
官网:https://openkruise.io/zh/
1:OpenKruise是什么
OpenKruise是个Kubernetes的扩展套件,主要聚焦于云原生应用的自动化,比如:部署,发布,运维以及可用性防护。OpenKruise提供的绝大部能力都是基于CRD扩展来定义的,它们不存在于任何外部依赖,可以运行在任意纯净的Kubernetes集群中,Kubernetes自身提供的一些应用部署管理功能,对于大规模应用与集群的场景这些功能是远远不够的,而OpenKruise弥补了Kubernetes在应用部署,升级,防护,运维等领域的不足。
2:OpenKruise提供了什么
1:增强版本的workloads:OpenKruise 包含了一系列增强版本的 Workloads(工作负载),比如 CloneSet、Advanced StatefulSet、Advanced DaemonSet、BroadcastJob 等。它们不仅支持类似于 Kubernetes 原生 Workloads 的基础功能,还提供了如原地升级、可配置的扩缩容/发布策略、并发操作等。原地升级是一种升级应用容器镜像甚至环境变量的全新方式。它只会用新的镜像重建 Pod 中的特定容器,整个 Pod 以及其中的其他容器都不会被影响。因此它带来了更快的发布速度,以及避免了对其他 Scheduler、CNI、CSI 等组件的负面影响。
2:应用旁路管理:OpenKruise 提供了多种通过旁路管理应用 sidecar 容器、多区域部署的方式,“旁路” 意味着你可以不需要修改应用的 Workloads 来实现它们。比如,SidecarSet 能帮助你在所有匹配的 Pod 创建的时候都注入特定的 sidecar 容器,甚至可以原地升级已经注入的 sidecar 容器镜像、并且对 Pod 中其他容器不造成影响。而 WorkloadSpread 可以约束无状态 Workload 扩容出来 Pod 的区域分布,赋予单一 workload 的多区域和弹性部署的能力。
3:高可用性防护:OpenKruise 在为应用的高可用性防护方面也做出了很多努力。目前它可以保护你的 Kubernetes 资源不受级联删除机制的干扰,包括 CRD、Namespace、以及几乎全部的 Workloads 类型资源。相比于 Kubernetes 原生的 PDB 只提供针对 Pod Eviction 的防护PodUnavailableBudget 能够防护 Pod Deletion、Eviction、Update 等许多种 voluntary disruption 场景。
4:高级的应用运维能力:OpenKruise也提供了很多高级的运维能力来帮助你更好的管理应用,比如可以通过ImagePullJob来在任意范围的节点上预先拉取某些镜像(镜像预热),或者指定某个Pod中的一个或多个容器被原地重启
3:OpenKruise架构
下图为Openkruise架构图
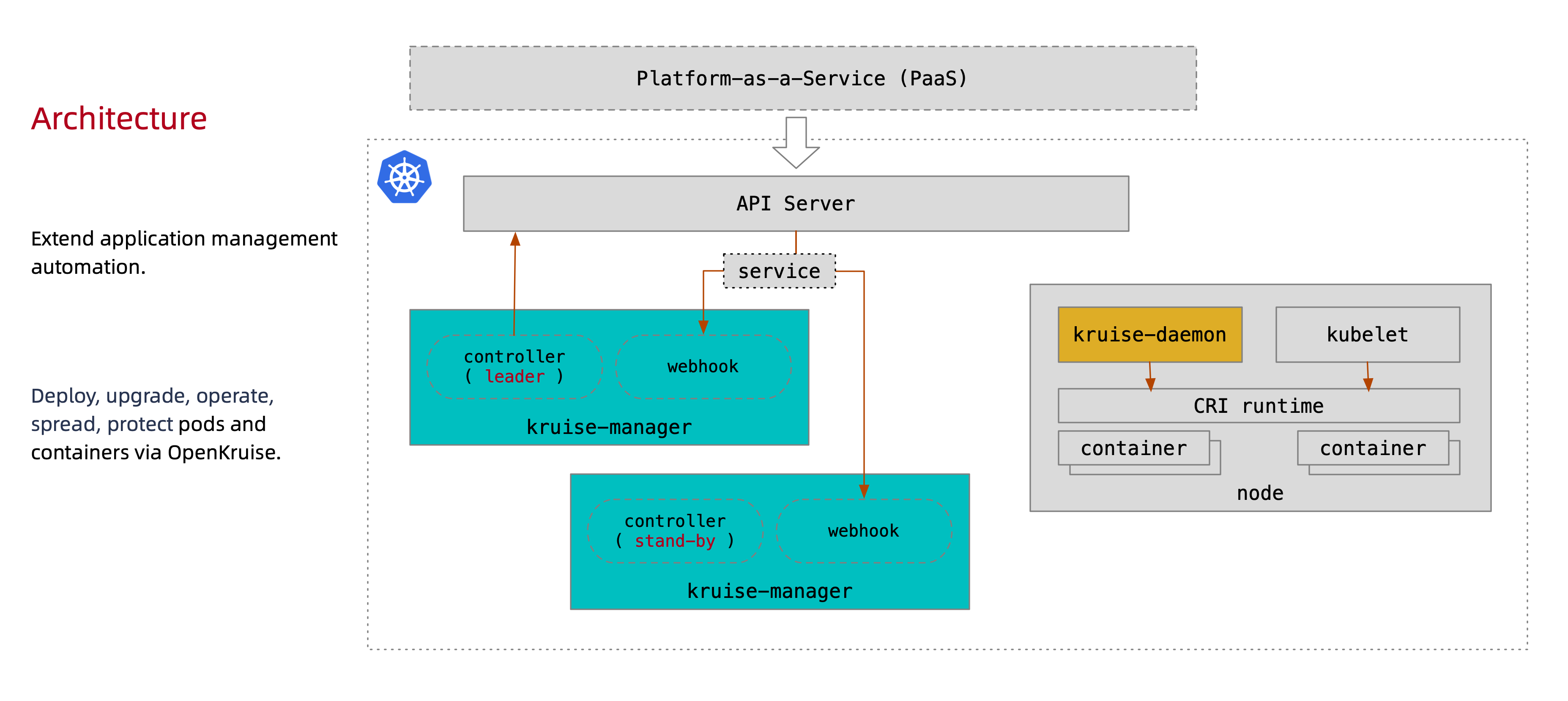
所有OpenKruise的功能都是通过kubernetes CRD来提供的,其中kruise-manager是一个运行控制器和webhook的中心组件,它通过Deployment部署在kruise-system命名空间中,从逻辑上来看,如cloneset-controller,sidecarset-controller这些控制器都是独立运行的,不过为了减少复杂度,它们都被打包在一个独立的二进制文件,并运行在kruise-controller-manager-xxx这个Pod中,除了控制器之外,kruise-controller-manager-xxx中还包含了针对Kruise CRD以及Pod资源的admission webhooks,Kruise-manager会创建一些webhook configurations来配置哪儿些资源需要感知处理,以及提供了一个Service来给kube-apiserver调用。
从v0.8.0版本开始提供了一个新的Kruise-daemon组件,它通过DaemonSet部署到每个节点上,提供镜像预热,容器重启等功能。
4:OpenKruise安装
这里我们选择Helm来安装它,注意我们这里使用的是v1.0.0开始的,OpenKruise要求kubernetes版本>= 1.16版本
# 添加Charts仓库
[root@k-m-1 ~]# helm repo add openkruise https://openkruise.github.io/charts
"openkruise" has been added to your repositories
[root@k-m-1 ~]# helm repo list
NAME URL
openkruise https://openkruise.github.io/charts
[root@k-m-1 ~]# helm repo update
Hang tight while we grab the latest from your chart repositories...
...Successfully got an update from the "openkruise" chart repository
Update Complete. ⎈Happy Helming!⎈
# 截至目前2023/06/05日,Openkruise的最新版本为1.5,稳定版本为1.4,我们这里选择稳定版本
[root@k-m-1 ~]# helm upgrade --install kruise openkruise/kruise --version 1.4.0
Release "kruise" does not exist. Installing it now.
NAME: kruise
LAST DEPLOYED: Mon Jun 5 07:28:04 2023
NAMESPACE: default
STATUS: deployed
REVISION: 1
TEST SUITE: None
[root@k-m-1 ~]# kubectl get pod -n kruise-system
NAME READY STATUS RESTARTS AGE
kruise-controller-manager-7cb6d4558-jzkb2 1/1 Running 0 49s
kruise-controller-manager-7cb6d4558-vgvg8 1/1 Running 0 49s
kruise-daemon-tqc9h 1/1 Running 0 49s
# 确定CRD资源
[root@k-m-1 ~]# kubectl get crd | grep kruise
advancedcronjobs.apps.kruise.io 2023-06-04T23:28:05Z
broadcastjobs.apps.kruise.io 2023-06-04T23:28:05Z
clonesets.apps.kruise.io 2023-06-04T23:28:05Z
containerrecreaterequests.apps.kruise.io 2023-06-04T23:28:05Z
daemonsets.apps.kruise.io 2023-06-04T23:28:05Z
imagepulljobs.apps.kruise.io 2023-06-04T23:28:05Z
nodeimages.apps.kruise.io 2023-06-04T23:28:05Z
nodepodprobes.apps.kruise.io 2023-06-04T23:28:05Z
persistentpodstates.apps.kruise.io 2023-06-04T23:28:05Z
podprobemarkers.apps.kruise.io 2023-06-04T23:28:05Z
podunavailablebudgets.policy.kruise.io 2023-06-04T23:28:05Z
resourcedistributions.apps.kruise.io 2023-06-04T23:28:05Z
sidecarsets.apps.kruise.io 2023-06-04T23:28:05Z
statefulsets.apps.kruise.io 2023-06-04T23:28:05Z
uniteddeployments.apps.kruise.io 2023-06-04T23:28:05Z
workloadspreads.apps.kruise.io 2023-06-04T23:28:05Z
# 可以看到这里就部署好了
[root@k-m-1 ~]# kubectl get deployments.apps,daemonsets.apps -n kruise-system
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/kruise-controller-manager 2/2 2 2 77s
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
daemonset.apps/kruise-daemon 1 1 1 1 1 <none> 77s
# 我们前面说了自从0.8.0开始多了一个daemonset的控制器来做一些操作,可以看到这里是和我们说明的是一致的,我这里是单节点的集群,所以多副本的高可用不太有用,但是生产一定要是多副本来保证高可用,另外如果需要定制一些需求可以将chart下载下来根据values的内容进行配置。
5:OpenKruise之CloneSet
CloneSet控制器是OpenKruise提供的对云原生Deployment的增强控制器,在使用方式上和Deployment几乎一致,下面我们部署一个示例。
apiVersion: apps.kruise.io/v1alpha1
kind: CloneSet
metadata:
name: nginx
namespace: default
labels:
app: nginx
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:latest
ports:
- name: http
containerPort: 80
# 部署一下这个CRD资源
[root@k-m-1 openkruise]# kubectl apply -f nginx.yaml
cloneset.apps.kruise.io/nginx created
[root@k-m-1 openkruise]# kubectl get clonesets,pod
NAME DESIRED UPDATED UPDATED_READY READY TOTAL AGE
cloneset.apps.kruise.io/nginx 1 1 1 1 1 33s
NAME READY STATUS RESTARTS AGE
pod/nginx-v4cxc 1/1 Running 0 33s
# 可以看到这里的资源完全是和Deployment很像的,然后我们看一下Pod的详细信息
[root@k-m-1 openkruise]# kubectl describe pod nginx-v4cxc
Name: nginx-v4cxc
Namespace: default
Priority: 0
Service Account: default
Node: k-m-1/10.0.0.11
Start Time: Mon, 05 Jun 2023 07:40:26 +0800
Labels: app=nginx
# Kruise给我们添加了很多的Labels
apps.kruise.io/cloneset-instance-id=v4cxc
controller-revision-hash=nginx-56bb68c858
lifecycle.apps.kruise.io/state=Normal
pod-template-hash=56bb68c858
Annotations: apps.kruise.io/runtime-containers-meta:
{"containers":[{"name":"nginx","containerID":"containerd://50c239a4571f0d1a7c2f1418cd240cc4914fc3673694bf7d39a57dd2710afd7e","restartCount...
cni.projectcalico.org/containerID: 61d21b18d970e267f2be9c9b7bd68a74fc3336f4fa342b28602275c93644c0d2
cni.projectcalico.org/podIP: 100.114.94.130/32
cni.projectcalico.org/podIPs: 100.114.94.130/32
lifecycle.apps.kruise.io/timestamp: 2023-06-04T23:40:26Z
Status: Running
IP: 100.114.94.130
IPs:
IP: 100.114.94.130
# 再看这里的控制器,我们用Deployment的时候,它的控制器是ReplicaSet,而这里并非 ReplicaSet
Controlled By: CloneSet/nginx
Containers:
nginx:
Container ID: containerd://50c239a4571f0d1a7c2f1418cd240cc4914fc3673694bf7d39a57dd2710afd7e
Image: nginx:latest
Image ID: docker.io/library/nginx@sha256:af296b188c7b7df99ba960ca614439c99cb7cf252ed7bbc23e90cfda59092305
Port: 80/TCP
Host Port: 0/TCP
State: Running
Started: Mon, 05 Jun 2023 07:40:54 +0800
Ready: True
Restart Count: 0
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-bn6mq (ro)
Readiness Gates:
Type Status
InPlaceUpdateReady True
KruisePodReady True
Conditions:
Type Status
KruisePodReady True
InPlaceUpdateReady True
Initialized True
Ready True
ContainersReady True
PodScheduled True
Volumes:
kube-api-access-bn6mq:
Type: Projected (a volume that contains injected data from multiple sources)
TokenExpirationSeconds: 3607
ConfigMapName: kube-root-ca.crt
ConfigMapOptional: <nil>
DownwardAPI: true
QoS Class: BestEffort
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 46m default-scheduler Successfully assigned default/nginx-v4cxc to k-m-1
Normal Pulling 46m kubelet Pulling image "nginx:latest"
Normal Pulled 45m kubelet Successfully pulled image "nginx:latest" in 27.536363769s
Normal Created 45m kubelet Created container nginx
Normal Started 45m kubelet Started container nginx
# 接下来我们来看看CloneSet多了哪儿些新功能
1:扩缩容
cloneset.spec.scaleStrategy下面有一个参数是podsToDelete,这个参数可以指定删除哪儿些Pod,比如HPA扩容出来的Pod,本来是无法控制删除哪儿些Pod的,但Kruise它就支持删除扩容出来的Pod,而原来的Pod依旧保留。
cloneset.spec.scaleStrategy下面还有一个maxUnavailable,指定最大不可用的Pod数量,用于控制CloneSet的副本变化的速率,尽量减少对用户的影响,如果在扩容时不可用的Pod大于这个配置时,则缩容失败,并且这个参数仅在扩容时生效
# 下面是配置
apiVersion: apps.kruise.io/v1alpha1
kind: CloneSet
metadata:
name: nginx
namespace: default
labels:
app: nginx
spec:
replicas: 5
minReadySeconds: 60
# 结合上面的minReadySeconds表示在扩容的时候只有当上一个扩容出来的Pod已经Ready了60s之后才会继续扩容下一个副本
scaleStrategy:
maxUnavailable: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:latest
ports:
- name: http
containerPort: 80
# 更新一下配置
[root@k-m-1 openkruise]# kubectl apply -f nginx.yaml
cloneset.apps.kruise.io/nginx configured
# 那么我们需要等待一会儿,大约四分钟左右才会启动全部的Pod,待会儿根据Pod的启动时间我们就可以观测出效果了
[root@k-m-1 openkruise]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-4n8js 1/1 Running 0 68s
nginx-7pftf 1/1 Running 0 4m20s
nginx-hlmhz 1/1 Running 0 5s
nginx-qg46n 1/1 Running 0 2m13s
nginx-xqw6n 1/1 Running 0 3m16s
# 从这里可以看一些猫腻了吧从四分钟到三分钟除去启动Pod的时间,相隔了60s,一个个推下来都是一样的结果,这个就是我们前面设置的策略的重点了。
# 那么这个时候比如说我们想指定的Pod进行缩容,原来的控制器肯定是不支持的,但是我们前面说了,podsToDelete它支持,那么我们来看看它是如何支持的。
apiVersion: apps.kruise.io/v1alpha1
kind: CloneSet
metadata:
name: nginx
namespace: default
labels:
app: nginx
spec:
# 缩容的话需要将副本调整一下
replicas: 4
minReadySeconds: 60
scaleStrategy:
maxUnavailable: 1
# 直接指定需要删除的Pod名称即可
podsToDelete:
- nginx-7pftf
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:latest
ports:
- name: http
containerPort: 80
# 更新配置
[root@k-m-1 openkruise]# kubectl apply -f nginx.yaml
cloneset.apps.kruise.io/nginx configured
# 对比之前的配置,发现好像真的把指定的Pod缩容没了
# 缩容前
[root@k-m-1 openkruise]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-4n8js 1/1 Running 0 68s
nginx-7pftf 1/1 Running 0 4m20s
nginx-hlmhz 1/1 Running 0 5s
nginx-qg46n 1/1 Running 0 2m13s
nginx-xqw6n 1/1 Running 0 3m16s
# 缩容后
[root@k-m-1 openkruise]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-4n8js 1/1 Running 0 6m52s
nginx-hlmhz 1/1 Running 0 5m49s
nginx-qg46n 1/1 Running 0 7m57s
nginx-xqw6n 1/1 Running 0 9m
# 再看一下控制器的Events
[root@k-m-1 openkruise]# kubectl describe clonesets.apps.kruise.io nginx
......
