Rook云原生存储
1:k8s数据持久化
1:volume:需要后端存储的一些细节
2:PV/PVC:管理员创建/定义PV,用户通过PVC使用PV的存储
3:storageClass:静态+动态,通过PVC声明使用的空间,自动创建PV和后端存储驱动对接
1.1:volumes
1:容器启动依赖数据
1:configmap
2:secret
2:临时数据存储
1:emptyDir
2:hostPath
3:持久化数据存储
1:nfs
2:cephfs
3:GlusterFS(新版本已去除驱动)
4:Cloud Storage
......
总结:这种方式没有单独的资源对象,它是与Pod的生命周期共存
1.2:pv/pvc
我们使用pv的创建存储对象,其实就是将我们的存储实例化成K8S的资源使得k8s可以去在自己的集群中与存储进行对接,这就是PV做的事情,比如创建一个nfs的pv这个时候这个pv的作用就是与nfs服务对接,负责管理访问模式等
pvc的作用就相当于我们要从这个nfs的pv中取出多少来使用比如nfs的pv有100G,pvc需要10G这样子,可以创建多个pvc去这个pv取存储的大小,以及这个存储䣌访问模式,比如只读,读写等。
1.3:storageClass
通过声明存储的提供者,storage自动会帮你去处理与后端存储的对接,包括创建PV等操作,完全由storageClass操作,我们只需要在对象内指定StorageClass的名称就可以了。
1.4:Volume对接
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx
image: nginx:alpine
volumeMounts:
- name: html
mountPath: /usr/share/nginx/html
volumes:
- name: html
nfs:
server: 10.0.0.16
path: /data
1.5:PV/PVC对接
apiVersion: v1
kind: PersistentVolume
metadata:
name: nfs-storage
spec:
capacity:
storage: 1Gi
accessModes:
- ReadWriteMany
nfs:
server: 10.0.0.16
path: /data
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: nginx
spec:
volumeName: nfs-storage
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
---
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx
image: nginx:alpine
volumeMounts:
- name: html
mountPath: /usr/share/nginx/html
volumes:
- name: html
persistentVolumeClaim:
claimName: nginx
1.6:StorageClass对接
# 静态PVC
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: local-storage
provisioner: kubernetes.io/no-provisioner
volumeBindingMode: WaitForFirstConsumer
allowVolumeExpansion: true
parameters:
type: local
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: nginx
spec:
storageClassName: local-storage
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
---
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx
image: nginx:alpine
volumeMounts:
- name: html
mountPath: /usr/share/nginx/html
volumes:
- name: html
persistentVolumeClaim:
claimName: nginx
# 动态创建pvc
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: mysql
spec:
replicas: 3
serviceName: mysql
selector:
matchLabels:
app: mysql
template:
metadata:
labels:
app: mysql
spec:
containers:
- name: mysql
image: mysql:5.7
env:
- name: MYSQL_ROOT_PASSWORD
value: password
volumeMounts:
- name: mysql-persistent-storage
mountPath: /var/lib/mysql
volumes:
- name: mysql-persistent-storage
persistentVolumeClaim:
claimName: mysql-pvc
volumeClaimTemplates:
- metadata:
name: mysql-pvc
spec:
accessModes: ["ReadWriteOnce"]
storageClassName: local-storage
resources:
requests:
storage: 1Gi
2:Rook入门
2.1:Ceph部署方式
1:CephDeploy
2:Cephadm
3:手动部署
4:Rook
2.2:什么是Rook
![]()
官网:https://rook.io
Rook是一套专门为云原生打造的存储方案,并且它专门为K8S提供解决方案,它的存储包括文件存储,块存储和对象存储,我们可以理解为Rook其实是一个存储引擎,它可以与各类存储进行对接最常见的比如Ceph,而Rook就是可以提供基于K8S对接Ceph的驱动,这就是Rook的核心,它其实也是借助Operator去做这个事情,当然了,Rook可以帮助我们解决管理Ceph的困扰,我们都知道Operator的便捷之处,而Rook就是利用Operator帮我们去管理Ceph。
2.3:Rook的存储类型
1:Ceph
2:NFS
3:Cassandra
......
2.4:Rook特性
1:简单可靠的自动化资源管理
2:超融合存储解决方案
3:有效的数据分发,以及数据的分布,保障数据的可用性
4:兼容多种存储方式
5:管理多种存储的解决方案
6:在您的数据中心轻松启用弹性存储
7:在 Apache 2.0 许可下发布的开源软件
8:可以运行在普通的硬件上设备上
2.5:Rook结合K8S
1:rook负责初始化和管理Ceph集群
1:monitor集群
2:mgr集群
3:osd集群
4:pool管理
5:对象存储
6:⽂件存储
7:监视和维护集群健康状态
2:rook负责提供访问存储所需的驱动
1:Flex驱动(旧驱动,不建议使⽤)
2:CSI驱动
3:RBD块存储
4:CephFS⽂件存储
5:S3/Swift⻛格对象存储
2.6:Rook架构
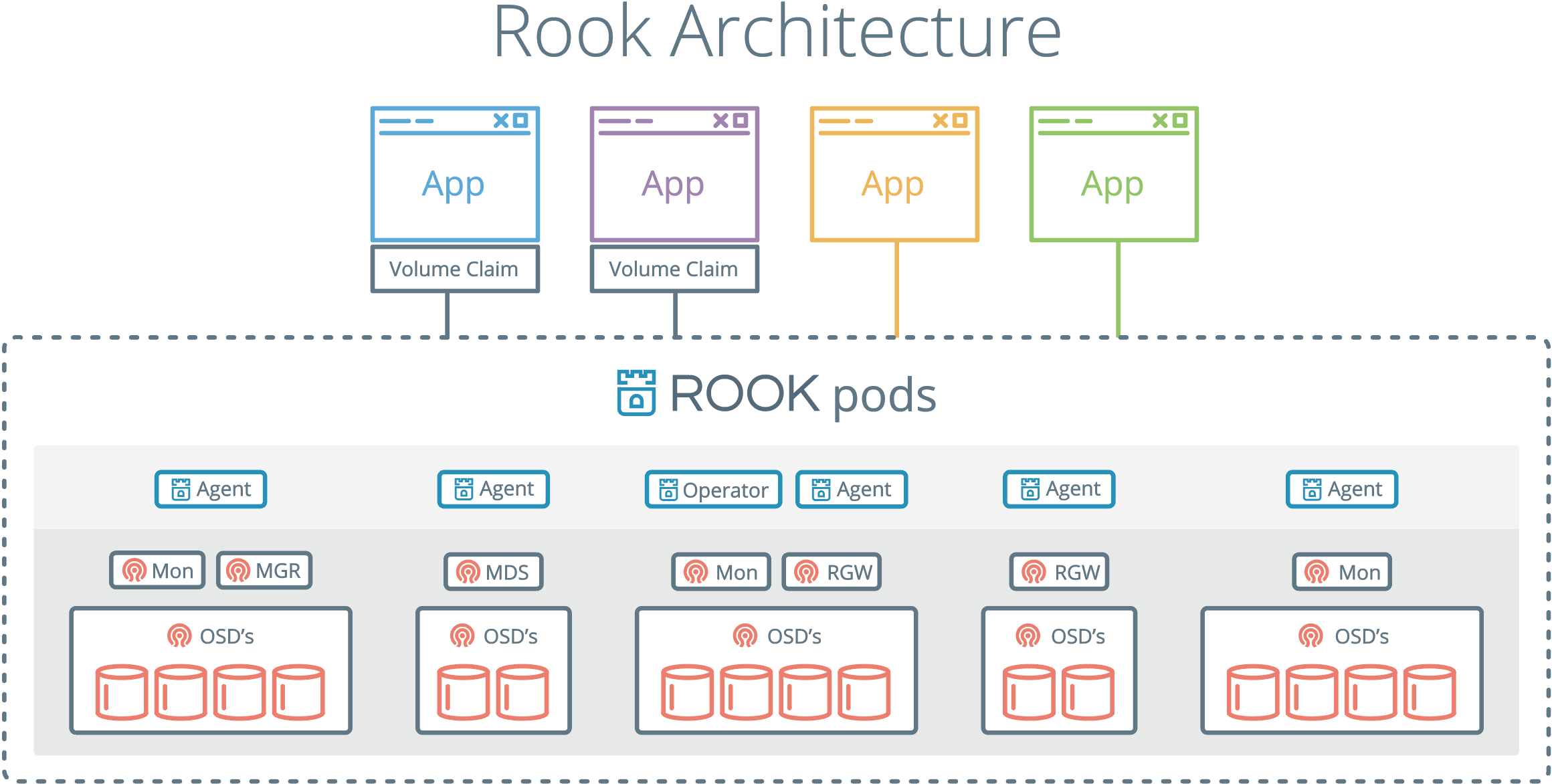
1:以上的所有对象都依托于Kubernetes集群
1:MON
2:RGW
3:MDS
4:MGR
5:OSD
6:Agent
1:csi-rbdplugin
2:csi-cephfsplugin
2:抽象化管理
1:pool
2:volumes
3:filesystems
4:buckets
3:Rook部署
3.1:环境介绍
| 节点 | IP | k8s角色 | 设备 | 系统 | k8s版本 |
|---|---|---|---|---|---|
| cce-kubernetes-master-1 | 10.0.0.16 | master | /dev/sdb | CentOS7.9 | 1.24.3 |
| cce-kubernetes-worker-1 | 10.0.0.17 | worker | /dev/sdb | CentOS7.9 | 1.24.3 |
3.2:部署Rook
前提条件
1:已经部署好的Kubernetes 1.11+
2:OSD节点需要有未格式化文件系统的磁盘
3:需要具备Linux基础
4:需要具备Ceph基础
1:mon
2:mds
3:rgw
4:osd
5:需要具备Kubernetes基础
1:Node,Pod
2:Deployment,Services,Statefulset
3:Volume,PV,PVC,StorageClass
3.3:获取源码并安装
# 如果需要master参与那么请将Master的污点去掉,否则无法参与Ceph的创建,或者在创建cluster的时候去修改配置可以容忍这些污点
[root@cce-kubernetes-master-1 ~]# git clone --single-branch --branch v1.10.12 https://github.com/rook/rook.git
[root@cce-kubernetes-master-1 ~]# cd rook/deploy/examples
[root@cce-kubernetes-master-1 examples]# kubectl create -f crds.yaml -f common.yaml -f operator.yaml
[root@cce-kubernetes-master-1 examples]# kubectl create -f cluster.yaml
[root@cce-kubernetes-master-1 examples]# kubectl get pod -n rook-ceph
NAME READY STATUS RESTARTS AGE
csi-cephfsplugin-h4csc 2/2 Running 0 17m
csi-cephfsplugin-provisioner-7c594f8cf-97fbd 5/5 Running 0 17m
csi-cephfsplugin-provisioner-7c594f8cf-fprzt 5/5 Running 0 17m
csi-cephfsplugin-z5bs4 2/2 Running 0 17m
csi-rbdplugin-6xtzq 2/2 Running 0 17m
csi-rbdplugin-85k2n 2/2 Running 0 17m
csi-rbdplugin-provisioner-99dd6c4c6-7q9rr 5/5 Running 0 17m
csi-rbdplugin-provisioner-99dd6c4c6-qrmtx 5/5 Running 0 17m
rook-ceph-crashcollector-cce-kubernetes-master-1-6b7c4c7885xbbw 1/1 Running 0 3m22s
rook-ceph-crashcollector-cce-kubernetes-worker-1-665df7874tgtwg 1/1 Running 0 3m23s
rook-ceph-mgr-a-f8b75cdb4-vs5mv 3/3 Running 0 7m28s
rook-ceph-mgr-b-6957b9b96f-xsbqc 3/3 Running 0 7m28s
rook-ceph-mon-a-5749c8659b-jn2cd 2/2 Running 0 13m
rook-ceph-mon-b-74d87b779f-8496k 2/2 Running 0 12m
rook-ceph-mon-c-7d7747cb6b-h65tv 2/2 Running 0 12m
rook-ceph-operator-644954fb4b-lfqnn 1/1 Running 0 92m
rook-ceph-osd-0-98876657-mqqlg 2/2 Running 0 3m23s
rook-ceph-osd-1-5c7675c47b-hhn58 2/2 Running 0 3m22s
rook-ceph-osd-prepare-cce-kubernetes-master-1-rrcpb 0/1 Completed 0 2m57s
rook-ceph-osd-prepare-cce-kubernetes-worker-1-jr5f6 0/1 Completed 0 2m54s
# 镜像下载不下来的话需要指定一下国内的加速或者魔法上网哦!
4:Ceph集群管理
4.1:Ceph资源对象
Ceph包含如下组件:
1:mon:monitor 管理集群
2:mgr:manager 监控管理
3:mds:CephFS 元数据管理
4:rgw:对象存储
5:osd:存储
4.2:ToolBox部署
其实这是一个Ceph的客户端,我们可以通过部署这个客户端来管理Ceph
[root@cce-kubernetes-master-1 ~]# cd /root/rook/deploy/examples
[root@cce-kubernetes-master-1 examples]# kubectl apply -f toolbox.yaml
deployment.apps/rook-ceph-tools created
# 这里我中间换了一套集群,因为我用的是CentOS7,但是Ceph最新版没有客户端包了,所以就换成了9的系统,不问题不大,不影响使用的
[root@cce-kubernetes-master-1 ~]# kubectl exec -it -n rook-ceph rook-ceph-tools-7857bc9568-m5rwl ceph status
kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl exec [POD] -- [COMMAND] instead.
cluster:
id: 60586a3f-6348-4bac-bd6b-868ae18a4dbe
health: HEALTH_OK
services:
mon: 3 daemons, quorum a,b,c (age 11m)
mgr: a(active, since 10m), standbys: b
osd: 3 osds: 3 up (since 10m), 3 in (since 11m)
data:
pools: 1 pools, 1 pgs
objects: 2 objects, 577 KiB
usage: 63 MiB used, 150 GiB / 150 GiB avail
pgs: 1 active+clean
4.3:K8S节点访问Ceph
[root@cce-kubernetes-master-1 ~]# kubectl exec -it -n rook-ceph rook-ceph-tools-7857bc9568-m5rwl cat /etc/ceph/ceph.conf
kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl exec [POD] -- [COMMAND] instead.
[global]
mon_host = 10.96.3.63:6789,10.96.0.138:6789,10.96.3.71:6789
[client.admin]
keyring = /etc/ceph/keyring
[root@cce-kubernetes-master-1 ~]# kubectl exec -it -n rook-ceph rook-ceph-tools-7857bc9568-m5rwl cat /etc/ceph/keyring
kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl exec [POD] -- [COMMAND] instead.
[client.admin]
key = AQBiNyhk46mRCRAA5SSOvLmSeapr55zjm/J3yA==
# 将这些配置原封不动的配置到需要访问Ceph集群的节点上
# ceph的客户端的配置是这样的,所以我们k8s去访问的时候基本上就是访问monitor的svc的IP和Port就可以了。
[root@cce-kubernetes-master-1 ~]# kubectl get svc -n rook-ceph
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
rook-ceph-mgr ClusterIP 10.96.0.155 <none> 9283/TCP 7h6m
rook-ceph-mgr-dashboard ClusterIP 10.96.2.106 <none> 8443/TCP 7h6m
rook-ceph-mon-a ClusterIP 10.96.1.106 <none> 6789/TCP,3300/TCP 7h12m
rook-ceph-mon-b ClusterIP 10.96.1.209 <none> 6789/TCP,3300/TCP 7h12m
rook-ceph-mon-c ClusterIP 10.96.2.234 <none> 6789/TCP,3300/TCP 7h11m
# 我们将配置放到任何一个Ceph的client上都是可以的,前提是要配置ceph的源
[root@cce-kubernetes-master-1 ~]# cat /etc/yum.repos.d/ceph.repo
[ceph]
name=ceph
baseurl=https://mirrors.tuna.tsinghua.edu.cn/ceph/rpm-17.2.5/el8/x86_64/
enabled=1
gpgcheck=0
[root@cce-kubernetes-master-1 ~]# yum install -y ceph-common.x86_64
[root@cce-kubernetes-master-1 ~]# ceph status
cluster:
id: 60586a3f-6348-4bac-bd6b-868ae18a4dbe
health: HEALTH_OK
services:
mon: 3 daemons, quorum a,b,c (age 12m)
mgr: a(active, since 11m), standbys: b
osd: 3 osds: 3 up (since 11m), 3 in (since 11m)
data:
pools: 1 pools, 1 pgs
objects: 2 objects, 577 KiB
usage: 63 MiB used, 150 GiB / 150 GiB avail
pgs: 1 active+clean
4.4:访问RBD
# 创建Pool
[root@cce-kubernetes-master-1 ~]# ceph osd pool create rook 16 16
pool 'rook' created
# 查看创建的Pool
[root@cce-kubernetes-master-1 ~]# ceph osd lspools
1 .mgr
2 rook
# 创建块存储
[root@cce-kubernetes-master-1 ~]# rbd create -p rook --image rook-rbd.img --size 1G
# 查看块存储
[root@cce-kubernetes-master-1 ~]# rbd ls -p rook
rook-rbd.img
# 详情
[root@cce-kubernetes-master-1 ~]# rbd info rook/rook-rbd.img
rbd image 'rook-rbd.img':
size 1 GiB in 256 objects
order 22 (4 MiB objects)
snapshot_count: 0
id: 3d213141932
block_name_prefix: rbd_data.3d213141932
format: 2
features: layering, exclusive-lock, object-map, fast-diff, deep-flatten
op_features:
flags:
create_timestamp: Sat Apr 1 22:12:51 2023
access_timestamp: Sat Apr 1 22:12:51 2023
modify_timestamp: Sat Apr 1 22:12:51 2023
# 使用块存储
[root@cce-kubernetes-master-1 ~]# rbd map rook/rook-rbd.img
/dev/rbd0
[root@cce-kubernetes-master-1 ~]# rbd showmapped
id pool namespace image snap device
0 rook rook-rbd.img - /dev/rbd0
# 这个时候我们就可以把/dev/rbd0当成本地的磁盘是正常的格式化使用了。
[root@cce-kubernetes-master-1 ~]# mkfs.xfs /dev/rbd0
meta-data=/dev/rbd0 isize=512 agcount=8, agsize=32768 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=1, sparse=1, rmapbt=0
= reflink=1 bigtime=1 inobtcount=1
data = bsize=4096 blocks=262144, imaxpct=25
= sunit=16 swidth=16 blks
naming =version 2 bsize=4096 ascii-ci=0, ftype=1
log =internal log bsize=4096 blocks=2560, version=2
= sectsz=512 sunit=16 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
Discarding blocks...Done.
[root@cce-kubernetes-master-1 ~]# mkdir /data
[root@cce-kubernetes-master-1 ~]# mount -t xfs /dev/rbd0 /data
[root@cce-kubernetes-master-1 ~]# df | grep /data
/dev/rbd0 1038336 40500 997836 4% /data
5:定制Rook集群
5.1:placement调度概述
Rook借助Kubernetes默认的调度机制,Ceph组件以Pods的方式调度运行在K8S节点中,然而每个节点因为角色不一样,其机器的配置也有所不同,比如mds对CPU要求是比较高的,磁盘却要求并不高,恰恰相反,OSD节点则对磁盘和内存的要求是比较高的,CPU却成了次要的,因此我们在规划的时候需要根据角色的不同来分配节点。
Rook提供了多种调度策略:
1:nodeAffinity:节点亲和力调度,根据Labels选择合适的调度节点。
2:podAffinity:Pod亲和力调度,将Pod调度到具有相同性质类型的节点上
3:podAntAffinity:Pod反亲和调度,将Pod调度到与某些Pod相反的节点
4:topologySpreadConstraints:拓扑选择调度
5:tolerations:污点容忍调度,允许调度到某些具有“污点”的节点上
Rook支持的调度对象
1:mon
2:mgr
3:osd
4:cleanup
[root@cce-kubernetes-master-1 ~]# kubectl get pod -n rook-ceph -owide | awk '{print $1,$3,$7}'
NAME STATUS NODE
csi-cephfsplugin-j2r8d Running cce-kubernetes-master-1
csi-cephfsplugin-provisioner-7c594f8cf-m6dpg Running cce-kubernetes-worker-1
csi-cephfsplugin-provisioner-7c594f8cf-rkb9p Running cce-kubernetes-worker-2
csi-cephfsplugin-sfr57 Running cce-kubernetes-worker-2
csi-cephfsplugin-x55ds Running cce-kubernetes-worker-1
csi-rbdplugin-4j7s2 Running cce-kubernetes-worker-2
csi-rbdplugin-7phpk Running cce-kubernetes-worker-1
csi-rbdplugin-ftznl Running cce-kubernetes-master-1
csi-rbdplugin-provisioner-99dd6c4c6-xknw8 Running cce-kubernetes-worker-1
csi-rbdplugin-provisioner-99dd6c4c6-z4x4s Running cce-kubernetes-worker-2
rook-ceph-crashcollector-cce-kubernetes-master-1-6b7c4c788jk2rv Running cce-kubernetes-master-1
rook-ceph-crashcollector-cce-kubernetes-worker-1-665df7874r5twr Running cce-kubernetes-worker-1
rook-ceph-crashcollector-cce-kubernetes-worker-2-854d69f5ch9v4j Running cce-kubernetes-worker-2
rook-ceph-mgr-a-5dbb7d78fb-rvwfv Running cce-kubernetes-worker-2
rook-ceph-mgr-b-7cc79bc7fc-dppfc Running cce-kubernetes-worker-1
rook-ceph-mon-a-cb6b6cfc-t8djd Running cce-kubernetes-worker-2
rook-ceph-mon-b-7bfff49bd9-csjxz Running cce-kubernetes-worker-1
rook-ceph-mon-c-6f5b6466b4-4qz24 Running cce-kubernetes-master-1
rook-ceph-operator-644954fb4b-g4jq4 Running cce-kubernetes-worker-1
rook-ceph-osd-0-6bcf58f497-sm5q5 Running cce-kubernetes-worker-2
rook-ceph-osd-1-7599b8fdd-qdq7w Running cce-kubernetes-worker-1
rook-ceph-osd-2-84cf6cbcdb-whjsn Running cce-kubernetes-master-1
rook-ceph-osd-prepare-cce-kubernetes-master-1-q64s2 Completed cce-kubernetes-master-1
rook-ceph-osd-prepare-cce-kubernetes-worker-1-xjwjk Completed cce-kubernetes-worker-1
rook-ceph-osd-prepare-cce-kubernetes-worker-2-tq7p6 Completed cce-kubernetes-worker-2
rook-ceph-tools-7857bc9568-m5rwl Running cce-kubernetes-worker-1
[root@cce-kubernetes-master-1 examples]# vim cluster.yaml
......
# placement:
# all:
# nodeAffinity:
# requiredDuringSchedulingIgnoredDuringExecution:
# nodeSelectorTerms:
# - matchExpressions:
# - key: role
# operator: In
# values:
# - storage-node
# podAffinity:
# podAntiAffinity:
# topologySpreadConstraints:
# tolerations:
# - key: storage-node
# operator: Exists
# The above placement information can also be specified for mon, osd, and mgr components
# mon:
# Monitor deployments may contain an anti-affinity rule for avoiding monitor
# collocation on the same node. This is a required rule when host network is used
# or when AllowMultiplePerNode is false. Otherwise this anti-affinity rule is a
# preferred rule with weight: 50.
# osd:
# prepareosd:
# mgr:
# cleanup:
......
