
前面我们学习了Prometheus自定义的方式来对Kubernetes集群进行监控,基本上能够完成监控告警的需求了,但是实际对上Kubernetes来说,还有更简单的方式来监控告警,那就是Prometheus-Operator,Prometheus Operator为监控Kubernetes资源和Prometheus实例的管理提供了简单的定义,简化在Kubernetes上部署,管理和运行Prometheus和Alertmanager集群。
官网:https://prometheus-operator.dev/
Github:https://github.com/prometheus-operator
但是我们其实可以看到,我们虽然说的是prometheus-operator,但实际上我们去部署的时候还是部署的kube-prometheus这个项目。然后使用prometheus-operator来管理它,使用CRD资源的方式为kube-prometheus创建资源。
1:概述
Prometheus-Operator为Kubernetes提供了对Prometheus机器相关监控租金的本地部署和管理方案,该项目的目的是为了简化自动化基于Prometheus的监控栈配置,主要包括如下几个功能:
1:kubernetes自定义资源:使用Kubernetes CRD来部署和管理Prometheus,Alertmanager和相关组件。
2:简化的部署配置:直接通过kubernetes清单配置Prometheus,比如版本、持久化、副本、保留策略等等配置。
3:prometheus监控目标配置:基于悉知的kubernetes标签查询自动生成监控目标配置,无需学习Prometheus特定的配置。
架构图如下:
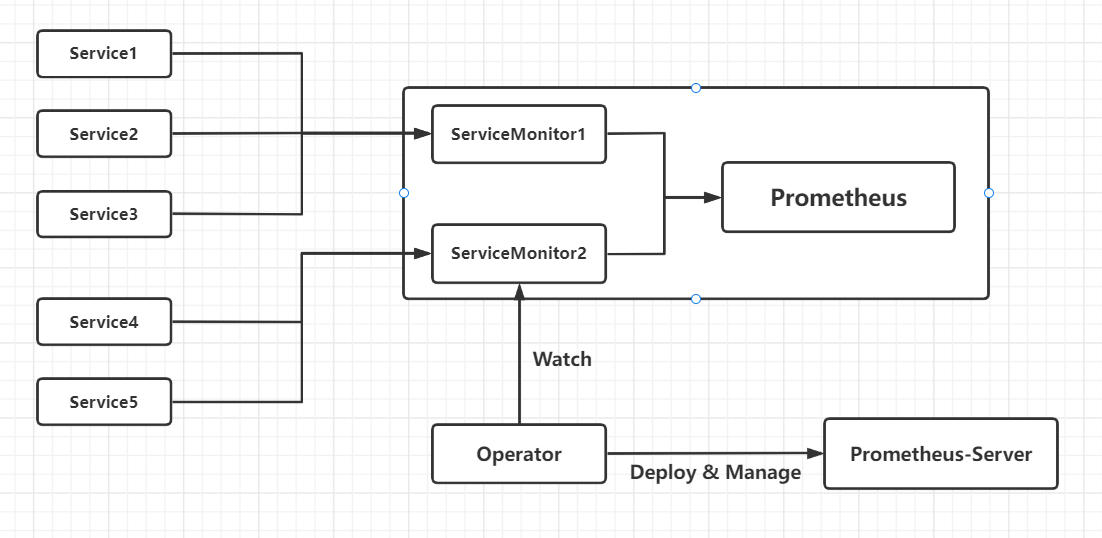
上图是大致的一个Prometheus Operator的一个架构图,各组件以不同的方式运行在Kubernetes集群中,其中Operator是最核心的部分,作为一个控制器,他会去创建Promtheus,ServiceMonitor,Alertmanager以及PrometheusRule等CRD资源对象,然后会一直Watch并维持这些资源对象的状态。
在新版本Operator中提供了以下几个CRD资源对象:
1:Prometheus
2:Alertmanager
3:ServiceMonitor
4:PodMonitor
5:Probe
6:ThanosRuler
7:PrometheusRule
8:AlertmanagerConfig
1.1:Prometheus
该CRD声明定义了Prometheus期望在Kubernetes集群中运行的配置,提供了配置选项来配置副本,持久化,报警实例等。
对于每个Prometheus CRD资源,Operator都会从Statefulset形式在相同的命名空间下部署对应的配置的资源,Prometheus Pod的配置是通过一个包含Prometheus配置的名称为<prometheus-name>的Secret对象声明挂载的,
该CRD根据标签选择来指定部署的Prometheus实例应该覆盖哪儿些ServiceMonitors,然后Operator会根据包含的ServiceMonitor生成配置,并包含配置的Secret中进行更新。
如果未提供对ServiceMonitor的选择,则Operator会将Secret的管理留给用户,这样就可以提供自定义配置,同时还享受Operator管理Operator的设置能力
1.2:Alertmanager
该CRD定义了在Kubernetes集群中运行的Alertmanager的配置,同样提供了多种配置,包括持久化存储。
对于每个Alertmanager资源,Operator都会在命名空间下部署一个对应配置的Statefulset,Alertmanager Pods被配置为包含一个名为<alertmanager-name>的Secret,该Secret以alertmanager.yaml为key的方式保存使用的配置文件。
当有两个或更多的副本时,Operator会在高可用模式下运行Alertmanager实例。
1.3:ThanosRuler
该CRD定义了一个ThanosRuler组件的配置,以便在Kubernetes集群中运行,通过ThanosRuler,可以跨多个Prometheus实例处理记录和警报规则。
一个Thanos Ruler实例至少需要一个queryEndpoint,它指向Thanos Queriers或Prometheus实例的位置,queryEndpoint用于配置Thanos运行时的--query参数,更多信息可以在 `https://thanos.io`文档中找到
1.4:ServiceMonitor
该CRD定义了如何监控一组动态的服务,使用标签选择来定义哪儿些Service被选择进行监控,这可以让团队制定一个如何暴露监控指标的规范,然后按照这些规范自动发现新的服务,而无需重新配置。
为了让Prometheus监控Kubernetes内的任何应用,需要存在一个Endpoints对象,Endpoints对上本质上时IP地址列表,通常Endpoints对象是由Service对象来自动填充的,Service对象通过标签选择器匹配Pod,并将其添加到Endpoints对象中,一个Service可以暴露一个或多个端口,这些端口由多个Endpoint列表支持,这些端点一般情况下都指向一个Pod。
Prometheus Operator引入这个ServiceMonitor对象就会发现这些Endpoints对象,并配置Prometheus监控这些Pod,ServiceMonitorSpec的endpoints部分就是用于配置这些Endpoints的哪儿些端口将被scrape指标的。
#注:endpoints(小写)是ServiceMonitor CRD中的字段,而Endpoints(大写)是Kubernetes的一种对象。
ServiceMonitors以及被发现的目标都可以来自任何命名空间,对于允许跨命名空间监控的场景非常重要,使用PrometheusSpec的ServiceMonitorNamespaceSelector,可以限制各自的Prometheus服务器选择ServiceMonitors的命名空间,使用ServiceMonitorSpec的namespaceSelector,可以限制Endpoints对象被允许从哪儿些命名空间中发现,要在所有命名空间中发现目标,namespaceSelector必须为空。
spec:
namespaceSelector:
any: true
1.5:PodMonitor
该CRD用于定义如何监控一组动态Pods,使用标签选择来定义哪儿些Pods被选择进行监控,同样团队中可以制定一些规范来暴露监控的指标。
Pod是一个或多个容器的集合,可以在一些端口上暴露Prometheus指标。
由Prometheus Operator引入的PodMonitor对象会发现这些Pod,并为Prometheus服务器生成相关配置,以便监控它们。
PodMonitorSpec中的PodMonitorEndpoints部分,用于配置Pod的哪儿些端口将被scrape指标,以及使用哪儿些参数。
PodMonitors和发现的目标可以来自任何命名空间,这样对于允许跨命名空间的监控用例是非常重要的,使用PodMonitorSpec的namespaceSelector,可以限制Pod允许发现的命名空间,要在所有的命名空间中发现目标,namespaceSelector必须为空。
spec:
namespaceSelector:
any: true
PodMonitor和ServiceMonitor最大的区别就是不需要对应的Service
1.6:Probe
该CRD用于定义如何监控一组Ingress和静态目标,除了Target之外,Probe对象还需要一个prober,它是监控的目标并为Prometheus提供指标和服务,例如可以通过使用blackbox-exporter来提供这个服务。
1.7:PrometheusRule
用于配置Prometheus的Rule规则文件,包括recording rules和alerting,可以自动被Prometheus加载。
1.8:AlertmanagerConfig
在以前的版本中需要配置Alertmanager都是通过ConfigMap来完成,在v0.43版本后新增该CRD,可以将Alertmanager的配置分割成不同的子对象进行配置,允许将报警路由到自定义的Receiver上,并配置抑制规则。
AlertmanagerConfig可以在命名空间级别上定义,不过这个CRD貌似目前好像不太稳定。
总之这样我们需要在集群中监控什么数据,就变成了直接去操作Kubernetes集群的资源对象了,这样比以前手动的方式更加方便很多。
2:安装
为了使用Prometheus-Operator,这里我们直接使用kube-prometheus这个项目进行安装,该项目和Prometheus-Operator的区别就类似Linux内核和CentOS这些发行版的关系,其实其实就是Operator依赖Kube-prometheus这个项目运行,真正起作用的是Operator,而kube-prometheus只是利用Operator编写了一系列常用的监控资源清单,不过需要注意Kubernetes版本和kube-prometheus的兼容:
这里我的集群是1.23.8,所以我们使用0.10或者0.11版本都是可以的。
当然了,这里其实是有一个kube-prometheus的Helm Charts来使用的进行快速安装的。也可以直接手动安装。
https://prometheus-community.github.io/helm-charts/
但是我们这里不用helm去装,我们用手动的方式去安装。
首先Clone代码到本地,我这里选择 release-0.11
[root@kubernetes-master-1 ~]# git clone https://github.com/prometheus-operator/kube-prometheus.git
正克隆到 'kube-prometheus'...
remote: Enumerating objects: 16896, done.
remote: Counting objects: 100% (20/20), done.
remote: Compressing objects: 100% (19/19), done.
remote: Total 16896 (delta 6), reused 1 (delta 0), pack-reused 16876
接收对象中: 100% (16896/16896), 8.55 MiB | 1.56 MiB/s, done.
处理 delta 中: 100% (11002/11002), done.
[root@kubernetes-master-1 ~]# cd kube-prometheus/
[root@kubernetes-master-1 kube-prometheus]# git branch -a
* main
remotes/origin/HEAD -> origin/main
remotes/origin/automated-updates-main
remotes/origin/main
remotes/origin/release-0.1
remotes/origin/release-0.10
remotes/origin/release-0.11
remotes/origin/release-0.2
remotes/origin/release-0.3
remotes/origin/release-0.4
remotes/origin/release-0.5
remotes/origin/release-0.6
remotes/origin/release-0.7
remotes/origin/release-0.8
remotes/origin/release-0.9
# 切换分支
[root@kubernetes-master-1 kube-prometheus]# git checkout release-0.11
# 首先创建需要的命名空间和CRDs资源,等待它们创建好后再创建其他资源。
[root@kubernetes-master-1 kube-prometheus]# kubectl apply -f manifests/setup/
[root@kubernetes-master-1 kube-prometheus]# kubectl apply -f manifests/setup/
customresourcedefinition.apiextensions.k8s.io/alertmanagerconfigs.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/alertmanagers.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/podmonitors.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/probes.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/prometheusrules.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/servicemonitors.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/thanosrulers.monitoring.coreos.com created
namespace/monitoring created
The CustomResourceDefinition "prometheuses.monitoring.coreos.com" is invalid: metadata.annotations: Too long: must have at most 262144 bytes
出现上面的问题的时候其实很简单,我们将apply换成create就OK了
[root@kubernetes-master-1 kube-prometheus]# kubectl create -f manifests/setup/
customresourcedefinition.apiextensions.k8s.io/prometheuses.monitoring.coreos.com created
......