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulCreate 12m cloneset-controller succeed to create pod nginx-7pftf
Normal SuccessfulCreate 11m cloneset-controller succeed to create pod nginx-xqw6n
Normal SuccessfulCreate 9m57s cloneset-controller succeed to create pod nginx-qg46n
Warning ScaleUpLimited 8m52s (x18 over 11m) cloneset-controller scaleUp is limited because of scaleStrategy.maxUnavailable, limit: 0
Warning ScaleUpLimited 8m52s (x3 over 11m) cloneset-controller scaleUp is limited because of scaleStrategy.maxUnavailable, limit: 1
Normal SuccessfulCreate 8m52s cloneset-controller succeed to create pod nginx-4n8js
# 可以看到这里删除的就是指定的Pod
Normal SuccessfulDelete 2m3s cloneset-controller succeed to delete pod nginx-7pftf
# 那么这就是关于cloneSet中scaleStrategy字段的用法了。
# 下面我们看到的一个功能在原始的Deployment中是没有的,也就是PVC模板功能,它是一个比较奇特的特性,CloneSet允许用户配置PVC模板,volumeClaimTemplates,用来给每个Pod生成独享的PVC,这是Deployment所不支持的,因为往往有状态应用才需要单独配置PVC,在使用CloneSet的PVC模板的时候需要注意下面的事项
1:每个被自动创建的PVC会有一个ownerReference指向CloneSet,因此CloneSet被删除时,它创建的所有Pod和PVC都会被删除。
2:每个被CloneSet创建的Pod和PVC,都会带一个apps.kruise.io/cloneset-instance-id: xxx的label,关联的Pod和PVC会有相同的instance-id,且它们的后缀都是这个instance-id
3:如果一个Pod被CloneSet Controller缩容删除时,这个Pod关联的PVC都会被一起删掉。
4:如果一个Pod被外部直接调用删除或驱逐时,这个Pod关联的PVC还都存在,并且CloneSet Controller发现数量不足重新扩容时,新扩容出来的Pod会复用原来的Pod的instance-id并关联原来的PVC
5:当Pod被重建升级时,关联的PVC会跟随Pod一起被删除,新建
6:当Pod被原地升级时,关联的PVC会持续使用。
# 下面我们来看一个例子
apiVersion: apps.kruise.io/v1alpha1
kind: CloneSet
metadata:
name: nginx
namespace: default
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:latest
ports:
- name: http
containerPort: 80
volumeMounts:
- name: data
mountPath: /usr/share/nginx/html
volumeClaimTemplates:
- metadata:
name: data
spec:
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 1Gi
# 部署一下
[root@k-m-1 openkruise]# kubectl get pod,pv,pvc
NAME READY STATUS RESTARTS AGE
pod/nginx-2hc8t 1/1 Running 0 13s
pod/nginx-46fdf 1/1 Running 0 13s
pod/nginx-clxww 1/1 Running 0 13s
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
pvc-3c6ba484-8a03-47f6-b4b3-3865f378af5f 1Gi RWO Delete Bound default/data-nginx-clxww managed-nfs-storage 28s
pvc-5195b310-7405-433d-8cb1-b0956d5315ba 1Gi RWO Delete Bound default/data-nginx-2hc8t managed-nfs-storage 28s
pvc-78ab8de0-6baa-4eea-a218-76b43bad4a28 1Gi RWO Delete Bound default/data-nginx-46fdf managed-nfs-storage 28s
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
persistentvolumeclaim/data-nginx-2hc8t Bound pvc-5195b310-7405-433d-8cb1-b0956d5315ba 1Gi RWO managed-nfs-storage 13s
persistentvolumeclaim/data-nginx-46fdf Bound pvc-78ab8de0-6baa-4eea-a218-76b43bad4a28 1Gi RWO managed-nfs-storage 13s
persistentvolumeclaim/data-nginx-clxww Bound pvc-3c6ba484-8a03-47f6-b4b3-3865f378af5f 1Gi RWO managed-nfs-storage 13s
# 观察Pod和PVC的标签
[root@k-m-1 openkruise]# kubectl get pod,pvc -l apps.kruise.io/cloneset-instance-id=clxww
NAME READY STATUS RESTARTS AGE
pod/nginx-clxww 1/1 Running 0 5m13s
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
persistentvolumeclaim/data-nginx-clxww Bound pvc-3c6ba484-8a03-47f6-b4b3-3865f378af5f 1Gi RWO managed-nfs-storage 5m13s
# 可以看到是一一绑定的,所以这也就对应了前面我们讲的,它们有一个instance-id是一致的。
# 这里我没有指定storageclass的原因是因为我的集群内存在一个Default的storageclass,具体的配置需要跟着k8s的版本走的,我这里有篇文章,大家可以去了解一下如何配置:https://www.cnblogs.com/layzer/articles/default_storage_class.html
# 但是我们要记住,这种方式删除Pod的时候它的PVC也会随着一起删除,所以大家请慎重考虑这种方式
# 前面我们也提到了CloneSet也提供原地升级的策略,CloneSet支持三种升级方式
1:ReCreate:删除旧Pod和它的PVC,然后用新版本重新创建出来,这是默认的方式
2:InPlaceIfPossible:会优先尝试原地升级Pod,如果不行再采用重建升级
3:InPlaceOnly:只允许采用原地升级,因此,用户只能修改上一条中的限制字段,如果尝试修改其他字段会被拒绝
# 这里有一个比较重要的概念:原地升级,这是OpenKruise提供的核心功能之一,当我们要升级一个Pod中镜像的时候,我们来看看对比
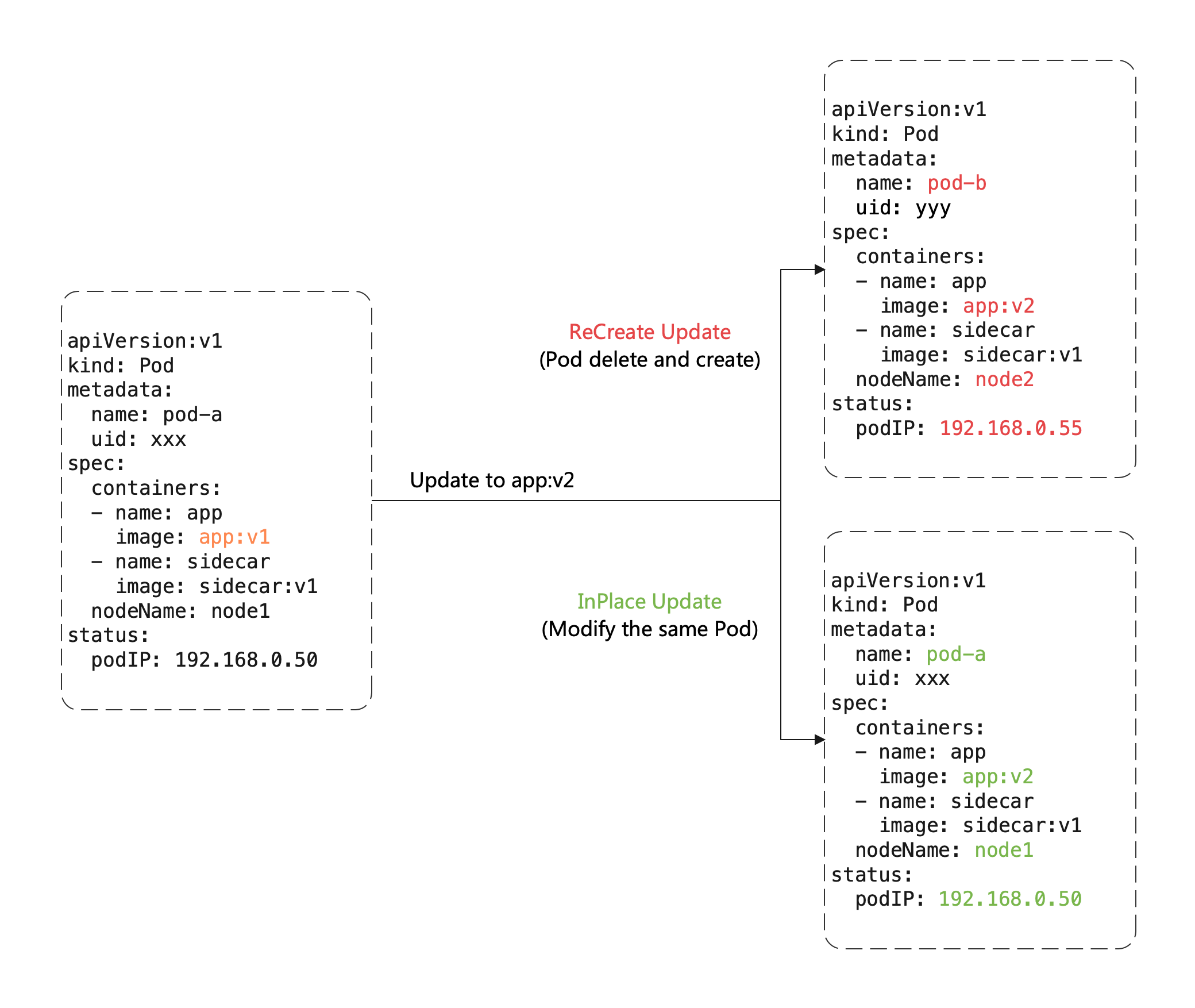
# 重建升级时我们需要删除旧Pod,创建新的Pod:
1:Pod名字和uid发生变化,以为它们是完全不同的两个Pod对象(比如Deployment升级)
2:Pod名字可能不变,但是uid变化,因为它们是不同的Pod对象,只是复用了同一个名字(比如StatefulSet升级)
3:Pod所在的Node名字可能发生变化,因为新Pod可能不会调度到之前所在的Node节点
4:Pod IP发生变化,因为新Pod很大可能性是不会被分配之前的IP地址
# 但是对于原地升级,我们仍然复用同一个Pod对象,只是修改它里面的字段:
1:可以避免调度,分配IP,挂载Volume等额外的操作和代价
2:更快的镜像拉取,因为复用的是已有旧镜像的大部分layer层,只需要拉取新镜像变化的一些layer
3:当一个容器原地升级时,Pod中其他的容器不会受到影响,仍然可以运行
# 所以显然效果能用原地升级方式来升级我们的工作负载,对在线应用的影响是最小的,上面我们提到了CloneSet升级类型支持InPlaceIfPossible,这意味着kruise会尽量对Pod采取原地升级,如果不能则退化到重建升级,以下改动会被允许指定原地升级:
1:更新Workload中的spec.template.metadata.*,比如labels/annotations,kruise只会将metadata中的修改更新到存量Pod上
2:更新Workload中的spec.template.spec.containers[x].image,kruise会原地升级Pod中这些容器的镜像,而不重建整个Pod
3:从kruise v1.0版本开始,更新spec.template.metadata.labels/annotations并且container中配置envfrom这些改动的labels/annotations,kruise会原地升级这些容器来生效新的env值。
否则,其他字段的改动,比如spec.template.spec.containers[x].env或spec.template.spec.containers[x].resource都是会回退到重建升级。
比如我们将上面应用的升级方式设置为InPlaceIfPossible,只需要在资源清单中添加spec.updateStrategy.type: InPlaceIfPossible即可:
apiVersion: apps.kruise.io/v1alpha1
kind: CloneSet
metadata:
name: nginx
namespace: default
labels:
app: nginx
spec:
replicas: 3
updateStrategy:
type: InPlaceIfPossible
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:latest
ports:
- name: http
containerPort: 80
# 部署应用
[root@k-m-1 openkruise]# kubectl apply -f nginx.yaml
cloneset.apps.kruise.io/nginx created
[root@k-m-1 openkruise]# kubectl describe clonesets.apps.kruise.io nginx
......
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulCreate 60m cloneset-controller succeed to create pod nginx-6gbqd
Normal SuccessfulCreate 60m cloneset-controller succeed to create pod nginx-j87ch
Normal SuccessfulCreate 60m cloneset-controller succeed to create pod nginx-jsgdg
Normal SuccessfulUpdatePodInPlace 45s cloneset-controller successfully update pod nginx-6gbqd in-place(revision nginx-6c7d6467d)
Normal SuccessfulUpdatePodInPlace 31s cloneset-controller successfully update pod nginx-jsgdg in-place(revision nginx-6c7d6467d)
Normal SuccessfulUpdatePodInPlace 26s cloneset-controller successfully update pod nginx-j87ch in-place(revision nginx-6c7d6467d)
[root@k-m-1 openkruise]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-6gbqd 1/1 Running 1 (72s ago) 60m
nginx-j87ch 1/1 Running 1 (54s ago) 60m
nginx-jsgdg 1/1 Running 1 (59s ago) 60m
# 可以看的出Pod的名称,创建时间一个没变 只是重启了一下其他都没有任何变化,基于控制器的Events可以看出一些端倪的,这就是原地升级的好处啦,下面我们看一下原地升级的整体工作流程是怎样的
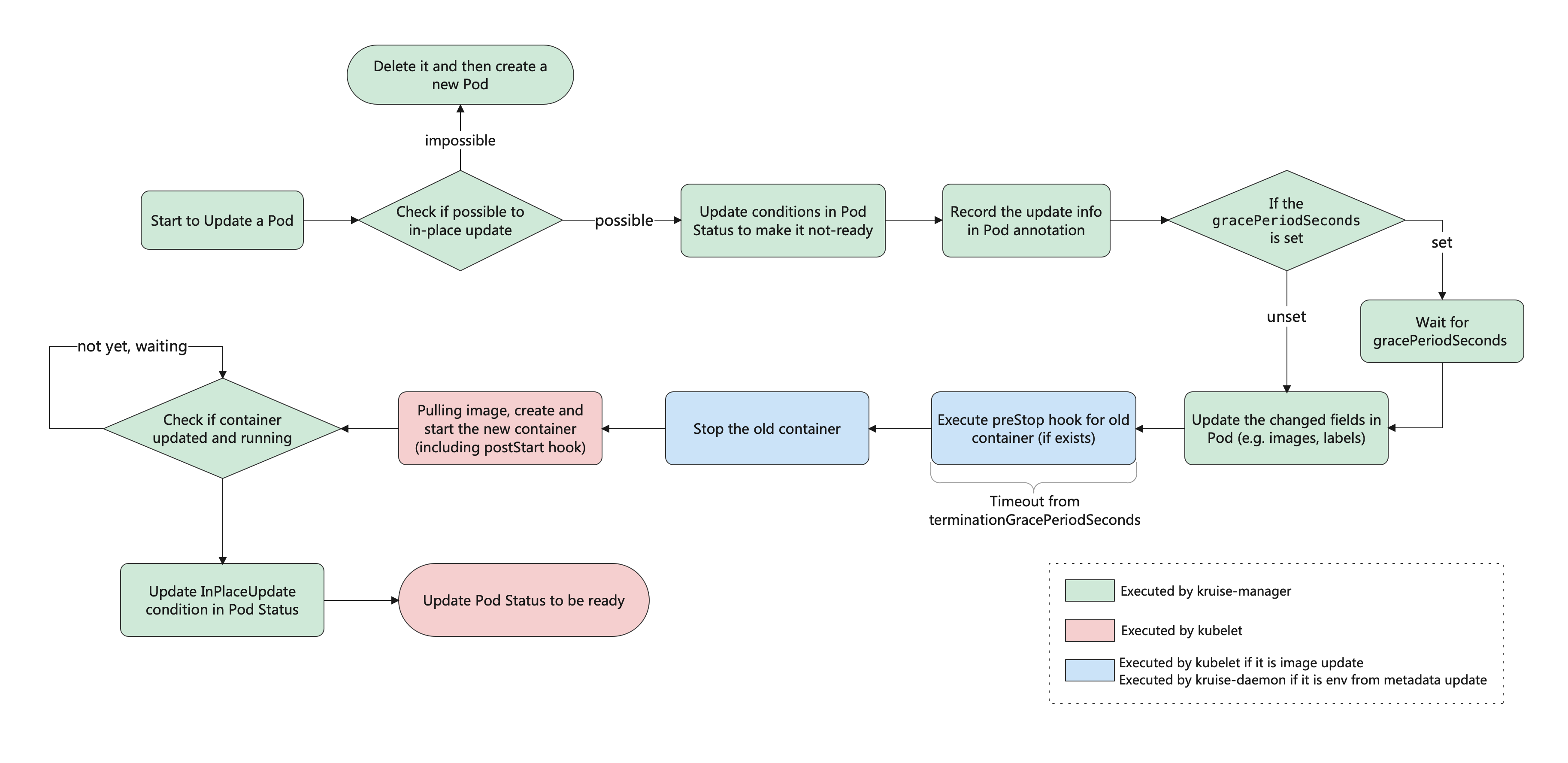
如果你安装或升级Kruise的时候启用了PreDownloadImageForInPlaceUpdate这个feature-gate,CloneSet控制器会自动在所有旧版本Pod所在的节点上预热你正在灰度发布的新版本镜像,这对于应用发布加速有很大帮助。
默认情况下CloneSet每个新镜像预热的并发度都是1,也就是一个节点拉取镜像,如果需要调整,你可以在CloneSet通过apps.kruise.io/image-predownload-parallelism这个annotation来设置并发度。
另外从kruise v1.1.0开始,还可以使用apps.kruise.io/image-predownload-min-updated-ready-pods来控制在少量新版本Pod已经升级成功之后再执行镜像预热,它的值可能是绝对值数字或者是百分比。
apiVersion: apps.kruise.io/v1alpha1
kind: CloneSet
metadata:
annotations:
apps.kruise.io/image-predownload-parallelism: "5"
apps.kruise.io/image-predownload-min-updated-ready-pods: "2"
# 注意,为了避免大量不必要的镜像拉取,目前只针对replicas > 3的CloneSet做自动预热。
此外CloneSet还支持分批次进行灰度,在updateStrategy属性中可以配置partition参数,该参数可以用来保留旧版本Pod的数量或百分比,默认为0
1:如果是数字:控制器会将(replicas - partition)的数量的Pod更新到最新版本
2:如果是百分比:控制器会将(replicas * (100% - partition))数量的Pod更新到最新版本
比如我们将上面示例中过的images更新为latest并且设置partition为2,更新后再查看一下结果
apiVersion: apps.kruise.io/v1alpha1
kind: CloneSet
metadata:
name: nginx
namespace: default
labels:
app: nginx
annotations:
apps.kruise.io/image-predownload-parallelism: "5"
apps.kruise.io/image-predownload-min-updated-ready-pods: "2"
spec:
replicas: 4
updateStrategy:
type: InPlaceIfPossible
# 表示只会保留两个旧版本的Pod
partition: 2
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:latest
ports:
- name: http
containerPort: 80
# 部署更新一下
[root@k-m-1 openkruise]# kubectl apply -f nginx.yaml
cloneset.apps.kruise.io/nginx configured
# 查看结果是否如我们所料
[root@k-m-1 openkruise]# kubectl get pod -o custom-columns='DATA:metadata.name,CONTAINERS:spec.containers[*].name,IMAGES:spec.containers[*].image'
DATA CONTAINERS IMAGES
nginx-5g84w nginx nginx:alpine
nginx-cgzcm nginx nginx:latest
nginx-skzqg nginx nginx:latest
nginx-tzwg6 nginx nginx:alpine
# 可以看到结果的确是按照我们的预期,保留了两个alpine的版本的Pod,其他的全部升级了
此外CloneSet还支持一些更高级的用法,比如可以定义优先级策略来控制Pod发布的优先级规则,还可以定义策略来将一类的Pod打散到整个发布过程中,也可以暂停Pod发布等操作。
# 声明周期钩子
每个CloneSet管理的Pod会有明确所处的状态,在Pod Label中的lifecycle.apps.kruise.io/state标记:
1:Normal:正常状态
2:PreparingUpdate:准备原地升级
3:Updating:原地升级中
4:Updated:原地升级完成
5:PreparingDelete:准备删除
而生命周期钩子,则是通过在上述状态流转中卡点,来实现原地升级前后,删除前的自定义操作,比如(开关流量,告警等)。
CloneSet的lifecycle下面主要支持preDelete和inPlaceUpdate两个属性
apiVerison: apps.kruise.io/v1alpha1
kind: CloneSet
spec:
# 通过finalizer定义Hook
lifecycle:
preDelete: # PreDelete是Pod被删除之前的Hook
finalizersHandler:
- example.com/unready-blocker
inPlaceUpdate: # InPlaceUdpate是Pod更新之前和更新之后的Hook
finalizersHandler:
- example.com/unready-blocker
# 或者也可以通过label定义
lifecycle:
inPlaceUpdate:
labelsHandler:
example.io/block-unready: "true"
如果设置preDelete.markPodNotReady=true:
1:kruise将会在Pod进入PreparingDelete状态时,将KruisePodReady这个Pod Condition设置为False,Pod将变为NotReady。
2:Kruise将会尝试将KruisePodReady这个Pod Condition设置回True
我们可以利用这一特性,在容器真正被停止之前将Pod的流量先行排除,防止流量损失。
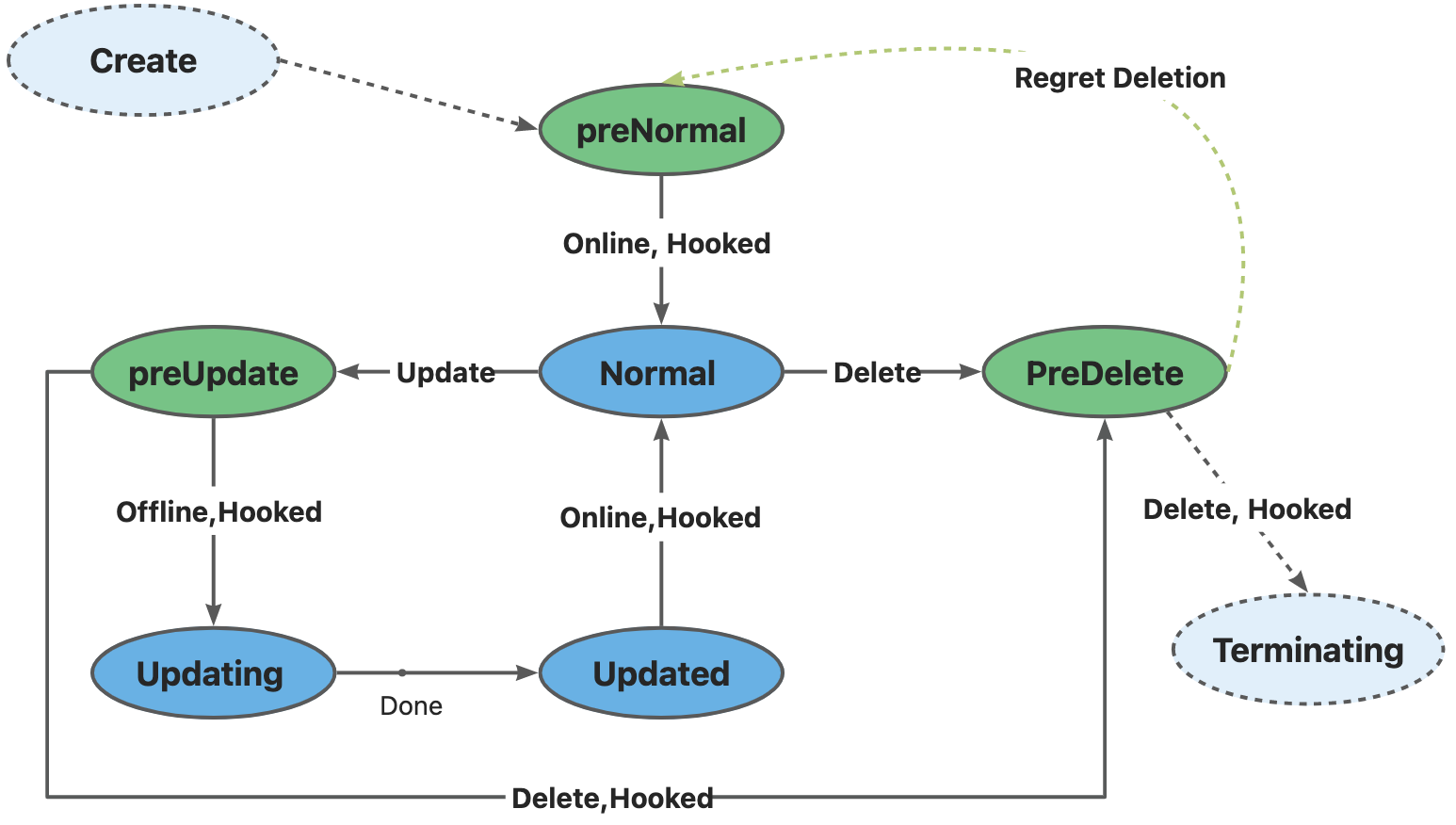
当 CloneSet 创建一个 Pod(包括正常扩容和重建升级)时:
1:如果 Pod 满足了 PreNormal hook 的定义,才会被认为是 Available,并且才会进入 Normal 状态;
2:这对于一些 Pod 创建时的后置检查很有用,比如你可以检查Pod是否已经挂载到SLB后端,从而避免滚动升级时,旧实例销毁后,新实例挂载失败导致的流量损失;
当 CloneSet 删除一个 Pod(包括正常缩容和重建升级)时:
1:如果没有定义 lifecycle hook 或者 Pod 不符合 preDelete 条件,则直接删除
2:否则,先只将 Pod 状态改为 PreparingDelete。等用户 controller 完成任务去掉 label/finalizer、Pod 不符合 preDelete 条件后,kruise 才执行 Pod 删除
3:注意:PreparingDelete 状态的 Pod 处于删除阶段,不会被升级
当 CloneSet 原地升级一个 Pod 时:
1:升级之前,如果定义了 lifecycle hook 且 Pod 符合 inPlaceUpdate 条件,则将 Pod 状态改为 PreparingUpdate
2:等用户 controller 完成任务去掉 label/finalizer、Pod 不符合 inPlaceUpdate 条件后,kruise 将 Pod 状态改为 Updating 并开始升级
3:升级完成后,如果定义了 lifecycle hook 且 Pod 不符合 inPlaceUpdate 条件,将 Pod 状态改为 Updated
4:等用户 controller 完成任务加上 label/finalizer、Pod 符合 inPlaceUpdate 条件后,kruise 将 Pod 状态改为 Normal 并判断为升级成功
关于从 PreparingDelete 回到 Normal 状态,从设计上是支持的(通过撤销指定删除),但我们一般不建议这种用法。由于 PreparingDelete 状态的 Pod 不会被升级,当回到 Normal 状态后可能立即再进入发布阶段,对于用户处理 hook 是一个难题。
# 用户Controller逻辑示例
按上述例子,可以定义:
1:example.com/unready-blocker finalizer作为hook
2:example.com/initialing annotation作为初始化标记
在CloneSet template模板里面带上这个字段
apiVersion: apps.kruise.io/v1alpha1
kind: CloneSet
spec:
template:
metadata:
annotations:
example.io/initialing: "true"
finalizers:
- example.com/unready-blocker
# ...
lifecycle:
preDelete:
finalizersHandler:
- example.com/unready-blocker
inPlaceUpdate:
finalizersHandler:
- example.com/unready-blocker
而后用户 controller 的逻辑如下:
1:对于刚创建出来的 Pod,其会处于 PreparingNormal 状态,当检查该 Pod 满足Available的标准后,将example.io/unready-blocker添加到 Pod 上, Pod 会转入 Normal 的可用状态。
2:对于 PreparingDelete 和 PreparingUpdate 状态的 Pod,切走流量,并去除 example.io/unready-blocker finalizer
3:对于 Updated 状态的 Pod,接入流量,并打上 example.io/unready-blocker finalizer
# 使用场景
因为各种原因和客观因素,有些用户可能无法将整套架构迁移到K8S上,比如有些用户暂时无法使用Kubernetes本身提供的Service发现机制,而是使用了独立于Kubernetes之外的另外一套服务注册和发现体系,在这种架构下,如果用户对服务进行Kubernetes化改造,可能会遇到很多问题,例如,每当Kubernetes成功创建出一个Pod的时候,都需要自行将该Pod注册到服务发现中心,以便能够对外提供服务,相应的,想要下线一个Pod,也通常先要将其在服务发现中心删除,才能将Pod优雅的下线,否则就可能导致流量丢失,但是在原生的Kubernetes体系中,Pod的生命周期由Workload管理(例如Deployment),当这些Workload的Replicas字段发生变化后,相应的Controller会立即添加或删除掉Pod,用户很难定制化地去管理Pod的生命周期
面对这一类问题,一般来说有两种解决思路:
1:约束kubernetes的弹性能力,例如规定只能由特定的链路对Workload进行扩缩容,以保证在Pod删除前先把Pod IP在服务注册中心摘除,但是这样一来会制约kubernetes本身的弹性能力,并且增加了链路管控的难度和风险。
2:在根本上改造现有的服务发现体系,显然是一个更加漫长和高风险的事情。
那么有没有一种既能够充分利用Kubernets弹性能力,又避免对既有的服务发现体系进行改造,快速弥补两个系统之间的间隙的方法呢?
OpenKruise CloneSet就提供了这样一组高度可定制化的扩展能力来专门应对此类场景,让用户能够对Pod生命周期做更精细化,定制化的管理。CloneSet在Pod生命周期中几个重要的时间节点留了Hook,使得用户可以在这些时间点插入一些定制化的扩展动作。比如,在Pod升级前,将Pod IP在服务发现中删除,升级完成后再将Pod IP注册到服务发现中心,或者做一些特殊的嗅探和监控动作。
我们假设一个场景:
1:用户不使用Kubernetes Service作为服务发现机制,服务发现体系完全独立于Kubernetes
2:使用CloneSet作为Kubernetes工作负载
并且对具体需求做如下合理假设:
1:当Kubernetes Pod被重建时:
1:在创建成功,且Pod Ready之后,将Pod IP注册到服务发现中心
2:当Kubernetes Pod原地升级时:
1:在升级之前,需要将Pod IP从服务发现中心删除(或者主动FailOver)
2:在升级完成,且Pod Ready之后,将Pod IP再次注册到服务发现中心
3:当Kubernetes Pod被删除时:
1:在删除之前,需要先将Pod IP从服务发现中心删除
基于以上的假设,其实我们就可以利用CloneSet Lifecycle 来编写一个简单的Operator实现用户定义的Pod生命周期管理机制。
前面我们提到了CloneSet Lifecycle将Pod的生命周期定义为了5种状态,5种状态之间的转换逻辑由一个状态机所控制。
我们可以选自己关心的一种或者多种,编写一个独立的Operator来实现这些状态的转换,控制Pod的生命周期,并在所关心的时间节点插入自己定制化的逻辑
apiVersion: apps.kruise.io/v1alpha1
kind: CloneSet
metadata:
name: nginx
namespace: default
spec:
replicas: 3
lifecycle:
inPlaceUpdate:
labelsHandler:
# 定义标签:
# 1:为CloneSet控制器阻止原地更新Pod的操作
# 2:通知operator执行inPlace update钩子
example.com/unready-blocker-inplace: "true"
preDelete:
labelsHandler:
example.com/unready-blocker-delete: "true"
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
# 这个标签可以用来判断此Pod是否是新建的
app: nginx
# 对应于spec.lifecycle.inPlaceUpdate.labelsHandler.example.com/unready-blocker-inplace
example.com/newly-create: "true"
# 对应spec.lifecycle.preDelete.labelsHandler.example.com/unready-blocker-inplace
example.com/unready-blocker-inplace: "true"
containers:
- name: nginx
image: nginx:latest
updateStrategy:
maxUnavailable: 20%
type: InPlaceIfPossible
下面是一个Operator的核心代码
const (
deleteHookLabel = "example.com/unready-blocker-delete"
inPlaceHookLabel = "example.com/unready-blocker-inplace"
newlyCreateLabel = "example.com/newly-create"
)
func (r *SampleReconciler) Reconcile(req ctrl.Request) (ctrl.Result, error) {
... ...
switchLabel := func(pod *v1.Pod, value string) error {
body := fmt.Sprintf(`{"metadata":{"labels":{"%s":"%s"}}}`, key, value)
if err := r.Patch(context.TODO(), pod, client.RawPatch(types.StrategicMergePatchType, []byte(body))); err != nil {
return err
}
return nil
}
switch{
case IsNewlyCreateHooked(pod):
if err := postRegistry(pod); err != nil {
return reconcle.Result{}, err
}
if err := switchLabel(pod, newlyCreateLabel, "false"); err != nil {
return reconcle.Result{}, err
}
case IsPreUpdateHooked(pod):
if err := postFailOver(pod); err != nil {
return reconcile.Result{}, err
}
if err := switchLabel(pod, inPlaceHookLabel, "false"); err != nil {
return reconcile.Result{}
}
case IsUpdatedHooked(pod):
if err := postRegistry(pod); err != nil {
return reconcile.Result{}, err
}
if err := switchLabel(pod, inPlaceHookLabel, "true"); err != nil {
return reconcile.Result{}, err
}
case IsPreDeleteHooked(pod):
if err := postUnregister(pod); err != nil {
return reconcile.Result, err
}
if err := switchLabel(pod, deleteHookLabel, "fasle"); err != nil {
return reconcile.Result{}, err
}
}
return ctrl.Result{}, nil
}
func IsNewlyCreateHooked(pod *v1.Pod) bool {
return kruiseappspub.LifecycleStateType(pod.Labels[kruiseappspub.LifecycleStateKey]) == kruiseappspub.LifecycleStateNormal && pod.Labels[newlyCreateLabel] == "true" && IsPodReady(pod)
}
func IsPreUpdateHooked(pod *v1.Pod) bool {
return kruiseappspub.LifecycleStateType(pod.Labels[kruiseappspub.LifecycleStateKey]) == kruiseappspub.LifecycleStatePreparingUpdate && pod.Labels[inPlaceHookLabel] == "true"
}
func IsUpdateHooked(pod *v1.Pod) bool {
return kruiseappspub.LifecycleStateType(pod.Labels[kruiseappspub.LifecycleStateKey]) == kruiseappspub.LifecycleStateUpdated && pod.Labels[inPlaceHookLabel] == "false" && IsPodReady(pod)
}
func IsPreDeleteHooked(pod *v1.Pod) bool {
return kruiseappspub.LifecycleStateType(pod.Labels[kruiseappspub.LifecycleStateKey]) == kruiseappspub.LifecycleStatePreparingDelete && pod.Labels[DeleteHookLabel] == "true"
}
上述代码中四个分支分别从上到下对应了Pod创建后,升级前,升级后,删除前四个重要生命周期节点,我们可以根据自己的实际需求来完善相应的Hook,我们这里上述几个Hook的具体行为:
1:postRegistry(pod *v1.Pod):发送请求通知服务发现中心注册该Pod服务
2:postFailOver(pod *v1.Pod):发送请求通知服务发现中心Fail Over该Pod服务
3:postUnregister(pod *v1.Pod):发送请求通知服务发现中心将该Pod服务注销
这就是CloneSet Lifecycle的强大之处,我们完全可以根据需求在Pod生命周期管理中插入强大的定制化逻辑。
6:OpenKruise之其他控制器
上面我们学习了CloneSet的基本的控制器,接下来我们就来继续看一看OpenKruise支持的其它控制器是做了哪儿些扩展
6.1:Advanced Statefulset
该控制器在原生的Statefulset的基础上增强了发布的能力,比如maxUnavailable并行发布,原地升级等,该对象的名称也是Statefulset,但是apiVersion是apps.kruise.io/v1beta1,这个CRD的所有默认字段,默认行为与原生Statefulset完全一致,除此自外还提供了一些可选字段来扩展增强的策略,因此,用户从原生的Statefulset迁移到Advacnced Statefulset,只需要把ApiVersion修改提交即可
- apiVersion: apps/v1
+ apiVersion: apps.kruise.io/v1beta1
kind: StatefulSet
metadata:
name: sample
spec:
# ...
# 最大不可用
Advanced StatefulSet在滚动更新策略中新增了maxUnavailable来支持并行Pod发布,它会保证发布过程中最多有多少个Pod处于不可用状态,注意,maxUnavailable只能配合podManagementPolicy为Parallel来使用。
这个策略的效果和Depliyment中的类似,但是可能会导致发布过程中的order顺序不能严格保证,如果不配置maxUnavailable,它的默认值为1,也就是和原生StatefulSet一样只能串行发布Pod,即使把podManagementPolicy配置为Parallel也是这样。
比如我们创建一个资源来看一下
apiVersion: apps.kruise.io/v1beta1
kind: StatefulSet
metadata:
name: nginx
namespace: default
spec:
serviceName: "nginx-headless"
podManagementPolicy: Parallel
replicas: 5
updateStrategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:latest
ports:
- name: http
containerPort: 80
# 部署一下
[root@k-m-1 openkruise]# kubectl apply -f nginx-sts.yaml
statefulset.apps.kruise.io/nginx created
# 查看创建时间
[root@k-m-1 openkruise]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-0 1/1 Running 0 4h37m
nginx-1 1/1 Running 0 4h37m
nginx-2 1/1 Running 0 4h37m
nginx-3 1/1 Running 0 4h37m
nginx-4 1/1 Running 0 4h37m
# 可以看到貌似是并行创建,而并非是创建一个之后再创建一个这样子,可能看不出来,那么我们再部署一个使用原生Statefulset控制器的应用
[root@k-m-1 openkruise]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-a-0 1/1 Running 0 32s
nginx-a-1 1/1 Running 0 32s
nginx-a-2 1/1 Running 0 32s
nginx-a-3 1/1 Running 0 32s
nginx-a-4 1/1 Running 0 32s
nginx-b-0 1/1 Running 0 32s
nginx-b-1 1/1 Running 0 26s
nginx-b-2 1/1 Running 0 13s
nginx-b-3 1/1 Running 0 9s
nginx-b-4 1/1 Running 0 5s
# 这一次看的应该很清楚了,应用a的创建时间是并行,都是一致的,而应用b的创建时间却是有先后顺序的,这就证明了应用a是并行,而应用b却是有先后顺序的。
# 那么,我们在资源清单内配置了一个最大允许不活跃的Pod数量为3,那么我们更新一下资源之后看看情况,我们可以看到如下的效果
[root@k-m-1 openkruise]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-a-0 1/1 Running 0 38s
nginx-a-1 1/1 Running 0 38s
nginx-a-2 0/1 ContainerCreating 0 4s
nginx-a-3 0/1 ContainerCreating 0 2s
nginx-a-4 0/1 ContainerCreating 0 4s
# 也就意味着,同时只有三个Pod允许更新,保留其他的提供服务,然后三个更新完成之后再更新其他的,那么我们同样的也可以配置一个partition的值,那么这个值,就是statefulset应用的order的值大于或者等于我们配置的partition才会更新,那么我们来看看,比如我们配置一个4
apiVersion: apps.kruise.io/v1beta1
kind: StatefulSet
metadata:
name: nginx-a
namespace: default
spec:
serviceName: "nginx-headless"
podManagementPolicy: Parallel
replicas: 5
updateStrategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 3
partition: 4
selector:
matchLabels:
app: nginx-a
template:
metadata:
labels:
app: nginx-a
spec:
containers:
- name: nginx
# 将alpine替换掉
image: nginx:latest
ports:
- name: http
containerPort: 80
[root@k-m-1 openkruise]# kubectl get pod -o custom-columns='DATA:metadata.name,CONTAINERS:spec.containers[*].name,IMAGES:spec.containers[*].image'
DATA CONTAINERS IMAGES
nginx-a-0 nginx nginx:alpine
nginx-a-1 nginx nginx:alpine
nginx-a-2 nginx nginx:alpine
nginx-a-3 nginx nginx:alpine
nginx-a-4 nginx nginx:latest
# 其实这个就是Statefulset提供的一个类似灰度的功能,当功能测试完成可以使用的时候我们就将partition的值配置为0再次更新一下清单,即可全部发布,并且是并发更新,其次呢,Kruise的Statefulset也同样支持原地升级,那么我们来看看如何配置。
apiVersion: apps.kruise.io/v1beta1
kind: StatefulSet
metadata:
name: nginx-a
namespace: default
spec:
serviceName: "nginx-headless"
podManagementPolicy: Parallel
replicas: 5
updateStrategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 3
partition: 4
# 优先使用原地升级策略
podUpdatePolicy: InPlaceIfPossible
# 原地升级后等待多久再进行下一个Pod的更新
inPlaceUpdateStrategy:
gracePeriodSeconds: 10
selector:
matchLabels:
app: nginx-a
template:
metadata:
labels:
app: nginx-a
spec:
containers:
- name: nginx
# 替换一下latest为alpine
image: nginx:alpine
ports:
- name: http
containerPort: 80
# 但是这里我必须告诉大家,这个时候你去部署的时候绝对会被Webhook给拦截下来,其实就是它需要配readinessGates去使用才可以,那么我们更新一下
apiVersion: apps.kruise.io/v1beta1
kind: StatefulSet
metadata:
name: nginx-a
namespace: default
spec:
serviceName: "nginx-headless"
podManagementPolicy: Parallel
replicas: 5
updateStrategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 3
partition: 4
# 优先使用原地升级策略
podUpdatePolicy: InPlaceIfPossible
# 原地升级后等待多久再进行下一个Pod的更新
inPlaceUpdateStrategy:
gracePeriodSeconds: 10
selector:
matchLabels:
app: nginx-a
template:
metadata:
labels:
app: nginx-a
spec:
# 字段加在这里就可以了,它的意思就是确保Pod在原地升级的时候保持 not ready的状态,直到原地升级结束
readinessGates:
- conditionType: InPlaceUpdateReady
containers:
- name: nginx
# 替换一下latest为alpine
image: nginx:alpine
ports:
- name: http
containerPort: 80
[root@k-m-1 openkruise]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-a-0 1/1 Running 1 (24s ago) 83s
nginx-a-1 1/1 Running 1 (27s ago) 83s
nginx-a-2 1/1 Running 1 (41s ago) 83s
nginx-a-3 1/1 Running 1 (41s ago) 83s
nginx-a-4 1/1 Running 1 (42s ago) 83s
# 看到重启,我们就知道它的确是原地升级了
[root@k-m-1 openkruise]# kubectl get pod -o custom-columns='DATA:metadata.name,CONTAINERS:spec.containers[*].name,IMAGES:spec.containers[*].image'
DATA CONTAINERS IMAGES
nginx-a-0 nginx nginx:alpine
nginx-a-1 nginx nginx:alpine
nginx-a-2 nginx nginx:alpine
nginx-a-3 nginx nginx:alpine
nginx-a-4 nginx nginx:alpine
# 查看一下Events
[root@k-m-1 openkruise]# kubectl describe asts nginx-a
......