5.2:清理Rook集群
参考文档:https://www.rook.io/docs/rook/v1.11/Getting-Started/ceph-teardown/
[root@cce-kubernetes-master-1 ~]# kubectl delete -f rook/deploy/examples/cluster.yaml
[root@cce-kubernetes-master-1 ~]# kubectl delete -f rook/deploy/examples/toolbox.yaml
[root@cce-kubernetes-master-1 ~]# kubectl delete -f rook/deploy/examples/operator.yaml
[root@cce-kubernetes-master-1 ~]# kubectl delete -f rook/deploy/examples/crds.yaml
[root@cce-kubernetes-master-1 ~]# kubectl delete -f rook/deploy/examples/common.yaml
# 过程可能需要大量的时间,当然如果按照顺序的话是没问题的,但是我们这个方法是一下子删除了所有的东西,所以有些API的依赖就找不到,所以就无法删除了
# 强删Namespace的方法也很简单,就是get指定的namespace然后导出Json格式,然后删除spec下面的信息,重新执行以下curl使用api删除就OK了,前提是得用kubectl proxy指定一下端口。
curl -k -H "Content-Type: application/json" -X PUT --data-binary @rook.json http://127.0.0.1:8888/api/v1/namespaces/rook-ceph/finalize
5.3:定制mon调度参数
# 如果您将Rook用于生产,那么一定要定制这些参数,需要让固定的机器去承载Ceph的各个组件,当然既然是K8S的调度,我们完全可以使用K8S原生的调度机制
这里用到了node的亲和性调度,如果节点上有`ceph-mon: enabled`的标签,那么就调度可以调度到这个节点,否则就无法调度,当然如果想更细致,也可以和其他的调度算法一起使用,这样粒度可以更高。
...
placement:
mon:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: ceph-mon
operator: In
values:
- enabled
...
storage:
useAllNodes: false
useAllDevices: false
# 这样我们去重建一下Rook
[root@cce-kubernetes-master-1 examples]# kubectl apply -f common.yaml -f crds.yaml -f operator.yaml
[root@cce-kubernetes-master-1 examples]# kubectl get pod -n rook-ceph
NAME READY STATUS RESTARTS AGE
csi-cephfsplugin-b4b45 2/2 Running 0 2m16s
csi-cephfsplugin-cn67w 2/2 Running 0 2m16s
csi-cephfsplugin-mgn98 2/2 Running 0 2m16s
csi-cephfsplugin-provisioner-7c594f8cf-7nn78 5/5 Running 0 2m16s
csi-cephfsplugin-provisioner-7c594f8cf-k4tmd 5/5 Running 0 2m16s
csi-rbdplugin-9bx8j 2/2 Running 0 2m16s
csi-rbdplugin-gjzc5 2/2 Running 0 2m16s
csi-rbdplugin-provisioner-99dd6c4c6-97xm4 5/5 Running 0 2m16s
csi-rbdplugin-provisioner-99dd6c4c6-l5q4w 5/5 Running 0 2m16s
csi-rbdplugin-z26d7 2/2 Running 0 2m16s
rook-ceph-detect-version-6bwww 0/1 Pending 0 2m20s
rook-ceph-operator-644954fb4b-ph7jw 1/1 Running 0 2m40s
# 因为我们有定制,所以会有一个无法调度,因为没有符合的标签,所以我们需要去给固定的节点去打上标签,所以我这里给Master打上标签
[root@cce-kubernetes-master-1 examples]# kubectl label nodes cce-kubernetes-master-1 ceph-mon=enabled
node/cce-kubernetes-master-1 labeled
[root@cce-kubernetes-master-1 examples]# kubectl get pod -n rook-ceph
NAME READY STATUS RESTARTS AGE
csi-cephfsplugin-b4b45 2/2 Running 0 5m33s
csi-cephfsplugin-cn67w 2/2 Running 0 5m33s
csi-cephfsplugin-mgn98 2/2 Running 0 5m33s
csi-cephfsplugin-provisioner-7c594f8cf-7nn78 5/5 Running 0 5m33s
csi-cephfsplugin-provisioner-7c594f8cf-k4tmd 5/5 Running 0 5m33s
csi-rbdplugin-9bx8j 2/2 Running 0 5m33s
csi-rbdplugin-gjzc5 2/2 Running 0 5m33s
csi-rbdplugin-provisioner-99dd6c4c6-97xm4 5/5 Running 0 5m33s
csi-rbdplugin-provisioner-99dd6c4c6-l5q4w 5/5 Running 0 5m33s
csi-rbdplugin-z26d7 2/2 Running 0 5m33s
rook-ceph-mon-a-canary-6765fd8d4f-9fknh 0/2 Pending 0 84s
rook-ceph-mon-b-canary-8449df56cd-fqdfz 2/2 Running 0 84s
rook-ceph-mon-c-canary-79f866997f-jjm5t 0/2 Pending 0 84s
rook-ceph-operator-644954fb4b-ph7jw 1/1 Running 0 5m57s
# 可以看到这样就起来了,但是还是有的节点是Pending,那是因为什么呢?其实这个就是还是不符合标签规则,这个在Cluster.yaml的时候有一个关键名词叫`allowMultiplePerNode`,也就是说它不允许单个节点上运行多个mon,所以导致了这个问题,所以解决这个问题的方法也很简单,如果是生产,那么就直接在规划好的承载mon的节点上也打上标签`ceph-mon: enabled`就可以了,稍等一会儿就会将Operator会watch到操作,然后就会重新启动mon到符合标签的节点上了。
[root@cce-kubernetes-master-1 examples]# kubectl get pod -n rook-ceph
NAME READY STATUS RESTARTS AGE
csi-cephfsplugin-hhg7x 2/2 Running 0 114s
csi-cephfsplugin-provisioner-7c594f8cf-qpnwg 5/5 Running 0 114s
csi-cephfsplugin-provisioner-7c594f8cf-qs2t9 5/5 Running 0 114s
csi-cephfsplugin-pw785 2/2 Running 0 114s
csi-cephfsplugin-w6wnc 2/2 Running 0 114s
csi-rbdplugin-provisioner-99dd6c4c6-7v5lq 5/5 Running 0 114s
csi-rbdplugin-provisioner-99dd6c4c6-x5jkf 5/5 Running 0 114s
csi-rbdplugin-s94x4 2/2 Running 0 114s
csi-rbdplugin-sqhd6 2/2 Running 0 114s
csi-rbdplugin-t6xzv 2/2 Running 0 114s
rook-ceph-mon-a-7744687d9c-x5vgl 2/2 Running 0 105s
rook-ceph-mon-b-5b6546b457-v6xl5 2/2 Running 0 78s
rook-ceph-mon-c-598bf66c9-gx2bz 2/2 Running 0 67s
rook-ceph-operator-644954fb4b-ph7jw 1/1 Running 2 (7m29s ago) 29m
5.4:定制mgr调度参数
...
mgr:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: ceph-mgr
operator: In
values:
- enabled
...
其实原理一样,我们只需要开启固定组件的调度策略就行了
[root@cce-kubernetes-master-1 examples]# kubectl label nodes cce-kubernetes-worker-1 ceph-mgr=enabled
node/cce-kubernetes-worker-1 labeled
[root@cce-kubernetes-master-1 examples]# kubectl label nodes cce-kubernetes-worker-2 ceph-mgr=enabled
node/cce-kubernetes-worker-2 labeled
[root@cce-kubernetes-master-1 examples]# kubectl get pod -n rook-ceph
NAME READY STATUS RESTARTS AGE
csi-cephfsplugin-hhg7x 2/2 Running 0 60m
csi-cephfsplugin-provisioner-7c594f8cf-qpnwg 5/5 Running 0 60m
csi-cephfsplugin-provisioner-7c594f8cf-qs2t9 5/5 Running 0 60m
csi-cephfsplugin-pw785 2/2 Running 0 60m
csi-cephfsplugin-w6wnc 2/2 Running 0 60m
csi-rbdplugin-provisioner-99dd6c4c6-7v5lq 5/5 Running 0 60m
csi-rbdplugin-provisioner-99dd6c4c6-x5jkf 5/5 Running 0 60m
csi-rbdplugin-s94x4 2/2 Running 0 60m
csi-rbdplugin-sqhd6 2/2 Running 0 60m
csi-rbdplugin-t6xzv 2/2 Running 0 60m
rook-ceph-crashcollector-cce-kubernetes-master-1-74b86f89bwpprg 1/1 Running 0 53m
rook-ceph-crashcollector-cce-kubernetes-worker-1-7557f44975vz6x 1/1 Running 0 54m
rook-ceph-crashcollector-cce-kubernetes-worker-2-868b99f7cssvhj 1/1 Running 0 54m
rook-ceph-mgr-a-5f5bbbc559-hnbzz 3/3 Running 0 65s
rook-ceph-mgr-b-7d67888786-2z8f8 3/3 Running 0 40s
rook-ceph-mon-a-7744687d9c-x5vgl 2/2 Running 0 60m
rook-ceph-mon-b-5b6546b457-v6xl5 2/2 Running 0 60m
rook-ceph-mon-d-6bb98ddb88-4775f 2/2 Running 0 53m
rook-ceph-operator-644954fb4b-ph7jw 1/1 Running 2 (66m ago) 88m
# 所以不太好看调度节点,我们用awk过滤出来看看
[root@cce-kubernetes-master-1 examples]# kubectl get pod -n rook-ceph -owide | awk '{print $1,$2,$3,$7}'
NAME READY STATUS NODE
......
rook-ceph-mgr-a-5f5bbbc559-hnbzz 3/3 Running cce-kubernetes-worker-2
rook-ceph-mgr-b-7d67888786-2z8f8 3/3 Running cce-kubernetes-worker-1
rook-ceph-mon-a-7744687d9c-x5vgl 2/2 Running cce-kubernetes-worker-1
rook-ceph-mon-b-5b6546b457-v6xl5 2/2 Running cce-kubernetes-worker-2
rook-ceph-mon-d-6bb98ddb88-4775f 2/2 Running cce-kubernetes-master-1
......
# 可以看到调度的是按照我们的定制去调度的,当然我们可以多开几个节点做节点之间的冗余,至少不会出现一个节点挂了,其他节点也无法调度的情况出现。
5.5:定制OSD存储调度
在前面我们定制mon的时候我们还记得有一个storage下面的两个参数我们给改了改成了`false`也就是说,默认不去找我们节点上的所有存储,那么这里我们就用到了那个storage下面的参数,我们下面来定制一下。
...
storage: # cluster level storage configuration and selection
useAllNodes: false
useAllDevices: false
#deviceFilter:
config:
# crushRoot: "custom-root" # specify a non-default root label for the CRUSH map
# metadataDevice: "md0" # specify a non-rotational storage so ceph-volume will use it as block db device of bluestore.
# databaseSizeMB: "1024" # uncomment if the disks are smaller than 100 GB
# journalSizeMB: "1024" # uncomment if the disks are 20 GB or smaller
# osdsPerDevice: "1" # this value can be overridden at the node or device level
# encryptedDevice: "true" # the default value for this option is "false"
# Individual nodes and their config can be specified as well, but 'useAllNodes' above must be set to false. Then, only the named
# nodes below will be used as storage resources. Each node's 'name' field should match their 'kubernetes.io/hostname' label.
nodes:
- name: "cce-kubernetes-master-1"
devices: # specific devices to use for storage can be specified for each node
- name: "sda"
config:
journalSizeMB: "4096"
- name: "cce-kubernetes-worker-1"
devices: # specific devices to use for storage can be specified for each node
- name: "sda"
config:
journalSizeMB: "4096"
- name: "cce-kubernetes-worker-2"
devices: # specific devices to use for storage can be specified for each node
- name: "sda"
config:
journalSizeMB: "4096"
...
# 这里有一点需要说明。这里每个节点的每个盘都是可以单独设置参数的,如果不设置的话就继承config下的参数。
# 执行apply,前提是记得清空一下盘的Ceph标识,否则是不会生效的
[root@cce-kubernetes-master-1 examples]# kubectl apply -f cluster.yaml
cephcluster.ceph.rook.io/rook-ceph configured
[root@cce-kubernetes-master-1 examples]# kubectl get pod -n rook-ceph -owide | awk '{print $1,$2,$3,$7}'
NAME READY STATUS NODE
......
rook-ceph-osd-0-6b594b854c-5mkqw 2/2 Running cce-kubernetes-master-1
rook-ceph-osd-1-6d7ccd76f4-kcvxb 2/2 Running cce-kubernetes-worker-1
rook-ceph-osd-2-5bbf555979-w9r9b 2/2 Running cce-kubernetes-worker-2
# 可以看到OSD也是按照我们的预想去调度到了指定的节点上,看客户端OSD为3个
[root@cce-kubernetes-master-1 examples]# ceph status
cluster:
id: 4093033c-5fdd-4b57-87a5-681a50e5a9e6
health: HEALTH_OK
services:
mon: 3 daemons, quorum a,b,d (age 3h)
mgr: b(active, since 2h), standbys: a
osd: 3 osds: 3 up (since 2m), 3 in (since 2m)
data:
pools: 1 pools, 1 pgs
objects: 2 objects, 577 KiB
usage: 63 MiB used, 150 GiB / 150 GiB avail
pgs: 1 active+clean
# 那么我们后续扩容节点的时候就可以将新节点加入集群,然后同样的方法配置到cluster.yaml中去重新Apply一下就可以了
5.6:定制资源限制
其实前面我们做的都是没有默认的资源限制的,也就是在`cluster.yaml`中是有resources限制的,我们可以根据自己的需求去配置一定的资源限制,为了保证Ceph核心组件可以分配到一定量的资源,的确是该需要分配固定的资源的。
1:mon:(推荐内存128G)
2:mds
3:osd:每T存储建议对应4G内存
# 我这里是做测试,所以就随便改改了
...
resources:
mon:
limits:
cpu: "1000m"
memory: "204Mi"
requests:
cpu: "1000m"
memory: "2048Mi"
mgr:
limits:
cpu: "1000m"
memory: "2048Mi"
requests:
cpu: "1000m"
memory: "2048Mi"
osd:
limits:
cpu: "1000m"
memory: "2048Mi"
requests:
cpu: "1000m"
memory: "2048Mi"
...
不过我这里配置其实不够了,我就不去做这个操作了,但是操作就是这样的,不过这里有个问题需要告诉大家,如果OSD分配的内存过于小的话是或报错的,Pod内会报堆栈的问题的,就像我上面的配置其实按正常逻辑是无法启动的,会报错的。
5.7:健康检查
# 这里我们还需要了解的就是关于这些组件之间的健康检查的情况,因为组件如果不健康,我们也无法第一时间获取到组件的运行情况的话肯定是不行的,所以我们就涉及到了健康检查的配置,当然,这个也是在cluster.yaml内配置的。
这里支持的检测组件有:
1:mon
2:osd
3:mgr
# 老版本15.x还不支持startupProbe,但是我们目前这个版本已经是支持了的,并且这些机制默认都是开启的。
...
healthCheck:
# 守护进程检查,这里默认都是开启的
daemonHealth:
mon:
disabled: false
interval: 45s
osd:
disabled: false
interval: 60s
status:
disabled: false
interval: 60s
# Change pod liveness probe timing or threshold values. Works for all mon,mgr,osd daemons.
livenessProbe:
mon:
disabled: false
mgr:
disabled: false
osd:
disabled: false
# Change pod startup probe timing or threshold values. Works for all mon,mgr,osd daemons.
startupProbe:
mon:
disabled: false
mgr:
disabled: false
osd:
disabled: false
...
当我们容器发生故障的时候,比如说某个容器异常的时候会被快速拉起,比如我们手动触发一个故障Kill掉ceph-mon的进程然后k8s的状态会出现问题,那么这个时候这些检测机制的作用就出来了,它就会快速的重启这个故障,来自动解决这个问题。这个配置其实在`describe`的`pod`的时候就会有这个配置。只要是支持的组件都是相同的操作,也都是相同的检测方法,原理也都一致。
6:云原生RBD存储
6.1:什么是块存储
块存储是一种数据存储技术,它以块为单位将数据写入磁盘或其他存储介质中。块存储通常被用于服务器、数据中心和云计算等环境中,以存储大规模数据集。
块存储系统通常由一个或多个块存储设备组成,这些设备可以是磁盘、固态硬盘 (SSD) 或其他存储介质。块存储设备通常具有高速读写能力和高可靠性。每个块存储设备都有一个控制器,负责管理块设备的读写操作,并将数据块复制到多个设备上以提高容错性和数据冗余性。
块存储的主要优点是高速读写能力、高可靠性和数据冗余性。块存储设备可以快速地读取和写入数据,并且可以自动处理数据的复制、备份和恢复等操作。此外,块存储设备还具有高度的容错性和可靠性,因为它们可以将数据复制到多个设备上,并在其中一个设备失败时自动切换到其他设备上。
块存储系统通常被用于存储大规模数据集,如数据库、文件系统、云计算平台等。它们也被用于存储关键数据,如服务器操作系统、应用程序和数据仓库等。
1:阿里云:EBS
2:腾讯云:CBS
3:Ceph:RBD
......
相信大家也都用过云盘,那么云盘可以做什么,当然我们的RBD也就可以做什么,比如快照备份,增量备份,内核驱动等,都是可以支持到的
1:Thin-provisioned (受分配,使用多少分配多少,慢慢扩大)
2:Images up to 16 exabytes (单个镜像最大16EB)
3:Configurable striping(可配置切片)
4:In-memory caching (内存缓存)
5:Snapshots(支持快照)
6:Copy-on-write cloning(快照克隆)
7:Kernel driver support(内核支持)
8:KVM/libvirt support(kvm/librirt支持)
9:Back-end for cloud solutions(后端支持云解决方案)
10:Incremental backup(增量备份)
11:Disaster recovery (multisite asynchronous replication)(灾难恢复)
6.2:RBD与StorageClass
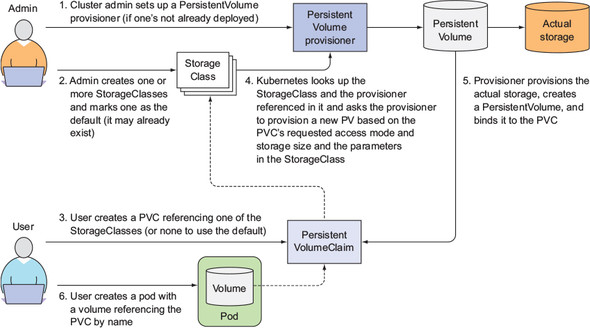
# 对接的三种方式
1:volume: 卷的存储方式,支持多种驱动,FC,EBS,Ceph等
2:PV/PVC : Persistent Volume 和 Persistent Volume Claim
3:StorageClass : 包含静态+动态两种
管理员定义好 provioner
终端用户通过 PVC 关联
Ceph对接RBD参考文档:https://docs.ceph.com/en/latest/rbd/rbd-kubernetes/
6.3:Ceph驱动
Ceph 和 kubernetes 的对接过程涉及到 pool 的创建, Ceph 认证信息,配置文件, CSI 驱动部署, StorageClass 创建等一系列过程。配置过程有一定的难度,如果对 Ceph 不熟悉的同学,对接可能有一定难度,而 Rook 则将这些配置过程简化,以云原生的方式实现对接,其默认已经继承好相关驱动,直接通过 kubernetes 创建 storageclass 即可
[root@cce-k8s-m-1 examples]# kubectl get pod -n rook-ceph
NAME READY STATUS RESTARTS AGE
csi-cephfsplugin-j9vq7 2/2 Running 0 13h
csi-cephfsplugin-nrp7f 2/2 Running 0 13h
csi-cephfsplugin-pl5vt 2/2 Running 0 13h
csi-cephfsplugin-provisioner-7c594f8cf-s7s9n 5/5 Running 0 13h
csi-cephfsplugin-provisioner-7c594f8cf-w6h47 5/5 Running 0 13h
csi-rbdplugin-2cwbl 2/2 Running 0 13h
csi-rbdplugin-4wpd5 2/2 Running 0 13h
csi-rbdplugin-dknj9 2/2 Running 0 13h
csi-rbdplugin-provisioner-99dd6c4c6-9vhnt 5/5 Running 0 13h
csi-rbdplugin-provisioner-99dd6c4c6-zqcwt 5/5 Running 0 13h
rook-ceph-crashcollector-cce-k8s-m-1-7499dbfff4-dcqg9 1/1 Running 0 13h
rook-ceph-crashcollector-cce-k8s-w-1-b58c96cb4-p7kx9 1/1 Running 0 13h
rook-ceph-crashcollector-cce-k8s-w-2-7db46448d5-xd25b 1/1 Running 0 13h
rook-ceph-mgr-a-c9b6d5b69-jfd4s 3/3 Running 0 13h
rook-ceph-mgr-b-6b7fcf6bd-kzng5 3/3 Running 0 13h
rook-ceph-mon-a-5cd956c46f-9b4ms 2/2 Running 0 13h
rook-ceph-mon-b-7bd996578f-f626r 2/2 Running 0 13h
rook-ceph-mon-c-67dcbbff4d-p85n5 2/2 Running 0 13h
rook-ceph-operator-644954fb4b-pm9cl 1/1 Running 0 13h
rook-ceph-osd-0-7bddbd7847-cj9lf 2/2 Running 0 13h
rook-ceph-osd-1-d4589dfc8-842s4 2/2 Running 0 13h
rook-ceph-osd-2-59547758c7-vk995 2/2 Running 0 13h
rook-ceph-osd-prepare-cce-k8s-m-1-7bf62 0/1 Completed 0 13h
rook-ceph-osd-prepare-cce-k8s-w-1-p7nn6 0/1 Completed 0 13h
rook-ceph-osd-prepare-cce-k8s-w-2-6k4cm 0/1 Completed 0 13h
rook-ceph-tools-7857bc9568-q2zgv 1/1 Running 0 13h
# 驱动信息
1:包含 rbd 和 cephfs 的驱动,csi-cephfsplugin 和 csi-rbdplugin
2:驱动由 provisioner 和 plugin 组成
6.4:创建存储类
# RBD块存储类
1:RBD 相关的存储驱动和 provisioner 安装 rook 时候已经创建好,因此接下来只需要直接对接即可, Rook 提供了两种对接的方式:
1:FlexVolume
2:CSI
其中 Flex 的方式比较老,默认驱动未安装,需要安装才可以对接,逐步淘汰,不建议使用,推荐使用 CSI 的对接方式
[root@cce-k8s-m-1 rbd]# pwd
/root/rook/deploy/examples/csi/rbd
[root@cce-k8s-m-1 rbd]# cat storageclass.yaml
apiVersion: ceph.rook.io/v1
kind: CephBlockPool
metadata:
name: replicapool
namespace: rook-ceph # namespace:cluster
spec:
failureDomain: host
replicated:
size: 3
# Disallow setting pool with replica 1, this could lead to data loss without recovery.
# Make sure you're *ABSOLUTELY CERTAIN* that is what you want
requireSafeReplicaSize: true
# gives a hint (%) to Ceph in terms of expected consumption of the total cluster capacity of a given pool
# for more info: https://docs.ceph.com/docs/master/rados/operations/placement-groups/#specifying-expected-pool-size
#targetSizeRatio: .5
---
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: rook-ceph-block
# Change "rook-ceph" provisioner prefix to match the operator namespace if needed
provisioner: rook-ceph.rbd.csi.ceph.com
parameters:
