

正则学习(2)--- 简单匹配原理
写写对简单的匹配原理的理解,还是以php为主。
首先,正则引擎主要可分为两大类:DFA和NFA,反正引擎见多了就不奇怪了,简单理解就是不同的匹配方式,就好比在数组中查找数据时,有的是从头开始顺序,查找,有的从中间开始查找,所用的方式不同。相对来说NFA有更长的历史,使用NFA的工具或者语言更多,但也有两个引擎混合使用的。某书上举的例子非常贴切:NFA好比汽油机,DFA好比电动机,它们都能使汽车运行但有使用不同的机理。由于NFA和DFA都发展了很多年,所以又出台了一个被称为POSIX的标准,它规定作为一个正则引擎应该支持的元字符和特性,以及最终用户想要得到的准确结果。
NFA,以(正则)表达式为主导进行匹配,DFA则以待匹配的字符串为主导进行匹配。php使用的是传统型的NFA引擎,当然了Perl也是。无论哪种引擎,有两个通用的原则:1. 优先匹配最靠左端的结果;2. 标准量词(+、?、*、{m,n})均是匹配优先的。
现有表达式如下,要匹配字符串'tonight'
'/to(nite|knite|night)/'
NFA:以表达式为主导,从表达式的第一部分开始,同时检查当前文本是否匹配,如果是,继续到表达式的下一部分,直到表达式全部都能匹配,整个匹配成功。表达式的第一个字符时t,它将在字符串中按顺序从左到右反复查找,直到找到一个t字符,如果找不到就宣告失败,如果找到,表达式下一个字符时o,继续在待匹配字符串中查找,开头两个都能匹配上,进入到由括号分组的一个选择分支中,匹配nite、knite或者night,它依次尝试这种三种可能。第一个分支尝试到nig时失败,第二个分支尝试到表达式中第一个n时失败,第三个分支恰好完全匹配。以正则表达主导的引擎,就必须检查完表达式才能得出最终结论。
DFA:与NFA不同,DFA在扫描字符串时,会记录当前有效的所有匹配可能,从最开始的t,它会在当前的匹配可能中添加一种可能,如果存在的话,一直扫描到字符串中的n时,它会记录两种可能,nite和night两处的n(它是从待匹配的字符串角度看表达式),继续扫描到i还是nite和night两种可能,接着到g只剩下night一种可能了,当h和t匹配完成后,引擎发现扫描字符串已扫描结束,报告成功(貌似有点深度与广度的意味)。
所以,一般情况下文本主导的DFA引擎要更快一些,表达式主导的NFA必须检测完所有的模式,在没有抵达模式结束之前,不知道匹配的成功与否,即使前面某个表达式匹配成功了,说不定后面继续要对它检测一下,这可能会浪费很多时间。而DFA以字符串为主导,到一个地方顶多记录几种可能性,目标文本中的字符最多只会检测一次。
但是多选分支的顺序,对于不同目标字符串的影响也很大,恰好符合的分支在前面,当然能更快找到。
由于NFA以表达式为主,表达式书写的不同会产生很大的影响,也能让我们更加灵活的控制它,也具有更多的可变性。这其中,对于NFA来说(本来也是以php为主),有一个重要的特性:回溯---遇到需要从两个可能成功的匹配中选择时,先选择一种,并记住另外一种,以作稍后可能的需要,这种情形主要出现在标准量词和多选分支(|)。
盗图一张: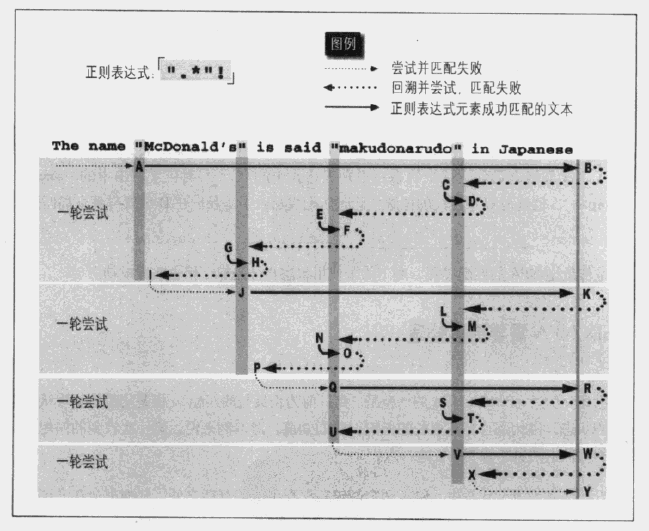
从表达式('/".*"!/')出发,首先找到双引号A处,接着由于是点号匹配任意字符(默认不包括换行符,这儿不用考虑),再加上元字符*表示可以匹配多个,由于标准量词的匹配优先机理,它一下子来到了字符串的结尾B处,因为在这之间*可以是0个、1个或多个,也就是说,这几种形式都是有可能匹配成功的,因此,引擎会记住这两种状态,即在一个位置可能匹配,也可以不匹配它,只要是*元字符经过的地方,从M到结尾都会记录。