[root@kubernetes-master-1 kube-prometheus]# kubectl get ns
NAME STATUS AGE
......
monitoring Active 105s
# 这个名称空间就是上面的yaml帮我们创建的
[root@kubernetes-master-1 kube-prometheus]# kubectl get crd | grep coreos
alertmanagerconfigs.monitoring.coreos.com 2022-09-13T17:19:19Z
alertmanagers.monitoring.coreos.com 2022-09-13T17:19:19Z
podmonitors.monitoring.coreos.com 2022-09-13T17:19:20Z
probes.monitoring.coreos.com 2022-09-13T17:19:20Z
prometheuses.monitoring.coreos.com 2022-09-13T17:20:31Z
prometheusrules.monitoring.coreos.com 2022-09-13T17:19:20Z
servicemonitors.monitoring.coreos.com 2022-09-13T17:19:20Z
thanosrulers.monitoring.coreos.com 2022-09-13T17:19:20Z
这就是我们的CRD资源,有了这些我们才可以去创建如Kind: Prometheus的资源,这样我们的CRD就安装好了,下面我们需要去安装控制器,也就是Operator
这个大家注意下,这个可能需要魔法上网的哈。
下面我们为了方便测试,我们将Alertmanager的service和Grafana的service还有Prometheus的service都改成了NodePort方式,默认是ClusterIP
[root@kubernetes-master-1 kube-prometheus]# vim manifests/grafana-service.yaml
[root@kubernetes-master-1 kube-prometheus]# vim manifests/alertmanager-service.yaml
[root@kubernetes-master-1 kube-prometheus]# vim manifests/prometheus-service.yaml
# 这个操作是只是为了我们方便而已。
# 部署
[root@kubernetes-master-1 kube-prometheus]# kubectl apply -f manifests/
# 需要静等几分钟
[root@kubernetes-master-1 kube-prometheus]# kubectl get pod -n monitoring
NAME READY STATUS RESTARTS AGE
alertmanager-main-0 2/2 Running 0 77s
alertmanager-main-1 2/2 Running 0 77s
alertmanager-main-2 2/2 Running 0 77s
blackbox-exporter-746c64fd88-9wvhn 3/3 Running 0 84s
grafana-5fc7f9f55d-j547n 1/1 Running 0 84s
kube-state-metrics-6c8846558c-z7nq9 3/3 Running 0 83s
node-exporter-b24ft 2/2 Running 0 83s
node-exporter-rjtbw 2/2 Running 0 83s
prometheus-adapter-6455646bdc-c566n 1/1 Running 0 83s
prometheus-adapter-6455646bdc-l7ws8 1/1 Running 0 83s
prometheus-k8s-0 1/2 Running 0 76s
prometheus-k8s-1 1/2 Running 0 76s
prometheus-operator-f59c8b954-h8rxg 2/2 Running 0 83s
[root@kubernetes-master-1 kube-prometheus]# kubectl get svc -n monitoring
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
alertmanager-main NodePort 20.1.141.235 <none> 9093:31146/TCP,8080:31307/TCP 7m54s
alertmanager-operated ClusterIP None <none> 9093/TCP,9094/TCP,9094/UDP 5m26s
blackbox-exporter ClusterIP 20.1.76.150 <none> 9115/TCP,19115/TCP 7m54s
grafana NodePort 20.1.208.9 <none> 3000:32337/TCP 7m53s
kube-state-metrics ClusterIP None <none> 8443/TCP,9443/TCP 7m53s
node-exporter ClusterIP None <none> 9100/TCP 7m53s
prometheus-adapter ClusterIP 20.1.191.253 <none> 443/TCP 7m52s
prometheus-k8s NodePort 20.1.166.83 <none> 9090:31404/TCP,8080:31369/TCP 7m52s
prometheus-operated ClusterIP None <none> 9090/TCP 5m25s
prometheus-operator ClusterIP None <none> 8443/TCP 7m52s
访问测试:
这里我们可以看到的东西是非常多的,因为绝大多数都是它自带的,就是我们Apply的时候那么多的东西。
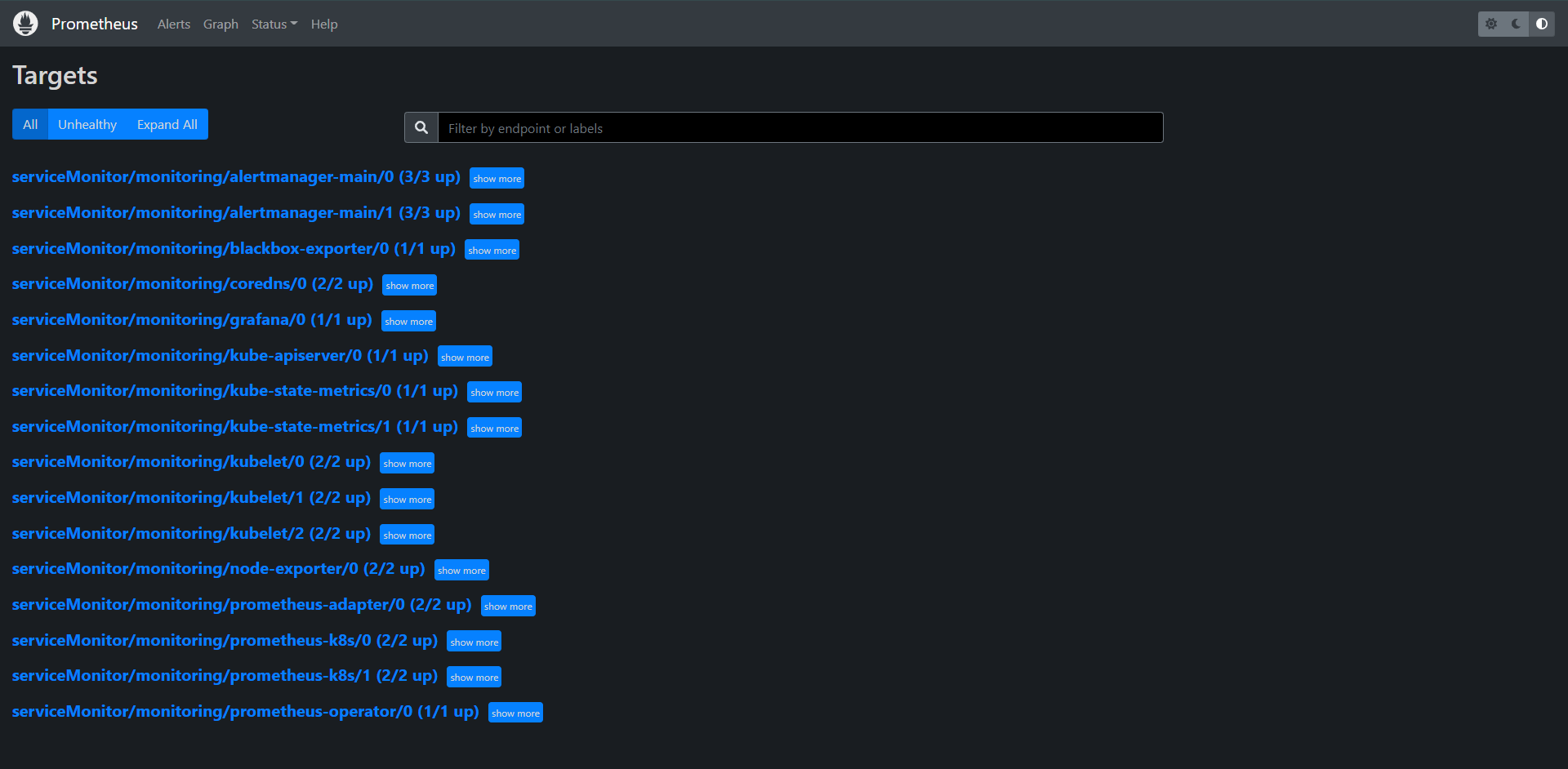
甚至抓取配置都已经帮我们配置好了,都是自动添加进去的,我们去维护或者新增,我们只需要去创建ServiceMonitor就可以了。
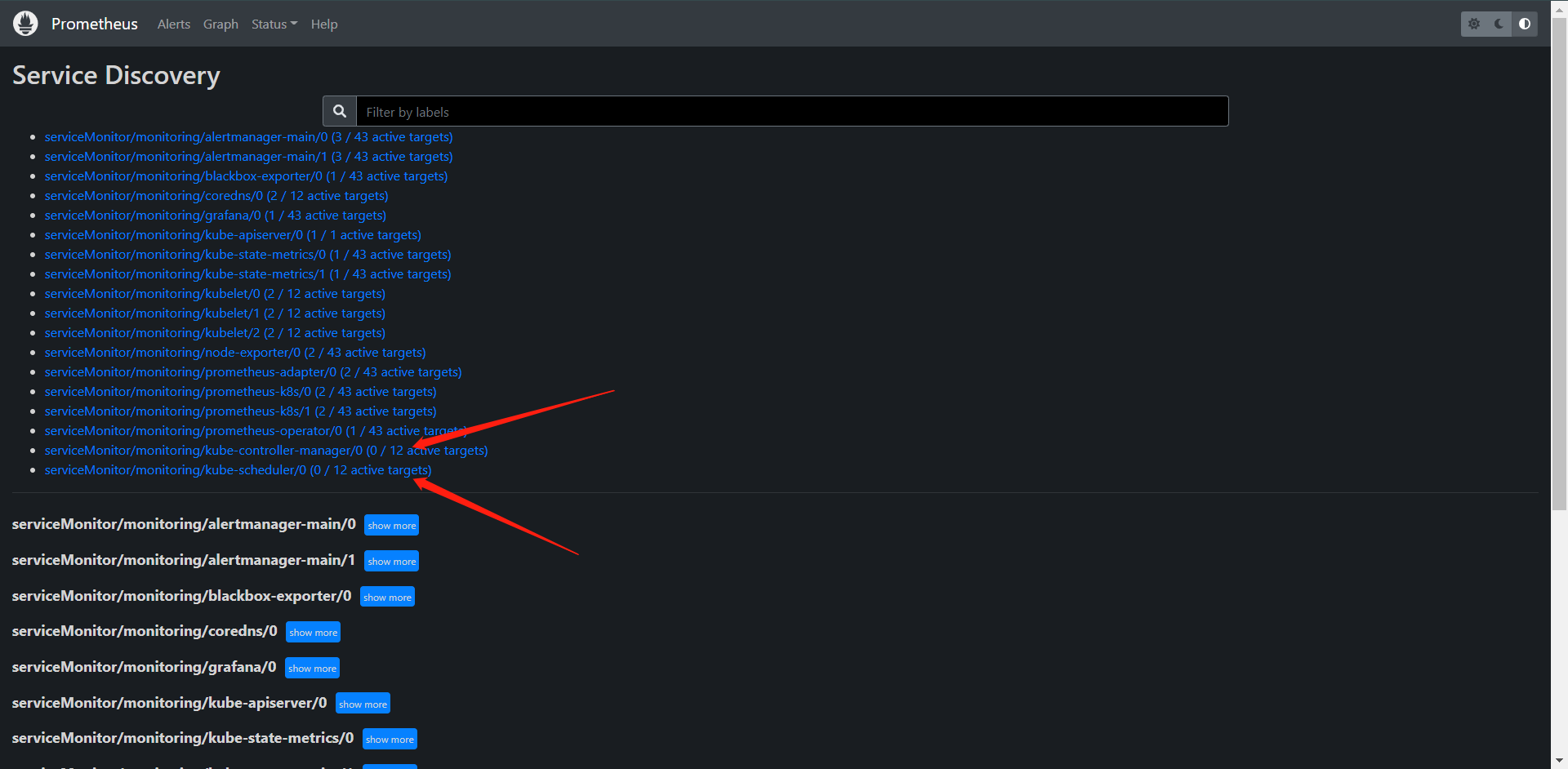
去看Service Discovery的时候发现有两个组件没有,这个原因其实就是因为它这个ServiceMonitor是去匹配的标签我们的那两个组件是没有的,我们可以看看它们的yaml
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
labels:
app.kubernetes.io/name: kube-scheduler
app.kubernetes.io/part-of: kube-prometheus
name: kube-scheduler
namespace: monitoring
spec:
endpoints:
- bearerTokenFile: /var/run/secrets/kubernetes.io/serviceaccount/token
interval: 30s
port: https-metrics
scheme: https
tlsConfig:
insecureSkipVerify: true
jobLabel: app.kubernetes.io/name
namespaceSelector:
matchNames:
- kube-system
selector:
matchLabels:
app.kubernetes.io/name: kube-scheduler
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
labels:
app.kubernetes.io/name: kube-controller-manager
app.kubernetes.io/part-of: kube-prometheus
name: kube-controller-manager
namespace: monitoring
spec:
endpoints:
- bearerTokenFile: /var/run/secrets/kubernetes.io/serviceaccount/token
interval: 30s
metricRelabelings:
- action: drop
regex: kubelet_(pod_worker_latency_microseconds|pod_start_latency_microseconds|cgroup_manager_latency_microseconds|pod_worker_start_latency_microseconds|pleg_relist_latency_microseconds|pleg_relist_interval_microseconds|runtime_operations|runtime_operations_latency_microseconds|runtime_operations_errors|eviction_stats_age_microseconds|device_plugin_registration_count|device_plugin_alloc_latency_microseconds|network_plugin_operations_latency_microseconds)
sourceLabels:
- __name__
- action: drop
regex: scheduler_(e2e_scheduling_latency_microseconds|scheduling_algorithm_predicate_evaluation|scheduling_algorithm_priority_evaluation|scheduling_algorithm_preemption_evaluation|scheduling_algorithm_latency_microseconds|binding_latency_microseconds|scheduling_latency_seconds)