# clusterID is the namespace where the rook cluster is running
# If you change this namespace, also change the namespace below where the secret namespaces are defined
clusterID: rook-ceph # namespace:cluster
# If you want to use erasure coded pool with RBD, you need to create
# two pools. one erasure coded and one replicated.
# You need to specify the replicated pool here in the `pool` parameter, it is
# used for the metadata of the images.
# The erasure coded pool must be set as the `dataPool` parameter below.
#dataPool: ec-data-pool
pool: replicapool
# (optional) mapOptions is a comma-separated list of map options.
# For krbd options refer
# https://docs.ceph.com/docs/master/man/8/rbd/#kernel-rbd-krbd-options
# For nbd options refer
# https://docs.ceph.com/docs/master/man/8/rbd-nbd/#options
# mapOptions: lock_on_read,queue_depth=1024
# (optional) unmapOptions is a comma-separated list of unmap options.
# For krbd options refer
# https://docs.ceph.com/docs/master/man/8/rbd/#kernel-rbd-krbd-options
# For nbd options refer
# https://docs.ceph.com/docs/master/man/8/rbd-nbd/#options
# unmapOptions: force
# (optional) Set it to true to encrypt each volume with encryption keys
# from a key management system (KMS)
# encrypted: "true"
# (optional) Use external key management system (KMS) for encryption key by
# specifying a unique ID matching a KMS ConfigMap. The ID is only used for
# correlation to configmap entry.
# encryptionKMSID: <kms-config-id>
# RBD image format. Defaults to "2".
imageFormat: "2"
# RBD image features
# Available for imageFormat: "2". Older releases of CSI RBD
# support only the `layering` feature. The Linux kernel (KRBD) supports the
# full complement of features as of 5.4
# `layering` alone corresponds to Ceph's bitfield value of "2" ;
# `layering` + `fast-diff` + `object-map` + `deep-flatten` + `exclusive-lock` together
# correspond to Ceph's OR'd bitfield value of "63". Here we use
# a symbolic, comma-separated format:
# For 5.4 or later kernels:
#imageFeatures: layering,fast-diff,object-map,deep-flatten,exclusive-lock
# For 5.3 or earlier kernels:
imageFeatures: layering
# The secrets contain Ceph admin credentials. These are generated automatically by the operator
# in the same namespace as the cluster.
csi.storage.k8s.io/provisioner-secret-name: rook-csi-rbd-provisioner
csi.storage.k8s.io/provisioner-secret-namespace: rook-ceph # namespace:cluster
csi.storage.k8s.io/controller-expand-secret-name: rook-csi-rbd-provisioner
csi.storage.k8s.io/controller-expand-secret-namespace: rook-ceph # namespace:cluster
csi.storage.k8s.io/node-stage-secret-name: rook-csi-rbd-node
csi.storage.k8s.io/node-stage-secret-namespace: rook-ceph # namespace:cluster
# Specify the filesystem type of the volume. If not specified, csi-provisioner
# will set default as `ext4`. Note that `xfs` is not recommended due to potential deadlock
# in hyperconverged settings where the volume is mounted on the same node as the osds.
csi.storage.k8s.io/fstype: ext4
# uncomment the following to use rbd-nbd as mounter on supported nodes
# **IMPORTANT**: CephCSI v3.4.0 onwards a volume healer functionality is added to reattach
# the PVC to application pod if nodeplugin pod restart.
# Its still in Alpha support. Therefore, this option is not recommended for production use.
#mounter: rbd-nbd
allowVolumeExpansion: true
reclaimPolicy: Delete
[root@cce-k8s-m-1 rbd]# kubectl apply -f storageclass.yaml
cephblockpool.ceph.rook.io/replicapool created
storageclass.storage.k8s.io/rook-ceph-block created
[root@cce-k8s-m-1 rbd]# ceph status
cluster:
id: 5d33f341-bf25-46bd-8a17-53952cda0eee
health: HEALTH_OK
services:
mon: 3 daemons, quorum a,b,c (age 13h)
mgr: b(active, since 13h), standbys: a
osd: 3 osds: 3 up (since 13h), 3 in (since 13h)
data:
pools: 2 pools, 2 pgs
objects: 3 objects, 577 KiB
usage: 64 MiB used, 150 GiB / 150 GiB avail
pgs: 2 active+clean
[root@cce-k8s-m-1 rbd]# ceph osd lspools
1 .mgr
2 replicapool
[root@cce-k8s-m-1 rbd]# ceph osd pool get replicapool size
size: 3
[root@cce-k8s-m-1 rbd]# kubectl get sc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
rook-ceph-block rook-ceph.rbd.csi.ceph.com Delete Immediate true 118s
# 可以看到这里就创建出来Pool和SC资源了。
6.5:PVC调用存储
创建好 storageclass 之后,我们就可以通过 PVC 向 storageclass 申请容量空间了, PVC 会自动和 storageclass 完成存储容量的创建过程,包括自动创建 PV , PV 与后端存储自动完成 RBD 块存储的创建,整个过程不需要我们关心,均通过 storageclass 和驱动自动完成,我们只需要关注使用即可,如下是一个 wordpress 博客应用连接 MySQL 数据库的一个云原生应用的范例
[root@cce-k8s-m-1 examples]# cat wordpress.yaml mysql.yaml
apiVersion: v1
kind: Service
metadata:
name: wordpress
labels:
app: wordpress
spec:
ports:
- port: 80
selector:
app: wordpress
tier: frontend
type: LoadBalancer
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: wp-pv-claim
labels:
app: wordpress
spec:
storageClassName: rook-ceph-block
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 20Gi
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: wordpress
labels:
app: wordpress
tier: frontend
spec:
selector:
matchLabels:
app: wordpress
tier: frontend
strategy:
type: Recreate
template:
metadata:
labels:
app: wordpress
tier: frontend
spec:
containers:
- image: wordpress:4.6.1-apache
name: wordpress
env:
- name: WORDPRESS_DB_HOST
value: wordpress-mysql
- name: WORDPRESS_DB_PASSWORD
value: changeme
ports:
- containerPort: 80
name: wordpress
volumeMounts:
- name: wordpress-persistent-storage
mountPath: /var/www/html
volumes:
- name: wordpress-persistent-storage
persistentVolumeClaim:
claimName: wp-pv-claim
---
apiVersion: v1
kind: Service
metadata:
name: wordpress-mysql
labels:
app: wordpress
spec:
ports:
- port: 3306
selector:
app: wordpress
tier: mysql
clusterIP: None
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: mysql-pv-claim
labels:
app: wordpress
spec:
storageClassName: rook-ceph-block
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 20Gi
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: wordpress-mysql
labels:
app: wordpress
tier: mysql
spec:
selector:
matchLabels:
app: wordpress
tier: mysql
strategy:
type: Recreate
template:
metadata:
labels:
app: wordpress
tier: mysql
spec:
containers:
- image: mysql:5.6
name: mysql
env:
- name: MYSQL_ROOT_PASSWORD
value: changeme
ports:
- containerPort: 3306
name: mysql
volumeMounts:
- name: mysql-persistent-storage
mountPath: /var/lib/mysql
volumes:
- name: mysql-persistent-storage
persistentVolumeClaim:
claimName: mysql-pv-claim
[root@cce-k8s-m-1 examples]# kubectl apply -f mysql.yaml -f wordpress.yaml
service/wordpress-mysql created
persistentvolumeclaim/mysql-pv-claim created
deployment.apps/wordpress-mysql created
service/wordpress created
persistentvolumeclaim/wp-pv-claim created
deployment.apps/wordpress created
[root@cce-k8s-m-1 examples]# kubectl get pod
NAME READY STATUS RESTARTS AGE
wordpress-7964897bd9-fkzcc 1/1 Running 0 119s
wordpress-mysql-776b4f56c4-29jlt 1/1 Running 0 119s
6.6:PVC调用逻辑
PVC 会完成一系列的出对接过程,包含有什么动作。 PVC —> storageclass 申请容量 —> 创建 PV ——> 向 Ceph 申请 RBD 块,完成和 Ceph 对接
[root@cce-k8s-m-1 examples]# kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
mysql-pv-claim Bound pvc-0c40943e-875f-4893-9ee9-a696d15ecc90 20Gi RWO rook-ceph-block 5m41s
wp-pv-claim Bound pvc-302ef2cf-b236-4915-ab12-dd28d8614262 20Gi RWO rook-ceph-block 5m41s
[root@cce-k8s-m-1 examples]# kubectl get pvc mysql-pv-claim -oyaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
......
finalizers:
- kubernetes.io/pvc-protection
labels:
app: wordpress
name: mysql-pv-claim
namespace: default
resourceVersion: "131911"
uid: 0c40943e-875f-4893-9ee9-a696d15ecc90
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 20Gi
storageClassName: rook-ceph-block
volumeMode: Filesystem
volumeName: pvc-0c40943e-875f-4893-9ee9-a696d15ecc90
status:
accessModes:
- ReadWriteOnce
capacity:
storage: 20Gi
phase: Bound
# PVC 会自动创建 PV
[root@cce-k8s-m-1 examples]# kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
pvc-0c40943e-875f-4893-9ee9-a696d15ecc90 20Gi RWO Delete Bound default/mysql-pv-claim rook-ceph-block 5m28s
pvc-302ef2cf-b236-4915-ab12-dd28d8614262 20Gi RWO Delete Bound default/wp-pv-claim rook-ceph-block 5m28s
[root@cce-k8s-m-1 examples]# kubectl get pv pvc-0c40943e-875f-4893-9ee9-a696d15ecc90 -oyaml
apiVersion: v1
kind: PersistentVolume
metadata:
......
finalizers:
- kubernetes.io/pv-protection
name: pvc-0c40943e-875f-4893-9ee9-a696d15ecc90
resourceVersion: "131908"
uid: 08d5b820-dc3d-4042-a736-e2671bd12e97
spec:
accessModes:
- ReadWriteOnce
capacity:
storage: 20Gi
claimRef:
apiVersion: v1
kind: PersistentVolumeClaim
name: mysql-pv-claim
namespace: default
resourceVersion: "131874"
uid: 0c40943e-875f-4893-9ee9-a696d15ecc90
csi:
controllerExpandSecretRef:
name: rook-csi-rbd-provisioner
namespace: rook-ceph
driver: rook-ceph.rbd.csi.ceph.com
fsType: ext4
nodeStageSecretRef:
name: rook-csi-rbd-node
namespace: rook-ceph
volumeAttributes:
clusterID: rook-ceph
imageFeatures: layering
imageFormat: "2"
imageName: csi-vol-bb18cc8d-d1d8-11ed-9a54-f63b7b5ac9a4
journalPool: replicapool
pool: replicapool
storage.kubernetes.io/csiProvisionerIdentity: 1680447203456-8081-rook-ceph.rbd.csi.ceph.com
volumeHandle: 0001-0009-rook-ceph-0000000000000002-bb18cc8d-d1d8-11ed-9a54-f63b7b5ac9a4
persistentVolumeReclaimPolicy: Delete
storageClassName: rook-ceph-block
volumeMode: Filesystem
status:
phase: Bound
# PV 会完成和 Ceph 的对接,自动创建 RBD 块存储空间,期间由 plugin 驱动完成创建
# RBD信息
[root@cce-k8s-m-1 examples]# rbd -p replicapool ls
csi-vol-bb146437-d1d8-11ed-9a54-f63b7b5ac9a4
csi-vol-bb18cc8d-d1d8-11ed-9a54-f63b7b5ac9a4
# mysql 使用 rbd 块信息
[root@cce-k8s-m-1 examples]# rbd -p replicapool info csi-vol-bb146437-d1d8-11ed-9a54-f63b7b5ac9a4
rbd image 'csi-vol-bb146437-d1d8-11ed-9a54-f63b7b5ac9a4':
size 20 GiB in 5120 objects
order 22 (4 MiB objects)
snapshot_count: 0
id: 131ac1b0c0ad1
block_name_prefix: rbd_data.131ac1b0c0ad1
format: 2
features: layering
op_features:
flags:
create_timestamp: Mon Apr 3 12:33:50 2023
access_timestamp: Mon Apr 3 12:33:50 2023
modify_timestamp: Mon Apr 3 12:33:50 2023
6.7:Wordpress验证
我们需要修改wordoress的svc实现外部访问,这里我们可以直接修改为NodePort或者Ingress
[root@cce-k8s-m-1 examples]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 14h
wordpress NodePort 10.96.2.110 <none> 80:32141/TCP 10m
wordpress-mysql ClusterIP None <none> 3306/TCP 10m
到这里就可以基本确认是没有问题的。
6.8:存储持久化模板
PVC 使用模式适用于单个 pods 容器,如多个 pods 都需要有各自的存储如何实现,需要借助于 StatefulSet 的 volumeClaimTemplates 功能,实现每个 pods 均有各自的存储
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: nginx
namespace: default
spec:
serviceName: "nginx"
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
terminationGracePeriodSeconds: 10
containers:
- name: nginx
image: nginx:latest
ports:
- containerPort: 80
name: web
volumeMounts:
- name: www
mountPath: /usr/share/nginx/html
volumeClaimTemplates:
- metadata:
name: www
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "rook-ceph-block"
resources:
requests:
storage: 10Gi
[root@cce-k8s-m-1 ~]# kubectl get pv,pvc,pod
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
persistentvolume/pvc-28491a54-25b1-4156-9c31-c43720dab0d6 10Gi RWO Delete Bound default/www-nginx-0 rook-ceph-block 3m20s
persistentvolume/pvc-496ca442-3add-4e21-948b-6e8a4154f9e5 10Gi RWO Delete Bound default/www-nginx-1 rook-ceph-block 2m35s
persistentvolume/pvc-d6794286-edb6-4c5a-b471-c930448b4c76 10Gi RWO Delete Bound default/www-nginx-2 rook-ceph-block 111s
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
persistentvolumeclaim/www-nginx-0 Bound pvc-28491a54-25b1-4156-9c31-c43720dab0d6 10Gi RWO rook-ceph-block 3m20s
persistentvolumeclaim/www-nginx-1 Bound pvc-496ca442-3add-4e21-948b-6e8a4154f9e5 10Gi RWO rook-ceph-block 2m35s
persistentvolumeclaim/www-nginx-2 Bound pvc-d6794286-edb6-4c5a-b471-c930448b4c76 10Gi RWO rook-ceph-block 111s
NAME READY STATUS RESTARTS AGE
pod/nginx-0 1/1 Running 0 3m20s
pod/nginx-1 1/1 Running 0 2m35s
pod/nginx-2 1/1 Running 0 111s
# 可以看到,一一对应,而且都有自己的容量。
7:CephFS文件存储
7.1:CephFS文件存储概述
1:RBD的特点:
RBD块存储只能用于单个 VM 或者单个 pods 使用,无法提供给多个虚拟机或者多个 pods ”同时“使用,如果虚拟机或 pods 有共同访问存储的需求需要使用 CephFS 实现。
2:NAS 网络附加存储:多个客户端同时访问
1:EFS
2:NAS
3:CFS
3:CephFS 特点:
1:POSIX-compliant semantics (符合 POSIX 的语法)
2:Separates metadata from data (metadata和data 分离,数据放入data,元数据放入metadata)
3:Dynamic rebalancing (动态从分布,自愈)
4:Subdirectory snapshots (子目录筷子)
5:Configurable striping (可配置切片)
6:Kernel driver support (内核级别挂载)
7:FUSE support (用户空间级别挂载)
8:NFS/CIFS deployable (NFS/CIFS方式共享出去提供使用)
9:Use with Hadoop (replace HDFS) (支持Hadoop 的 HDFS)
7.2:MDS架构

大部分文件存储均通过元数据服务( metadata )查找元数据信息,通过 metadata 访问实际的数据, Ceph 中通过 MDS 来提供 metadata 服务,内置高可用架构,支持部署单Active-Standby方式部署,也支持双主 Active 方式部署,其通过交换日志 Journal 来保障元数据的一致性。
7.3:MDS和FS部署
[root@cce-k8s-m-1 examples]# cat filesystem.yaml
#################################################################################################################
# Create a filesystem with settings with replication enabled for a production environment.
# A minimum of 3 OSDs on different nodes are required in this example.
# If one mds daemon per node is too restrictive, see the podAntiAffinity below.
# kubectl create -f filesystem.yaml
#################################################################################################################
apiVersion: ceph.rook.io/v1
kind: CephFilesystem
metadata:
name: myfs
namespace: rook-ceph # namespace:cluster
spec:
# The metadata pool spec. Must use replication.
metadataPool:
replicated:
size: 3
requireSafeReplicaSize: true
parameters:
# Inline compression mode for the data pool
# Further reference: https://docs.ceph.com/docs/master/rados/configuration/bluestore-config-ref/#inline-compression
compression_mode:
none
# gives a hint (%) to Ceph in terms of expected consumption of the total cluster capacity of a given pool
# for more info: https://docs.ceph.com/docs/master/rados/operations/placement-groups/#specifying-expected-pool-size
#target_size_ratio: ".5"
# The list of data pool specs. Can use replication or erasure coding.
dataPools:
- name: replicated
failureDomain: host
replicated:
size: 3
# Disallow setting pool with replica 1, this could lead to data loss without recovery.
# Make sure you're *ABSOLUTELY CERTAIN* that is what you want
requireSafeReplicaSize: true
parameters:
# Inline compression mode for the data pool
# Further reference: https://docs.ceph.com/docs/master/rados/configuration/bluestore-config-ref/#inline-compression
compression_mode:
none
# gives a hint (%) to Ceph in terms of expected consumption of the total cluster capacity of a given pool
# for more info: https://docs.ceph.com/docs/master/rados/operations/placement-groups/#specifying-expected-pool-size
#target_size_ratio: ".5"
# Whether to preserve filesystem after CephFilesystem CRD deletion
preserveFilesystemOnDelete: true
# The metadata service (mds) configuration
metadataServer:
# The number of active MDS instances
activeCount: 1
# Whether each active MDS instance will have an active standby with a warm metadata cache for faster failover.
# If false, standbys will be available, but will not have a warm cache.
activeStandby: true
# The affinity rules to apply to the mds deployment
placement:
# nodeAffinity:
# requiredDuringSchedulingIgnoredDuringExecution:
# nodeSelectorTerms:
# - matchExpressions:
# - key: role
# operator: In
# values:
# - mds-node
# topologySpreadConstraints:
# tolerations:
# - key: mds-node
# operator: Exists
# podAffinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- rook-ceph-mds
## Add this if you want to allow mds daemons for different filesystems to run on one
## node. The value in "values" must match .metadata.name.
# - key: rook_file_system
# operator: In
# values:
# - myfs
# topologyKey: kubernetes.io/hostname will place MDS across different hosts
topologyKey: kubernetes.io/hostname
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: app
operator: In
values:
- rook-ceph-mds
# topologyKey: */zone can be used to spread MDS across different AZ
# Use <topologyKey: failure-domain.beta.kubernetes.io/zone> in k8s cluster if your cluster is v1.16 or lower
# Use <topologyKey: topology.kubernetes.io/zone> in k8s cluster is v1.17 or upper
topologyKey: topology.kubernetes.io/zone
# A key/value list of annotations
# annotations:
# key: value
# A key/value list of labels
# labels:
# key: value
# resources:
# The requests and limits set here, allow the filesystem MDS Pod(s) to use half of one CPU core and 1 gigabyte of memory
# limits:
# cpu: "500m"
# memory: "1024Mi"
# requests:
# cpu: "500m"
# memory: "1024Mi"
priorityClassName: system-cluster-critical
livenessProbe:
disabled: false
startupProbe:
disabled: false
# Filesystem mirroring settings
# mirroring:
# enabled: true
# list of Kubernetes Secrets containing the peer token
# for more details see: https://docs.ceph.com/en/latest/dev/cephfs-mirroring/#bootstrap-peers
# Add the secret name if it already exists else specify the empty list here.
# peers:
#secretNames:
#- secondary-cluster-peer
# specify the schedule(s) on which snapshots should be taken
# see the official syntax here https://docs.ceph.com/en/latest/cephfs/snap-schedule/#add-and-remove-schedules
# snapshotSchedules:
# - path: /
# interval: 24h # daily snapshots
# The startTime should be mentioned in the format YYYY-MM-DDTHH:MM:SS
# If startTime is not specified, then by default the start time is considered as midnight UTC.
# see usage here https://docs.ceph.com/en/latest/cephfs/snap-schedule/#usage
# startTime: 2022-07-15T11:55:00
# manage retention policies
# see syntax duration here https://docs.ceph.com/en/latest/cephfs/snap-schedule/#add-and-remove-retention-policies
# snapshotRetention:
# - path: /
# duration: "h 24"
# 设置label
[root@cce-k8s-m-1 examples]# kubectl label nodes cce-k8s-m-1 app=rook-ceph-mds
node/cce-k8s-m-1 labeled
[root@cce-k8s-m-1 examples]# kubectl label nodes cce-k8s-w-1 app=rook-ceph-mds
node/cce-k8s-w-1 labeled
[root@cce-k8s-m-1 examples]# kubectl label nodes cce-k8s-w-2 app=rook-ceph-mds
node/cce-k8s-w-2 labeled
[root@cce-k8s-m-1 examples]# kubectl apply -f filesystem.yaml
cephfilesystem.ceph.rook.io/myfs created
[root@cce-k8s-m-1 examples]# kubectl -n rook-ceph get pods -l app=rook-ceph-mds
NAME READY STATUS RESTARTS AGE
rook-ceph-mds-myfs-a-6d98c9c4d8-hh95q 2/2 Running 0 6m49s
rook-ceph-mds-myfs-b-db75d54bf-4vbvl 2/2 Running 0 6m48s
[root@cce-k8s-m-1 examples]# ceph -s
cluster:
id: 5d33f341-bf25-46bd-8a17-53952cda0eee
health: HEALTH_OK
services:
mon: 3 daemons, quorum a,b,c (age 15h)
mgr: b(active, since 15h), standbys: a
mds: 1/1 daemons up, 1 hot standby
osd: 3 osds: 3 up (since 15h), 3 in (since 15h)
data:
volumes: 1/1 healthy
pools: 4 pools, 81 pgs
objects: 29 objects, 579 KiB
usage: 306 MiB used, 150 GiB / 150 GiB avail
pgs: 81 active+clean
io:
client: 1.2 KiB/s rd, 2 op/s rd, 0 op/s wr
# pool信息
[root@cce-k8s-m-1 examples]# ceph osd lspools
1 .mgr
2 replicapool
3 myfs-metadata # 元数据
4 myfs-replicated # 数据
[root@cce-k8s-m-1 examples]# ceph fs ls
name: myfs, metadata pool: myfs-metadata, data pools: [myfs-replicated ]
7.4:MDS高可用
MDS 支持双主的方式部署,即单个文件系统有多组 metadata 服务器,每组均有主备active-standby 的方式部署,修改`activeCount`,表示双主配置
[root@cce-k8s-m-1 examples]# kubectl apply -f filesystem.yaml
cephfilesystem.ceph.rook.io/myfs configured
[root@cce-k8s-m-1 examples]# kubectl get pod -n rook-ceph -l app=rook-ceph-mds
NAME READY STATUS RESTARTS AGE
rook-ceph-mds-myfs-a-657b6ccb9b-pbdhx 2/2 Running 0 2m57s
rook-ceph-mds-myfs-b-5d7bd967df-lpw5b 2/2 Running 0 119s
rook-ceph-mds-myfs-c-76fb898c78-gsxg2 2/2 Running 0 86s
rook-ceph-mds-myfs-d-849f46b5cf-v8khj 2/2 Running 0 55s
[root@cce-k8s-m-1 examples]# ceph status
cluster:
id: 5d33f341-bf25-46bd-8a17-53952cda0eee
health: HEALTH_OK
services:
mon: 3 daemons, quorum a,b,c (age 15h)
mgr: b(active, since 15h), standbys: a
mds: 2/2 daemons up, 2 hot standby
osd: 3 osds: 3 up (since 15h), 3 in (since 15h)
data:
volumes: 1/1 healthy
pools: 4 pools, 81 pgs
objects: 48 objects, 581 KiB
usage: 307 MiB used, 150 GiB / 150 GiB avail
pgs: 81 active+clean
io:
client: 1.7 KiB/s rd, 3 op/s rd, 0 op/s wr
# 这中间有标签规则的问题,而我把亲和性那一块给注释了然后就可以了,有兴趣的可以去研究一下。
7.5:MDS高级调度
s 通过 placement 提供了调度机制,支持节点调度, pods 亲和力调度, pods 反亲和调度,节点容忍和拓扑调度等,先看下节点的调度,通过 ceph-mds=enabled 标签选择具备满足条件的 node 节点
[root@cce-k8s-m-1 examples]# kubectl get pod -n rook-ceph -l app=rook-ceph-mds -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
rook-ceph-mds-myfs-a-657b6ccb9b-pbd... 2/2 Running 0 66m 100.101.104.157 cce-k8s-w-2 <none> <none>
rook-ceph-mds-myfs-b-5d7bd967df-lpw5b 2/2 Running 0 66m 100.101.104.158 cce-k8s-w-2 <none> <none>
rook-ceph-mds-myfs-c-76fb898c78-gsxg2 2/2 Running 0 65m 100.101.104.159 cce-k8s-w-2 <none> <none>
rook-ceph-mds-myfs-d-849f46b5cf-v8khj 2/2 Running 0 64m 100.118.108.219 cce-k8s-w-1 <none> <none>
...
metadataServer:
# The number of active MDS instances
activeCount: 2
# Whether each active MDS instance will have an active standby with a warm metadata cache for faster failover.
# If false, standbys will be available, but will not have a warm cache.
activeStandby: true
# The affinity rules to apply to the mds deployment
placement:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: ceph-mds
operator: In
values:
- enabled
...