等到结尾发现没有",于是回溯,需要说明,引擎总是回溯到最近记录的状态(类似栈),一个个往前回溯,直到遇到一个双引号的地方(C),然后匹配匹配到双引号后面(D),发现不是感叹号!,失败,再次回溯(状态记录不为空),到E处又找到了一个双引号,与刚才情况相同,继续匹配(F)发现没有感叹号,失败,继续回溯到G,同样由于后边(H)不是感叹号,仍需要回溯,到I,这时记录的状态已经没有了,也无法继续回溯了,第一轮匹配失败告终,但还没完,引擎的传动装置继续从A处双引号的下一个位置开始继续寻找第一个符合条件的双引号,到J,然后类似上一轮的过程继续上演。最终也没找到 "..."! 这样的字符串,过程却很曲折。
从上面的例子可以看出:一是 .* 这种形式的效率非常低,尤其在失败的时候(当然平常我们那几行代码几乎忽略不计),而且很容易出错,比如用 /".*/" 匹配一对双引号包围的字符串来匹配 ab"cde"fgh""ijk"lmn,最终的结果是"cde"fgh""ijk",最开始的双引号和最末尾的双引号中间的全部内容;二是如果有类似 ((...)*)*、((...)+)*之类的,外面里面同时记录不定状态的,回溯次数呈指数级上升,甚至形成死循环,更加耗时。当然对于改进状态的引擎提前检测这种状况,并报告错误,如同浏览器在自己跳转自己的页面那样报错。
因此在用到量词时,比如+,它可以匹配一个到多个,大于一个时,不是必须的,有两种选择状态,可以有也可以没有,这两种状态就是日后可能会在回溯中用到的状态,称为备用状态,?也是如此。
对于匹配双引号及之间的字符,中间不包括转义后的双引号的情况,我们可以使用忽略优先,'/".*?"/' ,忽略优先按量词的最小限度匹配, *最小是没有,相当于先检测空串,没有先匹配一个字符马上检测双引号,这在一定只要检测到右边有一个双引号匹配即成功结束,它匹配上图中的 "McDonald's"也省去了很多回溯。
当然,对于这种需要检测两个字符间的其他字符,还有一种办法,如 '/"[^"]"/',排除型字符组,它也达到了相同的需求,但情况不总是这样。
比如,匹配<b>与</b>之间的字符,使用 '/<b>[^<\/b>]*<\/b>/' ?注意字符组一次只能匹配一个字符,这里是匹配在<b>和</b>之间的,非<、/、b、>的任意一个字符,字符组不能把里边的字符当一个整体,对于整体、多个字符的检测,可以选择环视。环视与位置相关,生来就是限定周围的字符,一个或多个均可。这里需要否定型环视,因为我们需要的不能是</b>的字符,为了好看中间隔开。
'/<b>( (?!<\/b>) . )*<\/b>/' // 否定型环视
但是上面仍能匹配"<b>abc<b>def</b>",所以还要在其之间排除<b>,中间环视检测</?b>,/可以有或没有都行
'/<b> ( (?! <\/? b >) . )* <\/b>/'
上一篇写到了“交还”,在回溯过程中就伴随着交还,如上面的'/".*"!/',因发现双引号后面不是感叹号,而不得不回溯,此时选择另一种备用状态---不匹配刚才匹配到的字符,进行回退,是一个明显的交还。例子:

$pattern_1 = '/(\w+)(\d?)/'; $pattern_2 = '/(\w+)(\d+)/'; $pattern_3 = '/(\w+)(\d*)/'; $subject = 'abc12345'; preg_match($pattern_1, $subject, $match_1); preg_match($pattern_2, $subject, $match_2); preg_match($pattern_3, $subject, $match_3); echo 'match=><pre>'; var_dump($match_1, $match_2, $match_3);