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulCreate 2m37s statefulset-controller create Pod nginx-a-0 in StatefulSet nginx-a successful
Normal SuccessfulCreate 2m37s statefulset-controller create Pod nginx-a-1 in StatefulSet nginx-a successful
Normal SuccessfulCreate 2m37s statefulset-controller create Pod nginx-a-2 in StatefulSet nginx-a successful
Normal SuccessfulCreate 2m37s statefulset-controller create Pod nginx-a-3 in StatefulSet nginx-a successful
Normal SuccessfulCreate 2m37s statefulset-controller create Pod nginx-a-4 in StatefulSet nginx-a successful
Normal SuccessfulUpdatePodInPlace 2m5s statefulset-controller successfully update pod nginx-a-4 in-place(revision nginx-a-79b799b689)
Normal SuccessfulUpdatePodInPlace 2m5s statefulset-controller successfully update pod nginx-a-3 in-place(revision nginx-a-79b799b689)
Normal SuccessfulUpdatePodInPlace 2m5s statefulset-controller successfully update pod nginx-a-2 in-place(revision nginx-a-79b799b689)
Normal SuccessfulUpdatePodInPlace 111s statefulset-controller successfully update pod nginx-a-1 in-place(revision nginx-a-79b799b689)
Normal SuccessfulUpdatePodInPlace 108s statefulset-controller successfully update pod nginx-a-0 in-place(revision nginx-a-79b799b689)
# 可以看到原地升级的Pod都在这里被列出来了,当然了我们还可以在更新策略里面配置一个暂停更新的方法,也就是比如在更新过程中不想更新了,那么我们就可以在更新策略下添加一个pause: true的参数,然后更新一下配置,就可以暂停更新了,不过这个功能基本是很少用的,但是我们需要知道有这个能力,那么除此之外,Kruise的Statefulset还有一个序号保留功能,它的字段叫做reserveOrdinals,它表示保留序号的Pod,比如我现在的序号是 0 1 2 3 4,然后配置这个参数为1的时候,创建资源之后它的预期效果应该是 0 2 3 4,这里副本我也调整为4,那么我们来实践一下
apiVersion: apps.kruise.io/v1beta1
kind: StatefulSet
metadata:
name: nginx-a
namespace: default
spec:
serviceName: "nginx-headless"
podManagementPolicy: Parallel
replicas: 4
# 主要是这个字段
reserveOrdinals: [1]
updateStrategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 3
partition: 0
podUpdatePolicy: InPlaceIfPossible
inPlaceUpdateStrategy:
gracePeriodSeconds: 10
selector:
matchLabels:
app: nginx-a
template:
metadata:
labels:
app: nginx-a
spec:
readinessGates:
- conditionType: InPlaceUpdateReady
containers:
- name: nginx
image: nginx:alpine
ports:
- name: http
containerPort: 80
[root@k-m-1 openkruise]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-a-0 1/1 Running 1 (9m19s ago) 10m
nginx-a-2 1/1 Running 1 (9m36s ago) 10m
nginx-a-3 1/1 Running 1 (9m36s ago) 10m
nginx-a-4 1/1 Running 1 (9m37s ago) 10m
# 可以看到,的确是保留了1这个序号,和我们前面的预期是一样的,当然它能实现的功能其实就是我们可以删除指定序号的Pod,我们只需要将指定序号的Pod写入进去,然后变更副本,数量就可以删除这个序号的副本了,当然想保留的话就不需要变更这个副本数了,会有一个顺序的序号Pod去接替它
# 为了避免一个新的Advanced StatefulSet创建出来后有大量的失败的pod被创建出来,从Kruise v0.10.0版本开始引入了在scale strategy中的maxUnavailable策略,这和CloneSet流式扩容是一样的。
apiVerison: apps.kruise.io/v1beta1
kind: StatefulSet
spec:
# ...
replicas: 100
scaleStrategy: 10%
当这个字段设置后,Advanced StatefulSet会保证创建pod之后不可用pod数量不超过这个限制值,比如,上面Statefulset一开始会创建100 * 10% = 10个pod,在此之后,每当一个Pod变为Running,ready状态后,才会创建一个新的pod出来。
# 注意,这个功能只允许在podManagementPolicy是Parallel的StatefulSet中使用。
同样Advanced Statefulset和CloneSet提供的生命周期钩子也是一样的,可以通过spec.lifecycle字段来设置
apiVersion: apps.kruise.io/v1beta1
kind: StatefulSet
spec:
# ...
lifecycle:
preDelete:
exec:
command:
- /bin/sh
- -c
- echo "preDelete"
6.2:Advanced DaemonSet
同样这个控制器基于原生的DamonSet上增强了发布能力,比如:灰度发布,按Node Label选择,暂停,热升级等。同样它的资源对象也是DaemonSet,只是apiVersion是apps.kruise.io/v1alpha1,这个CRD的所有默认字段,默认行为与原生的DaemonSet完全一致,除此之外,还提供了一些可选字段来扩展增强策略
因此,用户从云原生DaemonSet迁移到Advanced DaemonSet,只需要把apiVersion修改后提交即可
- apiVersion: apps/v1
+ apiVersion: apps.kruise.io/v1alpha1
kind: DaemonSet
metadata:
name: example
spec:
# ...
# 升级
Advanced DaemonSet在spec.updateStrategy.rollingUpdate中有一个rollingUpdateType字段,标识了如何进行滚动更新升级:
1:Standard:对于每个节点,控制器会先删除旧的daemon Pod,再创建一个新的Pod,和原生DaemonSet行为一致。同样也可以通过maxUnavailable或maxSurge来控制重建新旧Pod的顺序。
2:Surging:对于每个node,控制器会创建一个新Pod,对于ready之后再删除老Pod。
3:InPlaceIfPossible:控制器会尽量采用原地升级的方式,如果不行则再重建升级,注意,在这个类型下,只能使用maxUnavailable而不可以用maxSurge。
apiVersion: apps.kruise.io/v1alpha1
kind: DaemonSet
metadata:
name: nginx
namespace: default
labels:
app: nginx
spec:
updateStrategy:
type: RollingUpdate
rollingUpdate:
rollingUpdateType: Standard
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:latest
ports:
- name: http
containerPort: 80
# 我们部署一下
[root@k-m-1 openkruise]# kubectl apply -f nginx-ds.yaml
daemonset.apps.kruise.io/nginx created
[root@k-m-1 openkruise]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-l5rct 1/1 Running 0 9s
# 需要注意的是原生的daemonset简写是ds,而kruise的叫做dameon,我这里是单节点集群,所以看不出效果的。
[root@k-m-1 openkruise]# kubectl get daemon
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE AGE
nginx 1 1 1 1 1 25s
# 其次我们来看看新增特性,在rollingUpdate下有一个特性是selector,它的存在意味着我们可以根据标签去寻找节点进行升级
apiVersion: apps.kruise.io/v1alpha1
kind: DaemonSet
metadata:
name: nginx
namespace: default
labels:
app: nginx
spec:
updateStrategy:
type: RollingUpdate
rollingUpdate:
rollingUpdateType: Standard
# 指定只升级匹配如下标签的节点的应用
selector:
matchLabels:
kubernetes.io/hostname: k-m-1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:latest
ports:
- name: http
containerPort: 80
# 因为我这里只有一个节点,所以看不出效果,如果节点多的话,就可有看出这个功能的效果了,比如我现在有100个节点,我的DaemonSet应用想在其中几个节点灰度测试一下,就可以用这种方式指定一下节点的labels,然后进行更新,这样就可以在指定的匹配的labels的node上升级,而其他的node上的应用不受影响。
# 同样的它也支持maxUnavailable和partition,这样的参数,而且功能都是一模一样的,这里面我们提一下,其实partition和selector的作用并非是一模一样的,只是功能类似,partition是控制旧的Pod数量,而selector是可以控制指定的节点Pod的升级的,同样的pause暂停发布也都是支持的。最重要的InPlaceIfPossible,原地升级的操作。
apiVersion: apps.kruise.io/v1alpha1
kind: DaemonSet
metadata:
name: nginx
namespace: default
labels:
app: nginx
spec:
updateStrategy:
type: RollingUpdate
rollingUpdate:
rollingUpdateType: InPlaceIfPossible
selector:
matchLabels:
kubernetes.io/hostname: k-m-1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:alpine
ports:
- name: http
containerPort: 80
# 部署一下
[root@k-m-1 openkruise]# kubectl apply -f nginx-ds.yaml
[root@k-m-1 openkruise]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-q6bsk 1/1 Running 1 (81s ago) 103s
[root@k-m-1 openkruise]# kubectl describe daemon nginx
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulCreate 17m daemonset-controller Created pod: nginx-l5rct
Normal SuccessfulDelete 35s daemonset-controller Deleted pod: nginx-l5rct
Normal SuccessfulCreate 34s daemonset-controller Created pod: nginx-q6bsk
Normal SuccessfulUpdatePodInPlace 12s daemonset-controller successfully update pod nginx-q6bsk in-place
# 不过目前Advanced DaemonSet只支持PreDelete Hook,它允许用户在daemon pod被删除前指定一些自定义的逻辑
6.3:Broadcast Job
这个控制器将Pod分发到集群中的每个节点上,类似与DaemonSet,但是BroadcastJob管理的Pod并不是长期运行的daemon服务,而是类似与Job的任务类型Pod,在每个节点上的Pod都执行完成退出后,BroadcastJob和这些Pod并不会占用集群资源,这个控制器非常有利于升级基础软件,巡检等过一段时间需要在整个集群中跑一次的工作。
apiVersion: apps.kruise.io/v1alpha1
kind: BroadcastJob
metadata:
name: bcj
namespace: default
spec:
template:
spec:
restartPolicy: Never
containers:
- name: counter
image: busybox:latest
command:
- "/bin/sh"
- "-c"
- "for i in 9 8 7 6 5 4 3 2 1; do echo $i; done"
# 执行一下顺便看一下输出
[root@k-m-1 openkruise]# kubectl apply -f bcj.yaml
broadcastjob.apps.kruise.io/bcj created
# 查看bcj
[root@k-m-1 openkruise]# kubectl get bcj
NAME DESIRED ACTIVE SUCCEEDED FAILED AGE
bcj 1 0 1 0 2m9s
# 查看一下标准输出
[root@k-m-1 openkruise]# kubectl logs -f pods/bcj-lls9h
9
8
7
6
5
4
3
2
1
# 可以看到这个是根据我们定义进行的的输出,那么这里我们强调一个参数completionPolicy,这个参数,他是一个完成的策略,其实也就是在配置Job的超时之类的操作。
apiVersion: apps.kruise.io/v1alpha1
kind: BroadcastJob
metadata:
name: bcj
namespace: default
spec:
completionPolicy:
type: Always
# Job运行超过20秒后将被标记为失败,并且会把正在运行的Pod删除
activeDeadlineSeconds: 20
# 表示这个Job运行完成后,10秒之后将被删除
ttlSecondsAfterFinished: 10
template:
spec:
restartPolicy: Never
containers:
- name: counter
image: busybox:latest
command:
- "/bin/sh"
- "-c"
- "for i in 9 8 7 6 5 4 3 2 1; do echo $i; done"
[root@k-m-1 openkruise]# kubectl apply -f bcj.yaml
broadcastjob.apps.kruise.io/bcj created
[root@k-m-1 openkruise]# kubectl get pod -w
NAME READY STATUS RESTARTS AGE
bcj-s64rq 0/1 ContainerCreating 0 3s
bcj-s64rq 0/1 Completed 0 9s
bcj-s64rq 0/1 Completed 0 10s
bcj-s64rq 0/1 Completed 0 10s
bcj-s64rq 0/1 Completed 0 11s
bcj-s64rq 0/1 Terminating 0 21s
bcj-s64rq 0/1 Terminating 0 21s
# 这就是这个Job的整个运行的过程。
# 其次我们再看一个参数,parallelism,这个参数其实就是在配置一个并发执行数,比如我有10台机器,这个参数我设置为3,那么这个时候并发执行的机器数量就是三个,当这三个并发每当有一个执行完成之后才会去创建一个新的Job去执行,但是我们要知道,它并非创建的是Job资源,而是一个Pod资源。
6.4:Advanced CronJob
Advanced CronJob是对于原生的CronJob的扩展版本,根据用户设置的schedule规则,周期性的创建Job执行任务,而Advanced CronJob的template支持多种不同的Job资源
apiVersion: apps.kruise.io/v1alpha1
kind: AdvancedCronJob
spec:
template:
# 第一种Job类型,就是Job资源
jobTemplate:
# ...
# 第二种Job类型是BroadcastJob资源
broadcastJobTemplate:
# ...
1:jobTemplate:与原生CronJob一样创建Job执行任务。
2:broadcastJobTemplate:周期性创建BroadcastJob执行任务。
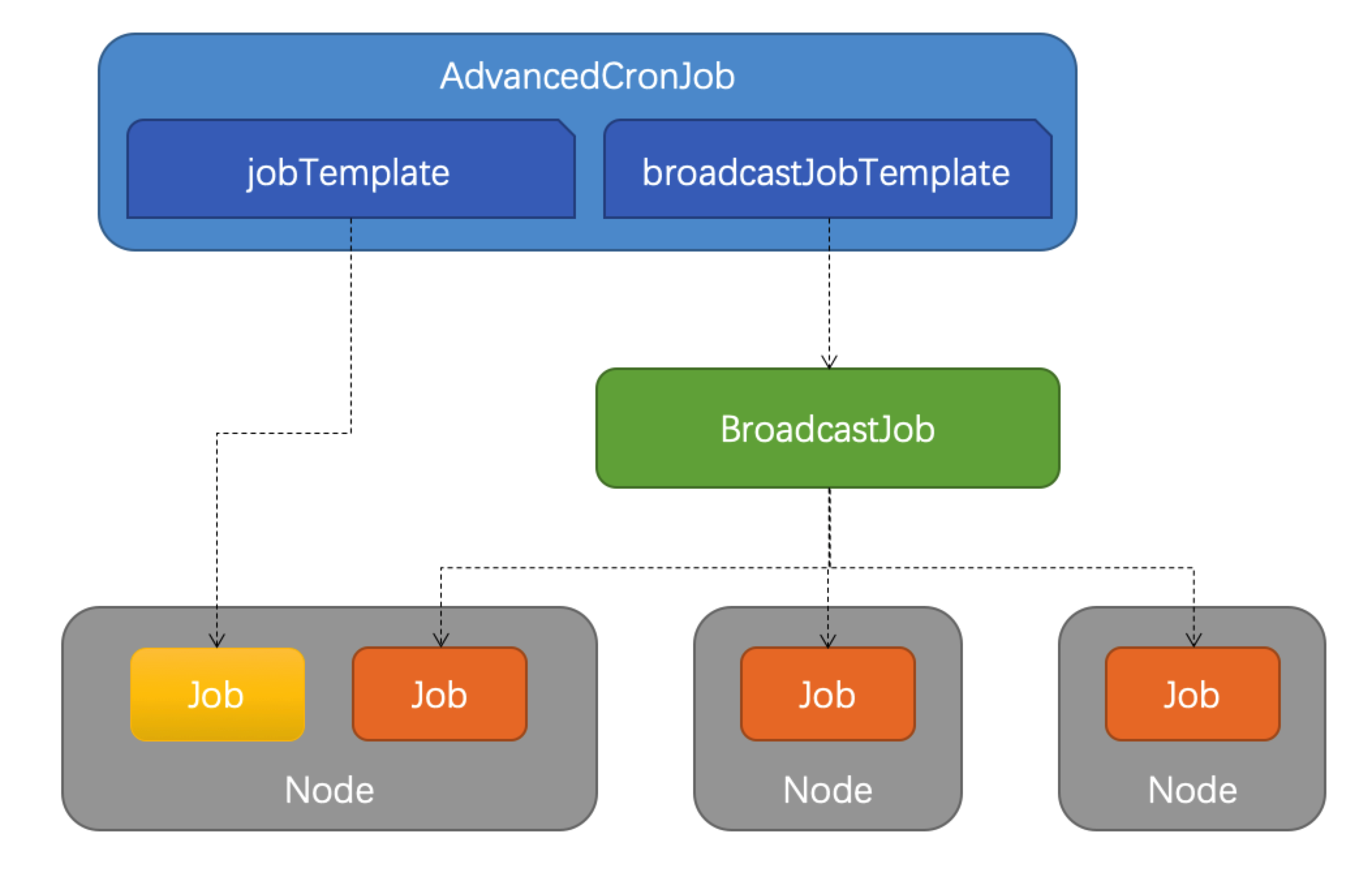
apiVersion: apps.kruise.io/v1alpha1
kind: AdvancedCronJob
metadata:
name: acj
spec:
schedule: "*/1 * * * *"
template:
broadcastJobTemplate:
spec:
completionPolicy:
type: Always
ttlSecondsAfterFinished: 30
template:
spec:
restartPolicy: Never
containers:
- name: counter
image: busybox:latest
command:
- "/bin/sh"
- "-c"
- "for i in 9 8 7 6 5 4 3 2 1; do echo $i; done"
# 可以看的出,它里面就是套了BroadcastJob的spec字段,那么我们部署一下
[root@k-m-1 openkruise]# kubectl apply -f acj.yaml
advancedcronjob.apps.kruise.io/acj created
# 查看acj资源
[root@k-m-1 openkruise]# kubectl get acj
NAME SCHEDULE TYPE LASTSCHEDULETIME AGE
acj */1 * * * * BroadcastJob 16s
[root@k-m-1 openkruise]# kubectl get acj
# 查看资源
[root@k-m-1 openkruise]# kubectl get pod
NAME READY STATUS RESTARTS AGE
acj-1686299160-g7qlc 0/1 Completed 0 6s
[root@k-m-1 openkruise]# kubectl get bcj
NAME DESIRED ACTIVE SUCCEEDED FAILED AGE
acj-1686299160 1 0 1 0 27s
# 查看输出
[root@k-m-1 openkruise]# kubectl logs -f acj-1686299160-9ljzw
9
8
7
6
5
4
3
2
1
# 过一分钟再看
[root@k-m-1 openkruise]# kubectl get pod -w
NAME READY STATUS RESTARTS AGE
acj-1686299160-9ljzw 0/1 Completed 0 19s
acj-1686299220-gfbkt 0/1 Pending 0 0s
acj-1686299220-gfbkt 0/1 Pending 0 0s
acj-1686299220-gfbkt 0/1 ContainerCreating 0 0s
acj-1686299220-gfbkt 0/1 ContainerCreating 0 0s
acj-1686299220-gfbkt 0/1 ContainerCreating 0 0s
acj-1686299220-gfbkt 0/1 Completed 0 4s
acj-1686299220-gfbkt 0/1 Completed 0 5s
acj-1686299220-gfbkt 0/1 Completed 0 5s
acj-1686299220-gfbkt 0/1 Completed 0 6s
acj-1686299160-9ljzw 0/1 Terminating 0 36s
acj-1686299160-9ljzw 0/1 Terminating 0 36s
# 可以看的出来策略都是生效的,而且又重建一个新的任务
[root@k-m-1 openkruise]# kubectl get pod
NAME READY STATUS RESTARTS AGE
acj-1686299280-zqpll 0/1 Completed 0 10s
# 当然这个Advanced CronJob在spec字段下指定timeZone这个功能,如果不指定的话,那么Job的时区都是按照Kruise的controller-manager的程序的本地时区走的,如果需要明确指定的话,也可以使用timeZone字段去指定。
apiVersion: apps.kruise.io/v1alpha1
kind: AdvancedCronJob
metadata:
name: acj
spec:
schedule: "*/1 * * * *"
timeZone: "Asia/Shanghai"
template:
broadcastJobTemplate:
spec:
completionPolicy:
type: Always
ttlSecondsAfterFinished: 30
template:
spec:
restartPolicy: Never
containers:
- name: counter
image: busybox:latest
command:
- "/bin/sh"
- "-c"
- "for i in 9 8 7 6 5 4 3 2 1; do echo $i; done"
6.5:SidecarSet
SidecarSet支持通过admission webhook来自动为集群中创建的符合条件的Pod注入sidecar容器,除了在Pod创建时候注入,SidecarSet还提供了为Pod原地升级其中已经注入的sidecar容器镜像的能力。SidecarSet将sidecar容器的定义和生命周期与业务容器解耦,它主要用于管理与状态的sidecar容器,比如监控,日志等agent
apiVersion: apps.kruise.io/v1alpha1
kind: SidecarSet
metadata:
name: scs
spec:
selector:
# 这个属性是是非常重要的,会使用这个标签来匹配Pod
matchLabels:
app: nginx
updateStrategy:
type: RollingUpdate
maxUnavailable: 1
containers:
- name: scs
image: busybox:latest
command: ["sleep", "999d"]
volumeMounts:
- name: log
mountPath: /var/log
volumes:
- name: log
emptyDir: {}
# 创建应用
[root@k-m-1 openkruise]# kubectl get sidecarsets
NAME MATCHED UPDATED READY AGE
scs 0 0 0 2m18s
# 此时我们可以看到,它并没有匹配到任何的Pod,根据Match来判断,我们去创建一个app=nginx的pod
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:latest
# 部署一下
[root@k-m-1 openkruise]# kubectl apply -f pod.yaml
pod/nginx created
# 查看是否注入
[root@k-m-1 openkruise]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx 2/2 Running 0 26s
# 可以观测到,我们明明配置的是一个容器,但是却显示了两个容器,那么我们详细来一下是怎么回事
[root@k-m-1 openkruise]# kubectl get sidecarsets
NAME MATCHED UPDATED READY AGE
scs 1 1 1 6m40s
# 可以看到sidecarset已经生效了。这也就证明了它的确是注入了一个Pod内了,那么我们前面也说了,这个SidecatSet也支持针对注入镜像的更新方式,那么我们来更新一下试试
apiVersion: apps.kruise.io/v1alpha1
kind: SidecarSet
metadata:
name: scs
spec:
selector:
matchLabels:
app: nginx
updateStrategy:
type: RollingUpdate
maxUnavailable: 1
containers:
- name: scs
image: busybox:1.35.0
command: ["sleep", "999d"]
volumeMounts:
- name: log
mountPath: /var/log
volumes:
- name: log
emptyDir: {}
# 部署更新一下
[root@k-m-1 openkruise]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx 2/2 Running 0 24h
[root@k-m-1 openkruise]# kubectl get sidecarsets
NAME MATCHED UPDATED READY AGE
scs 1 0 1 24h
# 经过测试这个功能貌似是控制器的问题,它并不能正常的去原地升级镜像,这个还需要后期的支持,而且sidecarset和pod的创建顺序也有要求,就是需要先创建sidecatset,然后控制器才可以watch到后面创建的Pod,这个也是一个问题,后期也需要更新修改,所以我这里直接删除了资源重建了一下
[root@k-m-1 openkruise]# kubectl get pod nginx
NAME READY STATUS RESTARTS AGE
nginx 2/2 Running 0 23s
# 这个时候的sidecar的镜像是1.35.0,我们再次通过patch去更新它
[root@k-m-1 openkruise]# kubectl patch sidecarsets scs --type json -p '[{"op": "replace", "path": "/spec/containers/0/image", "value": "busybox:latest"}]'
sidecarset.apps.kruise.io/scs patched
[root@k-m-1 openkruise]# kubectl describe pod nginx
......