[root@cce-k8s-m-1 examples]# kubectl label nodes cce-k8s-m-1 ceph-mds=enabled
node/cce-k8s-m-1 labeled
[root@cce-k8s-m-1 examples]# kubectl label nodes cce-k8s-w-1 ceph-mds=enabled
node/cce-k8s-w-1 labeled
[root@cce-k8s-m-1 examples]# kubectl label nodes cce-k8s-w-2 ceph-mds=enabled
node/cce-k8s-w-2 labeled
[root@cce-k8s-m-1 examples]# kubectl get pod -n rook-ceph -l app=rook-ceph-mds -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
rook-ceph-mds-myfs-a-86f58... 2/2 Running 0 2m12s 100.118.108.222 cce-k8s-w-1 <none> <none>
rook-ceph-mds-myfs-b-6c4b4... 2/2 Running 0 103s 100.101.104.160 cce-k8s-w-2 <none> <none>
rook-ceph-mds-myfs-c-69477... 2/2 Running 0 69s 100.101.104.161 cce-k8s-w-2 <none> <none>
rook-ceph-mds-myfs-d-75f79... 2/2 Running 0 38s 100.101.104.162 cce-k8s-w-2 <none> <none>
# 可以看到,这里的确是分布了,但是并没有完全分布到所有的节点上去,这个其实也是因为node的亲和性粒度也不是特别细致,所以只能说有概率调度到打了标签的所有节点上去,也是一种冗余机制,但是有一种情况就非常的操蛋了,比如恰巧你的两个主全部调度到了一个节点上,那么你的高可用也就不生效了,所以我们不仅要有亲和性,还要有反亲和的支持
...
placement:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: ceph-mds
operator: In
values:
- enabled
# topologySpreadConstraints:
# tolerations:
# - key: mds-node
# operator: Exists
# podAffinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- rook-ceph-mds
topologyKey: kubernetes.io/hostname
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: app
operator: In
values:
- rook-ceph-mds
topologyKey: topology.kubernetes.io/zone
...
[root@cce-k8s-m-1 examples]# kubectl get pod -n rook-ceph -l app=rook-ceph-mds -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
rook-ceph-mds-myfs-a-556bf87cc7-wq427 1/2 Running 0 11s 100.118.108.223 cce-k8s-w-1 <none> <none>
rook-ceph-mds-myfs-b-6c4b4b79c6-gf5vv 2/2 Running 0 20m 100.101.104.160 cce-k8s-w-2 <none> <none>
rook-ceph-mds-myfs-c-6947798bdc-xsc9v 2/2 Running 0 20m 100.101.104.161 cce-k8s-w-2 <none> <none>
rook-ceph-mds-myfs-d-75f7974874-4lc2r 2/2 Running 0 19m 100.101.104.162 cce-k8s-w-2 <none> <none>
# 我这里开反亲和会有问题因为需要4个节点去承载Pod,但是我只有三个,所以会有一个节点处于Pending,大家做的时候只要节点够,标签符合就行了,我这里就不做这个反亲和了。
7.6:部署CephFS存储类
Rook 默认将 CephFS 相关的存储驱动已安装好,只需要通过 storageclass 消费即可
[root@cce-k8s-m-1 cephfs]# cat storageclass.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: rook-cephfs
# Change "rook-ceph" provisioner prefix to match the operator namespace if needed
provisioner: rook-ceph.cephfs.csi.ceph.com # driver:namespace:operator
parameters:
# clusterID is the namespace where the rook cluster is running
# If you change this namespace, also change the namespace below where the secret namespaces are defined
clusterID: rook-ceph # namespace:cluster
# CephFS filesystem name into which the volume shall be created
fsName: myfs
# Ceph pool into which the volume shall be created
# Required for provisionVolume: "true"
pool: myfs-replicated
# The secrets contain Ceph admin credentials. These are generated automatically by the operator
# in the same namespace as the cluster.
csi.storage.k8s.io/provisioner-secret-name: rook-csi-cephfs-provisioner
csi.storage.k8s.io/provisioner-secret-namespace: rook-ceph # namespace:cluster
csi.storage.k8s.io/controller-expand-secret-name: rook-csi-cephfs-provisioner
csi.storage.k8s.io/controller-expand-secret-namespace: rook-ceph # namespace:cluster
csi.storage.k8s.io/node-stage-secret-name: rook-csi-cephfs-node
csi.storage.k8s.io/node-stage-secret-namespace: rook-ceph # namespace:cluster
# (optional) The driver can use either ceph-fuse (fuse) or ceph kernel client (kernel)
# If omitted, default volume mounter will be used - this is determined by probing for ceph-fuse
# or by setting the default mounter explicitly via --volumemounter command-line argument.
# mounter: kernel
reclaimPolicy: Delete
allowVolumeExpansion: true
mountOptions:
# uncomment the following line for debugging
#- debug
[root@cce-k8s-m-1 cephfs]# kubectl apply -f storageclass.yaml
storageclass.storage.k8s.io/rook-cephfs created
[root@cce-k8s-m-1 cephfs]# kubectl get sc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
rook-ceph-block rook-ceph.rbd.csi.ceph.com Delete Immediate true 7h12m
rook-cephfs rook-ceph.cephfs.csi.ceph.com Delete Immediate true 2s
7.7:容器调用CephFS
[root@cce-k8s-m-1 cephfs]# cat kube-registry.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: cephfs-pvc
namespace: kube-system
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 1Gi
# 对应上面的sc
storageClassName: rook-cephfs
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: kube-registry
namespace: kube-system
labels:
k8s-app: kube-registry
kubernetes.io/cluster-service: "true"
spec:
replicas: 3
selector:
matchLabels:
k8s-app: kube-registry
template:
metadata:
labels:
k8s-app: kube-registry
kubernetes.io/cluster-service: "true"
spec:
containers:
- name: registry
image: registry:2
imagePullPolicy: Always
resources:
limits:
cpu: 100m
memory: 100Mi
env:
- name: REGISTRY_HTTP_ADDR
value: :5000
- name: REGISTRY_HTTP_SECRET
value: "Ple4seCh4ngeThisN0tAVerySecretV4lue"
- name: REGISTRY_STORAGE_FILESYSTEM_ROOTDIRECTORY
value: /var/lib/registry
volumeMounts:
- name: image-store
mountPath: /var/lib/registry
ports:
- containerPort: 5000
name: registry
protocol: TCP
livenessProbe:
httpGet:
path: /
port: registry
readinessProbe:
httpGet:
path: /
port: registry
volumes:
- name: image-store
persistentVolumeClaim:
claimName: cephfs-pvc
readOnly: false
[root@cce-k8s-m-1 cephfs]# kubectl get pod,pv,pvc -n kube-system
NAME READY STATUS RESTARTS AGE
pod/coredns-6d4b75cb6d-4frh4 1/1 Running 0 21h
pod/coredns-6d4b75cb6d-9tmpr 1/1 Running 0 21h
pod/etcd-cce-k8s-m-1 1/1 Running 0 21h
pod/kube-apiserver-cce-k8s-m-1 1/1 Running 0 21h
pod/kube-controller-manager-cce-k8s-m-1 1/1 Running 0 21h
pod/kube-proxy-96l5q 1/1 Running 0 21h
pod/kube-proxy-mxpjw 1/1 Running 0 21h
pod/kube-proxy-r4l7k 1/1 Running 0 21h
pod/kube-registry-74d7b9999c-dptn2 1/1 Running 0 37s
pod/kube-registry-74d7b9999c-thcwl 1/1 Running 0 37s
pod/kube-registry-74d7b9999c-vp9l8 1/1 Running 0 37s
pod/kube-scheduler-cce-k8s-m-1 1/1 Running 0 21h
pod/kube-sealos-lvscare-cce-k8s-w-1 1/1 Running 0 21h
pod/kube-sealos-lvscare-cce-k8s-w-2 1/1 Running 0 21h
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
persistentvolume/pvc-... 1Gi RWX Delete Bound kube-system/cephfs-pvc rook-cephfs 37s
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
persistentvolumeclaim/cephfs-pvc Bound pvc-3118d092-914e-4728-bc04-f816f571fc46 1Gi RWX rook-cephfs 37s
# 测试数据共享
[root@cce-k8s-m-1 cephfs]# kubectl exec -it -n kube-system kube-registry-74d7b9999c-dptn2 /bin/sh
kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl exec [POD] -- [COMMAND] instead.
/ # cd /var/lib/registry/
/var/lib/registry # echo "This is CephFS" > index.html
/var/lib/registry # cat index.html
This is CephFS
/var/lib/registry # ls -lh
total 1K
-rw-r--r-- 1 root root 15 Apr 3 11:39 index.html
[root@cce-k8s-m-1 cephfs]# kubectl exec -it -n kube-system kube-registry-74d7b9999c-thcwl -- /bin/cat /var/lib/registry/index.html
This is CephFS
[root@cce-k8s-m-1 cephfs]# kubectl exec -it -n kube-system kube-registry-74d7b9999c-vp9l8 -- /bin/cat /var/lib/registry/index.html
This is CephFS
# 镜像仓库我就不测试了,这个只需要把Pod暴露出去就可以使用了。
7.8:外部访问CephFS
# 我们需要访问CephFS的时候需要一些数据,也就是Ceph的验证信息
[root@cce-k8s-m-1 cephfs]# cat /etc/ceph/ceph.conf
[global]
mon_host = 10.96.2.87:6789,10.96.0.229:6789,10.96.1.11:6789
[client.admin]
keyring = /etc/ceph/keyring
[root@cce-k8s-m-1 cephfs]# cat /etc/ceph/keyring
[client.admin]
key = AQBLlSlkTTxiCRAAfjLe95fOv8iYcFduO0BLXg==
# 我们在本地挂在一下CephFS看看效果
[root@cce-k8s-m-1 cephfs]# mkdir /data
[root@cce-k8s-m-1 cephfs]# mount -t ceph -o name=admin,secret=AQBLlSlkTTxiCRAAfjLe95fOv8iYcFduO0BLXg==,mds_namespace=myfs 10.96.2.87:6789,10.96.0.229:6789,10.96.1.11:6789:/ /data
[root@cce-k8s-m-1 cephfs]# df -Th
......
10.96.2.87:6789,10.96.0.229:6789,10.96.1.11:6789:/ 49696768 0 49696768 0% /data
[root@cce-k8s-m-1 cephfs]# cd /data/
[root@cce-k8s-m-1 data]# ls
volumes
[root@cce-k8s-m-1 data]# cd volumes/
[root@cce-k8s-m-1 volumes]# ls
csi _csi:csi-vol-a47a2b0b-d213-11ed-b070-161e0144d679.meta
[root@cce-k8s-m-1 volumes]# cd csi/
[root@cce-k8s-m-1 csi]# ls
csi-vol-a47a2b0b-d213-11ed-b070-161e0144d679
[root@cce-k8s-m-1 csi]# cd csi-vol-a47a2b0b-d213-11ed-b070-161e0144d679/
[root@cce-k8s-m-1 csi-vol-a47a2b0b-d213-11ed-b070-161e0144d679]# ls
28c47060-8dcf-40c9-8def-0251b325a206
[root@cce-k8s-m-1 csi-vol-a47a2b0b-d213-11ed-b070-161e0144d679]# cd 28c47060-8dcf-40c9-8def-0251b325a206/
[root@cce-k8s-m-1 28c47060-8dcf-40c9-8def-0251b325a206]# ls
index.html
[root@cce-k8s-m-1 28c47060-8dcf-40c9-8def-0251b325a206]# pwd
/data/volumes/csi/csi-vol-a47a2b0b-d213-11ed-b070-161e0144d679/28c47060-8dcf-40c9-8def-0251b325a206
[root@cce-k8s-m-1 28c47060-8dcf-40c9-8def-0251b325a206]# cat index.html
This is CephFS
# 这是我们kube-registry的数据
7.9:CephFS集群维护
1:pods状态
2:ceph状态
3:fs状态
4:日志查看
1:驱动日志
2:服务日志
# pods状态查看,mds以pods的形式运行,需要确保pods运行正常
[root@cce-k8s-m-1 ~]# kubectl -n rook-ceph get pods -l app=rook-ceph-mds
NAME READY STATUS RESTARTS AGE
rook-ceph-mds-myfs-a-86f58d679c-2pdk8 2/2 Running 0 67m
rook-ceph-mds-myfs-b-6c4b4b79c6-s72c2 2/2 Running 0 66m
rook-ceph-mds-myfs-c-6947798bdc-2zbg8 2/2 Running 0 66m
rook-ceph-mds-myfs-d-75f7974874-4lc2r 2/2 Running 0 92m
# Ceph状态查看
[root@cce-k8s-m-1 ~]# ceph -s
cluster:
id: 5d33f341-bf25-46bd-8a17-53952cda0eee
health: HEALTH_OK
services:
mon: 3 daemons, quorum a,b,c (age 21h)
mgr: b(active, since 21h), standbys: a
mds: 2/2 daemons up, 2 hot standby
osd: 3 osds: 3 up (since 21h), 3 in (since 21h)
data:
volumes: 1/1 healthy
pools: 4 pools, 81 pgs
objects: 52 objects, 643 KiB
usage: 311 MiB used, 150 GiB / 150 GiB avail
pgs: 81 active+clean
io:
client: 2.5 KiB/s rd, 4 op/s rd, 0 op/s wr
# 查看CephFS文件系统
[root@cce-k8s-m-1 ~]# ceph fs ls
name: myfs, metadata pool: myfs-metadata, data pools: [myfs-replicated ]
# 容器日志查看,包含 mds 的日志和对接驱动的日志,当服务异常的时候可以结合日志信息进行排查, provisioner 包含有多个不同的容器
1:csi-attacher 挂载
2:csi-snapshotter 快照
3:csi-resizer 调整大小
4:csi-provisioner 创建
5:csi-cephfsplugin 驱动agent
# 驱动日志查看
[root@cce-k8s-m-1 ~]# kubectl logs -f -n rook-ceph csi-cephfsplugin-provisioner-7c594f8cf-s7s9n
Defaulted container "csi-attacher" out of: csi-attacher, csi-snapshotter, csi-resizer, csi-provisioner, csi-cephfsplugin
I0402 14:52:10.339745 1 main.go:94] Version: v4.1.0
W0402 14:52:20.340846 1 connection.go:173] Still connecting to unix:///csi/csi-provisioner.sock
W0402 14:52:30.341189 1 connection.go:173] Still connecting to unix:///csi/csi-provisioner.sock
W0402 14:52:40.343364 1 connection.go:173] Still connecting to unix:///csi/csi-provisioner.sock
W0402 14:52:50.341415 1 connection.go:173] Still connecting to unix:///csi/csi-provisioner.sock
W0402 14:53:00.340881 1 connection.go:173] Still connecting to unix:///csi/csi-provisioner.sock
W0402 14:53:10.341314 1 connection.go:173] Still connecting to unix:///csi/csi-provisioner.sock
W0402 14:53:20.341893 1 connection.go:173] Still connecting to unix:///csi/csi-provisioner.sock
W0402 14:53:30.341447 1 connection.go:173] Still connecting to unix:///csi/csi-provisioner.sock
W0402 14:53:40.342075 1 connection.go:173] Still connecting to unix:///csi/csi-provisioner.sock
W0402 14:53:50.341314 1 connection.go:173] Still connecting to unix:///csi/csi-provisioner.sock
W0402 14:54:00.340977 1 connection.go:173] Still connecting to unix:///csi/csi-provisioner.sock
W0402 14:54:10.341170 1 connection.go:173] Still connecting to unix:///csi/csi-provisioner.sock
W0402 14:54:20.341209 1 connection.go:173] Still connecting to unix:///csi/csi-provisioner.sock
I0402 14:54:24.255787 1 common.go:111] Probing CSI driver for readiness
I0402 14:54:24.288670 1 leaderelection.go:248] attempting to acquire leader lease rook-ceph/external-attacher-leader-rook-ceph-cephfs-csi-ceph-com...
# mds 容器日志查看
[root@cce-k8s-m-1 ~]# kubectl logs -f -n rook-ceph rook-ceph-mds-myfs-a-86f58d679c-2pdk8
8:RGW对象存储
8.1:对象存储概述
对象存储通常是指用于上传 put 和下载 get 之用的存储系统,通常用于存储静态文件,如图片、视频、音频等,对象存储一旦上传之后无法再线进行修改,如需修改则需要将其下载到本地,对象存储最早由 aws 的 S3 提供, Ceph 的对象存储提供两种接口支持:
1:S3 ⻛格接口
2:Swift ⻛格接口
# Ceph 对象存储具有以下特点
1:RESTful Interface (RESTFul api实现对象的管理上传、下载)
2:S3- and Swift-compliant APIs(提供2种风格 api,s3 和 Swift-compliant)
3:S3-style subdomains (S3风格的子域)
4:Unified S3/Swift namespace (S3/Swift扁平空间)
5:User management (安全行:用户认证)
6:Usage tracking (使用率追踪)
7:Striped objects (分片上传,在重组)
8:Cloud solution integration (和云平台集成)
9:Multi-site deployment (多站点部署)
10:Multi-site replication (多站点复制)
8.2:部署RGW集群
通过 rook 部署 RGW 对象存储集群非常便捷,默认已经提供了 yaml 文件,会创建对象存储所需的 pool 和 rgw 集群实例
[root@cce-k8s-m-1 examples]# kubectl apply -f object.yaml
cephobjectstore.ceph.rook.io/my-store created
# 此时 rgw 已经部署完毕,默认部署了 1 个 rgw 实例,通过 ceph -s 可以查看到 rgw 已经部署到Ceph集群中
[root@cce-k8s-m-1 examples]# ceph -s
cluster:
id: 5d33f341-bf25-46bd-8a17-53952cda0eee
health: HEALTH_OK
services:
mon: 3 daemons, quorum a,b,c (age 12m)
mgr: b(active, since 22h), standbys: a
mds: 2/2 daemons up, 2 hot standby
osd: 3 osds: 3 up (since 22h), 3 in (since 22h)
rgw: 1 daemon active (1 hosts, 1 zones)
data:
volumes: 1/1 healthy
pools: 12 pools, 191 pgs
objects: 259 objects, 719 KiB
usage: 302 MiB used, 150 GiB / 150 GiB avail
pgs: 191 active+clean
io:
client: 2.2 KiB/s rd, 255 B/s wr, 4 op/s rd, 0 op/s wr
progress:
# RGW 默认会创建若干个 pool 来存储对象存储的数据, pool 包含 metadata pool 和 data
[root@cce-k8s-m-1 examples]# ceph osd lspools
1 .mgr
2 replicapool
3 myfs-metadata
4 myfs-replicated
5 .rgw.root
6 my-store.rgw.buckets.non-ec
7 my-store.rgw.otp
8 my-store.rgw.meta
9 my-store.rgw.buckets.index
10 my-store.rgw.control
11 my-store.rgw.log
12 my-store.rgw.buckets.data
8.3:RGW高可用集群
RGW 是一个无状态化的 http 服务器,通过 80 端口处理 http 的 put/get 请求,生产环境中需要部署多个 RGW 以满足高可用的要求,在 《Ceph入⻔到实战课程中》 我们通过 haproxy+keepalived 的方式来构建 RGW 的高可用集群
1:Ceph 集群中部署多个 RGW 实例
2:HAproxy 提供负载均衡能力
3:keepalived 提供 VIP 和保障 haproxy 的高可用性
通过 rook 构建 RGW 集群默认部署了一个 RGW 实例,无法实现高可用性的要求,需要部署多个 instances 以满足高可用的诉求。、
我们只需要调整object.yaml内的instance的个数就可以实现了。
[root@cce-k8s-m-1 examples]# kubectl get pod -n rook-ceph
NAME READY STATUS RESTARTS AGE
csi-cephfsplugin-j9vq7 2/2 Running 0 22h
csi-cephfsplugin-nrp7f 2/2 Running 0 22h
csi-cephfsplugin-pl5vt 2/2 Running 0 22h
csi-cephfsplugin-provisioner-7c594f8cf-s7s9n 5/5 Running 0 22h
csi-cephfsplugin-provisioner-7c594f8cf-w6h47 5/5 Running 0 22h
csi-rbdplugin-2cwbl 2/2 Running 0 22h
csi-rbdplugin-4wpd5 2/2 Running 0 22h
csi-rbdplugin-dknj9 2/2 Running 0 22h
csi-rbdplugin-provisioner-99dd6c4c6-9vhnt 5/5 Running 0 22h
csi-rbdplugin-provisioner-99dd6c4c6-zqcwt 5/5 Running 0 22h
rook-ceph-crashcollector-cce-k8s-m-1-7499dbfff4-52zh2 1/1 Running 0 124m
rook-ceph-crashcollector-cce-k8s-w-1-67b77df854-kcm6x 1/1 Running 0 45m
rook-ceph-crashcollector-cce-k8s-w-2-6fdb7f546c-s9cr2 1/1 Running 0 45m
rook-ceph-mds-myfs-a-86f58d679c-qj8jc 2/2 Running 0 45m
rook-ceph-mds-myfs-b-6c4b4b79c6-nlh5j 2/2 Running 0 45m
rook-ceph-mds-myfs-c-6947798bdc-fmhdx 2/2 Running 0 45m
rook-ceph-mds-myfs-d-75f7974874-n6rzs 2/2 Running 0 45m
rook-ceph-mgr-a-c9b6d5b69-jfd4s 3/3 Running 0 22h
rook-ceph-mgr-b-6b7fcf6bd-kzng5 3/3 Running 0 22h
rook-ceph-mon-a-5cd956c46f-9b4ms 2/2 Running 0 22h
rook-ceph-mon-b-7bd996578f-f626r 2/2 Running 0 22h
rook-ceph-mon-c-67dcbbff4d-p85n5 2/2 Running 0 22h
rook-ceph-operator-644954fb4b-pm9cl 1/1 Running 0 23h
rook-ceph-osd-0-7bddbd7847-cj9lf 2/2 Running 0 22h
rook-ceph-osd-1-d4589dfc8-842s4 2/2 Running 0 22h
rook-ceph-osd-2-59547758c7-vk995 2/2 Running 0 22h
rook-ceph-osd-prepare-cce-k8s-m-1-stsgr 0/1 Completed 0 77m
rook-ceph-osd-prepare-cce-k8s-w-1-pkx9l 0/1 Completed 0 77m
rook-ceph-osd-prepare-cce-k8s-w-2-tpwn8 0/1 Completed 0 77m
rook-ceph-rgw-my-store-a-765f5dc457-5svb9 2/2 Running 0 30m
rook-ceph-rgw-my-store-a-765f5dc457-zdmpk 2/2 Running 0 34s
rook-ceph-tools-7857bc9568-q2zgv 1/1 Running 0 22h
# 也因为有反亲和性的关系,所以两个Pod也不会调度到一个节点上去,这样就可以保证我们的RGW多副本高可用的状态。
[root@cce-k8s-m-1 examples]# ceph -s
cluster:
id: 5d33f341-bf25-46bd-8a17-53952cda0eee
health: HEALTH_OK
services:
mon: 3 daemons, quorum a,b,c (age 46m)
mgr: b(active, since 22h), standbys: a
mds: 2/2 daemons up, 2 hot standby
osd: 3 osds: 3 up (since 22h), 3 in (since 22h)
rgw: 2 daemons active (2 hosts, 1 zones)
data:
volumes: 1/1 healthy
pools: 12 pools, 169 pgs
objects: 403 objects, 740 KiB
usage: 335 MiB used, 150 GiB / 150 GiB avail
pgs: 169 active+clean
io:
client: 1.7 KiB/s rd, 3 op/s rd, 0 op/s wr
# 对外提供服务通过 service 的 VIP 实现, VIP 通过 80 端口映射到后端的两个 pods 上
[root@cce-k8s-m-1 examples]# kubectl describe svc -n rook-ceph rook-ceph-rgw-my-store
Name: rook-ceph-rgw-my-store
Namespace: rook-ceph
Labels: app=rook-ceph-rgw
app.kubernetes.io/component=cephobjectstores.ceph.rook.io
app.kubernetes.io/created-by=rook-ceph-operator
app.kubernetes.io/instance=my-store
app.kubernetes.io/managed-by=rook-ceph-operator
app.kubernetes.io/name=ceph-rgw
app.kubernetes.io/part-of=my-store
ceph_daemon_id=my-store
ceph_daemon_type=rgw
rgw=my-store
rook.io/operator-namespace=rook-ceph
rook_cluster=rook-ceph
rook_object_store=my-store
Annotations: <none>
Selector: app=rook-ceph-rgw,ceph_daemon_id=my-store,rgw=my-store,rook_cluster=rook-ceph,rook_object_store=my-store
Type: ClusterIP
IP Family Policy: SingleStack
IP Families: IPv4
IP: 10.96.1.56
IPs: 10.96.1.56
Port: http 80/TCP
TargetPort: 8080/TCP
# 对应两个RGW的地址
Endpoints: 100.101.104.176:8080,100.118.108.235:8080
Session Affinity: None
Events: <none>
8.4:RGW高级调度
和前面 mon , mds 一样, rgw 支持高级的调度机制,通过 nodeAffinity , podAntiAffinity , podAffinity , tolerations 高级调度算法将 RGW 调度到特定的节点上的诉求。
...
placement:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: ceph-rgw
operator: In
values:
- enabled
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: app
operator: In
values:
- rook-ceph-rgw
topologyKey: kubernetes.io/hostname
...