使用捕获型括号,分组,引擎记住两个括号中匹配的文本。结果如下:

从上到下依次为$match_1、$match_2、$match_3,由于\w与\d有公共部分,而且两个量词都是匹配优先,从结果来看,前一个+量词匹配得最多(键值为1的项),pattern_1中,\d?没有匹配,pattern_2中,\d+只匹配了一个,pattern_3中,\d*没有匹配,而它们讷的过程都类似于,先让\w+匹配到末尾,然后引擎看剩余的模式,\d?可有可无,那就无,因为无正则匹配也是成功,不交还。\d+必须匹配一个,否则将导致匹配失败,这里它会交还一个,因为它必须服从使得全局匹配的成功。对于\d*也是如此,可以不匹配,不交还。
假如这里的pattern是'/(\w+)(\d\d)/',那么它就必须交还两个数字,如果没有交还或是带匹配字符串中没有,就只能报告失败。所以有两个规律:
1. 先来先服务原则,匹配优先的量词在前,先尽量满足自己;
2. 必须服从全局匹配结果,有造成失败的可能,引擎会强迫匹配优先量词交还,否则整个匹配失败。
如果不交还呢?就会提前报告失败。必须谈到占有优先量词和固化分组,以+为例形式是 \w++、 (?>\w+)
$pattern = '/\w+:/'; $subject = 'abcdefghijk';
如例,我们人当然能一眼看出来,字符串结尾没有冒号肯定失败,但是程序不会这样,它会一轮又一轮的匹配-回溯,因为它记住了一些可选择性的状态,但现在我们已经明确知道了这些状态是没用的,回溯也是白费力气,回溯前就已经失败了。所以可以 \w++: 或者 (?>\w+): ,有了占有优先或者固化分组,这些可选择性的状态都会被抛弃,\w+一直匹配到字符串结尾,单词没了,然后检测冒号存不存在,冒号不存在,但是现在有没有可供回溯的状态,立即报告失败,如果是几十万行的文本会节省很多时间。
需要注意的是,固话分组或是占有优先对嵌套在里面的量词也是有作用的,这点跟?:只分组不捕获不同
(?> (\d+)+ ) // 里面的\d+的状态也会被抛弃 (?: abc (\d\d) ) // 外层的括号不会被捕获,但里面的括号不受影响,\1仍记录着数字字符
最后记录下选择分支的一个坑,例
$pattern = '/cat/'; $subject = 'indicate big cat';
cat当然会匹配indicate中间的cat,因为它在前面。再看这个
$pattern = 'fat|cat|belly|your'; $subject = 'The dragging belly indicates that your cat is too fat';
NFA以表达式为主导,从表达式的角度看字符串,因此先检测到的是fat,结果是fat吗?结果仍是cat!所以NFA的引擎始终优先匹配选择分支选择最左端的匹配结果,哪怕它位于选择分支的后边。
这也说明,NFA引擎的正则,只要表达式中还存在可能的多选分支,正则引擎会回溯到存在尚未尝试的多选分支的地方,这个过程不断重复,直到完成全局匹配,如果不是这样,上例中fat先匹配成功就已经作为结果返回了。多选状态不是匹配优先,也不是忽略优先,但是尝试是从左到右。而对于DFA和某些POSIX NFA,匹配的不是最靠字符串左端的文本,而是选择分支中最长的分支。
正则的细节太多,扯不清楚,还是得看书理解,尤其是对于正则的调校,以及某些常用的判断技巧,比如匹配" "包围的字符串,中间可以有\"和其他转义序列,还是很麻烦的,推荐《精通正则表达式》,中文翻译挺棒,读起来也不生硬,而且还有很多技巧性的东西,比如“消除循环”是一大利器。end

【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步