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 5m22s default-scheduler Successfully assigned default/nginx to k-m-1
Normal Pulling 5m22s kubelet Pulling image "busybox:1.35.0"
Normal Pulled 5m9s kubelet Successfully pulled image "busybox:1.35.0" in 13.292788666s
Normal Pulling 5m8s kubelet Pulling image "nginx:latest"
Normal Pulled 5m5s kubelet Successfully pulled image "nginx:latest" in 2.884890857s
Normal Created 5m5s kubelet Created container nginx
Normal Started 5m5s kubelet Started container nginx
Normal Killing 2m35s kubelet Container scs definition changed, will be restarted
Normal Created 2m4s (x2 over 5m8s) kubelet Created container scs
Normal Started 2m4s (x2 over 5m8s) kubelet Started container scs
Normal Pulled 2m4s kubelet Container image "busybox:latest" already present on machine
# 可以看到Pod的控制器在更新了,watch到了更新,然后就change了,然后sidecar就会重启,然后重启次数就会加1了
[root@k-m-1 openkruise]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx 2/2 Running 1 (30s ago) 3m47s
# 那么这个时候我们再将tag修改为1.35.0,然后使用apply的方式去更新一下
[root@k-m-1 openkruise]# kubectl describe pod nginx
......
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 8m15s default-scheduler Successfully assigned default/nginx to k-m-1
Normal Pulling 8m15s kubelet Pulling image "busybox:1.35.0"
Normal Pulled 8m2s kubelet Successfully pulled image "busybox:1.35.0" in 13.292788666s
Normal Pulling 8m1s kubelet Pulling image "nginx:latest"
Normal Pulled 7m58s kubelet Successfully pulled image "nginx:latest" in 2.884890857s
Normal Created 7m58s kubelet Created container nginx
Normal Started 7m58s kubelet Started container nginx
Normal Pulled 4m57s kubelet Container image "busybox:latest" already present on machine
Normal Killing 38s (x2 over 5m28s) kubelet Container scs definition changed, will be restarted
Normal Created 8s (x3 over 8m1s) kubelet Created container scs
Normal Started 8s (x3 over 8m1s) kubelet Started container scs
Normal Pulled 8s kubelet Container image "busybox:1.35.0" already present on machine
# 可以看到这个时候它有watch到更新了,并且修改镜像并重启了容器,重启次数再次加1
[root@k-m-1 openkruise]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx 2/2 Running 2 (56s ago) 9m3s
# 基本特性
需要注意的是sidecar的注入只发生在Pod创建阶段,并且只有Pod spec会被更新,不会影响Pod所属的工作负载template模板,spec.containers除了默认的k8s contaienr字段,还扩展了一些其他字段方便注入
apiVersion: apps.kruise.io/v1alpha1
kind: SidecarSet
metadata:
name: scs
spec:
selector:
matchLabels:
app: nginx
updateStrategy:
type: RollingUpdate
maxUnavailable: 1
containers:
- name: scs
image: busybox:1.35.0
command: ["sleep", "999d"]
volumeMounts:
- name: log
mountPath: /var/log
# 扩展的字段
podInjectPolicy: BeforeAppContainer
# 数据共享
shareVolumePolicy:
type: # disabled / enabled
# 环境变量共享
transferEnv:
- sourceContainerName: main
envName: PROXY_IP
volumes:
- name: log
emptyDir: {}
1:podInjectPolicy:定义了容器注入到pod.spec.containers中的位置
1:BeforeAppContainer:表示注入到Pod原Container的前面(默认)
2:AfterAppContainer:表示注入到Pod原Container的后面
2:shareVolumePolicy
1:共享指定卷:通过spec.volumes来定义sidecar自身需要的volume
2:共享所有卷:通过spec.containers[i].shareVolumePolicy.type = disabled | enabled来控制是否挂载pod应用容器的卷,常用于日志收集等sidecar,配置为enabled后会把应用容器中所有的挂载点注入sidecar,同一路径下(sidecar本身就有声明的数据卷和挂载点除外)
3:transferEnv:可以通过spec.contaienrs[i].transferEnv来从别的容器获取环境变量,会把名为sourceContainerName容器中的名为envName的环境变量拷贝到本容器中。
SidecarSet不仅支持sidecar容器的原地升级,而且提供了非常丰富的升级,灰度策略,同样在SidecarSet对象中updateStrategy属性下面也可以配置partition来定义保留旧版本Pod的数量或者百分比,默认为0,同样还可以配置的有maxUnavailable属性,表示发布过程中最大不可用的数量。
1:当 {matched pod}=100,partition=50,maxUnavailable=10,控制器会发布 50 个 Pod 到新版本,但是发布窗口为 10,即同一时间只会发布 10 个 Pod,每发布好一个 Pod 才会再找一个发布,直到 50 个发布完成。
2:当 {matched pod}=100,partition=80,maxUnavailable=30,控制器会发布 20 个 Pod 到新版本,因为满足 maxUnavailable 数量,所以这 20 个 Pod 会同时发布。
同样也可以设置paused: true来暂停发布,此时对于新创建的,扩容的pod依旧会实现注入能力,已经更新的pod会保持更新后的版本不动,还没有更新的Pod会暂停更新。
apiVersion: apps.kruise.io/v1alpha1
kind: SidecarSet
metadata:
name: sidecarset
spec:
# ...
updateStrategy:
type: RollingUpdate
maxUnavailable: 20%
partition: 10
paused: true
# 金丝雀发布
对于有金丝雀发布需求的业务,可以通过strategy.selector来实现。方式:对于需要率先金丝雀灰度的pod打上固定的labels[canary.release] = true,再通过strategy.selector.matchLabels来选中该pod
示例如下
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
namespace: default
spec:
replicas: 3
revisionHistoryLimit: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:latest
ports:
- name: http
containerPort: 80
# 这样创建出来之后我们就有4个带有app=nginx的标签了
[root@k-m-1 openkruise]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx 2/2 Running 2 (145m ago) 154m
nginx-586b477ddc-dn8vz 2/2 Running 0 15s
nginx-586b477ddc-npxdj 2/2 Running 0 15s
nginx-586b477ddc-ptc8h 2/2 Running 0 15s
# 由于都匹配上了上面创建的sidecarset对象,所以都会被注入一个sidecar容器,镜像为busybox,那么这个时候我们如果只想让nginx这个pod的sidecar执行灰度,那么这个时候我们只需要使用如下方法
apiVersion: apps.kruise.io/v1alpha1
kind: SidecarSet
metadata:
name: scs
spec:
selector:
matchLabels:
app: nginx
updateStrategy:
type: RollingUpdate
maxUnavailable: 1
# 需要配置这个参数
selector:
matchLabels:
# 这个参数是定死的参数
canary.release: "true"
containers:
- name: scs
# 灰度的新版本
image: busybox:1.28.3
command: ["sleep", "999d"]
volumeMounts:
- name: log
mountPath: /var/log
volumes:
- name: log
emptyDir: {}
# 这个时候其实还不行,我们还需要去指定的Pod上也加上这个标签才可以
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
app: nginx
# 加上这个标签
canary.release: "true"
spec:
containers:
- name: nginx
image: nginx:latest
# 灰度前
[root@k-m-1 openkruise]# kubectl get pod -o custom-columns='DATA:metadata.name,CONTAINERS:spec.containers[*].name,IMAGES:spec.containers[*].image'
DATA CONTAINERS IMAGES
nginx scs,nginx busybox:1.35.0,nginx:latest
nginx-586b477ddc-2r2qn scs,nginx busybox:1.35.0,nginx:latest
nginx-586b477ddc-cz2dz scs,nginx busybox:1.35.0,nginx:latest
nginx-586b477ddc-jsxfw scs,nginx busybox:1.35.0,nginx:latest
# 开始灰度
[root@k-m-1 openkruise]# kubectl apply -f scs.yaml
sidecarset.apps.kruise.io/scs configured
# 新一下我们的目标Pod,当然前面也可以用edit去更新
[root@k-m-1 openkruise]# kubectl apply -f pod.yaml
pod/nginx configured
# 查看效果
[root@k-m-1 openkruise]# kubectl get pod -o custom-columns='DATA:metadata.name,CONTAINERS:spec.containers[*].name,IMAGES:spec.containers[*].image'
DATA CONTAINERS IMAGES
nginx scs,nginx busybox:1.35.0,nginx:latest
nginx-586b477ddc-2r2qn scs,nginx busybox:1.35.0,nginx:latest
nginx-586b477ddc-cz2dz scs,nginx busybox:1.35.0,nginx:latest
nginx-586b477ddc-jsxfw scs,nginx busybox:1.35.0,nginx:latest
# 灰度后
[root@k-m-1 openkruise]# kubectl get pod -o custom-columns='DATA:metadata.name,CONTAINERS:spec.containers[*].name,IMAGES:spec.containers[*].image'
DATA CONTAINERS IMAGES
nginx scs,nginx busybox:1.28.3,nginx:latest
nginx-586b477ddc-2r2qn scs,nginx busybox:1.35.0,nginx:latest
nginx-586b477ddc-cz2dz scs,nginx busybox:1.35.0,nginx:latest
nginx-586b477ddc-jsxfw scs,nginx busybox:1.35.0,nginx:latest
# 查看Pod
[root@k-m-1 openkruise]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx 2/2 Running 1 (35s ago) 5m49s
nginx-586b477ddc-2r2qn 2/2 Running 0 5m49s
nginx-586b477ddc-cz2dz 2/2 Running 0 5m49s
nginx-586b477ddc-jsxfw 2/2 Running 0 5m49s
# 总的来说吧,这个sidecarset的控制器并非那么友好,有一些配置它不一定可以监听的到,这个还需要大家测试,因为我测试的过程中,两个镜像来回换的时候并不能触发灰度,我又换了第三个镜像才触发了灰度的功能,所以这个后面还是需要改进的。
# SidecarSet热升级
SidecarSet原地升级会先停止旧版本的容器,然后创建新版本的容器。这种方式更加适合不影响Pod服务可用性的sidecar容器,比如说:日志收集Agent。
但是对于很多代理或运行时的sidecar容器,例如Istio Envoy,这种升级方法就有问题了。Envoy作为Pod中的一个代理容器,代理了所有的流量,如果直接重启,Pod服务的可用性会受到影响。如果需要单独升级envoy sidecar,就需要复杂的grace终止和协调机制。所以我们为这种sidecar容器的升级提供了一种新的解决方案。
apiVersion: apps.kruise.io/v1alpha1
kind: SidecarSet
metadata:
name: hotupgrade-sidecarset
spec:
selector:
matchLabels:
app: hotupgrade
containers:
- name: sidecar
image: openkruise/hotupgrade-sample:sidecarv1
imagePullPolicy: Always
lifecycle:
postStart:
exec:
command:
- /bin/sh
- /migrate.sh
upgradeStrategy:
upgradeType: HotUpgrade
hotUpgradeEmptyImage: openkruise/hotupgrade-sample:empty
1:upgradeType: HotUpgrade代表该sidecar容器的类型是hot upgrade,将执行热升级方案
2:hotUpgradeEmptyImage: 当热升级sidecar容器时,业务必须要提供一个empty容器用于热升级过程中的容器切换。empty容器同sidecar容器具有相同的配置(除了镜像地址),例如:command, lifecycle, probe等,但是它不做任何工作。
3:lifecycle.postStart: 状态迁移,该过程完成热升级过程中的状态迁移,该脚本需要由业务根据自身的特点自行实现,例如:nginx热升级需要完成Listen FD共享以及流量排水(reload)
# 热升级特性总共包含以下两个过程:
1:Pod创建时,注入热升级容器
2:原地升级时,完成热升级流程
# 注入热升级容器
注入热升级容器
1:{sidecarContainer.name}-1: 如下图所示 envoy-1,这个容器代表正在实际工作的sidecar容器,例如:envoy:1.16.0
2:{sidecarContainer.name}-2: 如下图所示 envoy-2,这个容器是业务配置的hotUpgradeEmptyImage容器,例如:empty:1.0,用于后面的热升级机制
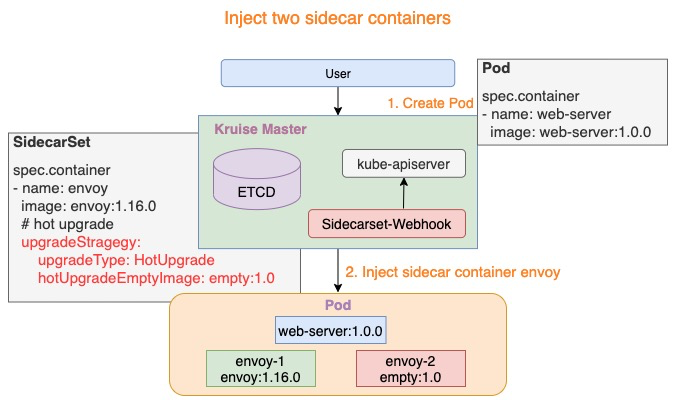
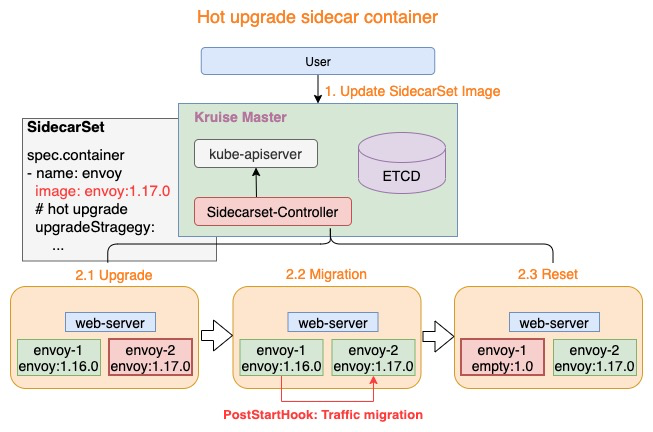
# 热升级流程
热升级流程主要分为一下三个步骤:
1:Upgrade: 将empty容器升级为当前最新的sidecar容器,例如:envoy-2.Image = envoy:1.17.0
2:Upgrade: 将empty容器升级为当前最新的sidecar容器,例如:envoy-2.Image = envoy:1.17.0
3:Upgrade: 将empty容器升级为当前最新的sidecar容器,例如:envoy-2.Image = envoy:1.17.0
上述三个步骤完成了热升级中的全部流程,当对Pod执行多次热升级时,将重复性的执行上述三个步骤。
apiVersion: apps.kruise.io/v1alpha1
kind: CloneSet
metadata:
name: busybox
labels:
app: hotupgrade
spec:
replicas: 1
selector:
matchLabels:
app: hotupgrade
template:
metadata:
labels:
app: hotupgrade
spec:
containers:
- name: busybox
image: openkruise/hotupgrade-sample:busybox
# 先创建上面的SidecarSet
[root@k-m-1 openkruise]# kubectl apply -f hotupgrade-sidecar.yaml
sidecarset.apps.kruise.io/hotupgrade-sidecarset created
[root@k-m-1 openkruise]# kubectl get sidecarsets.apps.kruise.io
NAME MATCHED UPDATED READY AGE
hotupgrade-sidecarset 0 0 0 7s
# 创建CloneSet的Pod
[root@k-m-1 openkruise]# kubectl apply -f hotupgrade-cloneset.yaml
cloneset.apps.kruise.io/busybox created
# 这里我们可以看到,它貌似变成了三个容器,
[root@k-m-1 openkruise]# kubectl get pod
NAME READY STATUS RESTARTS AGE
busybox-nkbjh 3/3 Running 0 54s
# 看一下镜像
[root@k-m-1 openkruise]# kubectl get pod -o custom-columns='IMAGES:spec.containers[*].image'
IMAGES
openkruise/hotupgrade-sample:sidecarv1,openkruise/hotupgrade-sample:empty,openkruise/hotupgrade-sample:busybox
# 可以看到,这里面就是我们定义的cloentset和sidecarset的中的镜像了,那么这个业务容器会每100毫秒去请求一下sidecar
[root@k-m-1 openkruise]# kubectl logs busybox-nkbjh -c busybox
......