[root@cce-k8s-m-1 examples]# kubectl label nodes cce-k8s-m-1 ceph-rgw=enabled
node/cce-k8s-m-1 labeled
[root@cce-k8s-m-1 examples]# kubectl label nodes cce-k8s-w-1 ceph-rgw=enabled
node/cce-k8s-w-1 labeled
[root@cce-k8s-m-1 examples]# kubectl label nodes cce-k8s-w-2 ceph-rgw=enabled
node/cce-k8s-w-2 labeled
[root@cce-k8s-m-1 examples]# kubectl get pod -n rook-ceph -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
csi-cephfsplugin-j9vq7 2/2 Running 0 22h 10.0.0.11 cce-k8s-m-1 <none> <none>
csi-cephfsplugin-nrp7f 2/2 Running 0 22h 10.0.0.13 cce-k8s-w-2 <none> <none>
csi-cephfsplugin-pl5vt 2/2 Running 0 22h 10.0.0.12 cce-k8s-w-1 <none> <none>
csi-cephfsplugin-provisioner-7c594f8cf-s7s9n 5/5 Running 0 22h 100.118.108.198 cce-k8s-w-1 <none> <none>
csi-cephfsplugin-provisioner-7c594f8cf-w6h47 5/5 Running 0 22h 100.101.104.136 cce-k8s-w-2 <none> <none>
csi-rbdplugin-2cwbl 2/2 Running 0 22h 10.0.0.13 cce-k8s-w-2 <none> <none>
csi-rbdplugin-4wpd5 2/2 Running 0 22h 10.0.0.12 cce-k8s-w-1 <none> <none>
csi-rbdplugin-dknj9 2/2 Running 0 22h 10.0.0.11 cce-k8s-m-1 <none> <none>
csi-rbdplugin-provisioner-99dd6c4c6-9vhnt 5/5 Running 0 22h 100.118.108.197 cce-k8s-w-1 <none> <none>
csi-rbdplugin-provisioner-99dd6c4c6-zqcwt 5/5 Running 0 22h 100.101.104.135 cce-k8s-w-2 <none> <none>
rook-ceph-crashcollector-cce-k8s-m-1-6675c67d88-54xl6 1/1 Running 0 40s 100.110.251.25 cce-k8s-m-1 <none> <none>
rook-ceph-crashcollector-cce-k8s-w-1-67b77df854-kcm6x 1/1 Running 0 55m 100.118.108.232 cce-k8s-w-1 <none> <none>
rook-ceph-crashcollector-cce-k8s-w-2-6fdb7f546c-s9cr2 1/1 Running 0 55m 100.101.104.173 cce-k8s-w-2 <none> <none>
rook-ceph-mds-myfs-a-86f58d679c-qj8jc 2/2 Running 0 55m 100.101.104.172 cce-k8s-w-2 <none> <none>
rook-ceph-mds-myfs-b-6c4b4b79c6-nlh5j 2/2 Running 0 55m 100.118.108.231 cce-k8s-w-1 <none> <none>
rook-ceph-mds-myfs-c-6947798bdc-fmhdx 2/2 Running 0 55m 100.118.108.233 cce-k8s-w-1 <none> <none>
rook-ceph-mds-myfs-d-75f7974874-n6rzs 2/2 Running 0 55m 100.118.108.234 cce-k8s-w-1 <none> <none>
rook-ceph-mgr-a-c9b6d5b69-jfd4s 3/3 Running 0 22h 100.101.104.137 cce-k8s-w-2 <none> <none>
rook-ceph-mgr-b-6b7fcf6bd-kzng5 3/3 Running 0 22h 100.118.108.200 cce-k8s-w-1 <none> <none>
rook-ceph-mon-a-5cd956c46f-9b4ms 2/2 Running 0 22h 100.101.104.147 cce-k8s-w-2 <none> <none>
rook-ceph-mon-b-7bd996578f-f626r 2/2 Running 0 22h 100.118.108.207 cce-k8s-w-1 <none> <none>
rook-ceph-mon-c-67dcbbff4d-p85n5 2/2 Running 0 22h 100.110.251.12 cce-k8s-m-1 <none> <none>
rook-ceph-operator-644954fb4b-pm9cl 1/1 Running 0 23h 100.101.104.131 cce-k8s-w-2 <none> <none>
rook-ceph-osd-0-7bddbd7847-cj9lf 2/2 Running 0 22h 100.110.251.9 cce-k8s-m-1 <none> <none>
rook-ceph-osd-1-d4589dfc8-842s4 2/2 Running 0 22h 100.118.108.203 cce-k8s-w-1 <none> <none>
rook-ceph-osd-2-59547758c7-vk995 2/2 Running 0 22h 100.101.104.141 cce-k8s-w-2 <none> <none>
rook-ceph-osd-prepare-cce-k8s-m-1-stsgr 0/1 Completed 0 86m 100.110.251.24 cce-k8s-m-1 <none> <none>
rook-ceph-osd-prepare-cce-k8s-w-1-pkx9l 0/1 Completed 0 86m 100.118.108.230 cce-k8s-w-1 <none> <none>
rook-ceph-osd-prepare-cce-k8s-w-2-tpwn8 0/1 Completed 0 86m 100.101.104.169 cce-k8s-w-2 <none> <none>
rook-ceph-rgw-my-store-a-5c9d68f44d-ngdtg 1/2 Running 0 20s 100.101.104.177 cce-k8s-w-2 <none> <none>
rook-ceph-rgw-my-store-a-5c9d68f44d-w54qm 2/2 Running 0 40s 100.110.251.26 cce-k8s-m-1 <none> <none>
rook-ceph-tools-7857bc9568-q2zgv 1/1 Running 0 22h 100.101.104.145 cce-k8s-w-2 <none> <none>
8.5:连接外部集群
Rook 提供了管理外部 RGW 对象存储的能力,通过 CephObjectStore 自定义资源对象提供了管理外部 RGW 对象存储的能力,其会通过创建一个 service 实现和外部对象存储管理, kubernetes 集群内部访问 service 的 vip 地址即可实现访问。
[root@cce-k8s-m-1 examples]# cat object-external.yaml
#################################################################################################################
# Create an object store with settings for replication in a production environment. A minimum of 3 hosts with
# OSDs are required in this example.
# kubectl create -f object.yaml
#################################################################################################################
apiVersion: ceph.rook.io/v1
kind: CephObjectStore
metadata:
name: external-store
namespace: rook-ceph # namespace:cluster
spec:
gateway:
# The port on which **ALL** the gateway(s) are listening on.
# Passing a single IP from a load-balancer is also valid.
port: 80
externalRgwEndpoints:
- ip: 192.168.39.182
# 地址就可以写多个RGW的地址这样就可以实现管理外部RGW的目的了,那么它其实就是封装了一层VIP,来转发给外部的RGW,不过我没有外部的RGW,所以我就不部署了。
8.6:创建Bucket桶
Ceph RGW 集群创建好之后就可以往 RGW 存储对象存储数据了,存储数据之前需要有创建 bucket , bucket 是存储桶,是对象存储中逻辑的存储空间,可以通过 Ceph 原生的接口管理存储桶入 radowgw-admin ,云原生环境下,推荐使用云原生的方式管理 bucket ,何为云原生模式?即资源对象抽象化为 kubernetes ⻛格的方式来管理,尽可能减少使用原生命令,如创建资源池,创建 bucket 等。
首先需要创建存储消费桶的 StorageClass
[root@cce-k8s-m-1 examples]# grep -v "[*^#]" storageclass-bucket-delete.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: rook-ceph-delete-bucket
reclaimPolicy: Delete
parameters:
objectStoreName: my-store
[root@cce-k8s-m-1 examples]# kubectl apply -f storageclass-bucket-delete.yaml
storageclass.storage.k8s.io/rook-ceph-delete-bucket created
[root@cce-k8s-m-1 examples]# kubectl get sc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
rook-ceph-block rook-ceph.rbd.csi.ceph.com Delete Immediate true 9h
rook-ceph-delete-bucket rook-ceph.ceph.rook.io/bucket Delete Immediate false 4s
rook-cephfs rook-ceph.cephfs.csi.ceph.com Delete Immediate true 146m
# 通过 ObjectBucketClaim 向 StorageClass 申请存储桶,创建了一个名为 ceph-bkt 的 bucket
[root@cce-k8s-m-1 examples]# grep -v "[*^#]" object-bucket-claim-delete.yaml
apiVersion: objectbucket.io/v1alpha1
kind: ObjectBucketClaim
metadata:
name: ceph-delete-bucket
spec:
generateBucketName: ceph-bkt
storageClassName: rook-ceph-delete-bucket
additionalConfig:
[root@cce-k8s-m-1 examples]# kubectl apply -f object-bucket-claim-delete.yaml
objectbucketclaim.objectbucket.io/ceph-delete-bucket created
[root@cce-k8s-m-1 examples]# kubectl get objectbucketclaim.objectbucket.io
NAME AGE
ceph-delete-bucket 19s
[root@cce-k8s-m-1 examples]# radosgw-admin bucket list
[
"rook-ceph-bucket-checker-5672a514-f2b3-4e15-b286-e441005d8b4d",
"ceph-bkt-ef8f0ce4-b429-40d3-944b-a8bbc5bd33a0"
]
8.7:集群访问对象存储
创建 ObjectBucketClaim 之后, operator 会自动创建 bucket 相关的访问信息,包括访问的路径,认证的访问所需的 key ,这些信息分别存放在 configmap 和 secrets 对象中,可以通过如下的方式获取
# 获取访问的地址
[root@cce-k8s-m-1 examples]# kubectl get configmaps ceph-delete-bucket -o yaml -o jsonpath='{.data.BUCKET_HOST}'
rook-ceph-rgw-my-store.rook-ceph.svc
# 获取 ACCESS KEY 和 SECRET_ACCESS_KEY , Secrets 通过 base64 加密,需要获取解密后的字符串
[root@cce-k8s-m-1 examples]# kubectl get secrets ceph-delete-bucket -o yaml -o jsonpath='{.data.AWS_ACCESS_KEY_ID}' | base64 -d
8GLBZSWMCF0T4I8TKL80
[root@cce-k8s-m-1 examples]# kubectl get secrets ceph-delete-bucket -o yamel -o jsonpath='{.data.AWS_SECRET_ACCESS_KEY}' | base64 -d
zyBtINZZAgDLs1svoGpqddAdzbMRPMAA8WBaBq5P
# 我们直接本机下载一个s3cmd
[root@cce-k8s-m-1 examples]# yum install -y s3cmd.noarch
# 配置s3cmd
[root@cce-k8s-m-1 examples]# s3cmd --configure
Enter new values or accept defaults in brackets with Enter.
Refer to user manual for detailed description of all options.
Access key and Secret key are your identifiers for Amazon S3. Leave them empty for using the env variables.
Access Key: 8GLBZSWMCF0T4I8TKL80
Secret Key: zyBtINZZAgDLs1svoGpqddAdzbMRPMAA8WBaBq5P
Default Region [US]:
Use "s3.amazonaws.com" for S3 Endpoint and not modify it to the target Amazon S3.
S3 Endpoint [s3.amazonaws.com]: 10.96.1.56:80
Use "%(bucket)s.s3.amazonaws.com" to the target Amazon S3. "%(bucket)s" and "%(location)s" vars can be used
if the target S3 system supports dns based buckets.
DNS-style bucket+hostname:port template for accessing a bucket [%(bucket)s.s3.amazonaws.com]: 10.96.1.56:80/%(bucket)
Encryption password is used to protect your files from reading
by unauthorized persons while in transfer to S3
Encryption password:
Path to GPG program [/usr/bin/gpg]:
When using secure HTTPS protocol all communication with Amazon S3
servers is protected from 3rd party eavesdropping. This method is
slower than plain HTTP, and can only be proxied with Python 2.7 or newer
Use HTTPS protocol [Yes]: no
On some networks all internet access must go through a HTTP proxy.
Try setting it here if you can't connect to S3 directly
HTTP Proxy server name:
New settings:
Access Key: 8GLBZSWMCF0T4I8TKL80
Secret Key: zyBtINZZAgDLs1svoGpqddAdzbMRPMAA8WBaBq5P
Default Region: US
S3 Endpoint: 10.96.1.56:80
DNS-style bucket+hostname:port template for accessing a bucket: 10.96.1.56:80/%(bucket)
Encryption password:
Path to GPG program: /usr/bin/gpg
Use HTTPS protocol: False
HTTP Proxy server name:
HTTP Proxy server port: 0
Test access with supplied credentials? [Y/n] y
Please wait, attempting to list all buckets...
Success. Your access key and secret key worked fine :-)
Now verifying that encryption works...
Not configured. Never mind.
Save settings? [y/N] y
Configuration saved to '/root/.s3cfg'
[root@cce-k8s-m-1 examples]# s3cmd ls
2023-04-03 14:01 s3://ceph-bkt-ef8f0ce4-b429-40d3-944b-a8bbc5bd33a0
# 可以看到我们的bucket了,那么我们下面就测试上传下载了
# 上传
[root@cce-k8s-m-1 examples]# s3cmd put /etc/passwd s3://ceph-bkt-ef8f0ce4-b429-40d3-944b-a8bbc5bd33a0
upload: '/etc/passwd' -> 's3://ceph-bkt-ef8f0ce4-b429-40d3-944b-a8bbc5bd33a0/passwd' [1 of 1]
1119 of 1119 100% in 0s 51.19 KB/s done
[root@cce-k8s-m-1 examples]# s3cmd ls s3://ceph-bkt-ef8f0ce4-b429-40d3-944b-a8bbc5bd33a0
2023-04-03 14:17 1119 s3://ceph-bkt-ef8f0ce4-b429-40d3-944b-a8bbc5bd33a0/passwd
# 下载文件
[root@cce-k8s-m-1 ~]# ls
anaconda-ks.cfg rook
[root@cce-k8s-m-1 ~]# s3cmd get s3://ceph-bkt-ef8f0ce4-b429-40d3-944b-a8bbc5bd33a0/passwd
download: 's3://ceph-bkt-ef8f0ce4-b429-40d3-944b-a8bbc5bd33a0/passwd' -> './passwd' [1 of 1]
1119 of 1119 100% in 0s 153.87 KB/s done
[root@cce-k8s-m-1 ~]# ls
anaconda-ks.cfg passwd rook
# 如果需要集群外的客户端访问到bucket,那么我们需要将rgw暴露出去,可有使用NodePort或者Ingress都是可以的,外部可以使用s3cmd,或者其他的bucket工具都可以访问到这个Bucket了
8.8:创建集群访问用户
# 目的:我们前面创建的Bucket的key是通过BucketClaim创建出来的,而它创建出来的key只能在集群操作资源,并不能创建Bucket,那么我们如果需要很大的权限来管理Bucket的话需要去创建Key的
# 客户端我们可以用这个命令去操作用户相关的问题
[root@cce-k8s-m-1 ~]# radosgw-admin -h
# 云原生资源的方式
[root@cce-k8s-m-1 examples]# cat object-user.yaml
apiVersion: ceph.rook.io/v1
kind: CephObjectStoreUser
metadata:
name: my-user
namespace: rook-ceph # namespace:cluster
spec:
store: my-store
displayName: "my display name"
# Quotas set on the user
# quotas:
# maxBuckets: 100
# maxSize: 10G
# maxObjects: 10000
# Additional permissions given to the user
# capabilities:
# user: "*"
# bucket: "*"
# metadata: "*"
# usage: "*"
# zone: "*"
[root@cce-k8s-m-1 examples]# kubectl -n rook-ceph get secrets rook-ceph-object-user-my-store-my-user
NAME TYPE DATA AGE
rook-ceph-object-user-my-store-my-user kubernetes.io/rook 3 52s
# 获取新用户的 access key 和 secret key 信息
[root@cce-k8s-m-1 examples]# kubectl -n rook-ceph get secrets rook-ceph-object-user-my-store-my-user -o yaml -o jsonpath='{.data.AccessKey}' | base64 -d
HCPYBS2NG38UUHEO22ZL
[root@cce-k8s-m-1 examples]# kubectl -n rook-ceph get secrets rook-ceph-object-user-my-store-my-user -o yaml -o jsonpath='{.data.SecretKey}' | base64 -d
se0XCl31VFiDPqAaYS8sNmhvA5NgCKEwE4HQanmK
[root@cce-k8s-m-1 examples]# kubectl -n rook-ceph get secrets rook-ceph-object-user-my-store-my-user -o yaml -o jsonpath='{.data.Endpoint}' | base64 -d
http://rook-ceph-rgw-my-store.rook-ceph.svc:80
# 修改当前宿主机 /root/.s3cfg 配置信息,使用新用户的 access key 和 secret key 信息
[root@cce-k8s-m-1 examples]# cat /root/.s3cfg
[default]
access_key = HCPYBS2NG38UUHEO22ZL
#access_key = 8GLBZSWMCF0T4I8TKL80
......
secret_key = se0XCl31VFiDPqAaYS8sNmhvA5NgCKEwE4HQanmK
#secret_key = zyBtINZZAgDLs1svoGpqddAdzbMRPMAA8WBaBq5P
......
# 验证新用户权限
[root@cce-k8s-m-1 examples]# s3cmd mb s3://layzer
Bucket 's3://layzer/' created
[root@cce-k8s-m-1 examples]# s3cmd ls
2023-04-03 15:00 s3://layzer
# 上传
[root@cce-k8s-m-1 examples]# s3cmd put /etc/passwd s3://layzer
upload: '/etc/passwd' -> 's3://layzer/passwd' [1 of 1]
1119 of 1119 100% in 0s 57.00 KB/s done
[root@cce-k8s-m-1 examples]# s3cmd ls s3://layzer
2023-04-03 15:00 1119 s3://layzer/passwd
# 下载
[root@cce-k8s-m-1 ~]# s3cmd get s3://layzer/passwd
download: 's3://layzer/passwd' -> './passwd' [1 of 1]
1119 of 1119 100% in 0s 161.46 KB/s done
[root@cce-k8s-m-1 ~]# ls
anaconda-ks.cfg passwd rook
# 查看Bucket列表
[root@cce-k8s-m-1 ~]# radosgw-admin bucket list
[
"layzer",
"rook-ceph-bucket-checker-5672a514-f2b3-4e15-b286-e441005d8b4d",
"ceph-bkt-ef8f0ce4-b429-40d3-944b-a8bbc5bd33a0"
]
8.9:RGW集群维护
# RGW 以容器 pods 的形式运行在集群中
[root@cce-k8s-m-1 ~]# kubectl get pods -n rook-ceph -l app=rook-ceph-rgw
NAME READY STATUS RESTARTS AGE
rook-ceph-rgw-my-store-a-5c9d68f44d-ngdtg 2/2 Running 0 80m
rook-ceph-rgw-my-store-a-5c9d68f44d-w54qm 2/2 Running 0 81m
# RGW 集群状态
[root@cce-k8s-m-1 ~]# ceph -s
cluster:
id: 5d33f341-bf25-46bd-8a17-53952cda0eee
health: HEALTH_OK
services:
mon: 3 daemons, quorum a,b,c (age 2h)
mgr: b(active, since 24h), standbys: a
mds: 2/2 daemons up, 2 hot standby
osd: 3 osds: 3 up (since 24h), 3 in (since 24h)
rgw: 2 daemons active (2 hosts, 1 zones)
data:
volumes: 1/1 healthy
pools: 12 pools, 169 pgs
objects: 440 objects, 744 KiB
usage: 354 MiB used, 150 GiB / 150 GiB avail
pgs: 169 active+clean
io:
client: 1.7 KiB/s rd, 3 op/s rd, 0 op/s wr
# 查看 RGW 日志
[root@cce-k8s-m-1 ~]# kubectl -n rook-ceph logs -f rook-ceph-rgw-my-store-a-5c9d68f44d-ngdtg
9:OSD日常管理
9.1:OSD健康状态
[root@cce-k8s-m-1 ~]# ceph status
cluster:
id: 5d33f341-bf25-46bd-8a17-53952cda0eee
health: HEALTH_OK
services:
mon: 3 daemons, quorum a,b,c (age 2h)
mgr: b(active, since 24h), standbys: a
mds: 2/2 daemons up, 2 hot standby
osd: 3 osds: 3 up (since 24h), 3 in (since 24h)
rgw: 2 daemons active (2 hosts, 1 zones)
data:
volumes: 1/1 healthy
pools: 12 pools, 169 pgs
objects: 440 objects, 744 KiB
usage: 363 MiB used, 150 GiB / 150 GiB avail
pgs: 169 active+clean
io:
client: 2.5 KiB/s rd, 4 op/s rd, 0 op/s wr
[root@cce-k8s-m-1 ~]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.14639 root default
-5 0.04880 host cce-k8s-m-1
0 hdd 0.04880 osd.0 up 1.00000 1.00000
-3 0.04880 host cce-k8s-w-1
1 hdd 0.04880 osd.1 up 1.00000 1.00000
-7 0.04880 host cce-k8s-w-2
2 hdd 0.04880 osd.2 up 1.00000 1.00000
[root@cce-k8s-m-1 ~]# ceph osd status
ID HOST USED AVAIL WR OPS WR DATA RD OPS RD DATA STATE
0 cce-k8s-m-1 114M 49.8G 0 5 3 771 exists,up
1 cce-k8s-w-1 122M 49.8G 1 0 7 772 exists,up
2 cce-k8s-w-2 126M 49.8G 0 0 2 42 exists,up
[root@cce-k8s-m-1 ~]# ceph osd df
ID CLASS WEIGHT REWEIGHT SIZE RAW USE DATA OMAP META AVAIL %USE VAR PGS STATUS
0 hdd 0.04880 1.00000 50 GiB 114 MiB 4.9 MiB 0 B 110 MiB 50 GiB 0.22 0.94 169 up
1 hdd 0.04880 1.00000 50 GiB 122 MiB 4.9 MiB 0 B 118 MiB 50 GiB 0.24 1.01 169 up
2 hdd 0.04880 1.00000 50 GiB 126 MiB 4.9 MiB 0 B 122 MiB 50 GiB 0.25 1.04 169 up
TOTAL 150 GiB 363 MiB 15 MiB 0 B 348 MiB 150 GiB 0.24
MIN/MAX VAR: 0.94/1.04 STDDEV: 0.01
[root@cce-k8s-m-1 ~]# ceph osd utilization
avg 169
stddev 0 (expected baseline 10.6145)
min osd.0 with 169 pgs (1 * mean)
max osd.0 with 169 pgs (1 * mean)
9.2:OSD横向扩容
当 Ceph 的存储空间不够时候,需要对 Ceph 进行扩容, Ceph 能支持横向动态水平扩容,通常两种方式:
1:添加更多的 osd
2:添加额外的 host
Rook 默认使用“所有节点上所有的磁盘”,采用默认策略只要添加了磁盘或者主机就会按照 ROOK_DISCOVER_DEVICES_INTERVAL 设定的间隔扩容磁盘,前面安装时候调整了相关的策略
[root@cce-k8s-m-1 examples]# cat cluster.yaml
......
217 storage: # cluster level storage configuration and selection
218 useAllNodes: false
219 useAllDevices: false
即关闭状态,因此需要手动定义 nodes 信息,将需要扩展的磁盘添加到列表中,这里我去给master和node都去扩容一块20G的盘
[root@cce-k8s-m-1 examples]# cat cluster.yaml
...
nodes:
- name: "cce-k8s-m-1"
devices:
- name: "sda"
config:
journalSizeMB: "4096"
- name: "sdb"
config:
journalSizeMB: "4096"
- name: "cce-k8s-w-1"
devices:
- name: "sda"
config:
journalSizeMB: "4096"
- name: "sdb"
config:
journalSizeMB: "4096"
- name: "cce-k8s-w-2"
devices:
- name: "sda"
config:
journalSizeMB: "4096"
- name: "sdb"
config:
journalSizeMB: "4096"
...