sourceLabels:
- __name__
- action: drop
regex: apiserver_(request_count|request_latencies|request_latencies_summary|dropped_requests|storage_data_key_generation_latencies_microseconds|storage_transformation_failures_total|storage_transformation_latencies_microseconds|proxy_tunnel_sync_latency_secs|longrunning_gauge|registered_watchers)
sourceLabels:
- __name__
- action: drop
regex: kubelet_docker_(operations|operations_latency_microseconds|operations_errors|operations_timeout)
sourceLabels:
- __name__
- action: drop
regex: reflector_(items_per_list|items_per_watch|list_duration_seconds|lists_total|short_watches_total|watch_duration_seconds|watches_total)
sourceLabels:
- __name__
- action: drop
regex: etcd_(helper_cache_hit_count|helper_cache_miss_count|helper_cache_entry_count|object_counts|request_cache_get_latencies_summary|request_cache_add_latencies_summary|request_latencies_summary)
sourceLabels:
- __name__
- action: drop
regex: transformation_(transformation_latencies_microseconds|failures_total)
sourceLabels:
- __name__
- action: drop
regex: (admission_quota_controller_adds|admission_quota_controller_depth|admission_quota_controller_longest_running_processor_microseconds|admission_quota_controller_queue_latency|admission_quota_controller_unfinished_work_seconds|admission_quota_controller_work_duration|APIServiceOpenAPIAggregationControllerQueue1_adds|APIServiceOpenAPIAggregationControllerQueue1_depth|APIServiceOpenAPIAggregationControllerQueue1_longest_running_processor_microseconds|APIServiceOpenAPIAggregationControllerQueue1_queue_latency|APIServiceOpenAPIAggregationControllerQueue1_retries|APIServiceOpenAPIAggregationControllerQueue1_unfinished_work_seconds|APIServiceOpenAPIAggregationControllerQueue1_work_duration|APIServiceRegistrationController_adds|APIServiceRegistrationController_depth|APIServiceRegistrationController_longest_running_processor_microseconds|APIServiceRegistrationController_queue_latency|APIServiceRegistrationController_retries|APIServiceRegistrationController_unfinished_work_seconds|APIServiceRegistrationController_work_duration|autoregister_adds|autoregister_depth|autoregister_longest_running_processor_microseconds|autoregister_queue_latency|autoregister_retries|autoregister_unfinished_work_seconds|autoregister_work_duration|AvailableConditionController_adds|AvailableConditionController_depth|AvailableConditionController_longest_running_processor_microseconds|AvailableConditionController_queue_latency|AvailableConditionController_retries|AvailableConditionController_unfinished_work_seconds|AvailableConditionController_work_duration|crd_autoregistration_controller_adds|crd_autoregistration_controller_depth|crd_autoregistration_controller_longest_running_processor_microseconds|crd_autoregistration_controller_queue_latency|crd_autoregistration_controller_retries|crd_autoregistration_controller_unfinished_work_seconds|crd_autoregistration_controller_work_duration|crdEstablishing_adds|crdEstablishing_depth|crdEstablishing_longest_running_processor_microseconds|crdEstablishing_queue_latency|crdEstablishing_retries|crdEstablishing_unfinished_work_seconds|crdEstablishing_work_duration|crd_finalizer_adds|crd_finalizer_depth|crd_finalizer_longest_running_processor_microseconds|crd_finalizer_queue_latency|crd_finalizer_retries|crd_finalizer_unfinished_work_seconds|crd_finalizer_work_duration|crd_naming_condition_controller_adds|crd_naming_condition_controller_depth|crd_naming_condition_controller_longest_running_processor_microseconds|crd_naming_condition_controller_queue_latency|crd_naming_condition_controller_retries|crd_naming_condition_controller_unfinished_work_seconds|crd_naming_condition_controller_work_duration|crd_openapi_controller_adds|crd_openapi_controller_depth|crd_openapi_controller_longest_running_processor_microseconds|crd_openapi_controller_queue_latency|crd_openapi_controller_retries|crd_openapi_controller_unfinished_work_seconds|crd_openapi_controller_work_duration|DiscoveryController_adds|DiscoveryController_depth|DiscoveryController_longest_running_processor_microseconds|DiscoveryController_queue_latency|DiscoveryController_retries|DiscoveryController_unfinished_work_seconds|DiscoveryController_work_duration|kubeproxy_sync_proxy_rules_latency_microseconds|non_structural_schema_condition_controller_adds|non_structural_schema_condition_controller_depth|non_structural_schema_condition_controller_longest_running_processor_microseconds|non_structural_schema_condition_controller_queue_latency|non_structural_schema_condition_controller_retries|non_structural_schema_condition_controller_unfinished_work_seconds|non_structural_schema_condition_controller_work_duration|rest_client_request_latency_seconds|storage_operation_errors_total|storage_operation_status_count)