I0610 23:04:16.543736 1 main.go:39] request sidecar server success, and response(body=This is version(v1) sidecar)
I0610 23:04:16.655644 1 main.go:39] request sidecar server success, and response(body=This is version(v1) sidecar)
I0610 23:04:16.767115 1 main.go:39] request sidecar server success, and response(body=This is version(v1) sidecar)
I0610 23:04:16.878332 1 main.go:39] request sidecar server success, and response(body=This is version(v1) sidecar)
I0610 23:04:16.989755 1 main.go:39] request sidecar server success, and response(body=This is version(v1) sidecar)
I0610 23:04:17.100634 1 main.go:39] request sidecar server success, and response(body=This is version(v1) sidecar)
# 这个时候可以看出它是v1的版本,我们如果想热升级它该怎么热升级呢,那么我们这个时候已知,sidecarv1的版本是一直在提供服务的,那么我们来试一下热升级一下sidecar到sidecarv2
[root@k-m-1 openkruise]# kubectl patch sidecarsets hotupgrade-sidecarset --type='json' -p='[{"op": "replace", "path": "/spec/containers/0/image", "value": "openkruise/hotupgrade-sample:sidecarv2"}]'
sidecarset.apps.kruise.io/hotupgrade-sidecarset patched
[root@k-m-1 openkruise]# kubectl logs busybox-nkbjh -c busybox
......
I0610 23:09:08.737580 1 main.go:39] request sidecar server success, and response(body=This is version(v2) sidecar)
I0610 23:09:08.849077 1 main.go:39] request sidecar server success, and response(body=This is version(v2) sidecar)
I0610 23:09:08.960434 1 main.go:39] request sidecar server success, and response(body=This is version(v2) sidecar)
I0610 23:09:09.072026 1 main.go:39] request sidecar server success, and response(body=This is version(v2) sidecar)
I0610 23:09:09.184368 1 main.go:39] request sidecar server success, and response(body=This is version(v2) sidecar)
I0610 23:09:09.296469 1 main.go:39] request sidecar server success, and response(body=This is version(v2) sidecar)
I0610 23:09:09.407723 1 main.go:39] request sidecar server success, and response(body=This is version(v2) sidecar)
I0610 23:09:09.518588 1 main.go:39] request sidecar server success, and response(body=This is version(v2) sidecar)
# 可以看到这个时候它就升级到v2来了,这个时候就会发现,我们的服务是并没有中断的,依旧是在请求sidecar的。
7:OpenKruise增强运维能力
7.1:Container Restart
ContainerRecreateRequest 可以帮助用户重启/重建存量 Pod 中一个或多个容器。
和 Kruise 提供的原地升级类似,当一个容器重建的时候,Pod 中的其他容器还保持正常运行。重建完成后,Pod 中除了该容器的 restartCount 增加以外不会有什么其他变化。 注意,之前临时写到旧容器 rootfs 中的文件会丢失,但是 volume mount 挂载卷中的数据都还存在。
这个功能依赖于 kruise-daemon 组件来停止 Pod 容器。 如果 KruiseDaemon feature-gate 被关闭了,ContainerRecreateRequest 也将无法使用。
apiVersion: apps.kruise.io/v1alpha1
kind: ContainerRecreateRequest
metadata:
namespace: pod-namespace
name: xxx
spec:
podName: pod-name
containers: # 要重建的容器名字列表,至少要有 1 个
- name: app
- name: sidecar
strategy:
failurePolicy: Fail # 'Fail' 或 'Ignore',表示一旦有某个容器停止或重建失败, CRR 立即结束
orderedRecreate: false # 'true' 表示要等前一个容器重建完成了,再开始重建下一个
terminationGracePeriodSeconds: 30 # 等待容器优雅退出的时间,不填默认用 Pod 中定义的
unreadyGracePeriodSeconds: 3 # 在重建之前先把 Pod 设为 not ready,并等待这段时间后再开始执行重建
minStartedSeconds: 10 # 重建后新容器至少保持运行这段时间,才认为该容器重建成功
activeDeadlineSeconds: 300 # 如果 CRR 执行超过这个时间,则直接标记为结束(未结束的容器标记为失败)
ttlSecondsAfterFinished: 1800 # CRR 结束后,过了这段时间自动被删除掉
所有 strategy 中的字段、以及 spec 中的 activeDeadlineSeconds/ttlSecondsAfterFinished 都是可选的。
1:一般来说,列表中的容器会一个个被停止,但可能同时在被重建和启动,除非 orderedRecreate 被设置为 true。
2:unreadyGracePeriodSeconds 功能依赖于 KruisePodReadinessGate 这个 feature-gate 要打开,后者会在每个 Pod 创建的时候注入一个 readinessGate。 否则,默认只会给 Kruise workload 创建的 Pod 注入 readinessGate,也就是说只有这些 Pod 才能在 CRR 重建时使用 unreadyGracePeriodSeconds。
当用户创建了一个 CRR,Kruise webhook 会把当时容器的 containerID/restartCount 记录到 spec.containers[x].statusContext 之中。 在 kruise-daemon 执行的过程中,如果它发现实际容器当前的 containerID 与 statusContext 不一致或 restartCount 已经变大, 则认为容器已经被重建成功了(比如可能发生了一次原地升级)。
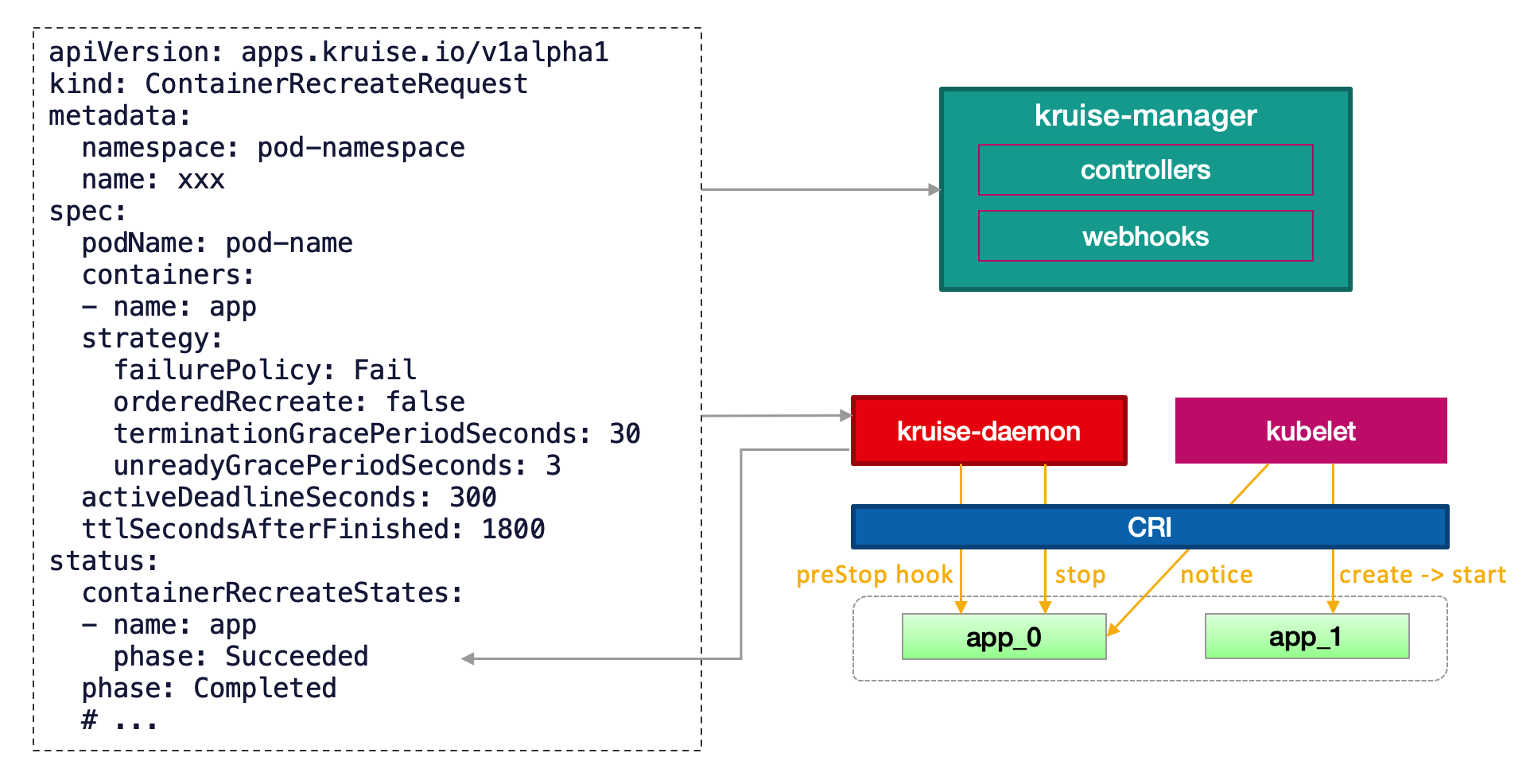
一般情况下,kruise-daemon 会执行 preStop hook 后把容器停掉,然后 kubelet 感知到容器退出,则会新建一个容器并启动。 最后 kruise-daemon 看到新容器已经启动成功超过 minStartedSeconds 时间后,会上报这个容器的 phase 状态为 Succeeded。
如果容器重建和原地升级操作同时触发了:
1:如果 Kubelet 根据原地升级要求已经停止或重建了容器,kruise-daemon 会判断容器重建已经完成。
2:如果 kruise-daemon 先停了容器,Kubelet 会继续执行原地升级,即创建一个新版本容器并启动。
如果针对一个 Pod 提交了多个 ContainerRecreateRequest 资源,会按时间先后一个个执行。
7.2:ImagePullJob
NodeImage 和 ImagePullJob 是从 Kruise v0.8.0 版本开始提供的 CRD。
Kruise 会自动为每个 Node 创建一个 NodeImage,它包含了哪些镜像需要在这个 Node 上做预热。
用户能创建 ImagePullJob 对象,来指定一个镜像要在哪些 Node 上做预热。
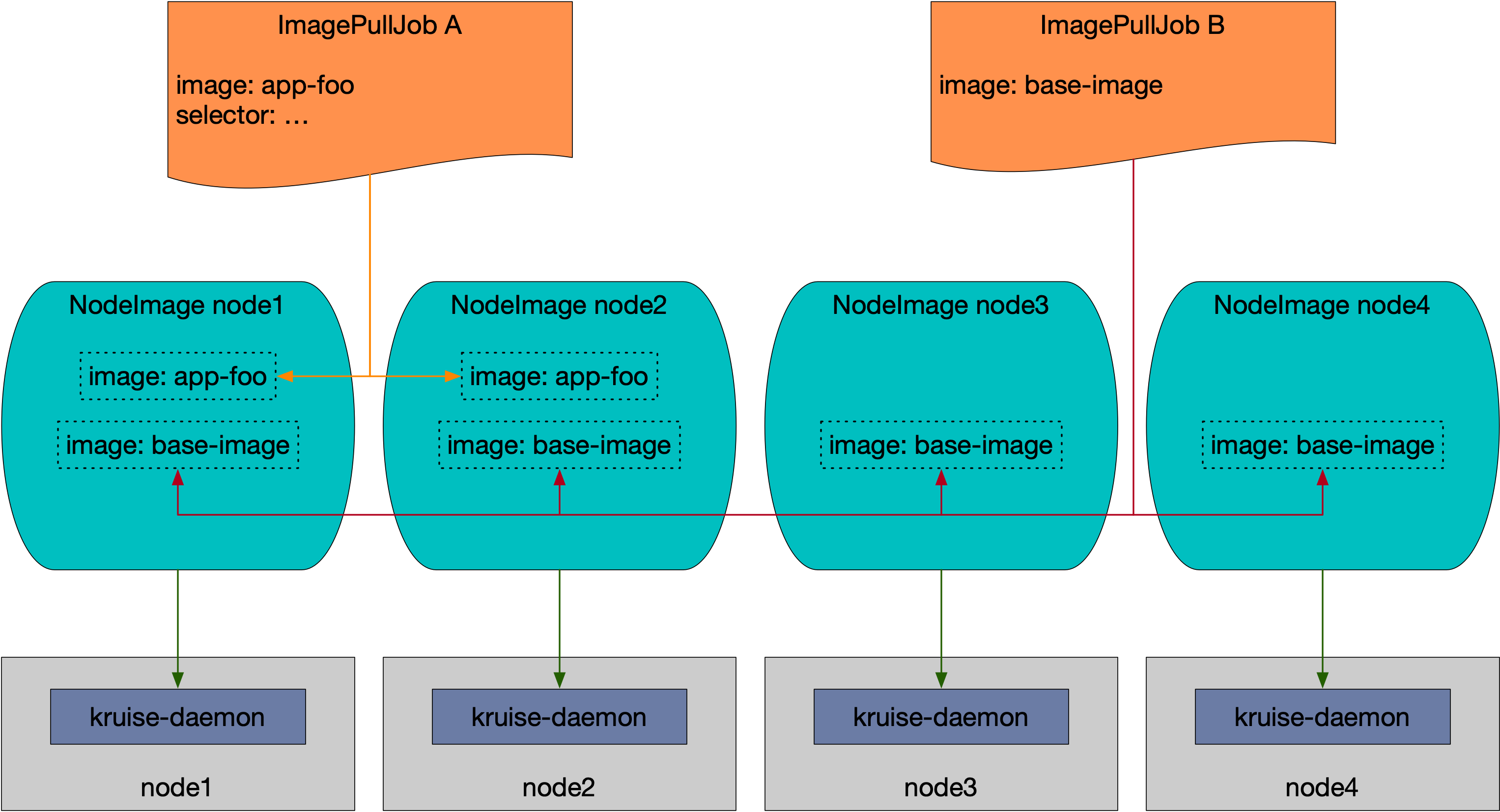
注意,NodeImage 是一个偏底层的 API,一般只在你要明确在某一个节点上做一次预热的时候才使用,否则你都应该使用 ImagePullJob 来指定某个镜像在一批节点上做预热。
[root@k-m-1 openkruise]# kubectl get nodeimage
NAME DESIRED PULLING SUCCEED FAILED AGE
k-m-1 0 0 0 0 6d
# 当我们创建kruise的时候它会帮助我们一起创建出来nodeimage这个资源
apiVersion: apps.kruise.io/v1alpha1
kind: NodeImage
metadata:
creationTimestamp: "2023-06-04T23:28:37Z"
generation: 1
labels:
beta.kubernetes.io/arch: amd64
beta.kubernetes.io/os: linux
kubernetes.io/arch: amd64
kubernetes.io/hostname: k-m-1
kubernetes.io/os: linux
node-role.kubernetes.io/control-plane: ""
node.kubernetes.io/exclude-from-external-load-balancers: ""
name: k-m-1
resourceVersion: "7671879"
uid: 7690ea2b-7711-4fa2-9f70-266464f4a364
spec:
# 设置预热拉取镜像的列表
images:
ubuntu:
# 设置拉取镜像的版本列表
tags:
- tag: latest
# 设置具体的拉取策略
pullPolicy:
# 拉取完成后超过这个时间才会去清除这个任务
ttlSecondsAfterFinished: 300
# 拉取超时时间(默认600)
timeoutSeconds: 600
# 重试拉取次数
backoffLimit: 3
# 整个任务的超时时间
activeDeadlineSeconds: 1200
status:
desired: 0
failed: 0
pulling: 0
succeeded: 0
[root@k-m-1 openkruise]# kubectl describe nodeimages.apps.kruise.io k-m-1
Name: k-m-1
Namespace:
Labels: beta.kubernetes.io/arch=amd64
beta.kubernetes.io/os=linux
kubernetes.io/arch=amd64
kubernetes.io/hostname=k-m-1
kubernetes.io/os=linux
node-role.kubernetes.io/control-plane=
node.kubernetes.io/exclude-from-external-load-balancers=
Annotations: <none>
API Version: apps.kruise.io/v1alpha1
Kind: NodeImage
Metadata:
Creation Timestamp: 2023-06-04T23:28:37Z
Generation: 2
Managed Fields:
API Version: apps.kruise.io/v1alpha1
Fields Type: FieldsV1
fieldsV1:
f:metadata:
f:labels:
.:
f:beta.kubernetes.io/arch:
f:beta.kubernetes.io/os:
f:kubernetes.io/arch:
f:kubernetes.io/hostname:
f:kubernetes.io/os:
f:node-role.kubernetes.io/control-plane:
f:node.kubernetes.io/exclude-from-external-load-balancers:
f:spec:
Manager: kruise-manager
Operation: Update
Time: 2023-06-04T23:28:37Z
API Version: apps.kruise.io/v1alpha1
Fields Type: FieldsV1
fieldsV1:
f:spec:
f:images:
.:
f:ubuntu:
.:
f:tags:
Manager: kubectl-edit
Operation: Update
Time: 2023-06-10T23:45:36Z
API Version: apps.kruise.io/v1alpha1
Fields Type: FieldsV1
fieldsV1:
f:status:
.:
f:desired:
f:failed:
f:imageStatuses:
.:
f:ubuntu:
.:
f:tags:
f:pulling:
f:succeeded:
Manager: kruise-daemon
Operation: Update
Subresource: status
Time: 2023-06-10T23:45:54Z
Resource Version: 9563203
UID: 7690ea2b-7711-4fa2-9f70-266464f4a364
Spec:
Images:
Ubuntu:
Tags:
Created At: 2023-06-10T23:45:36Z
Pull Policy:
Active Deadline Seconds: 1200
Backoff Limit: 3
Timeout Seconds: 600
Ttl Seconds After Finished: 300
Tag: latest
Status:
Desired: 1
Failed: 0
Image Statuses:
Ubuntu:
Tags:
Completion Time: 2023-06-10T23:45:50Z
Phase: Succeeded
Progress: 100
Start Time: 2023-06-10T23:45:36Z
Tag: latest
Pulling: 0
Succeeded: 1
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal PullImageSucceed 15s kruise-daemon-imagepuller Image ubuntu:latest, ecalpsedTime 13.645806656s
# 可以看到status中的信息表示了拉取镜像的状态,我们可以去节点查看镜像
[root@k-m-1 openkruise]# crictl image ls | grep ubuntu
docker.io/library/ubuntu latest 1f6ddc1b2547b 29.5MB
# ImagePullJob (high-level)
ImagePullJob 是一个 namespaced-scope 的资源。
apiVersion: apps.kruise.io/v1alpha1
kind: ImagePullJob
metadata:
name: job-with-always
spec:
image: nginx:1.9.1 # [required] 完整的镜像名 name:tag
parallelism: 10 # [optional] 最大并发拉取的节点梳理, 默认为 1
selector: # [optional] 指定节点的 名字列表 或 标签选择器 (只能设置其中一种)
names:
- node-1
- node-2
matchLabels:
node-type: xxx
# podSelector: # [optional] 通过 podSelector 匹配Pod,在这些 Pod 所在节点上拉取镜像, 与 selector 不能同时设置.
# matchLabels:
# pod-label: xxx
# matchExpressions:
# - key: pod-label
# operator: In
# values:
# - xxx
completionPolicy:
type: Always # [optional] 默认为 Always
activeDeadlineSeconds: 1200 # [optional] 无默认值, 只对 Alway 类型生效
ttlSecondsAfterFinished: 300 # [optional] 无默认值, 只对 Alway 类型生效
pullPolicy: # [optional] 默认 backoffLimit=3, timeoutSeconds=600
backoffLimit: 3
timeoutSeconds: 300
你可以在 selector 字段中指定节点的 名字列表 或 标签选择器 (只能设置其中一种),如果没有设置 selector 则会选择所有节点做预热。
或者你可以配置 podSelector 来在这些 pod 所在节点上拉取镜像,podSelector 与 selector 不能同时设置。
同时,ImagePullJob 有两种 completionPolicy 类型:
1:Always 表示这个 job 是一次性预热,不管成功、失败都会结束
1:activeDeadlineSeconds: 整个 job 的 deadline 结束时间
2:ttlSecondsAfterFinished: 结束后超过这个时间,自动清理删除 job
2:Never 表示这个 job 是长期运行、不会结束,并且会每天都会在匹配的节点上重新预热一次指定的镜像
# 如果这个镜像来自一个私有仓库,你可能需要配置一些 secret:
# ...
spec:
pullSecrets:
- secret-name1
- secret-name2
因为 ImagePullJob 是一种 namespaced-scope 资源,这些 secret 必须存在 ImagePullJob 所在的 namespace 中。 然后你只需要在 pullSecrets 字段中写上这些 secret 的名字即可。
7.3:Container Launch Priority
Container Launch Priority 提供了控制一个 Pod 中容器启动顺序的方法。
通常来说 Pod 容器的启动和退出顺序是由 Kubelet 管理的。Kubernetes 曾经有一个 KEP 计划在 container 中增加一个 type 字段来标识不同类型容器的启停优先级。 但是由于sig-node考虑到对现有代码架构的改动太大,它已经被拒绝了。
注意,这个功能作用在 Pod 对象上,不管它的 owner 是什么类型的,因此可以适用于 Deployment、CloneSet 以及其他的 workload 种类。
只需要在 Pod 中定义一个 annotation 即可:
apiVersion: v1
kind: Pod
annotations:
apps.kruise.io/container-launch-priority: Ordered
spec:
containers:
- name: sidecar
# ...
- name: main
# ...
Kruise 会保证前面的容器(sidecar)会在后面容器(main)之前启动。
7.4:ResourceDistribution
在对 Secret、ConfigMap 等 namespace-scoped 资源进行跨 namespace 分发及同步的场景中,原生 kubernetes 目前只支持用户 one-by-one 地进行手动分发与同步,十分地不方便。
典型的案例有:
1:当用户需要使用 SidecarSet 的 imagePullSecrets 能力时,要先重复地在相关 namespaces 中创建对应的 Secret,并且需要确保这些 Secret 配置的正确性和一致性。
2:用户想要采用 ConfigMap 来配置一些通用的环境变量时,往往需要在多个 namespaces 做 ConfigMap 的下发,并且后续的修改往往也要求多 namespaces 之间保持同步。
3:在多个Namespace下的Ingress需要使用同一个Secret对象
因此,面对这些需要跨 namespaces 进行资源分发和多次同步的场景,我们期望一种更便捷的分发和同步工具来自动化地去做这件事,为此我们设计并实现了一个新的CRD --- ResourceDistribution。
ResourceDistribution 目前支持 Secret 和 ConfigMap 两类资源的分发和同步。
ResourceDistribution是一类 cluster-scoped 的 CRD,其主要由 resource 和 targets 两个字段构成,其中 resource 字段用于描述用户所要分发的资源,targets 字段用于描述用户所要分发的目标命名空间。
apiVersion: apps.kruise.io/v1alpha1
kind: ResourceDirstribution
metadata:
name: sample
spec:
resource:
# ...
targets:
# ...
其中resource字段必须是一个完整,正确的资源描述
apiVersion: apps.kruise.io/v1alpha1
kind: ResourceDistribution
metadata:
name: sample
spec:
resource:
apiVersion: v1
kind: ConfigMap
metadata:
name: game-demo
data:
game.properties: |
enemy.types=aliens,monsters
player.maximum-lives=5
player_initial_lives: "3"
ui_properties_file_name: user-interface.properties
user-interface.properties: |
color.good=purple
color.bad=yellow
allow.textmode=true
targets:
... ...