[root@cce-k8s-m-1 examples]# kubectl apply -f cluster.yaml
[root@cce-k8s-m-1 examples]# ceph -s
cluster:
id: 5d33f341-bf25-46bd-8a17-53952cda0eee
health: HEALTH_OK
services:
mon: 3 daemons, quorum a,b,c (age 102m)
mgr: b(active, since 102m), standbys: a
mds: 2/2 daemons up, 2 hot standby
osd: 6 osds: 6 up (since 16s), 6 in (since 41s); 12 remapped pgs
rgw: 2 daemons active (1 hosts, 1 zones)
data:
volumes: 1/1 healthy
pools: 12 pools, 169 pgs
objects: 440 objects, 759 KiB
usage: 244 MiB used, 210 GiB / 210 GiB avail
pgs: 119/1320 objects misplaced (9.015%)
150 active+clean
12 active+recovering+undersized+remapped
3 active+remapped+backfilling
3 active+recovering
1 active+undersized+remapped
io:
client: 2.5 KiB/s rd, 4 op/s rd, 0 op/s wr
recovery: 238 B/s, 0 keys/s, 10 objects/s
# 可以看到OSD已经扩容到了6个
9.3:扩容失败排查-1
扩容后发现此时 osd 并未加入到集群中,原因何在呢?在 章节5 中定义了 osd 的节点调度机制,设定调度到具有 ceph-osd=enabled 标签的 node 节点,如果没有这个标签则无法满足调度的要求,前面我们只设定了 n4 节点,因此只有该节点满足调度要求,需要将其他的节设置上
1:查看当前 osd
[root@cce-k8s-m-1 examples]# kubectl -n rook-ceph get pods -l app=rook-ceph-osd
NAME READY STATUS RESTARTS AGE
rook-ceph-osd-0-7bddbd7847-cj9lf 2/2 Running 2 (105m ago) 26h
rook-ceph-osd-1-d4589dfc8-842s4 2/2 Running 2 (105m ago) 26h
rook-ceph-osd-2-59547758c7-vk995 2/2 Running 2 (105m ago) 26h
rook-ceph-osd-3-86dbf55594-tqdd4 2/2 Running 0 102m
rook-ceph-osd-4-7cbbf75fd4-4gx6k 2/2 Running 0 2m16s
rook-ceph-osd-5-dcfc7cc8-954d6 2/2 Running 0 2m16s
# 无非就是因为标签的问题
9.4:扩容失败排查-2
设定完标签调度机制后,重新看pods的状态发现此时 osd-0 状态处于 pending 状态,查看详情发现提示内存资源是 Insufficient ,即资源不够。
这个问题大概率不会出现在生产中,因为生产都是经过了定制的,并且资源方面都是选择好的,如果真的出现了这个问题,在cluster.yaml改改组件的配额就可以了
# 查看 ceph 集群
[root@cce-k8s-m-1 examples]# ceph -s
cluster:
id: 5d33f341-bf25-46bd-8a17-53952cda0eee
health: HEALTH_OK
services:
mon: 3 daemons, quorum a,b,c (age 107m)
mgr: b(active, since 107m), standbys: a
mds: 2/2 daemons up, 2 hot standby
osd: 6 osds: 6 up (since 5m), 6 in (since 5m)
rgw: 2 daemons active (1 hosts, 1 zones)
data:
volumes: 1/1 healthy
pools: 12 pools, 169 pgs
objects: 440 objects, 759 KiB
usage: 252 MiB used, 210 GiB / 210 GiB avail
pgs: 169 active+clean
io:
client: 2.5 KiB/s rd, 4 op/s rd, 0 op/s wr
# 查看 osd 信息
[root@cce-k8s-m-1 examples]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.20485 root default
-5 0.06828 host cce-k8s-m-1
0 hdd 0.04880 osd.0 up 1.00000 1.00000
4 hdd 0.01949 osd.4 up 1.00000 1.00000
-3 0.06828 host cce-k8s-w-1
1 hdd 0.04880 osd.1 up 1.00000 1.00000
5 hdd 0.01949 osd.5 up 1.00000 1.00000
-7 0.06828 host cce-k8s-w-2
2 hdd 0.04880 osd.2 up 1.00000 1.00000
3 hdd 0.01949 osd.3 up 1.00000 1.00000
[root@cce-k8s-m-1 examples]# ceph osd status
ID HOST USED AVAIL WR OPS WR DATA RD OPS RD DATA STATE
0 cce-k8s-m-1 47.2M 49.9G 0 0 2 0 exists,up
1 cce-k8s-w-1 38.5M 49.9G 0 0 4 212 exists,up
2 cce-k8s-w-2 48.0M 49.9G 0 0 1 0 exists,up
3 cce-k8s-w-2 51.0M 19.9G 0 0 0 0 exists,up
4 cce-k8s-m-1 33.4M 19.9G 0 0 0 0 exists,up
5 cce-k8s-w-1 33.6M 19.9G 0 0 0 0 exists,up
[root@cce-k8s-m-1 examples]# ceph osd df
ID CLASS WEIGHT REWEIGHT SIZE RAW USE DATA OMAP META AVAIL %USE VAR PGS STATUS
0 hdd 0.04880 1.00000 50 GiB 47 MiB 6.5 MiB 35 KiB 41 MiB 50 GiB 0.09 0.79 121 up
4 hdd 0.01949 1.00000 20 GiB 33 MiB 5.3 MiB 0 B 28 MiB 20 GiB 0.16 1.40 48 up
1 hdd 0.04880 1.00000 50 GiB 38 MiB 6.0 MiB 35 KiB 32 MiB 50 GiB 0.08 0.64 124 up
5 hdd 0.01949 1.00000 20 GiB 34 MiB 5.8 MiB 0 B 28 MiB 20 GiB 0.16 1.40 45 up
2 hdd 0.04880 1.00000 50 GiB 48 MiB 6.4 MiB 35 KiB 42 MiB 50 GiB 0.09 0.80 123 up
3 hdd 0.01949 1.00000 20 GiB 51 MiB 5.4 MiB 0 B 46 MiB 20 GiB 0.25 2.13 46 up
TOTAL 210 GiB 252 MiB 35 MiB 106 KiB 216 MiB 210 GiB 0.12
MIN/MAX VAR: 0.64/2.13 STDDEV: 0.06
# 日常发现 pods 无法运行时可以通过如下两种方式排查
1:kubectl describe pods 查看 events 事件
2:kubectl logs 查看容器内部日志信息
9.5:配置bluestore加速
Ceph 支持两种存储引擎
1:Filestore:SSD作为journal
2:Bluestore:WAL+DB=SSD
主流均已使用Bluestore,对于Bluestore加速需要将wal+db存储在SSD中,其到加速的作用,如下讲解配置,不涉及具体配置
参考文档:https://rook.io/docs/rook/v1.11/CRDs/Cluster/ceph-cluster-crd/#cluster-settings
# 查看主机磁盘信息
[root@cce-k8s-m-1 examples]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS
sda 8:0 0 50G 0 disk
sdb 8:16 0 20G 0 disk
sdc 8:32 0 20G 0 disk
sr0 11:0 1 8.3G 0 rom
nvme0n1 259:0 0 20G 0 disk
├─nvme0n1p1 259:1 0 1G 0 part /boot
└─nvme0n1p2 259:2 0 19G 0 part
├─cs-root 253:0 0 17G 0 lvm /
└─cs-swap 253:1 0 2G 0 lvm
[root@cce-k8s-m-1 examples]# cat cluster.yaml
...
nodes:
- name: "cce-k8s-m-1"
devices:
- name: "sda"
config:
journalSizeMB: "4096"
devices:
- name: "sdb"
config:
metadataDevice: "/dev/sdc"
databaseSizeMB: "4096"
walSizeMB: "4096"
...
# 不过我这里没有SSD盘,所以貌似是看不出效果的。加不进来。
9.6:云原生删除OSD
如果 OSD 所在的磁盘故障了或者需要更换配置,这时需要将 OSD 从集群中删除,删除 OSD 的注意事项有
1:删除 osd 后确保集群有足够的容量
2:删除 osd 后确保PG状态正常
3:单次尽可能不要删除过多的 osd
4:删除多个 osd 需要等待数据同步同步完毕后再执行(rebalancing)
模拟 osd.5 故障,osd 故障时候 pods 状态会变成 CrashLoopBackoff 或者 error 状态,此时 ceph 中 osd 的状态也会变成 down 状态,通过如下方式可以模拟
[root@cce-k8s-m-1 examples]# kubectl scale deployment -n rook-ceph rook-ceph-osd-5 --replicas=0
deployment.apps/rook-ceph-osd-5 scaled
[root@cce-k8s-m-1 examples]# kubectl get deployments.apps -n rook-ceph
NAME READY UP-TO-DATE AVAILABLE AGE
......
rook-ceph-osd-5 0/0 0 0 80m
......
[root@cce-k8s-m-1 examples]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.20485 root default
-5 0.06828 host cce-k8s-m-1
0 hdd 0.04880 osd.0 up 1.00000 1.00000
4 hdd 0.01949 osd.4 up 1.00000 1.00000
-3 0.06828 host cce-k8s-w-1
1 hdd 0.04880 osd.1 up 1.00000 1.00000
5 hdd 0.01949 osd.5 down 1.00000 1.00000
-7 0.06828 host cce-k8s-w-2
2 hdd 0.04880 osd.2 up 1.00000 1.00000
3 hdd 0.01949 osd.3 up 1.00000 1.00000
# 我们发现OSD.5已经down了。
# 通过 rook 提供的脚本来删除,修改 osd-purge.yaml 资源清单,云原生删除 osd 坏盘
[root@cce-k8s-m-1 examples]# cat osd-purge.yaml
#################################################################################################################
# We need many operations to remove OSDs as written in Documentation/Storage-Configuration/Advanced/ceph-osd-mgmt.md.
# This job can automate some of that operations: mark OSDs as `out`, purge these OSDs,
# and delete the corresponding resources like OSD deployments, OSD prepare jobs, and PVCs.
#
# Please note the following.
#
# - This job only works for `down` OSDs.
# - This job doesn't wait for backfilling to be completed.
#
# If you want to remove `up` OSDs and/or want to wait for backfilling to be completed between each OSD removal,
# please do it by hand.
#################################################################################################################
apiVersion: batch/v1
kind: Job
metadata:
name: rook-ceph-purge-osd
namespace: rook-ceph # namespace:cluster
labels:
app: rook-ceph-purge-osd
spec:
template:
metadata:
labels:
app: rook-ceph-purge-osd
spec:
serviceAccountName: rook-ceph-purge-osd
containers:
- name: osd-removal
image: rook/ceph:v1.10.12
args:
- "ceph"
- "osd"
- "remove"
- "--preserve-pvc"
- "false"
- "--force-osd-removal"
- "false"
- "--osd-ids"
# 这里是我们OSD的ID
- "5"
env:
- name: POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
- name: ROOK_MON_ENDPOINTS
valueFrom:
configMapKeyRef:
key: data
name: rook-ceph-mon-endpoints
- name: ROOK_CEPH_USERNAME
valueFrom:
secretKeyRef:
key: ceph-username
name: rook-ceph-mon
- name: ROOK_CONFIG_DIR
value: /var/lib/rook
- name: ROOK_CEPH_CONFIG_OVERRIDE
value: /etc/rook/config/override.conf
- name: ROOK_FSID
valueFrom:
secretKeyRef:
key: fsid
name: rook-ceph-mon
- name: ROOK_LOG_LEVEL
value: DEBUG
volumeMounts:
- mountPath: /etc/ceph
name: ceph-conf-emptydir
- mountPath: /var/lib/rook
name: rook-config
- name: ceph-admin-secret
mountPath: /var/lib/rook-ceph-mon
volumes:
- name: ceph-admin-secret
secret:
secretName: rook-ceph-mon
optional: false
items:
- key: ceph-secret
path: secret.keyring
- emptyDir: {}
name: ceph-conf-emptydir
- emptyDir: {}
name: rook-config
restartPolicy: Never
# 执行脚本删除OSD
[root@cce-k8s-m-1 examples]# kubectl apply -f osd-purge.yaml
job.batch/rook-ceph-purge-osd created
# 此时 Ceph 会自动的进行数据的同步,等带数据的同步完成
[root@cce-k8s-m-1 examples]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.18536 root default
-5 0.06828 host cce-k8s-m-1
0 hdd 0.04880 osd.0 up 1.00000 1.00000
4 hdd 0.01949 osd.4 up 1.00000 1.00000
-3 0.04880 host cce-k8s-w-1
1 hdd 0.04880 osd.1 up 1.00000 1.00000
-7 0.06828 host cce-k8s-w-2
2 hdd 0.04880 osd.2 up 1.00000 1.00000
3 hdd 0.01949 osd.3 up 1.00000 1.00000
[root@cce-k8s-m-1 examples]# ceph osd crush dump | grep devices -A 50
"devices": [
{
"id": 0,
"name": "osd.0",
"class": "hdd"
},
{
"id": 1,
"name": "osd.1",
"class": "hdd"
},
{
"id": 2,
"name": "osd.2",
"class": "hdd"
},
{
"id": 3,
"name": "osd.3",
"class": "hdd"
},
{
"id": 4,
"name": "osd.4",
"class": "hdd"
}
],
# 删除不必要的 Deployment
[root@cce-k8s-m-1 examples]# kubectl delete deployments.apps -n rook-ceph rook-ceph-osd-5
deployment.apps "rook-ceph-osd-5" deleted
# 由于 cluster.yaml 中关闭了 useAllNodes 和 useAllDevices ,因此需要将 osd 的信息从 nodes 中删除,避免 apply 之后重新添加回集群。
[root@cce-k8s-m-1 examples]# ceph status
cluster:
id: 5d33f341-bf25-46bd-8a17-53952cda0eee
health: HEALTH_WARN
clock skew detected on mon.b, mon.c
services:
mon: 3 daemons, quorum a,b,c (age 78m)
mgr: b(active, since 78m), standbys: a
mds: 2/2 daemons up, 2 hot standby
osd: 5 osds: 5 up (since 12m), 5 in (since 8m)
rgw: 2 daemons active (1 hosts, 1 zones)
data:
volumes: 1/1 healthy
pools: 12 pools, 169 pgs
objects: 440 objects, 777 KiB
usage: 184 MiB used, 190 GiB / 190 GiB avail
pgs: 169 active+clean
io:
client: 4.7 KiB/s rd, 426 B/s wr, 7 op/s rd, 1 op/s wr
9.7:手动删除OSD
# 除了使用云原生的方式删除 osd 之外,也可以使用 Ceph 标准的方式进行删除,如下是删除的方法
[root@cce-k8s-m-1 examples]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.18536 root default
-5 0.06828 host cce-k8s-m-1
0 hdd 0.04880 osd.0 up 1.00000 1.00000
4 hdd 0.01949 osd.4 up 1.00000 1.00000
-3 0.04880 host cce-k8s-w-1
1 hdd 0.04880 osd.1 up 1.00000 1.00000
-7 0.06828 host cce-k8s-w-2
2 hdd 0.04880 osd.2 up 1.00000 1.00000
3 hdd 0.01949 osd.3 up 1.00000 1.00000
# 将 osd 标识为 out
[root@cce-k8s-m-1 examples]# ceph osd out osd.0
marked out osd.2.
[root@cce-k8s-m-1 examples]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.18536 root default
-5 0.06828 host cce-k8s-m-1
0 hdd 0.04880 osd.0 up 0 1.00000
4 hdd 0.01949 osd.4 up 1.00000 1.00000
-3 0.04880 host cce-k8s-w-1
1 hdd 0.04880 osd.1 up 1.00000 1.00000
-7 0.06828 host cce-k8s-w-2
2 hdd 0.04880 osd.2 up 1.00000 1.00000
3 hdd 0.01949 osd.3 up 1.00000 1.00000
[root@cce-k8s-m-1 examples]# ceph -s
cluster:
id: 5d33f341-bf25-46bd-8a17-53952cda0eee
health: HEALTH_WARN
Degraded data redundancy: 1/1317 objects degraded (0.076%), 1 pg degraded
services:
mon: 3 daemons, quorum a,b,c (age 100m)
mgr: b(active, since 100m), standbys: a
mds: 2/2 daemons up, 2 hot standby
osd: 5 osds: 5 up (since 37s), 4 in (since 11s); 25 remapped pgs
rgw: 2 daemons active (1 hosts, 1 zones)
data:
volumes: 1/1 healthy
pools: 12 pools, 169 pgs
objects: 439 objects, 777 KiB
usage: 275 MiB used, 140 GiB / 140 GiB avail
pgs: 0.592% pgs not active
1/1317 objects degraded (0.076%)
101/1317 objects misplaced (7.669%)
126 active+clean
28 active+recovering+undersized+remapped
11 active+recovering
2 active+remapped+backfilling
1 peering
1 active+recovering+undersized+degraded+remapped
io:
client: 11 KiB/s rd, 1.2 KiB/s wr, 14 op/s rd, 4 op/s wr
recovery: 5.3 KiB/s, 3 keys/s, 20 objects/s
[root@cce-k8s-m-1 examples]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.18536 root default
-5 0.06828 host cce-k8s-m-1
0 hdd 0.04880 osd.0 down 0 1.00000
4 hdd 0.01949 osd.4 up 1.00000 1.00000
-3 0.04880 host cce-k8s-w-1
1 hdd 0.04880 osd.1 up 1.00000 1.00000
-7 0.06828 host cce-k8s-w-2
2 hdd 0.04880 osd.2 up 1.00000 1.00000
3 hdd 0.01949 osd.3 up 1.00000 1.00000
[root@cce-k8s-m-1 examples]# ceph osd purge 0
purged osd.0
[root@cce-k8s-m-1 examples]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.13657 root default
-5 0.01949 host cce-k8s-m-1
4 hdd 0.01949 osd.4 up 1.00000 1.00000
-3 0.04880 host cce-k8s-w-1
1 hdd 0.04880 osd.1 up 1.00000 1.00000
-7 0.06828 host cce-k8s-w-2
2 hdd 0.04880 osd.2 up 1.00000 1.00000
3 hdd 0.01949 osd.3 up 1.00000 1.00000
[root@cce-k8s-m-1 examples]# ceph status
cluster:
id: 5d33f341-bf25-46bd-8a17-53952cda0eee
health: HEALTH_OK
services:
mon: 3 daemons, quorum a,b,c (age 109m)
mgr: b(active, since 109m), standbys: a
mds: 2/2 daemons up, 2 hot standby
osd: 4 osds: 4 up (since 26s), 4 in (since 37s)
rgw: 2 daemons active (1 hosts, 1 zones)
data:
volumes: 1/1 healthy
pools: 12 pools, 169 pgs
objects: 440 objects, 777 KiB
usage: 263 MiB used, 140 GiB / 140 GiB avail
pgs: 169 active+clean
io:
client: 3.4 KiB/s rd, 170 B/s wr, 5 op/s rd, 1 op/s wr
# 删除 out ,此时会进行元数据的同步,即 backfilling 和 rebalancing 动作,完成数据的迁移
[root@cce-k8s-m-1 examples]# ceph osd crush dump | grep devices -A 50
"devices": [
{
"id": 0,
"name": "device0"
},
{
"id": 1,
"name": "osd.1",
"class": "hdd"
},
{
"id": 2,
"name": "osd.2",
"class": "hdd"
},
{
"id": 3,
"name": "osd.3",
"class": "hdd"
},
{
"id": 4,
"name": "osd.4",
"class": "hdd"
}
],
# 对应 deployment 和 cluster.yaml 中的内容删除
9.8:OSD替换方法
1:替换操作的思路是:
1:将其从 Ceph 集群中删除—采用云原生方式或手动方式
2:删除之后数据同步完毕后再通过扩容的方式添加回集群中
3:添加回来时候注意将对应的LVM删除
10:Dashboard概述
10.1:Dashboard Web概述
日常可以通过 Ceph 原生的命令行和 Rook 提供的云原生方式对 Ceph 进行管理,这两种方式都具有一定的难度, Ceph 提供了一种更加简单的方式使用和 Ceph 监控,这个工具便是 Ceph Dashboard , Ceph dashboard 官方展板介绍地址,它是一个 WebUI 的图形管理方式,能够提供两个方面的功能:
1:Ceph 管理: 如 Pool,RBD,CephFS的日常管理接口
2:性能监控: 监控 Ceph 的健康状态,如 Mon,OSD,mgr
10.2:启用Dashboard组件
Rook 默认在 cluster.yaml 文件中已经启用了 Ceph Dashboard 组件,集成在 mgr 内部,不需要任何的配置即可使用(免去了包的安装,插件启用,SSL证书,端口等配置过程),使用非常简单
...
mgr:
# When higher availability of the mgr is needed, increase the count to 2.
# In that case, one mgr will be active and one in standby. When Ceph updates which
# mgr is active, Rook will update the mgr services to match the active mgr.
count: 2
allowMultiplePerNode: false
modules:
# Several modules should not need to be included in this list. The "dashboard" and "monitoring" modules
# are already enabled by other settings in the cluster CR.
- name: pg_autoscaler
enabled: true
# enable the ceph dashboard for viewing cluster status
dashboard:
enabled: true
urlPrefix: /ceph-dashboard
# serve the dashboard at the given port.
# port: 8443
# serve the dashboard using SSL
ssl: false
...