sourceLabels:
- __name__
- action: drop
regex: etcd_(debugging|disk|request|server).*
sourceLabels:
- __name__
port: https-metrics
scheme: https
tlsConfig:
insecureSkipVerify: true
jobLabel: app.kubernetes.io/name
namespaceSelector:
matchNames:
- kube-system
selector:
matchLabels:
app.kubernetes.io/name: kube-controller-manager
仔细观察我们会发现它们都是去匹配的label,然后我们再观察一下它们是否有这个标签呢?
[root@kubernetes-master-1 kube-prometheus]# kubectl get service -n kube-system -l app.kubernetes.io/name=kube-controller-manager
No resources found in kube-system namespace.
[root@kubernetes-master-1 kube-prometheus]# kubectl get service -n kube-system -l app.kubernetes.io/name=kube-scheduler
No resources found in kube-system namespace.
我们会发现压根就没有,所以我们只需要创建一下这两个组件的Service就OK了
# 获取Label
[root@kubernetes-master-1 kube-prometheus]# kubectl get pods -n kube-system kube-scheduler-kubernetes-master-1 --show-labels
NAME READY STATUS RESTARTS AGE LABELS
kube-scheduler-kubernetes-master-1 1/1 Running 0 128m component=kube-scheduler,tier=control-plane
apiVersion: v1
kind: Service
metadata:
name: kube-scheduler
namespace: kube-system
labels:
app.kubernetes.io/name: kube-scheduler # 这里的标签是必须和上面的ServiceMonitor匹配的标签一致的。
spec:
selector:
component: kube-scheduler
ports:
- name: https-metrics
port: 10259
targetPort: 10259 # 现版本默认安全端口是10259
[root@kubernetes-master-1 kube-prometheus]# kubectl get pods -n kube-system kube-controller-manager-kubernetes-master-1 -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
kube-controller-manager-kubernetes-master-1 1/1 Running 0 129m 10.0.0.11 kubernetes-master-1 <none> <none>
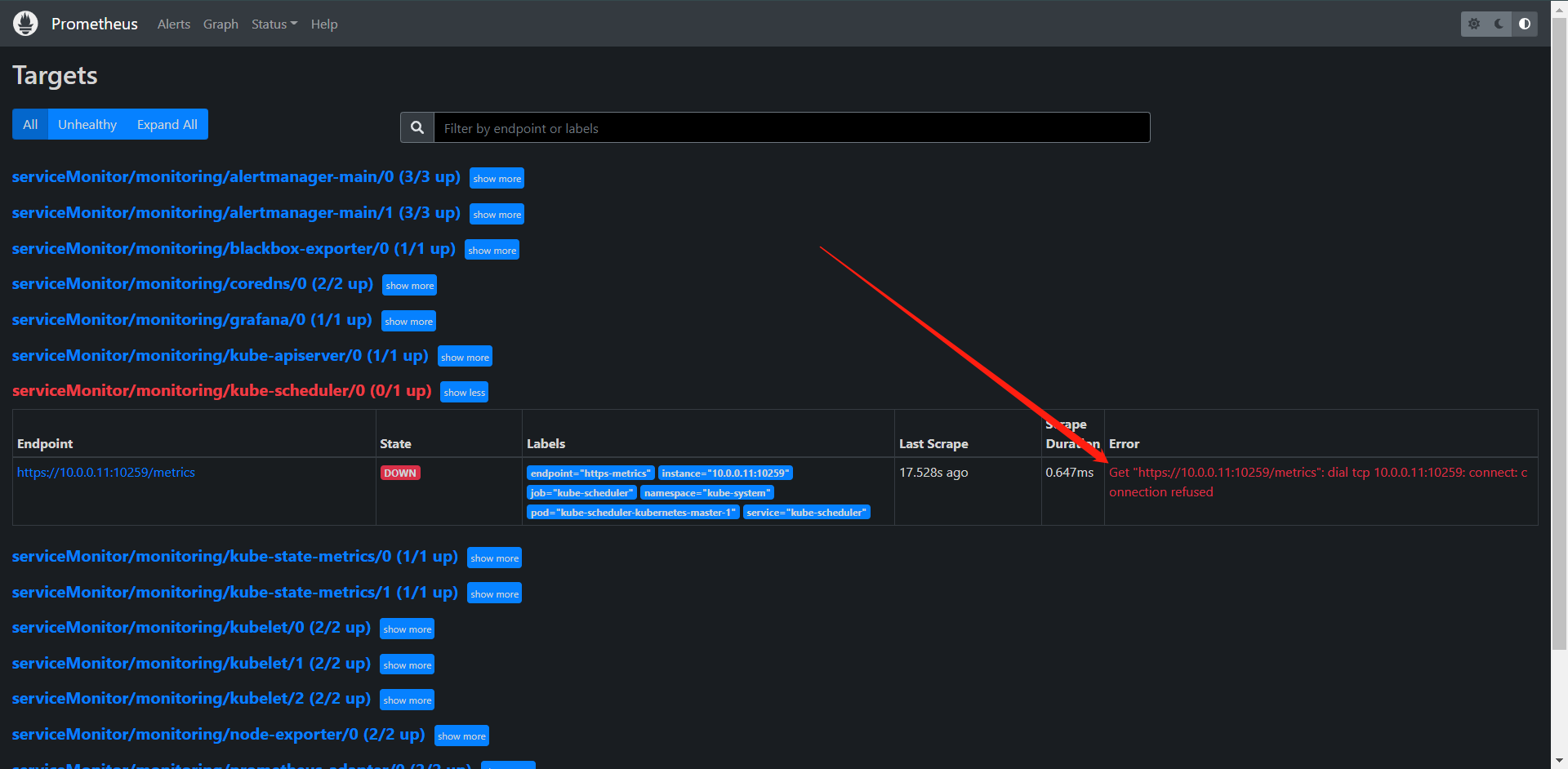
这里我们发现有是有了,但是去请求的是否发现连接被拒绝了,当然这个其实也简单,这个原因是因为scheduler默认绑定的是127.0.0.1的ip,我们需要进行修改。
这个可以在master的/etc/kubernetes/manifests下的yaml改,改完我们也不需要操作,它会自动重启的。
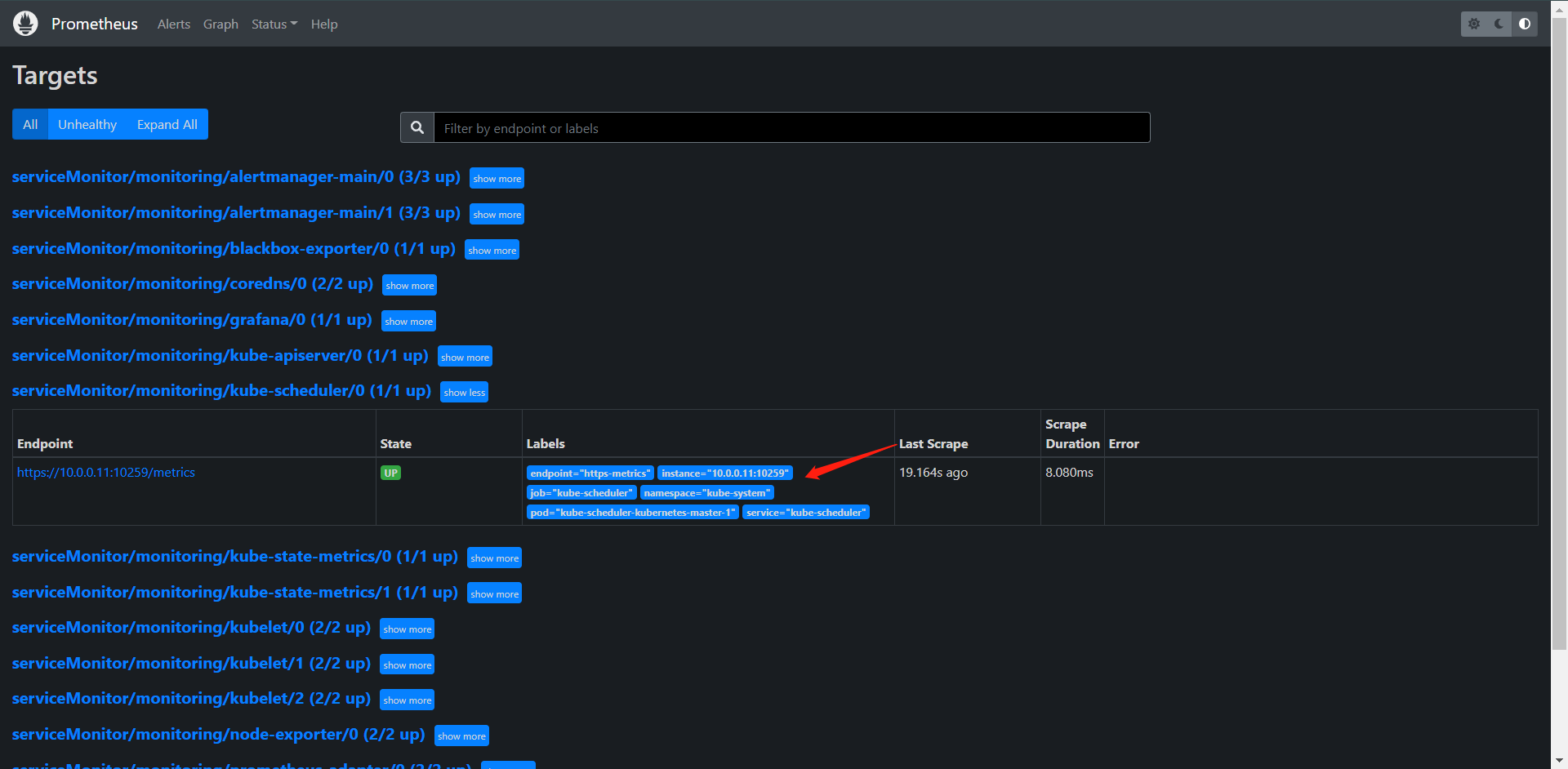
这样就已经监控上kube-scheduler了,照葫芦画瓢,把kube-controller也搞出来,它也是需要改IP的哈
apiVersion: v1
kind: Service
metadata:
name: kube-controller-manager
namespace: kube-system
labels:
app.kubernetes.io/name: kube-controller-manager
spec:
selector:
component: kube-controller-manager
ports:
- name: https-metrics
port: 10257
targetPort: 10257
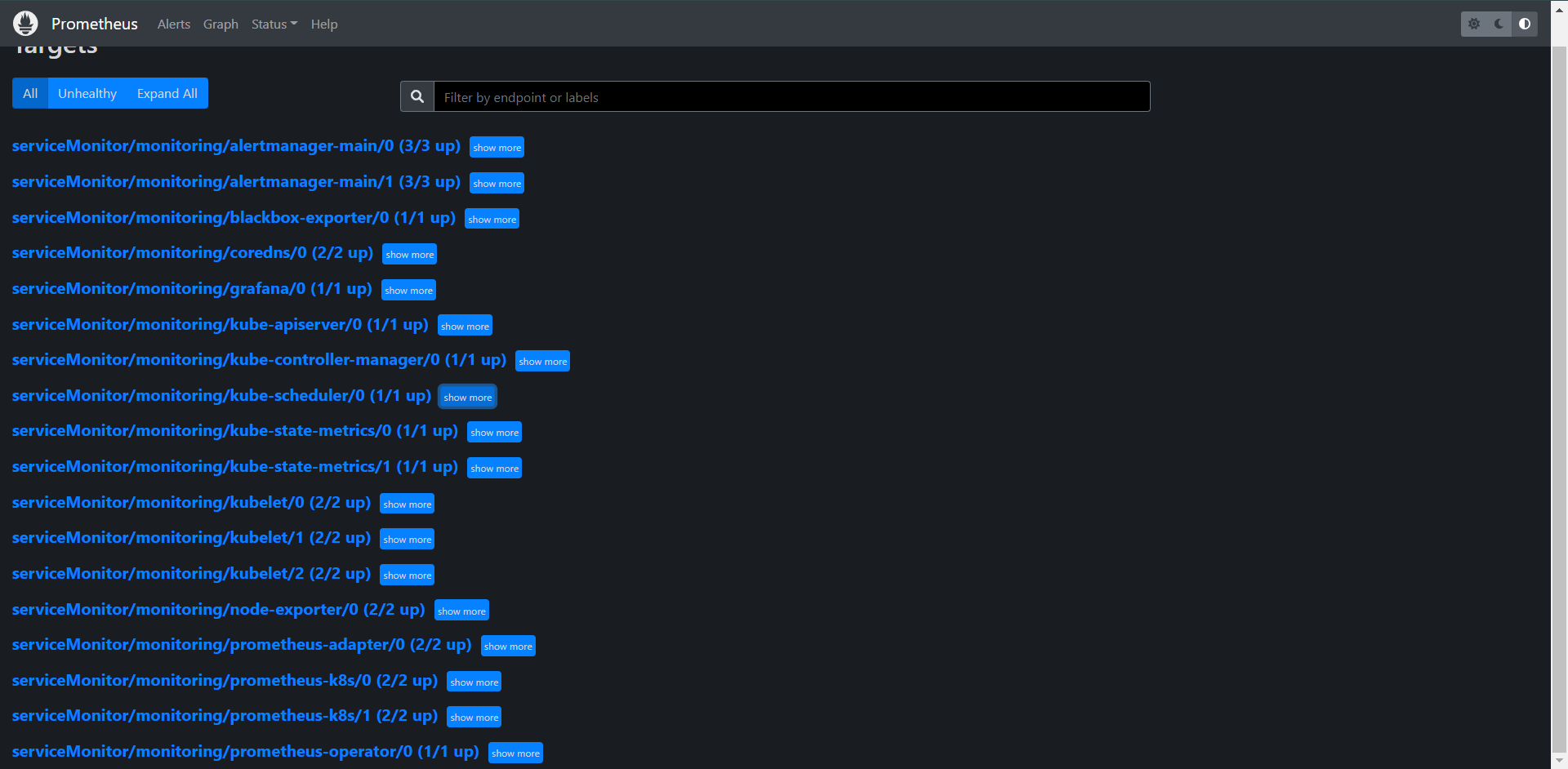
这样监控就基本上部署好了,还有就是这里的Grafana,它帮我们已经集成了很多的Dashboard面板了
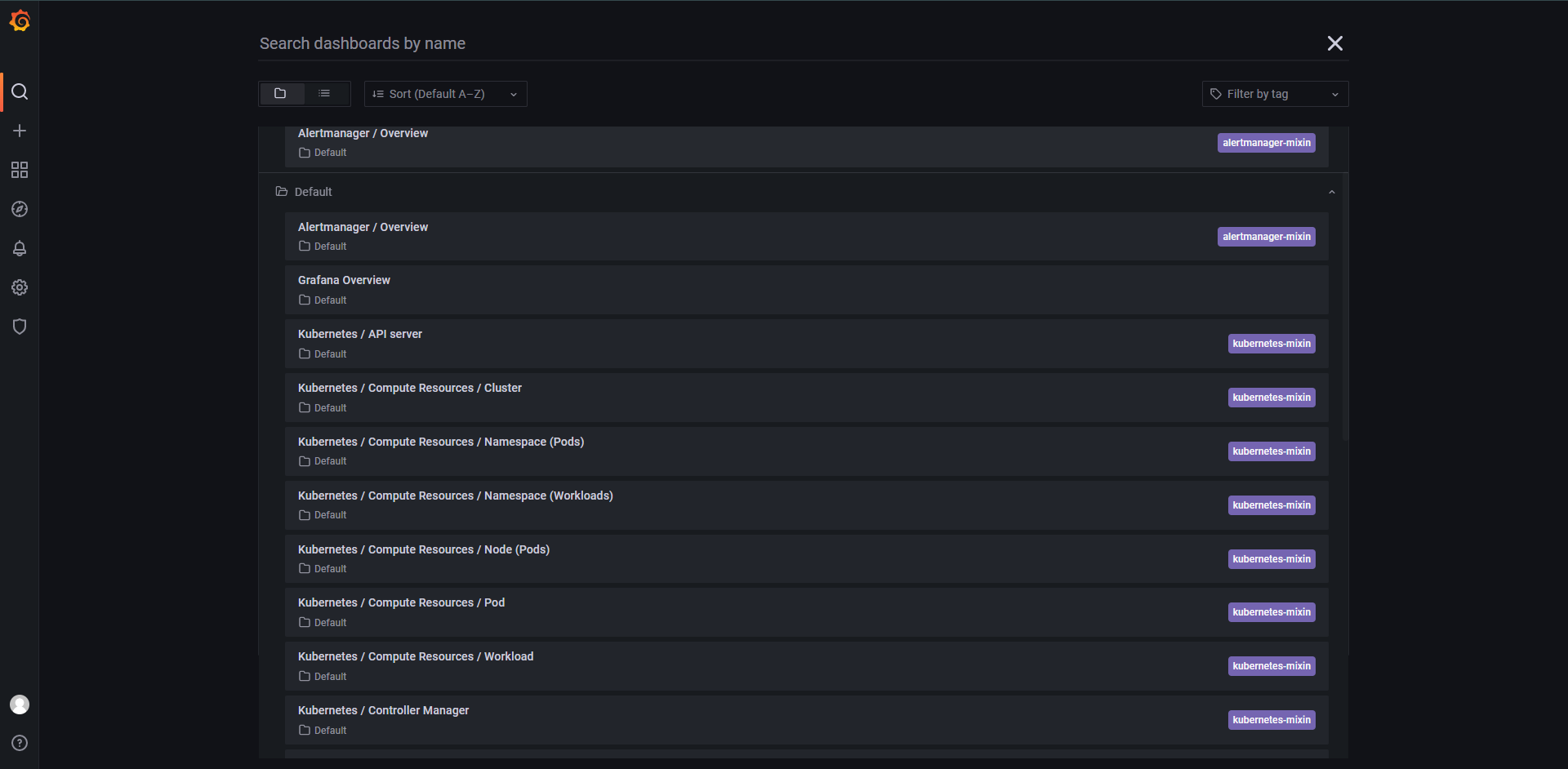
基本上就是开箱即用。
3:使用Operator自定义监控
上面基本上是我们使用Prometheus Operator的基本使用,这里主要来看我们如何使用Operator去自定义监控数据。
除了Kubernetes集群的一些对象,节点及组件需要监控,有的时候我们还可能需要根据实际业务需求去添加自定义监控项,当然添加一个自定义监控项的步骤也非常的简单:
1:建立一个ServiceMonitor对象,用于Prometheus添加监控项
2:为ServiceMonitor对象关联metrics数据接口的一个Service对象
3:确保Service对象可以正确获取到Metrics接口的数据
接下来我们来看看如何添加etcd集群的监控,无论是Kubernetes集群外还是使用kubeadm安装在集群内的etcd集群我们这里都将其视为外置集群,因为这两者的监控方式没有什么不同。
我这里是kubeadm,所以我们可以通过kubectl来获取一些需要的参数
[root@kubernetes-master-1 kube-prometheus]# kubectl get pods -n kube-system -l component=etcd
NAME READY STATUS RESTARTS AGE
etcd-kubernetes-master-1 1/1 Running 0 3h37m
[root@kubernetes-master-1 kube-prometheus]# kubectl get pods -n kube-system etcd-kubernetes-master-1 -oyaml
......
spec:
containers:
- command:
- etcd
- --advertise-client-urls=https://10.0.0.11:2379
- --cert-file=/etc/kubernetes/pki/etcd/server.crt
- --client-cert-auth=true
- --data-dir=/var/lib/etcd
- --experimental-initial-corrupt-check=true
- --initial-advertise-peer-urls=https://10.0.0.11:2380
- --initial-cluster=kubernetes-master-1=https://10.0.0.11:2380
- --key-file=/etc/kubernetes/pki/etcd/server.key
- --listen-client-urls=https://127.0.0.1:2379,https://10.0.0.11:2379
- --listen-metrics-urls=http://127.0.0.1:2381 # 我们可以看到这里有一个metrics的接口,但是它监听的是127.0.0.1,所以我们需要改一下
- --listen-peer-urls=https://10.0.0.11:2380
- --name=kubernetes-master-1
- --peer-cert-file=/etc/kubernetes/pki/etcd/peer.crt
- --peer-client-cert-auth=true
- --peer-key-file=/etc/kubernetes/pki/etcd/peer.key
- --peer-trusted-ca-file=/etc/kubernetes/pki/etcd/ca.crt
- --snapshot-count=10000
- --trusted-ca-file=/etc/kubernetes/pki/etcd/ca.crt
image: registry.aliyuncs.com/google_containers/etcd:3.5.1-0
imagePullPolicy: IfNotPresent
......