ips: 用户可以先在本地某个命名空间中创建相应资源并进行测试,确认资源配置正确后再拷贝过来。
# Target 字段说明
targets 字段目前支持四种规则来描述用户所要分发的目标命名空间,包括 allNamespaces、includedNamespaces、namespaceLabelSelector 以及 excludedNamespaces:
1:allNamespaces: bool值,如果为true,则分发至所有命名空间;
2:includedNamespaces: 通过 Name 来匹配目标命名空间;
3:namespaceLabelSelector:通过 LabelSelector 来匹配目标命名空间;
4:excludedNamespaces: 通过 Name 来排除某些不想分发的命名空间;
目标命名空间的计算规则:
1:初始化目标命名空间 T = ∅;
2:如果用户设置了allNamespaces=true,T 则会匹配所有命名空间;
3:将includedNamespaces中列出的命名空间加入 T;
4:将与namespaceLabelSelector匹配的命名空间加入 T;
5:将excludedNamespaces中列出的命名空间从 T 中剔除;
allNamespaces、includedNamespaces、namespaceLabelSelector 之间是 或(OR) 的关系,而excludedNamespaces一旦被配置,则会显式地排除掉这些命名空间。另外,targets还将自动忽略kube-system 和 kube-public 两个命名空间。
apiVersion: apps.kruise.io/v1alpha1
kind: ResourceDistribution
metadata:
name: sample
spec:
resource:
... ...
targets:
includedNamespaces:
list:
- name: ns-1
- name: ns-4
namespaceLabelSelector:
matchLabels:
group: test
excludedNamespaces:
list:
- name: ns-3
该 ResourceDistribution 的目标命名空间一定会包含ns-1和ns-4,并且Labels满足namespaceLabelSelector的命名空间也会被包含进目标命名空间,但是,即使ns-3即使满足namespaceLabelSelector也不会被包含,因为它已经在excludedNamespaces中被显式地排除了。
ResourceDistribution 允许用户更新resource字段,即更新资源,并且会自动地对所有目标命名空间中的资源进行同步更新。 每一次更新资源时,ResourceDistribution 都会计算新版本资源的哈希值,并记录到资源的Annotations之中,当 ResourceDistribution 发现新版本的资源与目前资源的哈希值不同时,才会对资源进行更新。
apiVersion: v1
kind: ConfigMap
metadata:
name: game-demo
annotations:
kruise.io/resourcedistribution.resource.from: sample
kruise.io/resourcedistribution.resource.distributed.timestamp: 2021-09-06 08:44:52.7861421 +0000 UTC m=+12896.810364601
kruise.io/resourcedistribution.resource.hashcode: 0821a13321b2c76b5bd63341a0d97fb46bfdbb2f914e2ad6b613d10632fa4b63
... ...
我们非常不建议用户绕过 ResourceDistribution 直接对资源进行修改,除非用户知道自己在做什么:
1:直接修改资源后,资源的哈希值不会被自动计算,因此,下次 resource字段被修改后,ResourceDistribution 可能将用户对这些资源的直接修改覆盖掉;
2:ResourceDistribution 通过 kruise.io/resourcedistribution.resource.from 来判断资源是否由该 ResourceDistribution 分发,如果该 Annotation 被修改或删除,则被修改的资源会被 ResourceDistribution 当成冲突资源,并且无法通过 ResourceDistribution 进行同步更新。
8:Kruise Rollouts
Kruise Rollouts是OpenKruise提供的一个旁路组件,用于提供先进的渐进式交付功能,它支持金丝雀,多批次和A/B测试交付模式,可以帮助实现对应应用程序变更和平稳可控发布,同时它与Gateway API和各种Ingress实现的兼容性使其更容易与你现有基础架构集成,总的来说,Kruise Rollouts对于希望优化其部署流程的Kubernetes用户来说是一个有价值的工具。
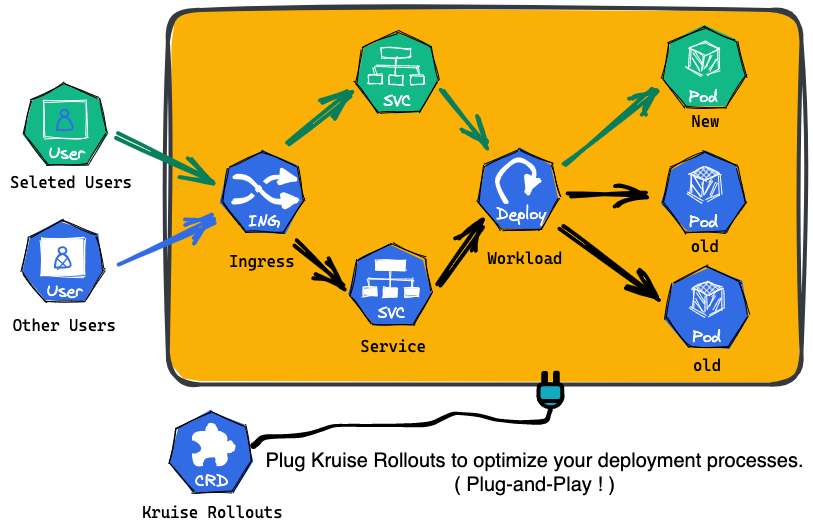
kruise Rollouts具有如下几个主要特点:
1:更多的发布策略
1:Deployment,CloneSet,StatefulSet和Advanced StatefulSet的多批次更新策略
2:Deployment的金丝雀发布策略
2:更多流量路由管理策略
1:在更新工作负载时进行流量细粒度加权流量转移
2:基于HTTP头和Cookie进行A/B测试,根据流量进行转移
3:更多流量协议支持
1:Ingress控制器集成:NGINX,ALB,Higress
2:通过Gateway API与服务网格集成
3:可插拔的Lua脚本,轻松扩展到其他Kubernetes流量协议(甚至CRD)
4:容易集成
1:轻松与GitOps风格的基于Kubernetes的PaaS集成
和其他发布组件相比,Kruise Rollouts的优势如下
| Component |
Kruise Rollouts |
Argo Rollouts |
Flux Flagger |
| 核心概念 |
增强现有工作负载 |
替换工作负载 |
管理工作负载 |
| 架构 |
旁路 |
新的工作负载类型 |
旁路 |
| 插拔式组件,热插拔 |
是 |
否 |
否 |
| 发布类型 |
多批次,金丝雀,A/B测试 |
多批次,金丝雀,蓝绿,A/B测试 |
金丝雀,蓝绿,A/B测试 |
| 工作负载类型 |
Deployment,StatefulSet,CloneSet,Advaned StatefulSet,DaemonSet(WIP) |
Agro-Rollout |
Deployment. DaemonSet |
| 流量类型 |
Ingress, GatewayAPI, CRD (Need Lua Script) |
Ingress, GatewayAPI, APISIX, Traefik, SMI and more |
Ingress, GatewayAPI, APISIX, Traefik, SMI and more |
| 迁移成本 |
无需迁移你的工作负载和Pod |
必须迁移你的工作负载和Pod |
必须迁移你的Pod |
| HPA兼容 |
是 |
是 |
是 |
整体对比下来,Kruise Rollouts与Argo Rollouts有相似的架构,但是功能上Kruise Rollouts更强一些,支持更多的发布策略和流量路由管理策略,同时也支持更多的流量协议,Kruise Rollouts也是一个旁路组件,不需要迁移你的工作负载和Pod,你可以在任何时候安装它,它会自动发现你的工作负载并管理它们,而和Flagger相比,Kruise Rollouts支持更多的发布策略和流量路由管理策略,同时也支持更多的流量协议
所以如果你想要更多的发布策略和流量路由管理策略,同时也想要更多的流量协议支持,那么Kruise Rollouts就是一个不错的选择
8.1:Kruise Rollouts安装
要求:要使用Kruise Rollouts的话Kubernetes版本必须>= 1.19版本,如果要使用CloneSet作为工作负载类型,则还需要安装OpenKruise
# 我们这里依旧使用Helm来安装它
[root@k-m-1 rollouts]# helm repo add openkruise https://openkruise.github.io/charts/
[root@k-m-1 rollouts]# helm repo update
[root@k-m-1 rollouts]# helm upgrade --install kruise-rollouts openkruise/kruise-rollout --version 0.3.0
Release "kruise-rollouts" does not exist. Installing it now.
NAME: kruise-rollouts
LAST DEPLOYED: Sun Jun 11 09:25:29 2023
NAMESPACE: default
STATUS: deployed
REVISION: 1
TEST SUITE: None
# 查看部署结果
[root@k-m-1 rollouts]# kubectl get pod -n kruise-rollout
NAME READY STATUS RESTARTS AGE
kruise-rollout-controller-manager-84b54b7584-gdtbk 1/1 Running 0 41s
kruise-rollout-controller-manager-84b54b7584-jnb2k 1/1 Running 0 41s
# 同时它还安装了三个用于Rollouts的CRD
[root@k-m-1 rollouts]# kubectl get crd | grep rollouts
batchreleases.rollouts.kruise.io 2023-06-11T01:25:29Z
rollouthistories.rollouts.kruise.io 2023-06-11T01:25:29Z
rollouts.rollouts.kruise.io 2023-06-11T01:25:29Z
# 查看helm安装记录
[root@k-m-1 rollouts]# helm ls
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
kruise default 1 2023-06-05 07:28:04.642089649 +0800 deployed kruise-1.4.0 1.4.0
kruise-rollouts default 1 2023-06-11 09:25:29.583140174 +0800 deployed kruise-rollout-0.3.0 0.3.0
8.2:Kruise Rollouts管理工作负载
# 当然了,在管理工作负载之前,我们肯定得有一个工作负载可供管理,那么下面是一个工作负载的demo
apiVersion: apps/v1
kind: Deployment
metadata:
name: workload
namespace: default
spec:
replicas: 10
selector:
matchLabels:
app: busybox
template:
metadata:
labels:
app: busybox
spec:
containers:
- name: busybox
image: busybox:latest
command: ["/bin/sh", "-c", "sleep 100d"]
env:
- name: VERSION
value: "version-1"
# 部署一下工作负载
[root@k-m-1 rollouts]# kubectl apply -f workload.yaml
deployment.apps/workload created
# 查看工作负载
[root@k-m-1 rollouts]# kubectl get pod
NAME READY STATUS RESTARTS AGE
workload-854b5ccf8f-7wlqk 1/1 Running 0 45s
workload-854b5ccf8f-bk6kt 1/1 Running 0 45s
workload-854b5ccf8f-dxxrb 1/1 Running 0 45s
workload-854b5ccf8f-l9w25 1/1 Running 0 45s
workload-854b5ccf8f-pjtdc 1/1 Running 0 45s
workload-854b5ccf8f-pshf6 1/1 Running 0 45s
workload-854b5ccf8f-q86d2 1/1 Running 0 45s
workload-854b5ccf8f-vljf2 1/1 Running 0 45s
workload-854b5ccf8f-vpbqx 1/1 Running 0 45s
workload-854b5ccf8f-wrv5h 1/1 Running 0 45s
# 多批次更新是Kruise Rollouts的一个特性,它可以支持让我们在更新工作负载时,可以控制每批次更新的Pod数量,以及每批次更新时间的间隔,接下来我们需要创建一个Rollout对象来管理这个工作负载,比如我们想使用多批次更新策略将Deployment从version-1升级到version-2
1:第一批:升级一个Pod
2:第二批:50%的Pod应该升级,即5个更新的Pod
3:第三批:100%的Pod因该被升级,即10个更新Pod
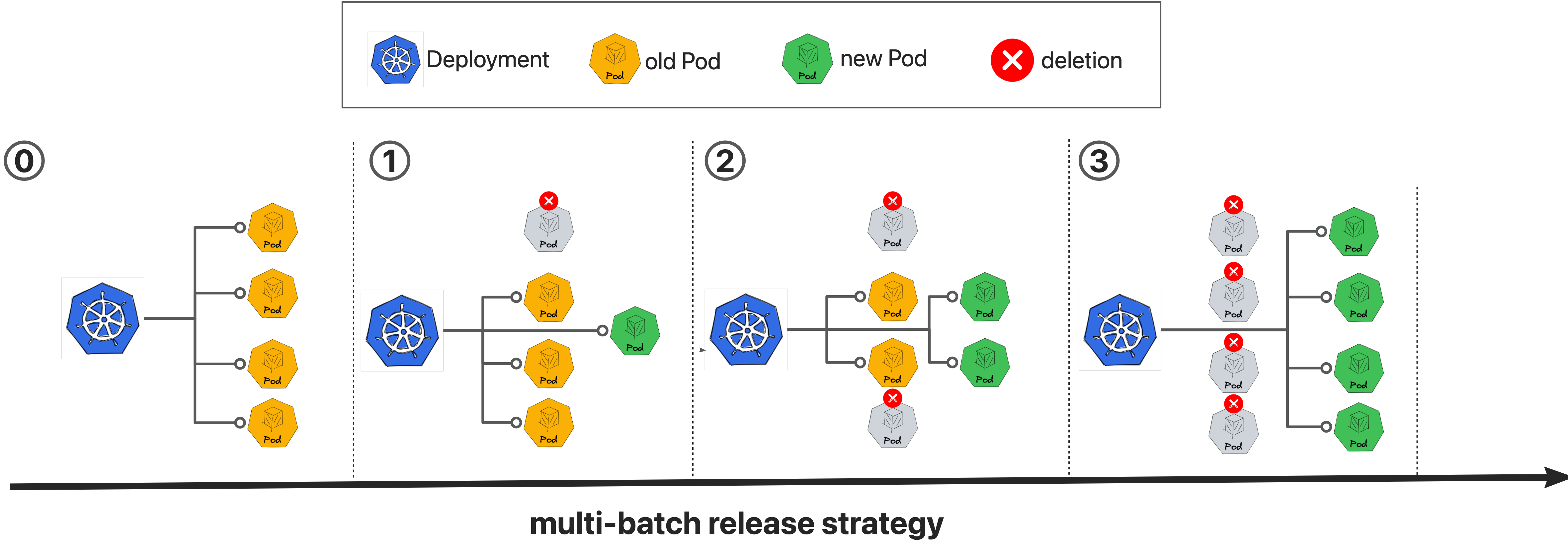
目前,多批次更新策略可以在CloneSet,StatefulSet,Advanced StatefulSet和Deployment上工作,那么我们来看看示例
apiVersion: rollouts.kruise.io/v1alpha1
kind: Rollout
metadata:
name: rollout
namespace: default
annotations:
rollouts.kruise.io/rolling-style: partition
# 使用多批次更新策略,只能配置partition和canary
# partition:意味着像CloneSet一样分批次滚动,不会创建任何额外的Workload
# canary:表示以金丝雀方式滚动,并创建一个金丝雀工作负载,对于Deployment默认是canary
spec:
objectRef: # 定义工作负载
workloadRef: # 关联需要管理的工作负载
apiVersion: apps/v1
kind: Deployment
name: workload
strategy: # 定义升级策略
canary: # 使用canary策略
steps:
- replicas: 1
- replicas: 50%
- replicas: 100%
# 我们可以直接创建Rollout对象
[root@k-m-1 rollouts]# kubectl apply -f rollout.yaml
rollout.rollouts.kruise.io/rollout created
[root@k-m-1 rollouts]# kubectl get rollout
NAME STATUS CANARY_STEP CANARY_STATE MESSAGE AGE
rollout Healthy 3 Completed workload deployment is completed 5s
# 此时我们的Rollout没有监测到任何更新,所以它的msg告诉我们的是workload是complete状态,我们这个时候只需要去更新一下Workload一下就好了
apiVersion: apps/v1
kind: Deployment
metadata:
name: workload
namespace: default
spec:
replicas: 10
selector:
matchLabels:
app: busybox
template:
metadata:
labels:
app: busybox
spec:
containers:
- name: busybox
image: busybox:latest
command: ["/bin/sh", "-c", "sleep 100d"]
env:
- name: VERSION
# 更新一下version的版本
value: "version-2"
# 部署一下更新
[root@k-m-1 rollouts]# kubectl apply -f workload.yaml
deployment.apps/workload created
[root@k-m-1 rollouts]# kubectl get deployments.apps
NAME READY UP-TO-DATE AVAILABLE AGE
workload 10/10 1 10 54m
[root@k-m-1 rollouts]# kubectl get pod
NAME READY STATUS RESTARTS AGE
workload-56db5786cf-cxzpm 1/1 Running 0 63s
workload-854b5ccf8f-7wlqk 1/1 Running 0 54m
workload-854b5ccf8f-bk6kt 1/1 Running 0 54m
workload-854b5ccf8f-dxxrb 1/1 Running 0 54m
workload-854b5ccf8f-l9w25 1/1 Running 0 54m
workload-854b5ccf8f-pjtdc 1/1 Running 0 54m
workload-854b5ccf8f-pshf6 1/1 Running 0 54m
workload-854b5ccf8f-vljf2 1/1 Running 0 54m
workload-854b5ccf8f-vpbqx 1/1 Running 0 54m
workload-854b5ccf8f-wrv5h 1/1 Running 0 54m
[root@k-m-1 rollouts]# kubectl describe rollout rollout
......