Ceph Dashboard默认会通过 service 的方式将服务暴露给外部,通过 8443 的 https 端口进行访问,如下
[root@cce-k8s-m-1 examples]# kubectl get svc -n rook-ceph
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
rook-ceph-mgr ClusterIP 10.96.1.168 <none> 9283/TCP 64m
rook-ceph-mgr-dashboard ClusterIP 10.96.1.173 <none> 8443/TCP 64m
rook-ceph-mon-a ClusterIP 10.96.0.92 <none> 6789/TCP,3300/TCP 66m
rook-ceph-mon-b ClusterIP 10.96.2.93 <none> 6789/TCP,3300/TCP 65m
rook-ceph-mon-c ClusterIP 10.96.1.40 <none> 6789/TCP,3300/TCP 65m
# 暴露 Dashboard 访问
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: rook-ceph-mgr-dashboard
namespace: rook-ceph
spec:
ingressClassName: nginx
rules:
- host: rook-ceph.kudevops.cn
http:
paths:
- pathType: Prefix
path: /ceph-dashboard
backend:
service:
name: rook-ceph-mgr-dashboard
port:
name: http-dashboard
# 但是我这里走的是ingress,可以用
[root@cce-k8s-m-1 examples]# ls | grep dashboard
dashboard-external-https.yaml
dashboard-external-http.yaml
dashboard-ingress-https.yaml
dashboard-loadbalancer.yaml
# 这四个都是可以的,不过前提是我前面关闭了ssl,然后svc就会变成7000端口了

用户: admin ,密码从 secrets 中获取
[root@cce-k8s-m-1 examples]# kubectl -n rook-ceph get secrets rook-ceph-dashboard-password -o yaml -o jsonpath={.data.password} | base64 -d
R}9I?$ih=K'bqs8|>rM_
10.3:Dashboard监控Ceph
Dashboard 提供了图形界面的功能,能够监控完成 Ceph 监控所需的功能,包括:
1:集群监控,包含各组件的监控,如 MON,MGR,RGW,OSD,HOST 等
2:容量监控,容量使用情况,Objects 数量,Pool 状态,PGs 状态,Pool 等;
3:性能监控,如客户端读写性能,吞吐量量,恢复 Recovery 流量,Scrubbing 等
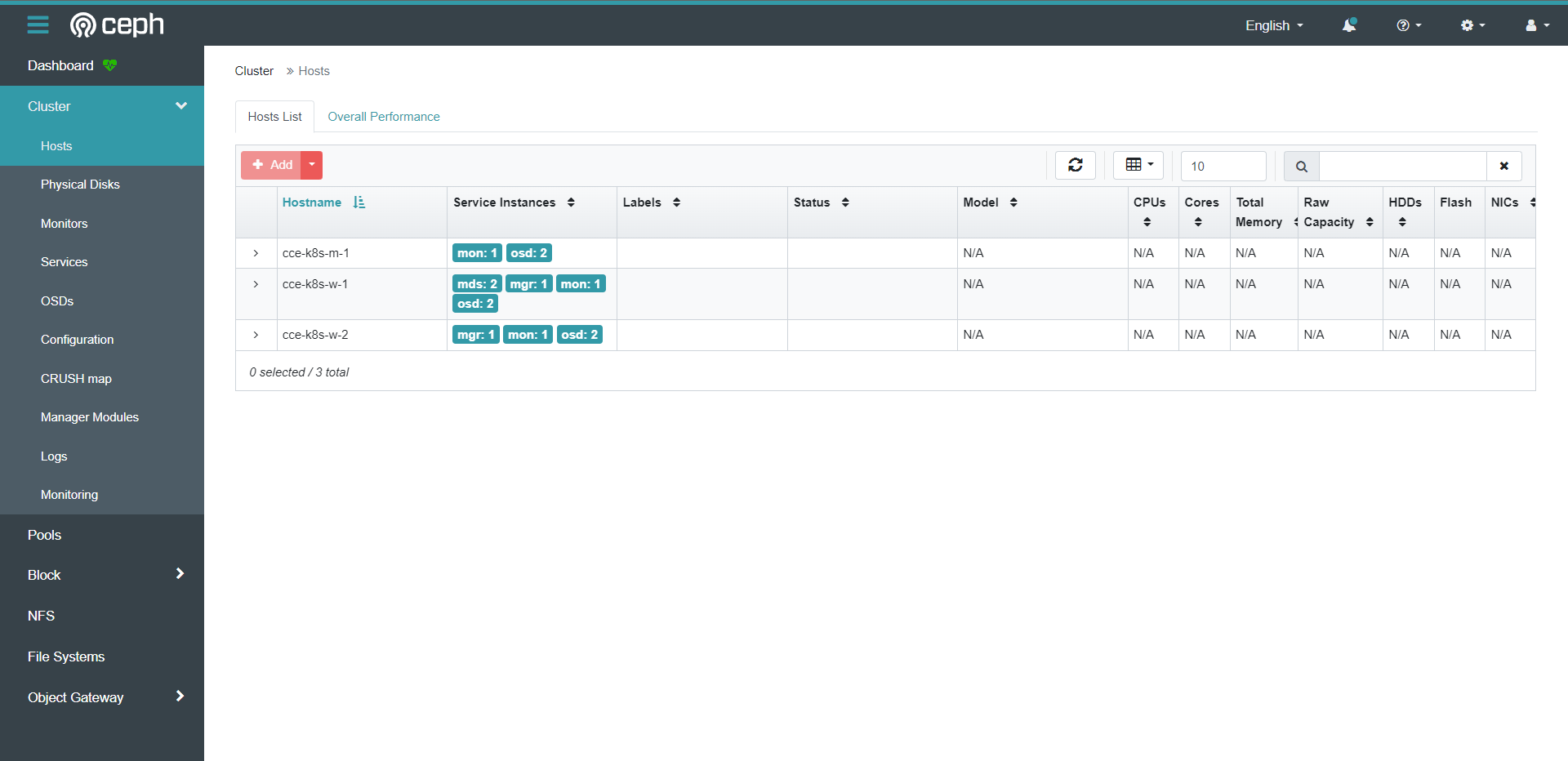
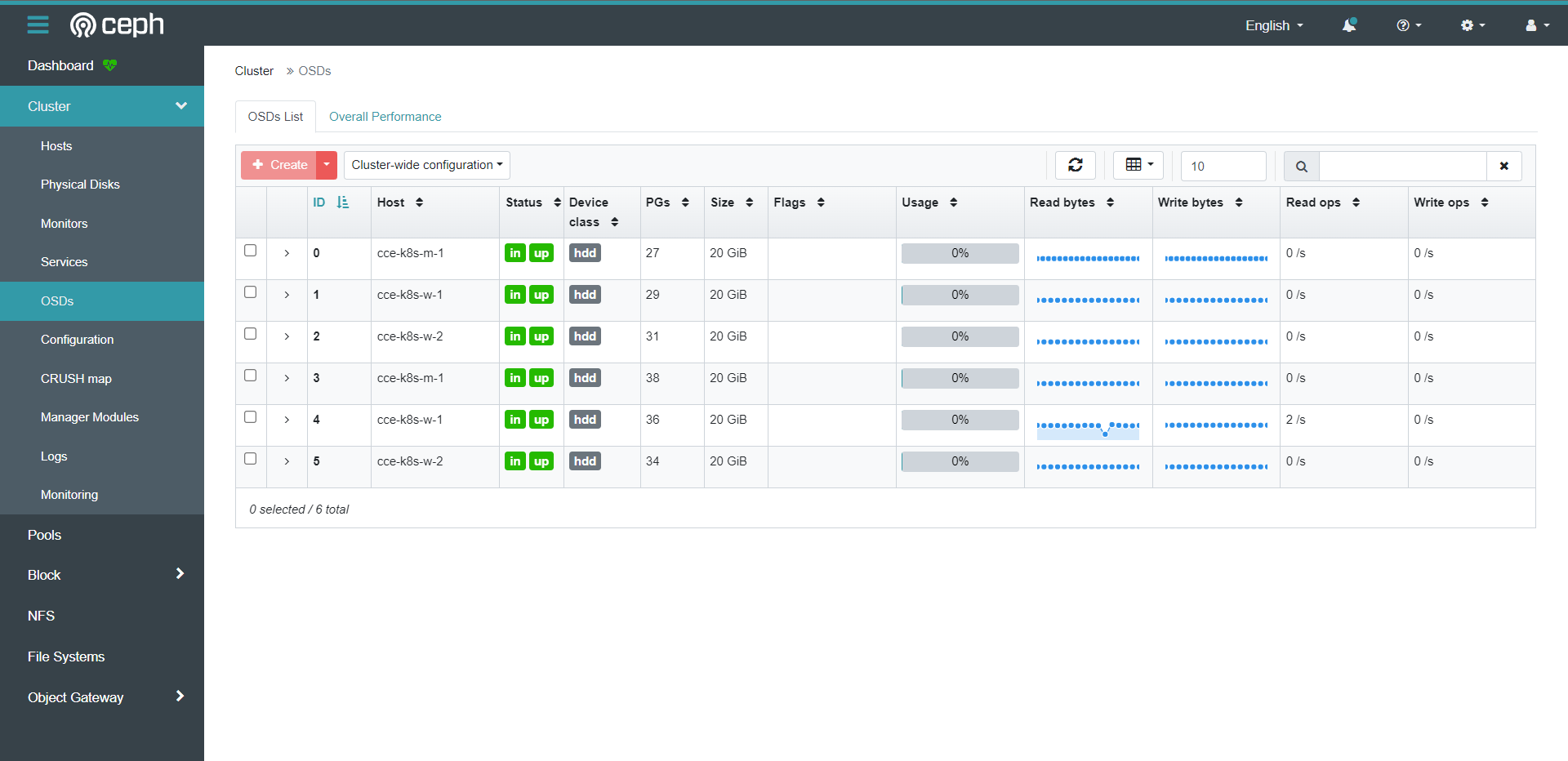
10.4:Dashboard管理Ceph
Ceph 还提供了部分管理 Ceph 的功能,如 Pool,RBD 块存储,RGW对象存储等
# 创建Pool
# 修改Pool类型
# 查看Pool信息
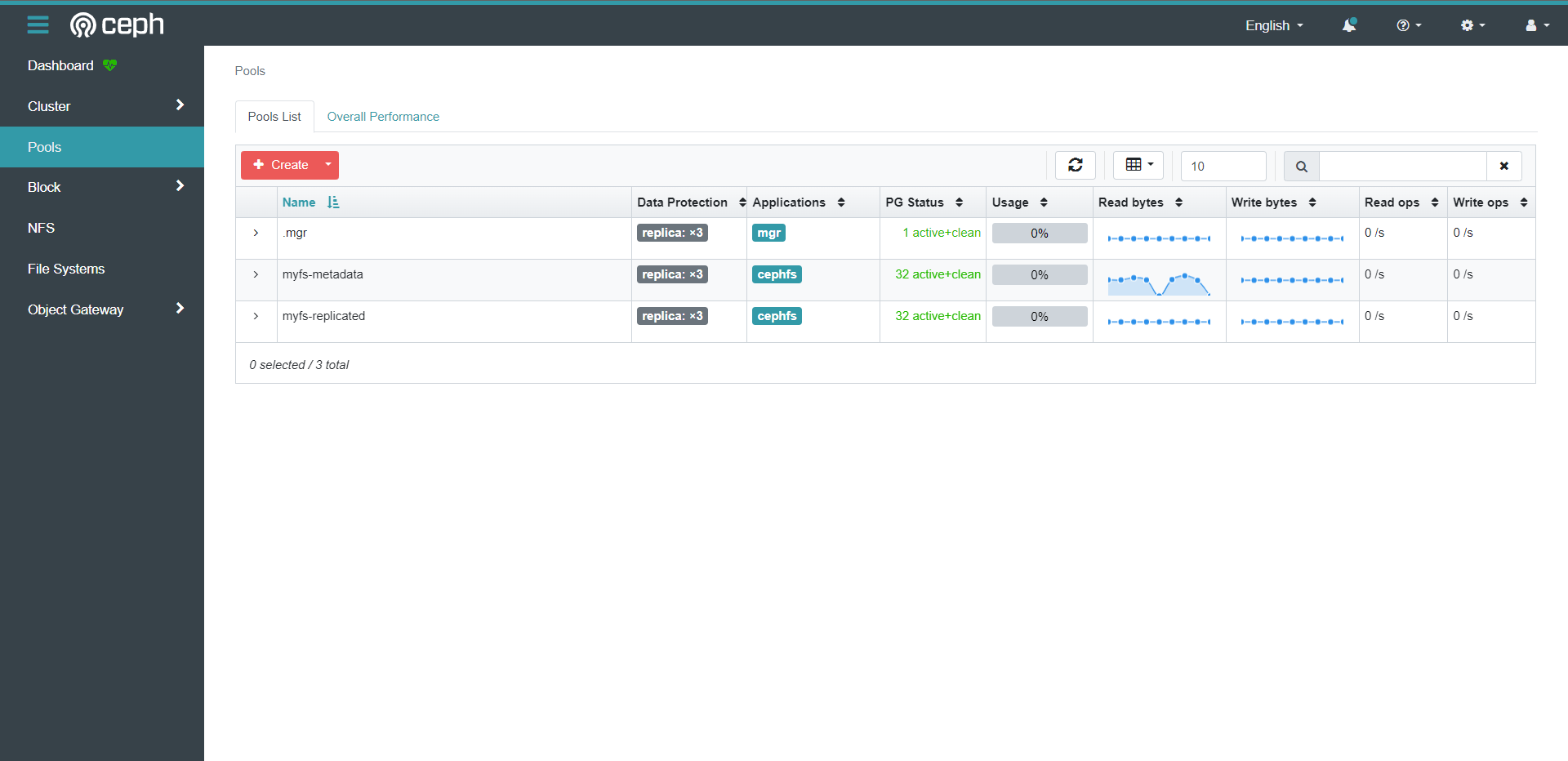
# 对比
[root@cce-k8s-m-1 examples]# ceph osd lspools
1 .mgr
2 myfs-metadata
3 myfs-replicated
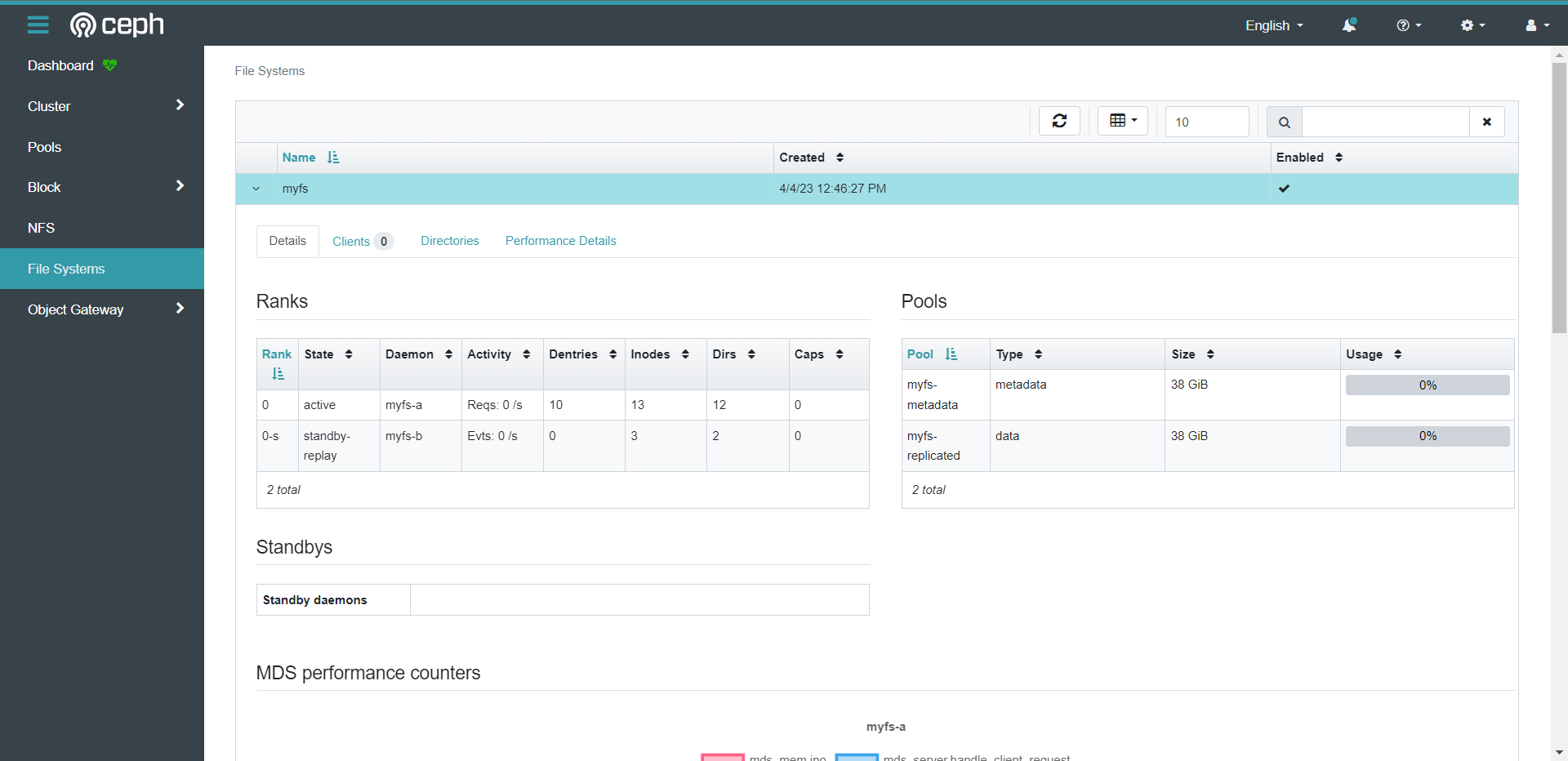
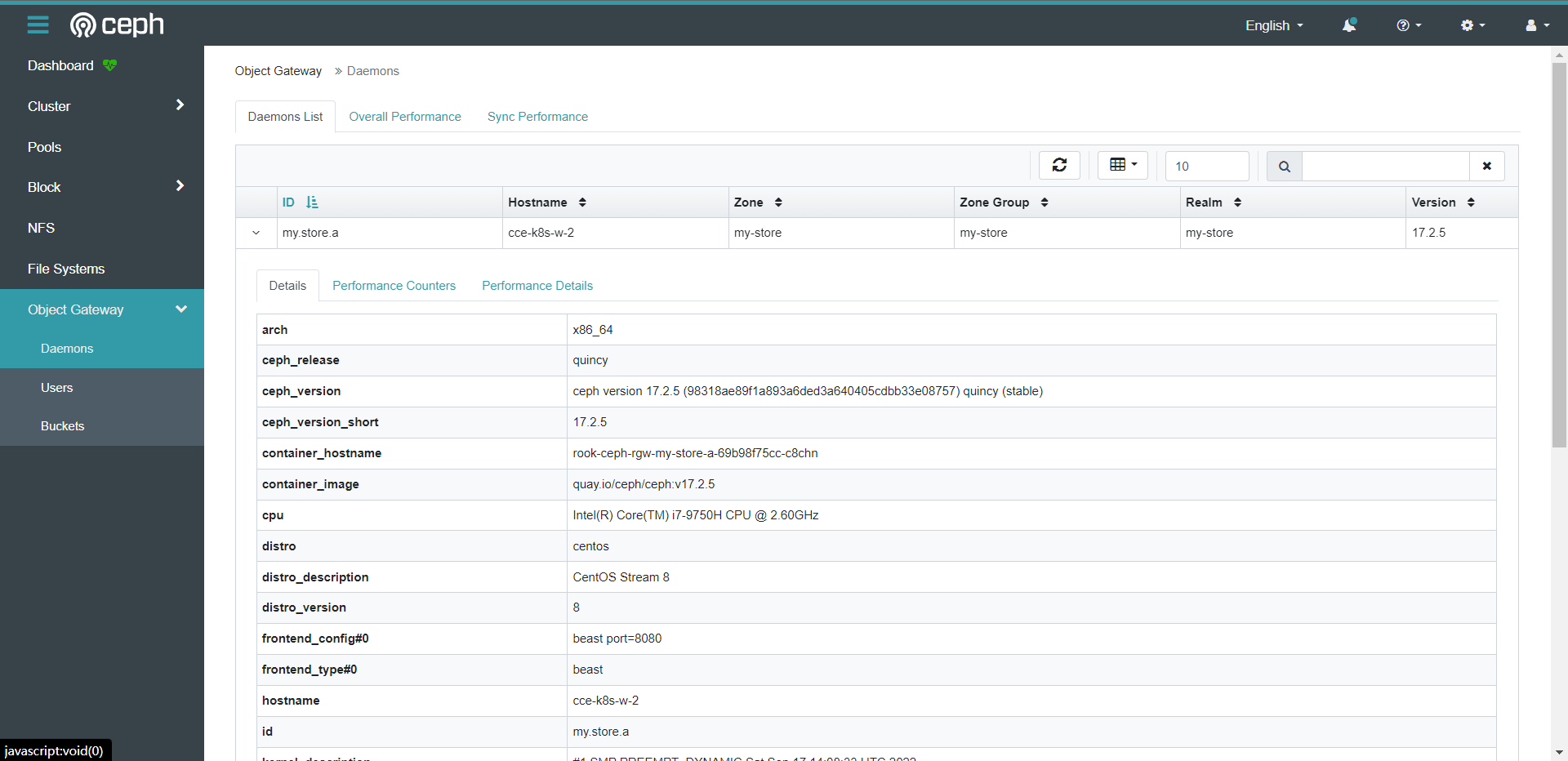
11:Prometheus监控系统
11.1:Prometheus与Ceph
Dashboard 能够提供部分 Ceph 的监控能力,然而如果要更加细化的监控能力和自定义监控则无法实现, prometheus 是新一代的监控系统,能够提供更加完善的监控指标和告警能力,一个完善的 prometheus 系统通常包含:
1:exporter:监控agent端,用于上报,mgr默认已经提供,内置有监控指标
2:promethues:监控服务端,存储监控数据,提供查询,监控,告警,展示等能力;
3:grafana:从prometheus中获取监控指标并通过模版进行展示

11.2:exporters客户端
Rook 默认启用了 exporters 客户端,以 rook-ceph-mgr service的方式提供 9283 端口作为 agent 端,默认是 ClusterIP ,可以启用为 NodePort 给外部访问,如下开启
[root@cce-k8s-m-1 examples]# kubectl -n rook-ceph get svc -l app=rook-ceph-mgr
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
rook-ceph-mgr ClusterIP 10.96.1.168 <none> 9283/TCP 178m
rook-ceph-mgr-dashboard ClusterIP 10.96.1.173 <none> 7000/TCP 178m
# 我们可以通过edit这个svc使其可以在外部回去到Ceph的监控数据
[root@cce-k8s-m-1 examples]# kubectl edit svc -n rook-ceph rook-ceph-mgr
apiVersion: v1
kind: Service
metadata:
creationTimestamp: "2023-04-04T04:42:55Z"
labels:
app: rook-ceph-mgr
ceph_daemon_id: b
rook_cluster: rook-ceph
name: rook-ceph-mgr
namespace: rook-ceph
ownerReferences:
- apiVersion: ceph.rook.io/v1
blockOwnerDeletion: true
controller: true
kind: CephCluster
name: rook-ceph
uid: cdc98920-f581-4acb-a0a1-27a320987d2a
resourceVersion: "39576"
uid: d015099f-880c-4a54-a03a-0ca871dfe33e
spec:
clusterIP: 10.96.1.168
clusterIPs:
- 10.96.1.168
externalTrafficPolicy: Cluster
internalTrafficPolicy: Cluster
ipFamilies:
- IPv4
ipFamilyPolicy: SingleStack
ports:
- name: http-metrics
nodePort: 31976
port: 9283
protocol: TCP
targetPort: 9283
selector:
app: rook-ceph-mgr
ceph_daemon_id: b
rook_cluster: rook-ceph
sessionAffinity: None
type: NodePort
status:
loadBalancer: {}
[root@cce-k8s-m-1 examples]# kubectl get svc -n rook-ceph
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
rook-ceph-mgr ClusterIP 10.96.1.168 <none> 9283/TCP 3h
rook-ceph-mgr-dashboard ClusterIP 10.96.1.173 <none> 7000/TCP 3h
rook-ceph-mon-a ClusterIP 10.96.0.92 <none> 6789/TCP,3300/TCP 3h1m
rook-ceph-mon-b ClusterIP 10.96.2.93 <none> 6789/TCP,3300/TCP 3h
rook-ceph-mon-c ClusterIP 10.96.1.40 <none> 6789/TCP,3300/TCP 3h
rook-ceph-rgw-my-store ClusterIP 10.96.1.169 <none> 80/TCP 52m
[root@cce-k8s-m-1 ~]# cat ceph-metrics-ingress.yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: rook-ceph-metrics
namespace: rook-ceph
spec:
ingressClassName: nginx
rules:
- host: rook-ceph-metrics.kudevops.cn
http:
paths:
- pathType: Prefix
path: /metrics
backend:
service:
name: rook-ceph-mgr
port:
name: http-metrics
[root@cce-k8s-m-1 ~]# kubectl get ingress -n rook-ceph
NAME CLASS HOSTS ADDRESS PORTS AGE
rook-ceph-metrics nginx rook-ceph-metrics.kudevops.cn 80 4s
rook-ceph-mgr-dashboard nginx rook-ceph.kudevops.cn 10.0.0.12 80 99m
[root@cce-k8s-m-1 ~]# kubectl apply -f ceph-metrics-ingress.yaml
ingress.networking.k8s.io/rook-ceph-metrics created
11.3:部署Prometheus Operator
[root@cce-k8s-m-1 monitoring]# kubectl create -f https://raw.githubusercontent.com/coreos/prometheus-operator/v0.64.0/bundle.yaml
customresourcedefinition.apiextensions.k8s.io/alertmanagerconfigs.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/alertmanagers.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/podmonitors.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/probes.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/prometheusagents.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/prometheuses.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/prometheusrules.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/servicemonitors.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/thanosrulers.monitoring.coreos.com created
clusterrolebinding.rbac.authorization.k8s.io/prometheus-operator created
clusterrole.rbac.authorization.k8s.io/prometheus-operator created
deployment.apps/prometheus-operator created
serviceaccount/prometheus-operator created
service/prometheus-operator created
[root@cce-k8s-m-1 monitoring]# kubectl get pod,svc
NAME READY STATUS RESTARTS AGE
pod/prometheus-operator-745b9c6b7f-s46qf 1/1 Running 0 17s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 9h
service/prometheus-operator ClusterIP None <none> 8080/TCP 17s
11.4:部署Prometheus
[root@cce-k8s-m-1 ~]# cd rook/deploy/examples/monitoring/
[root@cce-k8s-m-1 monitoring]# ls
csi-metrics-service-monitor.yaml keda-rgw.yaml prometheus-service.yaml rbac.yaml
externalrules.yaml localrules.yaml prometheus.yaml service-monitor.yaml
[root@cce-k8s-m-1 monitoring]# kubectl apply -f prometheus.yaml
serviceaccount/prometheus created
clusterrole.rbac.authorization.k8s.io/prometheus created
clusterrole.rbac.authorization.k8s.io/prometheus-rules created
clusterrolebinding.rbac.authorization.k8s.io/prometheus created
prometheus.monitoring.coreos.com/rook-prometheus created
[root@cce-k8s-m-1 monitoring]# kubectl apply -f prometheus-service.yaml
service/rook-prometheus created
[root@cce-k8s-m-1 monitoring]# kubectl apply -f service-monitor.yaml
servicemonitor.monitoring.coreos.com/rook-ceph-mgr created
[root@cce-k8s-m-1 monitoring]# kubectl get pod,svc -n rook-ceph
NAME READY STATUS RESTARTS AGE
pod/csi-cephfsplugin-g654n 2/2 Running 2 (69m ago) 9h
pod/csi-cephfsplugin-provisioner-75b9f74d7b-5z57g 5/5 Running 5 (69m ago) 9h
pod/csi-cephfsplugin-provisioner-75b9f74d7b-r58zz 5/5 Running 5 (69m ago) 9h
pod/csi-cephfsplugin-ttw8h 2/2 Running 2 (69m ago) 9h
pod/csi-cephfsplugin-zdqmq 2/2 Running 2 (69m ago) 9h
pod/csi-rbdplugin-4kkp8 2/2 Running 2 (69m ago) 9h
pod/csi-rbdplugin-5cbxq 2/2 Running 2 (69m ago) 9h
pod/csi-rbdplugin-provisioner-66d48ddf89-4dn6n 5/5 Running 5 (69m ago) 9h
pod/csi-rbdplugin-provisioner-66d48ddf89-gr6tb 5/5 Running 5 (69m ago) 9h
pod/csi-rbdplugin-tppmh 2/2 Running 2 (69m ago) 9h
pod/prometheus-rook-prometheus-0 2/2 Running 0 74s
pod/rook-ceph-crashcollector-cce-k8s-m-1-5c977d69f5-fpctk 1/1 Running 1 (69m ago) 8h
pod/rook-ceph-crashcollector-cce-k8s-w-1-5f8979948c-xj22j 1/1 Running 1 (69m ago) 8h
pod/rook-ceph-crashcollector-cce-k8s-w-2-7cdd5bfdf4-bwv2c 1/1 Running 1 (69m ago) 5h34m
pod/rook-ceph-mds-myfs-a-fc84f6679-6x2kp 2/2 Running 2 (69m ago) 8h
pod/rook-ceph-mds-myfs-b-9cd4f99fb-xwctq 2/2 Running 2 (69m ago) 8h
pod/rook-ceph-mgr-a-5f8c5f4d97-rnkq5 3/3 Running 4 (68m ago) 4h2m
pod/rook-ceph-mgr-b-5f547b498-pgt5r 3/3 Running 4 (67m ago) 4h1m
pod/rook-ceph-mon-a-6c9999c8cf-64wlv 2/2 Running 2 (69m ago) 9h
pod/rook-ceph-mon-b-cb878d55-vtvqr 2/2 Running 2 (69m ago) 9h
pod/rook-ceph-mon-c-644cdff6c5-h2l9l 2/2 Running 2 (69m ago) 9h
pod/rook-ceph-operator-cc59dfcb9-dd4hx 1/1 Running 1 (69m ago) 8h
pod/rook-ceph-osd-0-78cf58899c-tkgd6 2/2 Running 2 (69m ago) 9h
pod/rook-ceph-osd-1-65d869f84-5bwfq 2/2 Running 2 (69m ago) 9h
pod/rook-ceph-osd-2-6f5995d478-5qpzr 2/2 Running 2 (69m ago) 9h
pod/rook-ceph-osd-3-879d78967-444lh 2/2 Running 2 (69m ago) 9h
pod/rook-ceph-osd-4-5fc974dbbb-skr8v 2/2 Running 2 (69m ago) 9h
pod/rook-ceph-osd-5-54f5b874cf-6rxfs 2/2 Running 2 (69m ago) 9h
pod/rook-ceph-osd-prepare-cce-k8s-m-1-mfbxv 0/1 Completed 0 66m
pod/rook-ceph-osd-prepare-cce-k8s-w-1-qff8s 0/1 Completed 0 66m
pod/rook-ceph-osd-prepare-cce-k8s-w-2-lwt72 0/1 Completed 0 66m
pod/rook-ceph-tools-54bdbfc7b7-t2vld 1/1 Running 1 (69m ago) 9h
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/prometheus-operated ClusterIP None <none> 9090/TCP 74s
service/rook-ceph-mgr ClusterIP 10.96.1.168 <none> 9283/TCP 9h
service/rook-ceph-mgr-dashboard ClusterIP 10.96.1.173 <none> 7000/TCP 9h
service/rook-ceph-mon-a ClusterIP 10.96.0.92 <none> 6789/TCP,3300/TCP 9h
service/rook-ceph-mon-b ClusterIP 10.96.2.93 <none> 6789/TCP,3300/TCP 9h
service/rook-ceph-mon-c ClusterIP 10.96.1.40 <none> 6789/TCP,3300/TCP 9h
service/rook-prometheus NodePort 10.96.3.152 <none> 9090:30900/TCP 56s
11.5:Prometheus控制台
访问svc或者可以用ingress暴露出去可以直接访问到Prometheus了
11.6:安装grafana服务端
prometheus 将 exporter 上报的监控数据进行统一的存储,在 prometheus 中可以通过 PromSQL 查询监控数据并进行数据的展示, prometheus 提供了比较简陋的图形界面,这些图形界面显然无法满足到日常实际的需求,幸运的是, grafana 是这方面的高手,因此我们通过 grafana 进行数据的展示, grafana 支持将prometheus做为一个后端进行展示,如下是安装的方法:
[root@cce-k8s-m-1 monitoring]# yum install -y https://mirrors.tuna.tsinghua.edu.cn/grafana/yum/rpm/Packages/grafana-9.4.7-1.x86_64.rpm
[root@cce-k8s-m-1 monitoring]# systemctl enable grafana-server --now
Synchronizing state of grafana-server.service with SysV service script with /usr/lib/systemd/systemd-sysv-install.