# 我们修改它的监听然后去关联service就OK了
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: etcd
namespace: monitoring
labels:
app: etcd
spec:
jobLabel: app
endpoints:
- port: port
interval: 15s
selector:
matchLabels:
app: etcd
namespaceSelector:
matchNames:
- kube-system
---
apiVersion: v1
kind: Service
metadata:
name: etcd
namespace: kube-system
labels:
app: etcd
spec:
type: ClusterIP
clusterIP: None
ports:
- name: port
port: 2381
---
apiVersion: v1
kind: Endpoints
metadata:
name: etcd
namespace: kube-system
labels:
app: etcd
subsets:
- addresses:
- ip: 10.0.0.11
nodeName: kubernetes-master-1
ports:
- name: port
port: 2381
[root@kubernetes-master-1 kube-prometheus]# kubectl apply -f manifests/kubernetesControlPlane-serviceMonitorEtcd.yaml
servicemonitor.monitoring.coreos.com/etcd created
service/etcd created
endpoints/etcd created
这样只能证明我们创建好了,But,我们看看现在是什么情况
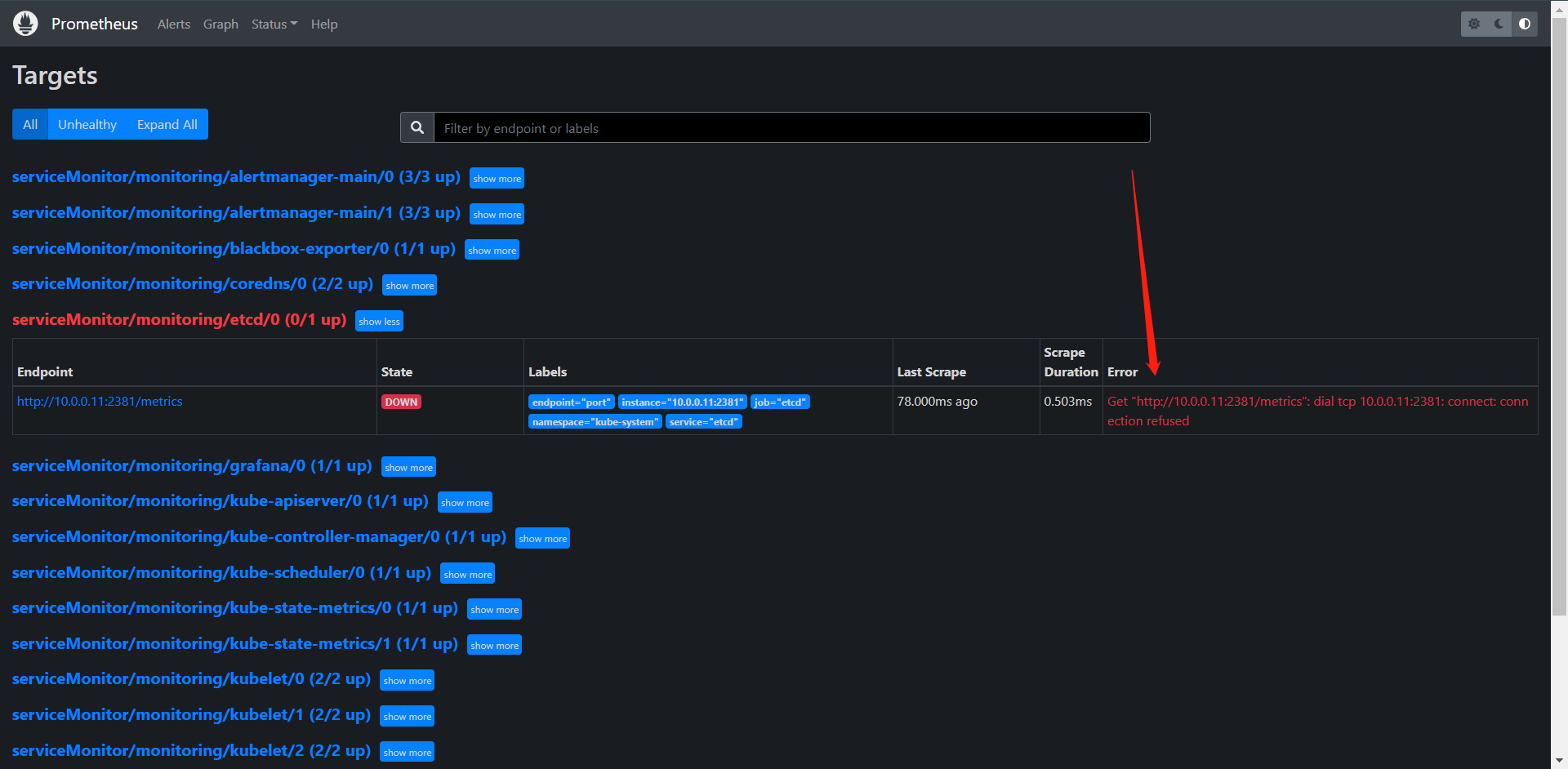
这个我们在前面也讲了,因为它的自带的metrics接口只允许本地访问,所以我们还是去改一下。
[root@kubernetes-master-1 kube-prometheus]# cat /etc/kubernetes/manifests/etcd.yaml | grep metrics
- --listen-metrics-urls=http://0.0.0.0:2381
# 这样搞完集群会有一定的时间无法使用哦
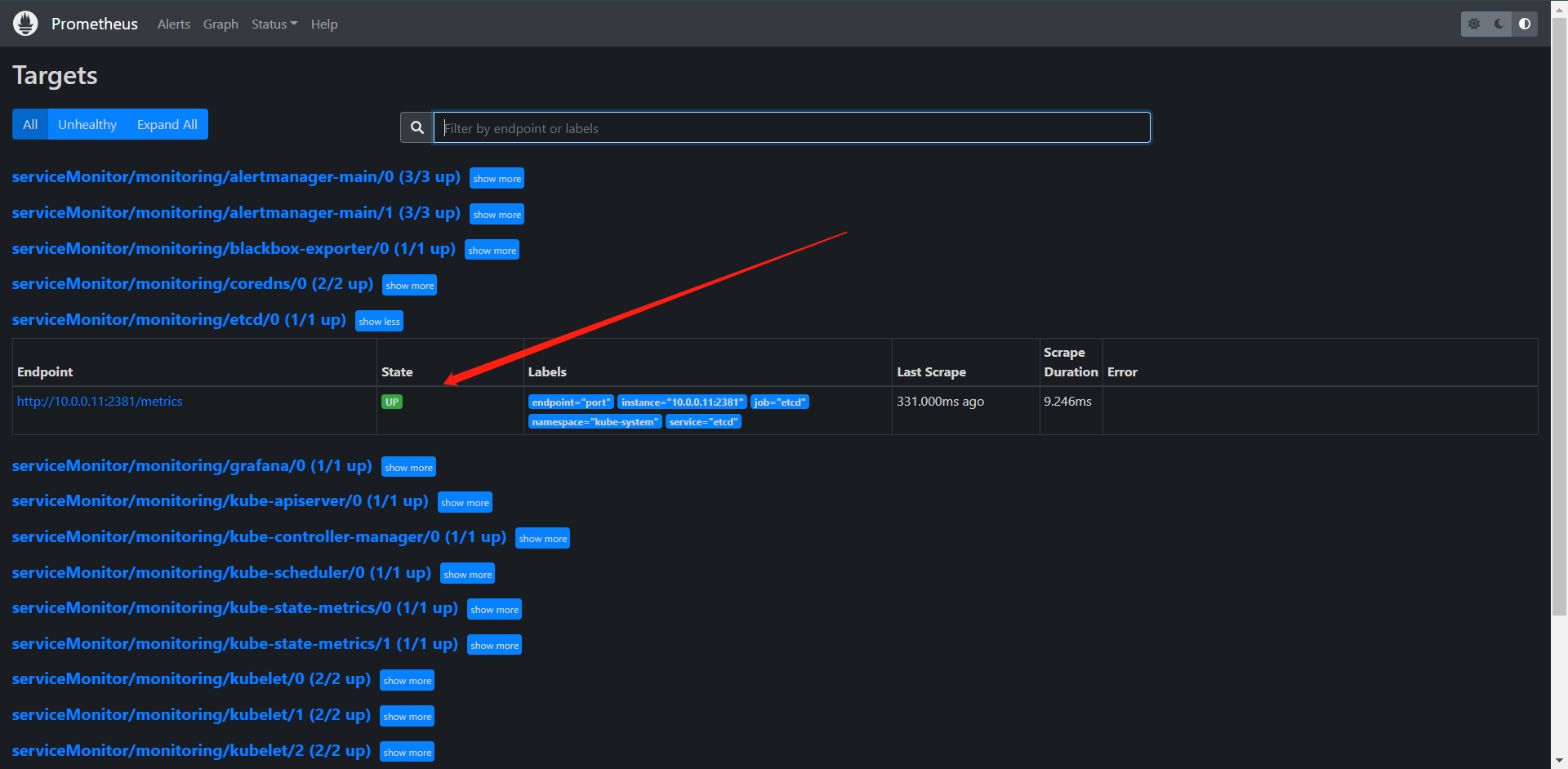
这样就正常了,其实etcd这个metrics接口它是http的而且无需任何的认证,这就是我们接入一个自定义监控的应用的方法了,只需要创建一个ServiceMonitor就完成了,我们也可以在Grafana直接导入模板3070,效果如下:
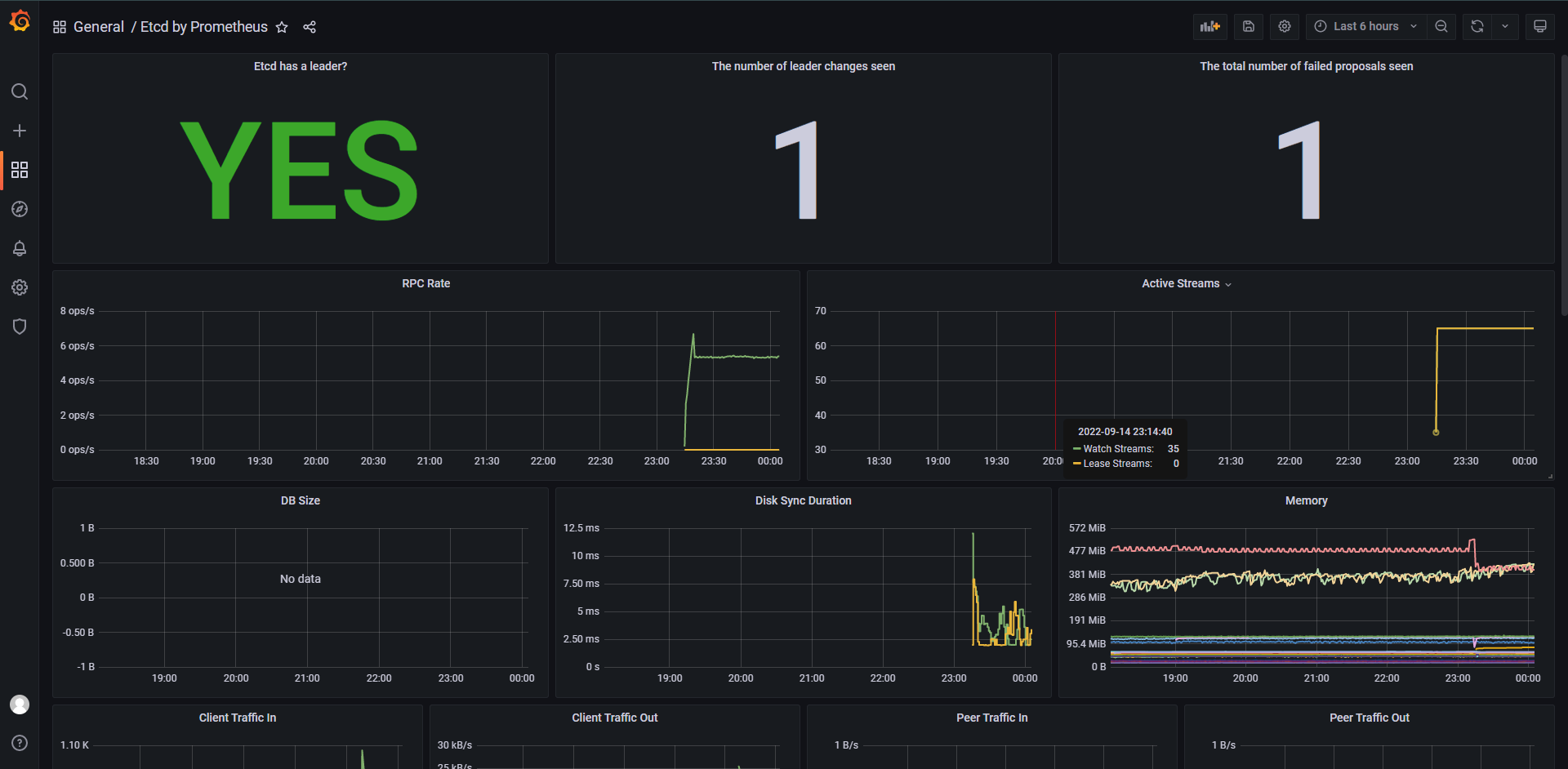
其实PodMonitor和ServiceMonitor的用法基本是一样的,无非是过滤的时候它去找Pod而已,
4:配置PrometheusRule
上面我们知道了如何配置一个ServiceMonitor对象了,但是还需要定义一些报警规则呢,我们去看看Prometheus Dashboard的Alert下面其实已经内置了很多的报警规则了,这一系列的规则其实都来源于项目:https://github.com/kubernetes-monitoring/kubernetes-mixin,我们通过Prometheus Operator安装配置上了。
但是这些报警规则信息是哪儿来的呢?它们应该用怎样的方式去通知我们呢?我们知道之前我们学过自定义的方式可以在Prometheus的配置文件内指定Alertmanager实例和报警的Rules文件,现在我们通过Operator部署的话怎么办呢?我们可以在Prometheus Dashboard的Config页面下查看关于Alertmanager的配置。
alerting:
alert_relabel_configs:
- separator: ;
regex: prometheus_replica
replacement: $1
action: labeldrop
alertmanagers:
- follow_redirects: true
enable_http2: true
scheme: http
path_prefix: /
timeout: 10s
api_version: v2
relabel_configs:
- source_labels: [__meta_kubernetes_service_name]
separator: ;
regex: alertmanager-main
replacement: $1
action: keep
- source_labels: [__meta_kubernetes_endpoint_port_name]
separator: ;
regex: web
replacement: $1
action: keep
kubernetes_sd_configs:
- role: endpoints
kubeconfig_file: ""
follow_redirects: true
enable_http2: true
namespaces:
own_namespace: false
names:
- monitoring
它其实是通过自动发现的方式将告警推送给来了Alertmanager的
[root@kubernetes-master-1 kube-prometheus]# kubectl get svc -n monitoring
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
alertmanager-main NodePort 20.1.141.235 <none> 9093:31146/TCP,8080:31307/TCP 7h50m
其实就是它
[root@kubernetes-master-1 kube-prometheus]# kubectl get pods -n monitoring
NAME READY STATUS RESTARTS AGE
alertmanager-main-0 2/2 Running 0 7h48m
alertmanager-main-1 2/2 Running 0 7h48m
alertmanager-main-2 2/2 Running 0 7h48m
这是对应的Pod
# 这里存放的都是报警规则
rule_files:
- /etc/prometheus/rules/prometheus-k8s-rulefiles-0/*.yaml
这个其实就是我们自带了很多的Rules的规则了。
/etc/prometheus/rules/prometheus-k8s-rulefiles-0 $ ls
monitoring-alertmanager-main-rules-c5fac85b-3943-4a8b-baa0-7156d273a918.yaml
monitoring-grafana-rules-09df9c69-bf75-4efc-a3a2-dd99e8bcc0af.yaml
monitoring-kube-prometheus-rules-37239f99-6b67-4e3f-84ee-b994530f3e32.yaml
