脚本(进程)的切分后的文件,一个他要写入的中间文件名,因此这里是一个进程处理一个切分后的小文件,如果规定切分文件行数是10W,就是一个进程处理10w条记录。如果当前进程数已达最大值,输出please wait.......,只要一个小文件处理完并完整退出,它的进程就会消失,总的进程数就会减1,while循环的条件是true,因此又会检查数组还有没有数据,有的话检查当前进程数是否小于最大值,小于的话,重新启动一个import_code_into_cache进程,接续处理数组中的下一个文件名,由于处理的是是从数组中array_pop出来的,每处理完一个,数组中少一个文件路径名,等所有的处理完file_list长度为0,进入while内最外层的else分支,开始汇总数据并break,break会退出这个死循环。
下面是实际导入程序import_code_into_cache.php
<?php /** import_code_into_cache.php 实际执行导入的脚本,导入数据并写入中间数据文件 */ // 处理传入的两个文件名参数 $curr_proc_file = isset($argv[1]) ? $argv[1] : ''; // 当前处理的文件 $curr_mid_file = isset($argv[2]) ? $argv[2] : ''; // 当前要写入的中间数据文件 $proc_handle = fopen($curr_proc_file, 'r'); $mid_handle = fopen($curr_mid_file, 'w'); if($proc_handle && $mid_handle) { chmod($curr_mid_file, 0777); while(!feof($proc_handle)) { $line = fgets($proc_handle); // TODO: 执行导入缓存等其他操作,获取操作结果 // 如果导入成功,写入中间数据文件,这里直接写入 fwrite($mid_handle, $line); } } sleep(10); // 延迟10秒,仅仅为了看进程测试
这里实际导入脚本没做任何有意义的操作,仅为了演示,while循环读取切分后的小文件,接下来可以执行你想要的操作,成功后再fwrite进中间数据文件。
也就是说,并没直接nohup /usr/bin/php import_code_into_cache.php *** 启动导入程序,而是在已经运行的脚本中启动的,而且对于一个正常完成的程序,它的进程会自动消失掉,这是检测进程数的关键。
最后,需要一个脚本把所有这一切连起来,这是整个导入程序的直接入口(import.php)
<?php /** import.php 导入程序的直接入口 */ if($argc <= 1) { exit("input cmd like: nohup /usr/bin/php import.php 1 > import.log 2>&1 &"); } date_default_timezone_set("Asia/Shanghai"); set_time_limit(0); // 无时间限制 ini_set('memory_limit', '512M'); // 内存限制为512M,仅为示例 echo "\nprocess start at ".date('Y-m-d H:i:s')."\n\n"; $start_time = microtime(true); // 记录开始时间 $GLOBALS['ARGV_INPUT'] = $argv; // 接收脚本参数 require_once('config.php'); // 配置文件 require_once('tool.php'); // 工具函数文件 require_once('model.php'); // 执行导入的类文件 init_workspace(); // 初始化待处理目录、中间数据目录、最终合并数据目录 $file_list = get_split_file_list(); // 对文件进行劈分,分给各个进程处理 $file_num = count($file_list); if($file_num > 0) { echo "total file num: {$file_num}\n"; $proc_data_obj = new proj_manger($num, $max_proc_num, $file_list, $mid_dir, $end_dir, $import_script, $exec_import_file, $is_del_mid); $proc_data_obj->process_data(); } else { echo "no splited files to be processed.\n"; } $end_time = microtime(true); $length = sprintf('%.3f', $end_time - $start_time); echo "process end, spend time: ".$length." seconds.\n"; // 记录本次执行时间 exit;
因此整个导入程序运行时是这样工作的,先进入当前脚本所在目录,确保当前目录下的original目录下有原始文件且名称对应,执行/usr/bin/php import.php 1 > import.log 2>&1 &,整个导入程序便开始。这里先调用了init_workspace简单初始化一下各个需要的目录,然后切分文件,然后new了一个proj_manager类并直接开始执行process_data方法,进行导入,从这个方法里边,执行实际导入数据的脚本,并保证同时最多有若干个进程在处理数据。
这里在给import.php传参数时只传了一个数字,表示第几次导入,如果想做的有扩展性点,比如某天为某个应用某次导入数据,就可以多传几个参数,而且文件的命名也会不同,甚至存放文件的目录完全换成一个日期为名称的目录下边,存放待处理数据、中间数据和汇总数据,具体看就要看需求了。
所有的代码文件 
original目录存放原始大数据量文件,data目录分别有三个目录proc、mid、end,作用如前所述,正在处理的小文件目录、中间数据文件目录、最终汇总数据文件目录。
original目录下有一个测试文件 ![]() ,36行数据
,36行数据
运行示例如下(在我的mbp下边)

运行后,ps -ef | grep import可以看到有5个执行导入的进程,进程正在跑,完事儿后作业完成给出了Done的完成状态,并显示作业号[1]以及后边的一串这个作业所执行的指令。
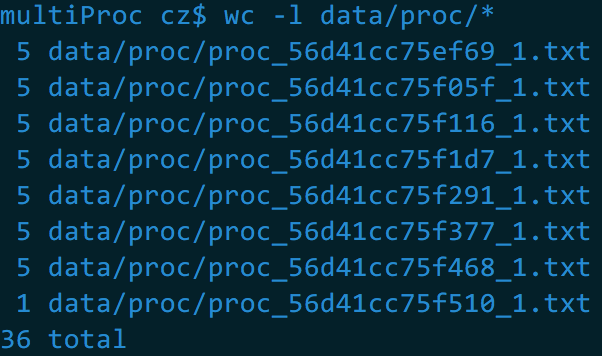
再看看proc和end目录下的文件
![]()
测试时是每个文件最多5行,总共36行数据,是能对上的。
当然俺在这儿没讲什么设计,基本是怎么简单怎么来,以后再需要处理这种大量的重复动作,拿这个为模板,改改又能用了-_-