Executing: /usr/lib/systemd/systemd-sysv-install enable grafana-server
Created symlink /etc/systemd/system/multi-user.target.wants/grafana-server.service → /usr/lib/systemd/system/grafana-server.service.
[root@cce-k8s-m-1 monitoring]# ss -lnt | grep 3000
LISTEN 0 4096 *:3000 *:*
11.7:配置grafana数据源
grafana 是一个数据展示的开源工具,其数据需要依托于后端的数据源(Data Sources),因此需要配置数据源,以便更好和 grafana 进行集成,如下是配置 prometheus 和 grafana 进行集成,需要 prometheus 的 9090 端口
账号:admin
密码:admin
11.8:配置Grafana展板
grafana 如何展示 prometheus 的数据呢?需要编写 PromSQL 实现和 prometheus 集成,幸好已经有很多定义好的 json 模版,我们直接使用即可,下载 json 后将其 import 到 grafana 中
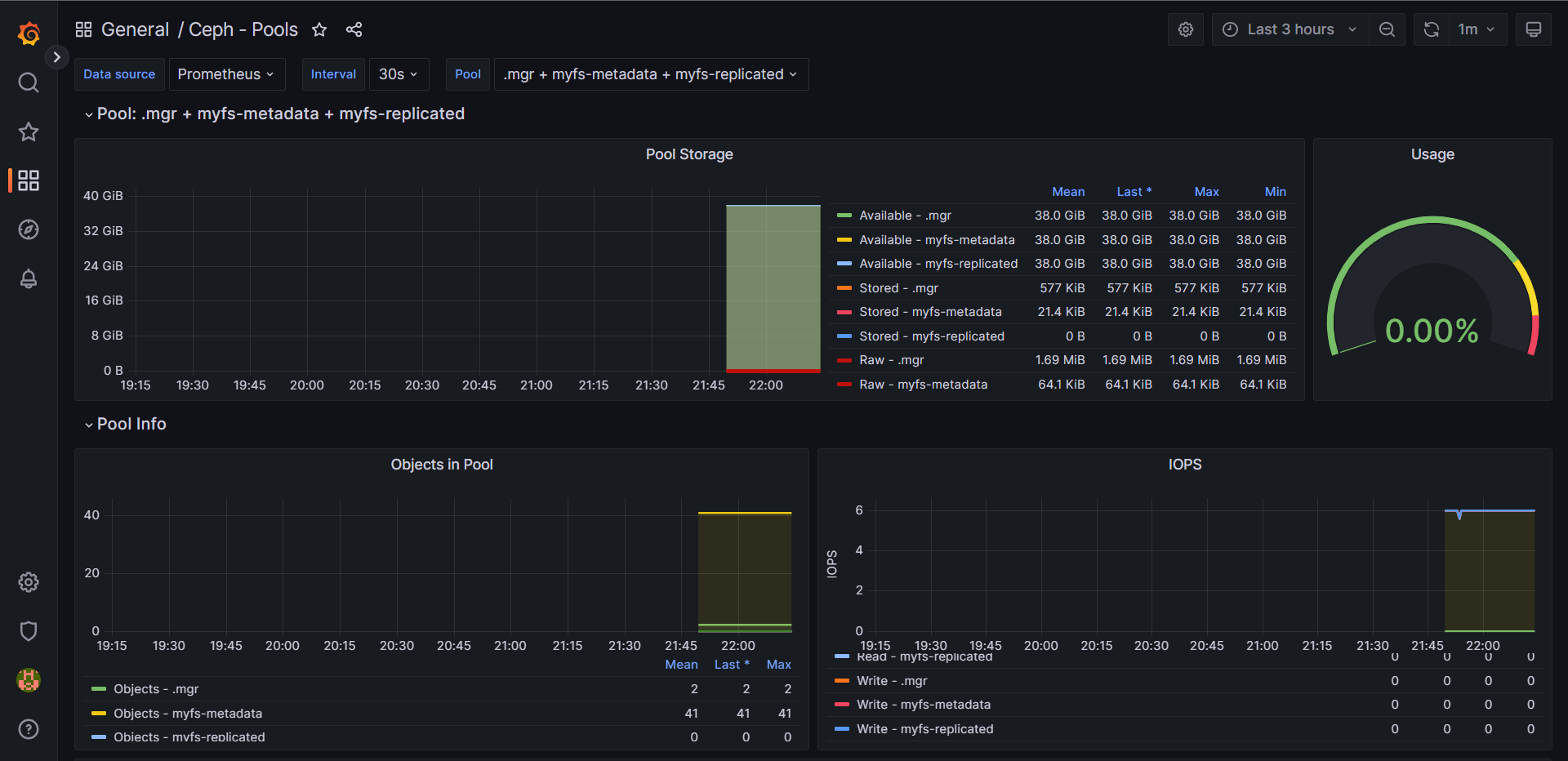
11.9:配置Prometheus Alerts
[root@cce-k8s-m-1 monitoring]# kubectl apply -f rbac.yaml
role.rbac.authorization.k8s.io/rook-ceph-monitor created
rolebinding.rbac.authorization.k8s.io/rook-ceph-monitor created
role.rbac.authorization.k8s.io/rook-ceph-metrics created
rolebinding.rbac.authorization.k8s.io/rook-ceph-metrics created
role.rbac.authorization.k8s.io/rook-ceph-monitor-mgr created
rolebinding.rbac.authorization.k8s.io/rook-ceph-monitor-mgr created
[root@cce-k8s-m-1 monitoring]# vim ../cluster.yaml
apiVersion: ceph.rook.io/v1
kind: CephCluster
metadata:
name: rook-ceph
namespace: rook-ceph
[...]
spec:
[...]
monitoring:
enabled: true # 启动配置,默认为 false
rulesNamespace: "rook-ceph"
[...]
[root@cce-k8s-m-1 monitoring]# kubectl apply -f localrules.yaml
prometheusrule.monitoring.coreos.com/prometheus-ceph-rules created
# 配置完成后,打开 prometheus 的控制台即可看到 alter 相关的告警,如下
12:容器存储扩缩容
12.1:云原生存储扩容
容器的容量的不足的时候需要对容器的存储空间进行扩容, Rook 默认提供了两种驱动:
1:RBD
2:CephFS
这两种驱动通过 StorageClass 存储供给者为容器提供存储空间,同时已经自动扩容的能力,其流程为:
客户端通过 PVC 声明的方式向 StorageClass 申请扩容容量空间,通过驱动调整 PV 的容量,调整底层的 RBD 像块容量,最终达到容量的扩展,如下是操作过程:
[root@cce-k8s-m-1 monitoring]# cd ../
[root@cce-k8s-m-1 examples]# kubectl apply -f mysql.yaml
service/wordpress-mysql created
persistentvolumeclaim/mysql-pv-claim created
deployment.apps/wordpress-mysql created
[root@cce-k8s-m-1 examples]# kubectl get pv,pvc
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
persistentvolume/pvc-... 20Gi RWO Delete Bound default/mysql-pv-claim rook-cephfs 44s
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
persistentvolumeclaim/mysql-... Bound pvc-31b8fe4d-3cee-442b-b55b-8d8923a9cf72 20Gi RWO rook-cephfs 45s
[root@cce-k8s-m-1 examples]# cat mysql.yaml
apiVersion: v1
kind: Service
metadata:
name: wordpress-mysql
labels:
app: wordpress
spec:
ports:
- port: 3306
selector:
app: wordpress
tier: mysql
clusterIP: None
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: mysql-pv-claim
labels:
app: wordpress
spec:
storageClassName: rook-cephfs
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 30Gi
---
......
# 更新资源清单
[root@cce-k8s-m-1 examples]# kubectl apply -f mysql.yaml
service/wordpress-mysql unchanged
persistentvolumeclaim/mysql-pv-claim configured
deployment.apps/wordpress-mysql unchanged
[root@cce-k8s-m-1 examples]# kubectl get pv,pvc
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
persistentvolume/pvc-31b... 30Gi RWO Delete Bound default/mysql-pv-claim rook-cephfs 3h23m
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
persistentvolumeclaim/mysql-... Bound pvc-31b8fe4d-3cee-442b-b55b-8d8923a9cf72 30Gi RWO rook-cephfs 3h23m
# 可以看到已经扩容到了30G了,查看一下容器内的存储大小
[root@cce-k8s-m-1 examples]# kubectl exec -it wordpress-mysql-6f99c59595-895bn -- df -Th
Filesystem Type Size Used Avail Use% Mounted on
overlay overlay 17G 8.1G 9.0G 48% /
tmpfs tmpfs 64M 0 64M 0% /dev
/dev/mapper/cs-root xfs 17G 8.1G 9.0G 48% /etc/hosts
shm tmpfs 64M 0 64M 0% /dev/shm
10.96.0.92:6789,10.96.2.93:6789,10.96.1.40:6789:/volumes/csi/csi-vol-00cee7d1-d2f5-11ed-bfce-0a700b708e03/b490e28f-3789-4e83-9c6f-c137a3d27547 ceph 30G 112M 30G 1% /var/lib/mysql
tmpfs tmpfs 3.5G 12K 3.5G 1% /run/secrets/kubernetes.io/serviceaccount
tmpfs tmpfs 1.8G 0 1.8G 0% /proc/acpi
tmpfs tmpfs 1.8G 0 1.8G 0% /proc/scsi
tmpfs tmpfs 1.8G 0 1.8G 0% /sys/firmware
# 可以看到存储也是30G了
12.2:RBD块扩容原理
# PVC —> PV —> RBD 块 —> 文件系统扩容
# 查看 PV 对应 RBD 块容量
[root@cce-k8s-m-1 examples]# kubectl get pv pvc-c7740a06-df1d-4c23-bf3b-4a79d024f9fc -o yaml
apiVersion: v1
kind: PersistentVolume
metadata:
annotations:
pv.kubernetes.io/provisioned-by: rook-ceph.rbd.csi.ceph.com
volume.kubernetes.io/provisioner-deletion-secret-name: rook-csi-rbd-provisioner
volume.kubernetes.io/provisioner-deletion-secret-namespace: rook-ceph
creationTimestamp: "2023-04-04T18:00:54Z"
finalizers:
- kubernetes.io/pv-protection
name: pvc-c7740a06-df1d-4c23-bf3b-4a79d024f9fc
resourceVersion: "117698"
uid: 10402b2b-cd8f-4ca5-8bad-dd8dd40ea0c4
spec:
accessModes:
- ReadWriteOnce
capacity:
storage: 30Gi
claimRef:
apiVersion: v1
kind: PersistentVolumeClaim
name: mysql-pv-claim
namespace: default
resourceVersion: "117681"
uid: c7740a06-df1d-4c23-bf3b-4a79d024f9fc
csi:
controllerExpandSecretRef:
name: rook-csi-rbd-provisioner
namespace: rook-ceph
driver: rook-ceph.rbd.csi.ceph.com
fsType: ext4
nodeStageSecretRef:
name: rook-csi-rbd-node
namespace: rook-ceph
volumeAttributes:
clusterID: rook-ceph
imageFeatures: layering
imageFormat: "2"
imageName: csi-vol-a4a7b890-d312-11ed-8457-b6ca8b376104 # PV 对应的 RBD 块
journalPool: replicapool # RBD 块所在的 pool
pool: replicapool
storage.kubernetes.io/csiProvisionerIdentity: 1680612058363-8081-rook-ceph.rbd.csi.ceph.com
volumeHandle: 0001-0009-rook-ceph-000000000000000d-a4a7b890-d312-11ed-8457-b6ca8b376104
persistentVolumeReclaimPolicy: Delete
storageClassName: rook-ceph-block
volumeMode: Filesystem
status:
phase: Bound
# 查看 RBD 块大小
[root@cce-k8s-m-1 examples]# rbd -p replicapool info csi-vol-a4a7b890-d312-11ed-8457-b6ca8b376104
rbd image 'csi-vol-a4a7b890-d312-11ed-8457-b6ca8b376104':
size 30 GiB in 7680 objects
order 22 (4 MiB objects)
snapshot_count: 0
id: 1121597d1eef6
block_name_prefix: rbd_data.1121597d1eef6
format: 2
features: layering
op_features:
flags:
create_timestamp: Wed Apr 5 02:00:54 2023
access_timestamp: Wed Apr 5 02:00:54 2023
modify_timestamp: Wed Apr 5 02:00:54 2023
# 容器内部磁盘空间查看
[root@cce-k8s-m-1 examples]# kubectl exec -it wordpress-mysql-6f99c59595-hfq7q -- df -h
Filesystem Size Used Avail Use% Mounted on
overlay 17G 8.1G 9.0G 48% /
tmpfs 64M 0 64M 0% /dev
/dev/mapper/cs-root 17G 8.1G 9.0G 48% /etc/hosts
shm 64M 0 64M 0% /dev/shm
/dev/rbd0 30G 116M 30G 1% /var/lib/mysql
tmpfs 3.5G 12K 3.5G 1% /run/secrets/kubernetes.io/serviceaccount
tmpfs 1.8G 0 1.8G 0% /proc/acpi
tmpfs 1.8G 0 1.8G 0% /proc/scsi
tmpfs 1.8G 0 1.8G 0% /sys/firmware
# 扩容 RBD 镜像块容量大小
[root@cce-k8s-m-1 examples]# rbd -p replicapool resize csi-vol-a4a7b890-d312-11ed-8457-b6ca8b376104 --size 40G
Resizing image: 100% complete...done.
[root@cce-k8s-m-1 examples]# rbd -p replicapool info csi-vol-a4a7b890-d312-11ed-8457-b6ca8b376104
rbd image 'csi-vol-a4a7b890-d312-11ed-8457-b6ca8b376104':
size 40 GiB in 10240 objects
order 22 (4 MiB objects)
snapshot_count: 0
id: 1121597d1eef6
block_name_prefix: rbd_data.1121597d1eef6
format: 2
features: layering
op_features:
flags:
create_timestamp: Wed Apr 5 02:00:54 2023
access_timestamp: Wed Apr 5 02:00:54 2023
modify_timestamp: Wed Apr 5 02:00:54 2023
# 查看 PVC/PV 大小是否扩容
[root@cce-k8s-m-1 examples]# kubectl get pv,pvc
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
persistentvolume/pvc-... 30Gi RWO Delete Bound default/mysql-pv-claim rook-ceph-block 5m2s
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
persistentvolumeclaim/mysql-... Bound pvc-c7740a06-df1d-4c23-bf3b-4a79d024f9fc 30Gi RWO rook-ceph-block 5m2s
# 登陆容器所在宿主机,扩容文件系统的容量
[root@cce-k8s-m-1 examples]# kubectl get pod -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
prometheus-operator-745b9c6b7f-s46qf 1/1 Running 0 4h27m 100.101.104.168 cce-k8s-w-2 <none> <none>
wordpress-mysql-6f99c59595-hfq7q 1/1 Running 0 6m48s 100.118.108.209 cce-k8s-w-1 <none> <none>
[root@cce-k8s-w-1 ~]# rbd showmapped
id pool namespace image snap device
0 replicapool csi-vol-a4a7b890-d312-11ed-8457-b6ca8b376104 - /dev/rbd0
[root@cce-k8s-w-1 ~]# df -h | grep pvc-c7740a06-df1d-4c23-bf3b-4a79d024f9fc
/dev/rbd0 30G 116M 30G 1% /var/lib/kubelet/pods/36ae784d-5f75-4123-84e1-27174cfe6cfc/volumes/kubernetes.io~csi/pvc-c7740a06-df1d-4c23-bf3b-4a79d024f9fc/mount
[root@cce-k8s-w-1 ~]# df -h | grep pvc-c7740a06-df1d-4c23-bf3b-4a79d024f9fc | awk '{print $1}'
/dev/rbd0
[root@cce-k8s-w-1 ~]# resize2fs /dev/rbd0
resize2fs 1.46.5 (30-Dec-2021)
Filesystem at /dev/rbd0 is mounted on /var/lib/kubelet/plugins/kubernetes.io/csi/rook-ceph.rbd.csi.ceph.com/f50ce3b26dd2c62f281e30d83d0ed62f6dc99bbc0f35f00d0642a44cd1671fe5/globalmount/0001-0009-rook-ceph-000000000000000d-a4a7b890-d312-11ed-8457-b6ca8b376104; on-line resizing required
old_desc_blocks = 4, new_desc_blocks = 5
The filesystem on /dev/rbd0 is now 10485760 (4k) blocks long.
# 查看校验存储容量扩展情况
[root@cce-k8s-w-1 ~]# df -h | grep pvc-c7740a06-df1d-4c23-bf3b-4a79d024f9fc
/dev/rbd0 40G 116M 40G 1% /var/lib/kubelet/pods/36ae784d-5f75-4123-84e1-27174cfe6cfc/volumes/kubernetes.io~csi/pvc-c7740a06-df1d-4c23-bf3b-4a79d024f9fc/mount
# 再次去查看容器,可以看到扩容上来了
[root@cce-k8s-m-1 examples]# kubectl exec -it wordpress-mysql-6f99c59595-hfq7q -- df -h
Filesystem Size Used Avail Use% Mounted on
overlay 17G 8.2G 8.8G 49% /
tmpfs 64M 0 64M 0% /dev
/dev/mapper/cs-root 17G 8.2G 8.8G 49% /etc/hosts
shm 64M 0 64M 0% /dev/shm
/dev/rbd0 40G 116M 40G 1% /var/lib/mysql
tmpfs 3.5G 12K 3.5G 1% /run/secrets/kubernetes.io/serviceaccount
tmpfs 1.8G 0 1.8G 0% /proc/acpi
tmpfs 1.8G 0 1.8G 0% /proc/scsi
tmpfs 1.8G 0 1.8G 0% /sys/firmware
# 遗留问题:PVC/PV 信息没有扩容
[root@cce-k8s-m-1 examples]# kubectl get pv,pvc
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
persistentvolume/pvc- 30Gi RWO Delete Bound default/mysql-pv-claim rook-ceph-block 12m
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
per.../mysql-pv-claim Bound pvc-c7740a06-df1d-4c23-bf3b-4a79d024f9fc 30Gi RWO rook-ceph-block 12m

 浙公网安备 33010602011771号
浙公网安备 33010602011771号