monitoring-kube-state-metrics-rules-5bd7d1d9-ba9f-4a0d-8ccf-41e0f15e1de7.yaml
monitoring-kubernetes-monitoring-rules-96f2f7cb-7e14-4f3e-a6ef-8dcbfa4b67f3.yaml
monitoring-node-exporter-rules-bc2a9706-7d79-4c06-acd4-30b3c5e32644.yaml
monitoring-prometheus-k8s-prometheus-rules-f6f436d8-a99f-47c0-a99d-9d8a518a5d07.yaml
monitoring-prometheus-operator-rules-35eb6078-c05e-433c-bb97-bdabde1c9cba.yaml
这些就是我们看到的规则都是从这些文件内读取的,这些文件就来自于我们CRD的PrometheusRule创建的资源都会被写入到对应的文件内,那么下面我们来具体实战一下自定义写一个etcd的报警来看看
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
labels:
prometheus: k8s
role: alert-rules
name: etcd-rules
namespace: monitoring
spec:
groups:
- name: etcd
rules:
- alert: EtcdClusterUnailable
annotations:
summary: etcd cluster small
description: if on more etcd peer goes down the cluster will be unavilable
expr: |
count(up{job='etcd'} == 0) > (count(up{job='etcd'}) / 2 - 1)
for: 3m
labels:
serverity: crititcal
然后我们创建一下这个规则,然后观察一下Prometheus看看
[root@kubernetes-master-1 ~]# kubectl apply -f prometheus-etcdRules.yaml
prometheusrule.monitoring.coreos.com/etcd-rules created
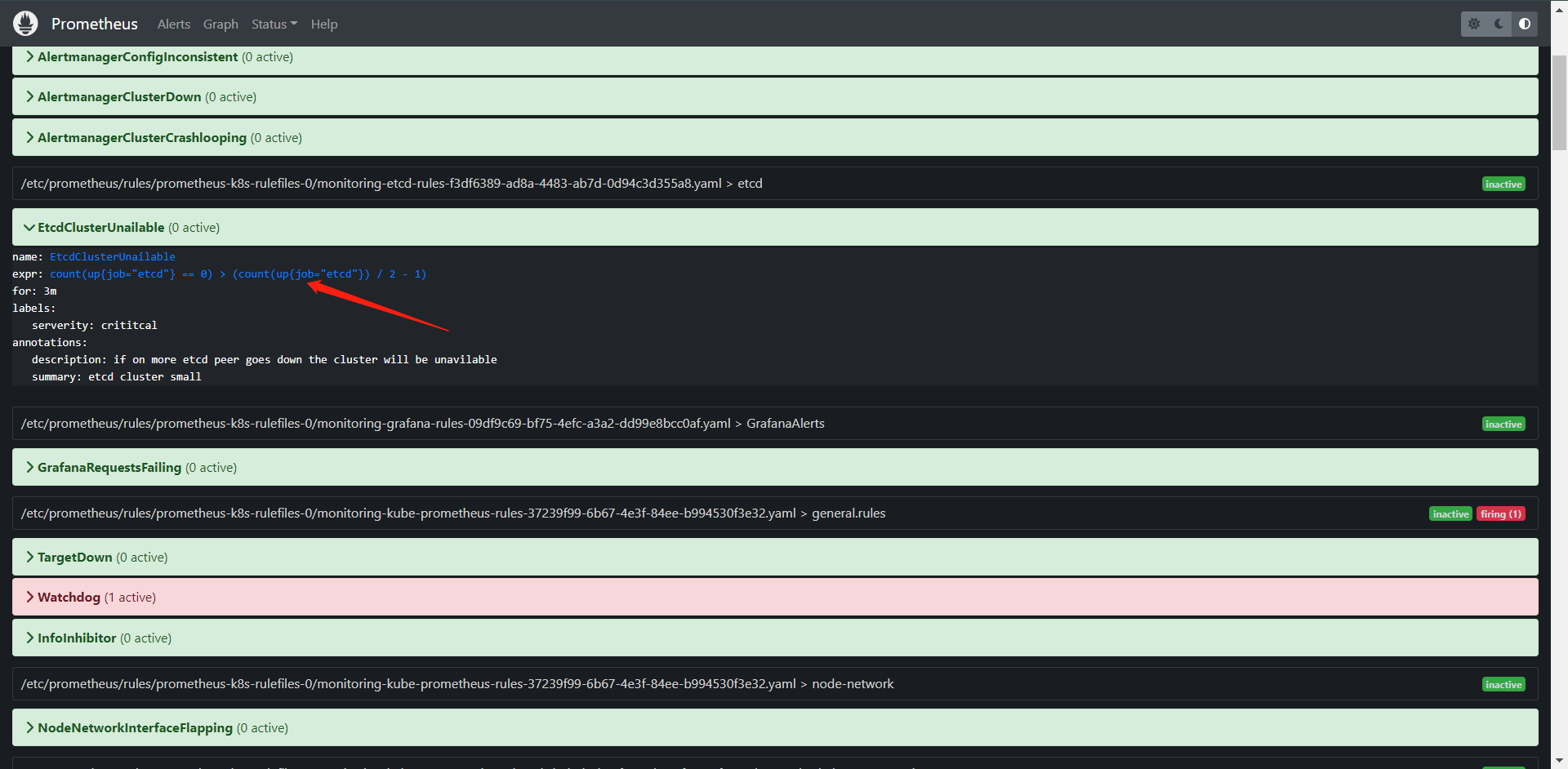
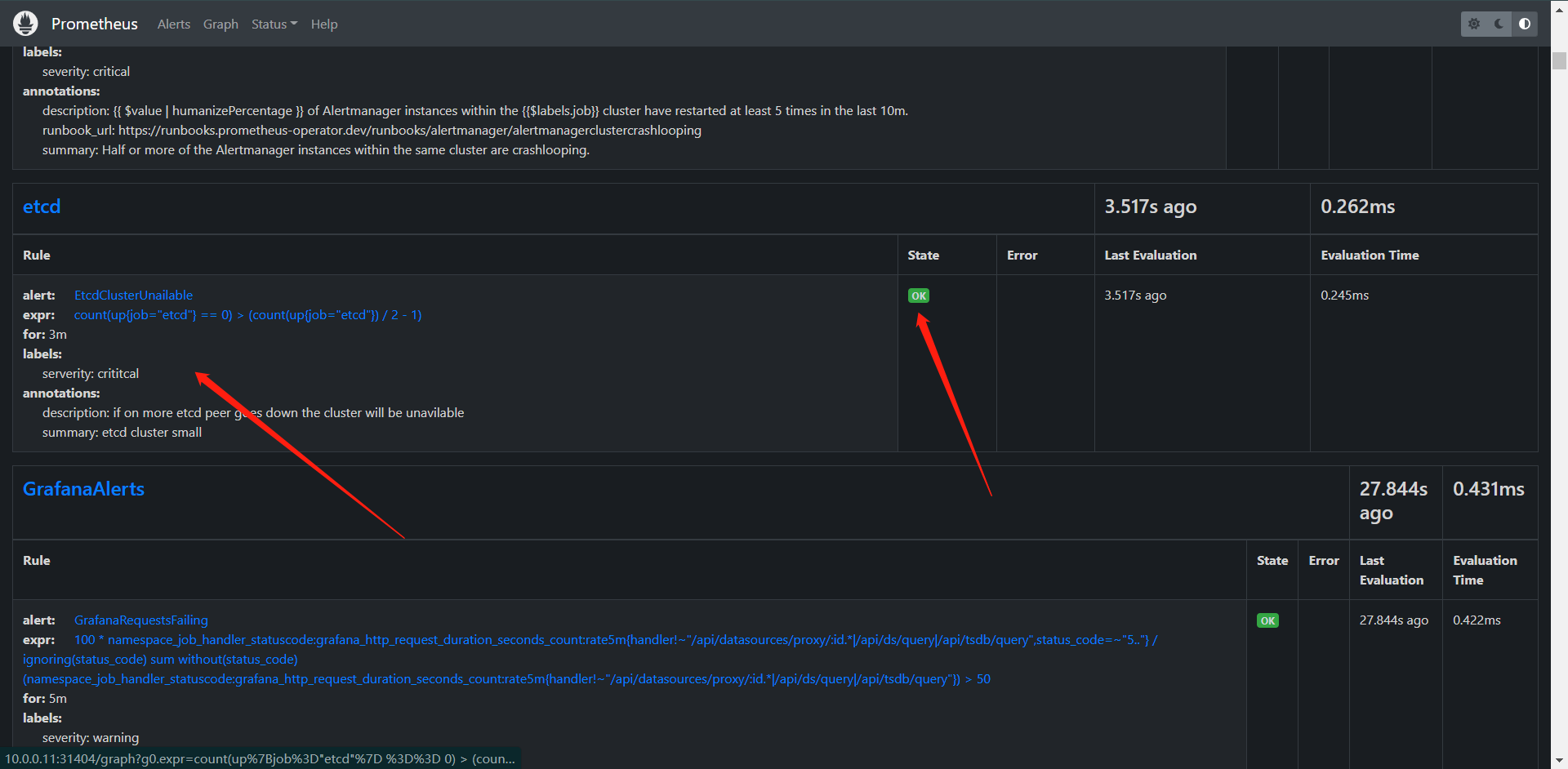
这边可以看到我们的规则已经创建出来了。而且状态也是OK的,下面我们来看看转换到Prometheus内它是什么样子的
/etc/prometheus/rules/prometheus-k8s-rulefiles-0 $ ls
monitoring-alertmanager-main-rules-c5fac85b-3943-4a8b-baa0-7156d273a918.yaml
monitoring-etcd-rules-f3df6389-ad8a-4483-ab7d-0d94c3d355a8.yaml
monitoring-grafana-rules-09df9c69-bf75-4efc-a3a2-dd99e8bcc0af.yaml
monitoring-kube-prometheus-rules-37239f99-6b67-4e3f-84ee-b994530f3e32.yaml
monitoring-kube-state-metrics-rules-5bd7d1d9-ba9f-4a0d-8ccf-41e0f15e1de7.yaml
monitoring-kubernetes-monitoring-rules-96f2f7cb-7e14-4f3e-a6ef-8dcbfa4b67f3.yaml
monitoring-node-exporter-rules-bc2a9706-7d79-4c06-acd4-30b3c5e32644.yaml
monitoring-prometheus-k8s-prometheus-rules-f6f436d8-a99f-47c0-a99d-9d8a518a5d07.yaml
monitoring-prometheus-operator-rules-35eb6078-c05e-433c-bb97-bdabde1c9cba.yaml
/etc/prometheus/rules/prometheus-k8s-rulefiles-0 $ cat monitoring-etcd-rules-f3df6389-ad8a-4483-ab7d-0d94c3d355a8.yaml
groups:
- name: etcd
rules:
- alert: EtcdClusterUnailable
annotations:
description: if on more etcd peer goes down the cluster will be unavilable
summary: etcd cluster small
expr: |
count(up{job='etcd'} == 0) > (count(up{job='etcd'}) / 2 - 1)
for: 3m
labels:
serverity: crititcal
可以看到从spec向下,都是元丰不懂得给我们放进来了,这就是我们创建出来的CRD最后的样子。
我们想想,监控有了,规则也有了,后面我们还差什么?我们还差的就是Alertmanager的告警了,那么我们下面来看这些是怎么写的。
apiVersion: monitoring.coreos.com/v1alpha1
kind: AlertmanagerConfig
metadata:
name: dinghook
namespace: monitoring
labels:
alertmanagerConfig: example
spec:
receivers:
- name: Critical
webhookConfigs:
- url: http://<webhookurl>
sendResolved: true
route:
groupBy: ["namespace"]
groupWait: 30s
groupInterval: 5m
repeatInterval: 12h
receiver: Critical
routes:
- receiver: Critical # 它对应了上面的receivers的name
match:
serverity: critical
当然了,这是一个测试的,大家可以根据自己的生产去配置就OK了邮箱也是可以的。
[root@kubernetes-master-1 ~]# kubectl get alertmanagerconfigs.monitoring.coreos.com -n monitoring
NAME AGE
dinghook 93s
but,这个时候其实我们创建的资源是没有i生效的。我们需要去改一下Alertmanager的标签,也就是可以修改manifests/alertmanager-alertmanager.yaml,在最后加上这个标签就OK了,当然不只是这一种方法,还可以匹配Namespace也是OK的哦
# 第一种
...
alertmanagerConfigSelector:
matchLabels:
alertmanagerConfig: example
# 第二种
[root@kubernetes-master-1 kube-prometheus]# kubectl get ns --show-labels monitoring
NAME STATUS AGE LABELS
monitoring Active 32h kubernetes.io/metadata.name=monitoring
...
alertmanaerConfigNamespaceSelector:
matchLabels:
kubernetes.io/metadata.name: monitoring
然后我们部署一下
[root@kubernetes-master-1 kube-prometheus]# kubectl apply -f manifests/alertmanager-alertmanager.yaml
alertmanager.monitoring.coreos.com/main configured
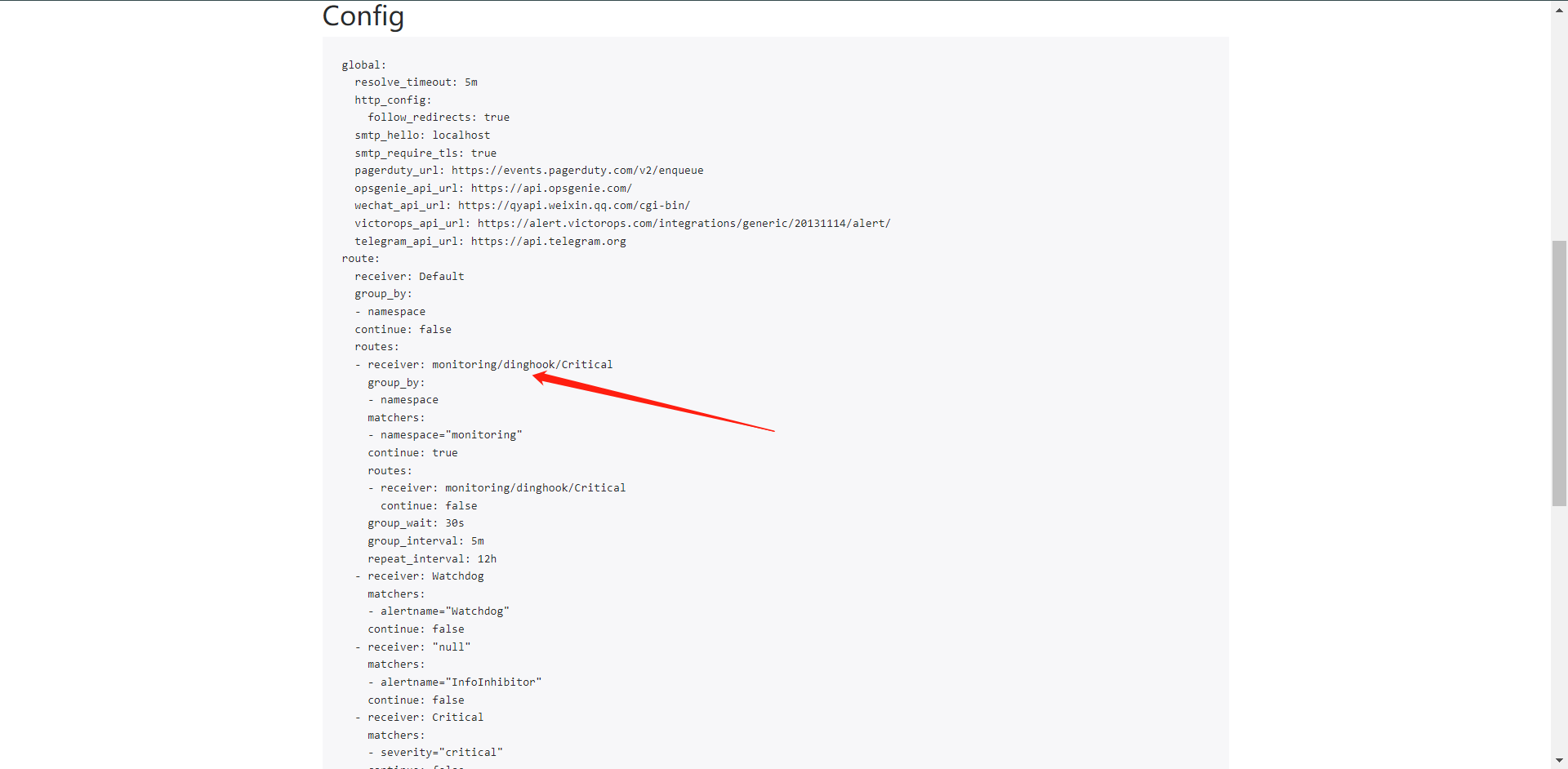
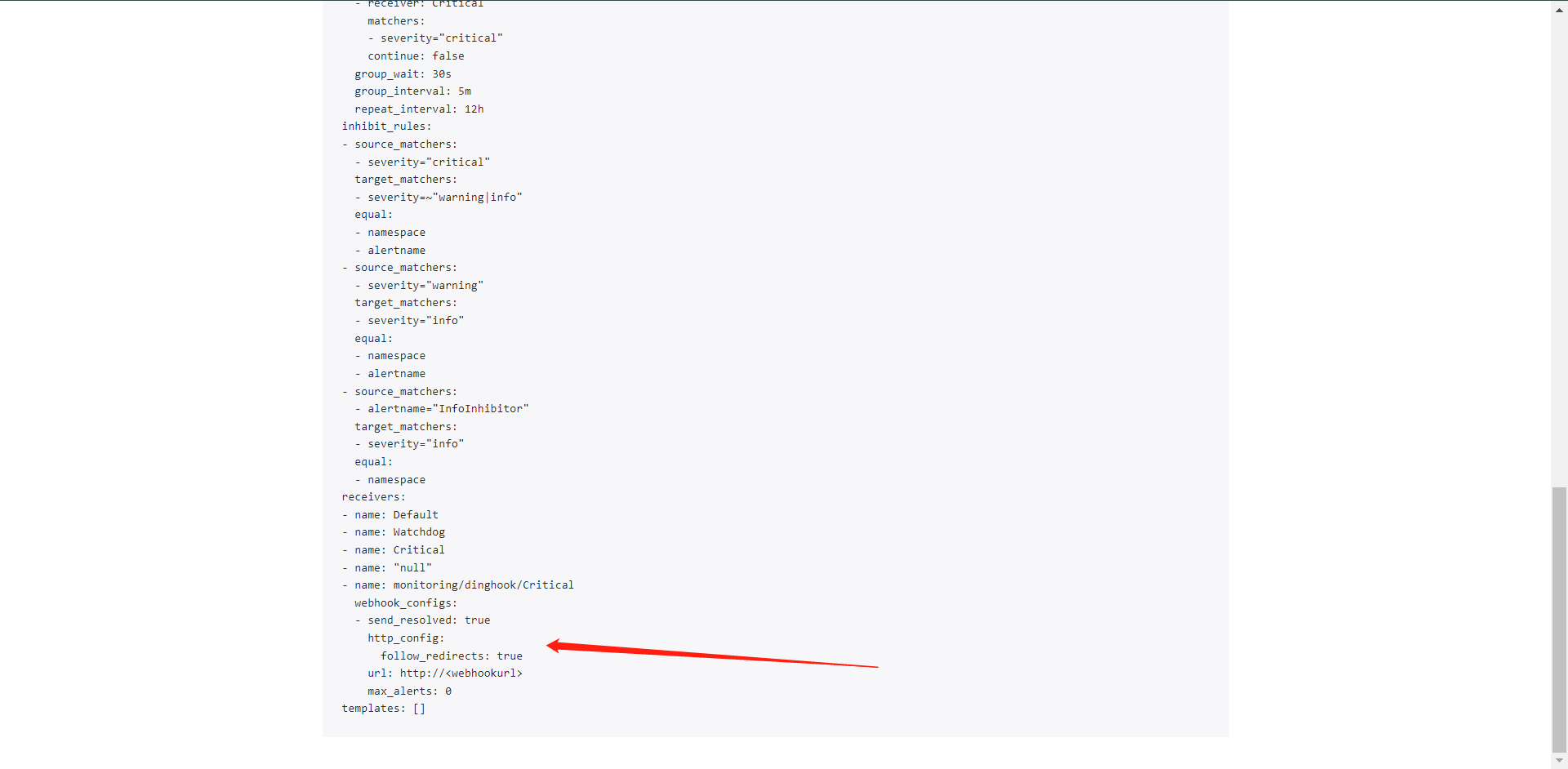
从这里可以看出我们的配置其实已经生效了。发送给了我们的WebHook,但是我这个Webhook是自定义的,我现在没有WebHook所以只是测试下。
到这里其实Prometheus Operator的自定义监控就完成了,我们从头监控了一个ETCD并且给他创建了规则,并且我们还了解了如何去创建AlertmanagerConfig配置发送规则,这基本上就是我们在前面学过的Prometheus+Alertmanager的所有配置了,
5:Operator 高级配置
上面我们学习了如何使用Prometheus Operator去配置一个自定义的监控项,以及报警规则的使用,那么我们可以直接使用前面学习Prometheus的时候学习的发现功能么?如果我们在Kubernetes中已经有有很多的Service/Pod,那么我们是否还是需要一个个的去创建ServiceMonitor或者PodMonitor对象来进行监控呢?这样我们是不是就又麻烦起来了。
5.1:自动发现配置
为了解决我们一个个创建ServiceMonitor和PodMonitor的问题,Operator为我们提供了一个额外的抓取配置来解决这个问题,我们可以通过添加额外配置来进行服务发现,进行自动监控,和前面自定义的方法一样,我们可以在Prometheus Operator当中去自动发现并监控具有 prometheus.io/scrape=true这个annotations的Service,之前我们定义的Prometheus的配置是这样的:
[root@kubernetes-master-1 ~]# cat prometheus-additional.yaml
- job_name: "endpoints"
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]
action: replace
target_label: __scheme__
regex: (https?)
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port]
action: replace
target_label: __address__
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_service_name]
action: replace
target_label: kubernetes_name
- source_labels: [__meta_kubernetes_pod_name]
action: replace
target_label: kubernetes_pod_name
- source_labels: [__meta_kubernetes_node_name]
action: replace
target_label: kubernetes_node
看过我前面的文章就会发现这个就是当时做的发现Service的配置,那么这个配置如何用在Operator上呢?
我们需要用到 prometheus下的additionalScrapeConfigs这个参数,它允许我们指定一个额外的Prometheus的配置,我们只需要创建一个Secret就可以了。
[root@kubernetes-master-1 ~]# kubectl create secret generic additionalconfigs --from-file=prometheus-additional.yaml -n monitoring
secret/additional-configs created
创建完成之后它不会生效的,我们需要把这个secrets配置到prometheus的CRD内,配置prometheus-prometheus.yaml下
[root@kubernetes-master-1 ~]# cat kube-prometheus/manifests/prometheus-prometheus.yaml
......
additionalScrapeConfigs:
name: additionalconfigs
key: prometheus-additional.yaml
这里我们或许还需要更新一下权限,否则Prometheus的SA的权限还是不够的。
[root@kubernetes-master-1 ~]# cat kube-prometheus/manifests/prometheus-clusterRole.yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
labels:
app.kubernetes.io/component: prometheus
app.kubernetes.io/instance: k8s
app.kubernetes.io/name: prometheus
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 2.36.1
name: prometheus-k8s
rules:
- apiGroups:
- ""
resources:
- nodes
- services
- endpoints
- pods
- nodes/proxy
verbs:
- get
- list
- watch
- apiGroups:
- ""
resources:
- configmaps
- nodes/metrics
verbs:
- get
- nonResourceURLs:
- /metrics
verbs:
- get
[root@kubernetes-master-1 ~]# kubectl apply -f kube-prometheus/manifests/prometheus-clusterRole.yaml
clusterrole.rbac.authorization.k8s.io/prometheus-k8s configured
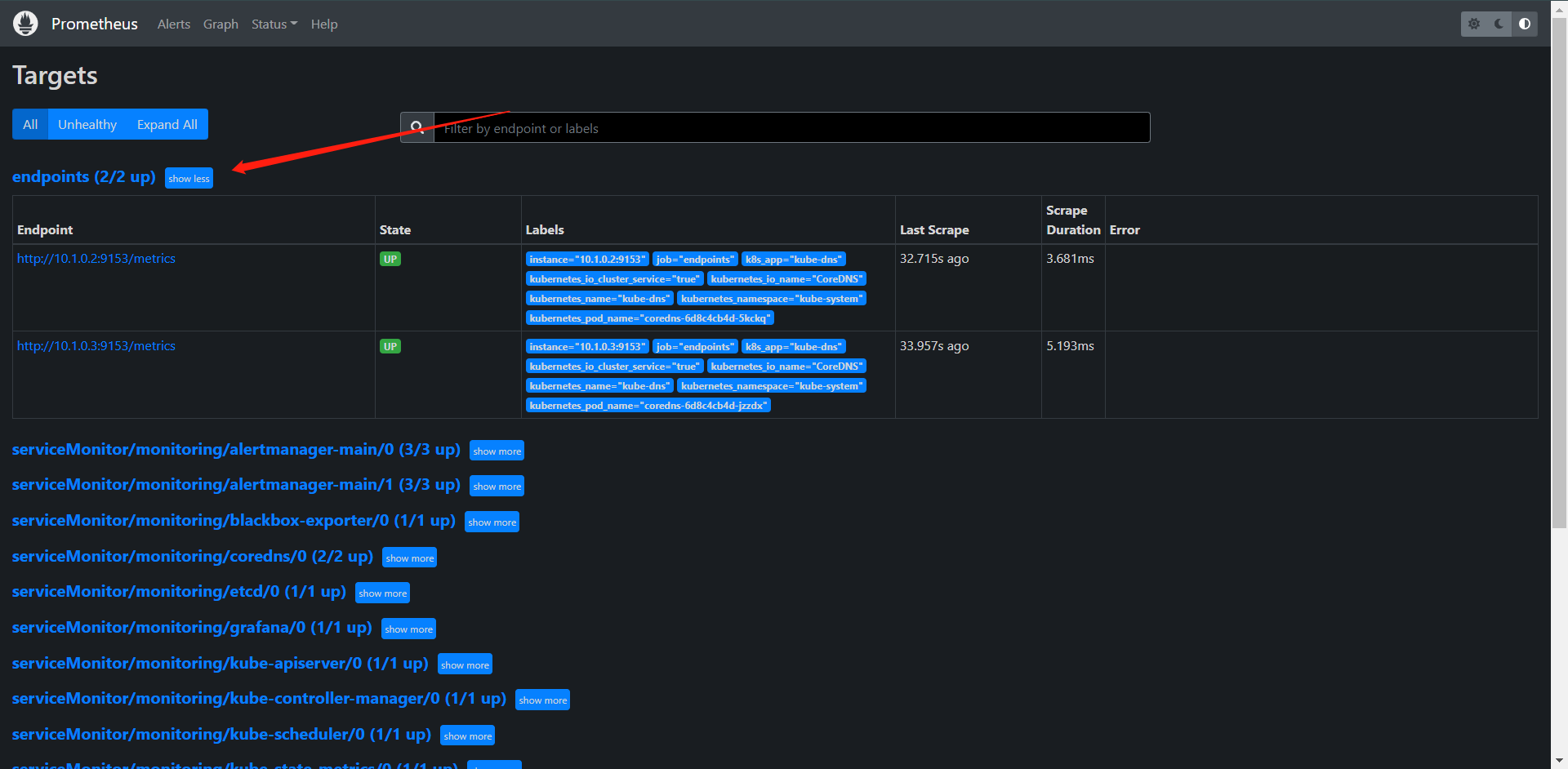
从这里就可以看出我们的配置生效了,并且已经发现了两个Service,这个是CoreDNS的,当然了,我们把以前那个Redis拿来创建一下也是可以的
[root@kubernetes-master-1 ~]# cat redis-discovery.yaml
kind: Deployment
apiVersion: apps/v1
metadata:
name: redis
namespace: monitoring
labels:
app: redis
spec:
selector:
matchLabels:
app: redis
template:
metadata:
labels:
app: redis
spec:
containers:
- name: redis
image: redis:latest
resources:
requests:
cpu: 100m
memory: 100Mi
limits:
cpu: 100m
memory: 100Mi
ports:
- containerPort: 6379
- name: redis-exporter
image: oliver006/redis_exporter:latest
resources:
requests:
cpu: 100m
memory: 100Mi
limits:
cpu: 100m
memory: 100Mi
ports:
- containerPort: 9121
---
kind: Service
apiVersion: v1
metadata:
annotations:
prometheus.io/port: "9121"
prometheus.io/scrape: "true"
name: redis
namespace: monitoring
labels:
app: redis
spec:
type: ClusterIP
selector:
app: redis
ports:
- name: redis
port: 6379
targetPort: 6379
- name: exporter
port: 9121
targetPort: 9121
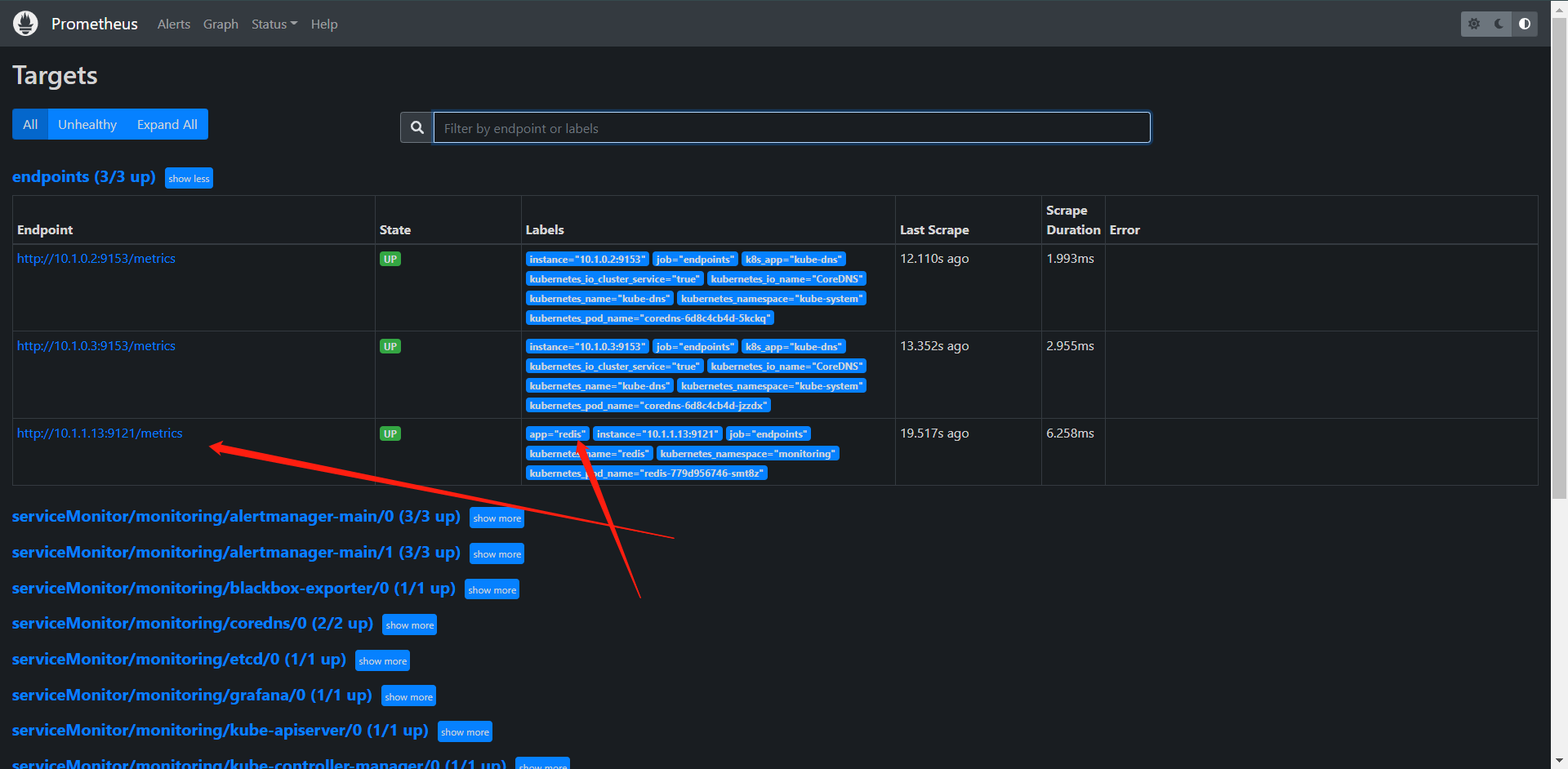
这个时候我们就会发现我们的Redis就被自动发现到了,我们也就不需要再去创建ServiceMonitor了
5.2:数据持久化
这里我们要提到一点,前面我们建立的这个Prometheus的其实是没有数据持久化的,这个我们可以通过get查看一下,也就意味着,我们这个Pod一旦Down掉了,数据就会丢失了,
[root@kubernetes-master-1 ~]# kubectl get statefulsets -n monitoring prometheus-k8s -oyaml
...
volumeMounts:
- mountPath: /etc/prometheus/config_out
name: config-out
readOnly: true
- mountPath: /etc/prometheus/certs
name: tls-assets
readOnly: true
- mountPath: /prometheus
name: prometheus-k8s-db
- mountPath: /etc/prometheus/rules/prometheus-k8s-rulefiles-0
name: prometheus-k8s-rulefiles-0
- mountPath: /etc/prometheus/web_config/web-config.yaml
name: web-config
readOnly: true
subPath: web-config.yaml
...
volumeMounts:
- mountPath: /etc/prometheus/config
name: config
- mountPath: /etc/prometheus/config_out
name: config-out
- mountPath: /etc/prometheus/rules/prometheus-k8s-rulefiles-0
name: prometheus-k8s-rulefiles-0
...
volumes:
- name: config
secret:
defaultMode: 420
secretName: prometheus-k8s
- name: tls-assets
projected:
defaultMode: 420
sources:
- secret:
name: prometheus-k8s-tls-assets-0
- emptyDir: {}
name: config-out
- configMap:
defaultMode: 420
name: prometheus-k8s-rulefiles-0
name: prometheus-k8s-rulefiles-0
- name: web-config
secret:
defaultMode: 420
secretName: prometheus-k8s-web-config
- emptyDir: {}
name: prometheus-k8s-db
...
那么我们如何配置它呢?其实这个配置也可以在prometheus-prometheus.yaml下配置,我们下面来看看如何配置它、
[root@kubernetes-master-1 ~]# cat kube-prometheus/manifests/prometheus-prometheus.yaml
......
storage:
volumeClaimTemplate:
spec:
storageClassName: nfs-storage # 我这里用的是NFS的存储,但是生产不建议用NFS
resources:
requests:
storage: 10Gi
[root@kubernetes-master-1 ~]# kubectl apply -f kube-prometheus/manifests/prometheus-prometheus.yaml
prometheus.monitoring.coreos.com/k8s configured
[root@kubernetes-master-1 ~]# kubectl get pvc -n monitoring
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
prometheus-k8s-db-prometheus-k8s-0 Bound pvc-4a3f969e-7cd4-407a-bf59-eba353d1d05a 10Gi RWO nfs-storage 39s
prometheus-k8s-db-prometheus-k8s-1 Bound pvc-1128f24f-5662-4282-a633-af028ce42302 10Gi RWO nfs-storage 39s
这个时候Prometheus就会重建了,并且随着重建,数据也会随之丢失,但是后面的数据都会被保存下来。
关于Prometheus Operator接入VictoriaMetrics的 vm Operator这边不详细去讲了,毕竟这篇文章只是在讲如何使用Prometheus Operator。后面单独出一篇VictoriaMetrics和vm Operator的文章。
Prometheus Operator官网:https://prometheus-operator.dev/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号