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Progressing 87s rollout-controller upgrade step(1) canary pods with new versions done
# 通过如上几步都可以看出,目前的确是更新了一个Pod,其他的Pod都还没有更新,这个时候由于我们没有配置pause这个参数,所以需要让我们手动去确认下一步是否继续执行,这里我们需要装一个kubectl-kruise
[root@k-m-1 rollouts]# wget https://github.com/openkruise/kruise-tools/releases/download/v1.0.5/kubectl-kruise-linux-amd64.tar.gz
[root@k-m-1 rollouts]# tar xf kubectl-kruise-linux-amd64.tar.gz
[root@k-m-1 rollouts]# mv linux-amd64/kubectl-kruise /usr/local/bin/
[root@k-m-1 rollouts]# kubectl kruise version
Client Version: version.Info{Major:"1", Minor:"0", GitVersion:"v1.0.5", GitCommit:"a27ae8ca65b365a38f797f19f0b8821925389290", GitTreeState:"clean", BuildDate:"2022-10-13T06:45:07Z", GoVersion:"go1.16.15", Compiler:"gc", Platform:"linux/amd64"}
Server Version: version.Info{Major:"1", Minor:"25", GitVersion:"v1.25.0", GitCommit:"a866cbe2e5bbaa01cfd5e969aa3e033f3282a8a2", GitTreeState:"clean", BuildDate:"2022-08-23T17:38:15Z", GoVersion:"go1.19", Compiler:"gc", Platform:"linux/amd64"}
WARNING: version difference between client (1.0) and server (1.25) exceeds the supported minor version skew of +/-1
# 既然有了cli了,那么我们就可以去使用cli进行手动确认发布了
[root@k-m-1 rollouts]# kubectl kruise rollout approve rollout
rollout.rollouts.kruise.io/rollout approved
# 根据我们定义的预期,第二批次是更新50%的Pod
[root@k-m-1 rollouts]# kubectl get pod
NAME READY STATUS RESTARTS AGE
workload-56db5786cf-4tjz2 1/1 Running 0 61s
workload-56db5786cf-8nbxx 1/1 Running 0 61s
workload-56db5786cf-cxzpm 1/1 Running 0 100m
workload-56db5786cf-h6nz5 1/1 Running 0 61s
workload-56db5786cf-wxcjt 1/1 Running 0 61s
workload-854b5ccf8f-7wlqk 1/1 Running 0 154m
workload-854b5ccf8f-l9w25 1/1 Running 0 154m
workload-854b5ccf8f-pjtdc 1/1 Running 0 154m
workload-854b5ccf8f-pshf6 1/1 Running 0 154m
workload-854b5ccf8f-vljf2 1/1 Running 0 154m
[root@k-m-1 rollouts]# kubectl get deployments.apps
NAME READY UP-TO-DATE AVAILABLE AGE
workload 10/10 5 10 159m
# 前五个都是我们发布的版本,其次我们再来看看rollout的控制器
[root@k-m-1 rollouts]# kubectl describe rollout rollout
......
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Progressing 110s rollout-controller upgrade step(2) canary pods with new versions done
# 可以看到这个时候是金丝雀第二段,Pod的数量也是我们预期之中的,
# 再次手动触发确认
[root@k-m-1 rollouts]# kubectl kruise rollout approve rollout
rollout.rollouts.kruise.io/rollout approved
[root@k-m-1 rollouts]# kubectl get deployments.apps
NAME READY UP-TO-DATE AVAILABLE AGE
workload 10/10 10 10 161m
[root@k-m-1 rollouts]# kubectl get pods
NAME READY STATUS RESTARTS AGE
workload-56db5786cf-4tjz2 1/1 Running 0 8m30s
workload-56db5786cf-8nbxx 1/1 Running 0 8m30s
workload-56db5786cf-98q2q 1/1 Running 0 43s
workload-56db5786cf-cxzpm 1/1 Running 0 107m
workload-56db5786cf-h6nz5 1/1 Running 0 8m30s
workload-56db5786cf-kl6bm 1/1 Running 0 43s
workload-56db5786cf-p5vvw 1/1 Running 0 43s
workload-56db5786cf-qqf9p 1/1 Running 0 43s
workload-56db5786cf-vqmk7 1/1 Running 0 43s
workload-56db5786cf-wxcjt 1/1 Running 0 8m30s
# 这个时候所有的应用就全部升级了,也就意味着我们的金丝雀发布完成了。
# 上面我们使用kubectl kruise rollout approve 命令来手动确认的,那么还有其他方法吗?目前一共两种方法
1:可以将第一批pause.duration字段来设置为duration: 0,会自动进入下一批
2:可以更新rollout.status.canaryStatus.currentStepState字段为StepReady,同样会自动进入下一批次
# 当然两种方法都有自己的优缺点:
1:它可以确保你操作的幂等性,但是在下一个发布之前,你需要将发布策略重置回原始状态(例如持续duration重置为nil)
kind: Rollout
spec:
strategy:
canary:
steps:
- replicas: 1
pause:
duration: 0
- ... ...
2:无需在下一次发布之前更改任何内容,不过在确认之前,需要查看Rollout的状态,使用update接口,而不是Kubernetes客户端的patch接口,或者使用我们的kubectl-kruise工具,也就是上面我们使用的
kubectl kruise rollout approve rollout/<rollout name> -n <namespace>
那么入过我们想要回滚操作该怎么办呢?事实上,Kruise Rollout 不提供直接回滚的能力,Kruise Rollout 更喜欢用户可以直接回滚工作负载来规范的回滚他们的应用程序,当用户需要从version-2回滚到version-1时,Kruise Rollout会使用原生的滚动升级策略快速回滚,而不是遵循multi-batch checkpoint策略
此外还有一些其他注意事项值得我们注意:
1:持续发布:假设Rollout正在从version-1发布到version-2(未完成),现在,工作负载被修改为了version-3,Rollout将从步骤(第一步)开始进行
2:HPA兼容性:假设你将HPA配置为你的工作负载并使用多批次更新策略,我们建议使用百分比来指定steps[x].replicas,如果rollout发布过程中副本被放大/缩小,旧版本和新版本将根据百分比配置进行缩放。
8.3:Kruise Rollouts金丝雀发布
金丝雀发布允许用户在发布新版本时,将流量分配给新版本一小部分,以便在发布新版本之前,可以对其进行测试,如果测试通过,则将可以将流量分配给新版本的所有副本,否则可以回滚到旧版本。
但可惜的是目前金丝雀发布仅支持Deployment工作负载
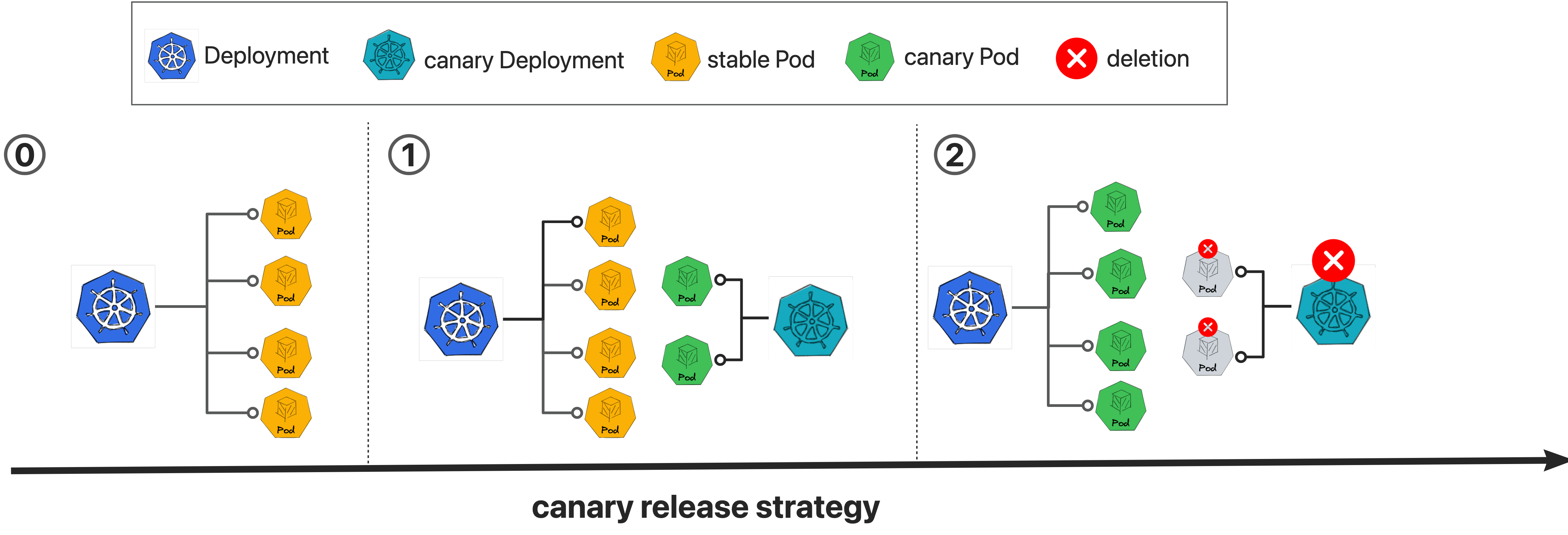
apiVersion: apps/v1
kind: Deployment
metadata:
name: echoserver
labels:
app: echoserver
spec:
replicas: 5
selector:
matchLabels:
app: echoserver
template:
metadata:
labels:
app: echoserver
spec:
containers:
- name: echoserver
image: registry.aliyuncs.com/google_containers/echoserver:1.10
ports:
- containerPort: 8080
env:
- name: VERSION
value: v1
- name: NODE_NAME
value: version1
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
- name: POD_IP
valueFrom:
fieldRef:
fieldPath: status.podIP
---
apiVersion: v1
kind: Service
metadata:
name: echoserver
labels:
app: echoserver
spec:
ports:
- port: 8080
targetPort: 8080
selector:
app: echoserver
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: echoserver
spec:
ingressClassName: nginx
rules:
- host: echo.k8s.local
http:
paths:
- path: /apis/echo
pathType: Exact
backend:
service:
name: echoserver
port:
number: 8080
# 那么我们接下来就部署一下它
[root@k-m-1 rollouts]# kubectl get pod,svc,ingress
NAME READY STATUS RESTARTS AGE
pod/echoseve-6f9d7bbfd6-2vbmk 1/1 Running 0 41s
pod/echoseve-6f9d7bbfd6-c9nb7 1/1 Running 0 41s
pod/echoseve-6f9d7bbfd6-jp9dv 1/1 Running 0 41s
pod/echoseve-6f9d7bbfd6-kbjzv 1/1 Running 0 41s
pod/echoseve-6f9d7bbfd6-p9tfx 1/1 Running 0 41s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/echoserver ClusterIP 10.96.3.92 <none> 8080/TCP 41s
service/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 41d
NAME CLASS HOSTS ADDRESS PORTS AGE
ingress.networking.k8s.io/echoserver nginx echo.k8s.local 10.0.0.11 80 41s
# 本地我就是用hosts解析一下了
[root@k-m-1 rollouts]# curl echo.k8s.local/apis/echo
Hostname: echoserver-6f9d7bbfd6-crtfj
Pod Information:
node name: version1
pod name: echoserver-6f9d7bbfd6-crtfj
pod namespace: default
pod IP: 100.114.94.176
Server values:
server_version=nginx: 1.13.3 - lua: 10008
Request Information:
client_address=10.0.0.11
method=GET
real path=/apis/echo
query=
request_version=1.1
request_scheme=http
request_uri=http://echo.k8s.local:8080/apis/echo
Request Headers:
accept=*/*
host=echo.k8s.local
user-agent=curl/7.76.1
x-forwarded-for=10.0.0.11
x-forwarded-host=echo.k8s.local
x-forwarded-port=80
x-forwarded-proto=http
x-forwarded-scheme=http
x-real-ip=10.0.0.11
x-request-id=2019bf15c8b075290ae5fe21cc676330
x-scheme=http
Request Body:
-no body in request-
# 这是目前我们请求的信息
那么接下来我们就可以使用Rollout来进行金丝雀发布了,下面是一个示例
apiVersion: rollouts.kruise.io/v1alpha1
kind: Rollout
metadata:
name: rollouts-canary
annotations:
rollouts.kruise.io/rolling-style: canary # 指定金丝雀发布策略
spec:
objectRef:
workloadRef:
apiVersion: apps/v1
kind: Deployment
name: echoserver
strategy:
canary: # 金丝雀发布策略
steps:
- weight: 5 # 导入5%的流量
replicas: 1 # 第一批发布的副本数
- weight: 40 # 导入40%的流量,没有配置replicas,也就意味着发布40%的副本数
pause:
duration: 30 # 不需要人工确认,等待30s继续下一批
- weight: 60
pause:
duration: 30
- weight: 80
pause:
duration: 30
- weight: 100
pause:
duration: 30
trafficRoutings: # 流量路由
- service: echoserver
ingress:
classType: nginx
name: echoserver
# 部署Rollout
[root@k-m-1 rollouts]# kubectl apply -f rollout-canary.yaml
rollout.rollouts.kruise.io/rollouts-canary created
[root@k-m-1 rollouts]# kubectl get rollout
NAME STATUS CANARY_STEP CANARY_STATE MESSAGE AGE
rollouts-canary Healthy 5 Completed workload deployment is completed 4m25s
# 然后我们再次打开一个终端去监听一下请求,因为我们要看出效果,所以来看看
[root@k-m-1 rollouts]# while true; do curl -s http://echo.k8s.local/apis/echo | grep node; sleep 5; done
node name: version1
node name: version1
# 这个脚本会每隔5秒请求一次我们的应用,从而可以看出金丝雀的效果
apiVersion: apps/v1
kind: Deployment
metadata:
name: echoserver
labels:
app: echoserver
spec:
replicas: 5
selector:
matchLabels:
app: echoserver
template:
metadata:
labels:
app: echoserver
spec:
containers:
- name: echoserver
image: registry.aliyuncs.com/google_containers/echoserver:1.10
ports:
- containerPort: 8080
env:
# 这里变更不变更无所谓
- name: VERSION
value: v2
- name: NODE_NAME
# 我们只变更了这个变量的值
value: version2
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
- name: POD_IP
valueFrom:
fieldRef:
fieldPath: status.podIP
---
apiVersion: v1
kind: Service
metadata:
name: echoserver
labels:
app: echoserver
spec:
ports:
- port: 8080
targetPort: 8080
selector:
app: echoserver
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: echoserver
spec:
ingressClassName: nginx
rules:
- host: echo.k8s.local
http:
paths:
- path: /apis/echo
pathType: Exact
backend:
service:
name: echoserver
port:
number: 8080
# 发布新版本
[root@k-m-1 rollouts]# kubectl apply -f workload-canary.yaml
deployment.apps/echoserver configured
service/echoserver unchanged
ingress.networking.k8s.io/echoserver unchanged
[root@k-m-1 rollouts]# kubectl get deployments.apps
NAME READY UP-TO-DATE AVAILABLE AGE
echoserver 5/5 0 5 8m49s
echoserver-4vn72 1/1 1 1 69s
# 查看金丝雀版本是否请求到流量
[root@k-m-1 rollouts]# while true; do curl -s http://echo.k8s.local/apis/echo | grep node; sleep 5; done
......
node name: version1
node name: version1
node name: version1
node name: version1
node name: version1
# 明显可以看到金丝雀版本拿到流量了
node name: version2
node name: version1
node name: version1
# 之不过我们第一次发布版本的时候只发布了一个Pod,所以流量不会特别多,而且我们定义了,只有5%的流量进入,所以会很少
[root@k-m-1 rollouts]# kubectl get pod
NAME READY STATUS RESTARTS AGE
echoserver-4vn72-64799fc45d-z44px 1/1 Running 0 15m
echoserver-6f9d7bbfd6-crtfj 1/1 Running 0 22m
echoserver-6f9d7bbfd6-jllhd 1/1 Running 0 22m
echoserver-6f9d7bbfd6-lmb65 1/1 Running 0 22m
echoserver-6f9d7bbfd6-m46nw 1/1 Running 0 22m
echoserver-6f9d7bbfd6-t8sdk 1/1 Running 0 22m
# 可以看到金丝雀这个时候就也会创建一个Pod帮我们去支持服务,但是具体说它是怎么去支持流量的,这个我们直接看service就行
[root@k-m-1 rollouts]# kubectl get service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
echoserver ClusterIP 10.96.1.94 <none> 8080/TCP 23m
echoserver-canary ClusterIP 10.96.3.140 <none> 8080/TCP 16m
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 41d
# 可以看出它是帮我们创建了一个service是canary的service,那么我们看看详情
apiVersion: v1
kind: Service
metadata:
creationTimestamp: "2023-06-11T12:21:07Z"
name: echoserver-canary
namespace: default
ownerReferences:
- apiVersion: rollouts.kruise.io/v1alpha1
blockOwnerDeletion: true
controller: true
kind: Rollout
name: rollouts-canary
uid: 0469aadf-23d9-45c0-9999-8cecd28174bd
resourceVersion: "9781653"
uid: 585cdaee-33d6-45c9-93dd-780a4abfadc0
spec:
clusterIP: 10.96.3.140
clusterIPs:
- 10.96.3.140
internalTrafficPolicy: Cluster
ipFamilies:
- IPv4
ipFamilyPolicy: SingleStack
ports:
- port: 8080
protocol: TCP
targetPort: 8080
selector:
app: echoserver
# 这个是它自动帮我们创建的一个labels
pod-template-hash: 64799fc45d
sessionAffinity: None
type: ClusterIP
status:
loadBalancer: {}
# 再来看看ingress,同样它也帮我们创建了一个ingress去关联这个service
[root@k-m-1 rollouts]# kubectl get ingress
NAME CLASS HOSTS ADDRESS PORTS AGE
echoserver nginx echo.k8s.local 10.0.0.11 80 25m
echoserver-canary nginx echo.k8s.local 10.0.0.11 80 18m
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
annotations:
kubectl.kubernetes.io/last-applied-configuration: |
{"apiVersion":"networking.k8s.io/v1","kind":"Ingress","metadata":{"annotations":{},"name":"echoserver","namespace":"default"},"spec":{"ingressClassName":"nginx","rules":[{"host":"echo.k8s.local","http":{"paths":[{"backend":{"service":{"name":"echoserver","port":{"number":8080}}},"path":"/apis/echo","pathType":"Exact"}]}}]}}
# 这里就是基于ingress的金丝雀了,开启金丝雀发布
nginx.ingress.kubernetes.io/canary: "true"
# 配置5%的流量进入到这里
nginx.ingress.kubernetes.io/canary-weight: "5"
creationTimestamp: "2023-06-11T12:21:00Z"
generation: 1
name: echoserver-canary
namespace: default
ownerReferences:
- apiVersion: rollouts.kruise.io/v1alpha1
blockOwnerDeletion: true
controller: true
kind: Rollout
name: rollouts-canary
uid: 0469aadf-23d9-45c0-9999-8cecd28174bd
resourceVersion: "9781681"
uid: fd9c5bcb-f793-4955-a06f-bb483f86234a
spec:
ingressClassName: nginx
rules:
- host: echo.k8s.local
http:
paths:
- backend:
service:
name: echoserver-canary
port:
number: 8080
path: /apis/echo
pathType: Exact
status:
loadBalancer:
ingress:
- ip: 10.0.0.11
它帮我们关联了一个service,就是rollout帮我们创建的一个service,当我们去查看Pod的资源的时候其实它的labels里面也有一个labels是pod-template-hash: 64799fc45d
那么想要金丝雀继续发布,那么我们直接使用kubectl kruise确认一下就可以了
[root@k-m-1 rollouts]# kubectl kruise rollout approve rollout
rollout.rollouts.kruise.io/rollouts-canary approved
# 而后就是等待发布完成即可,我们配置了后面都是无需确认,所以最后的结果就是全部Pod发布到新版本
[root@k-m-1 rollouts]# while true; do curl -s http://echo.k8s.local/apis/echo | grep node; sleep 5; done
......
node name: version2
node name: version2
node name: version2
node name: version2
node name: version2
node name: version2
node name: version2
node name: version2
node name: version2
node name: version2
node name: version2
node name: version2
node name: version2
node name: version2
# 现在可以看到灰度的版本全部已经是version2的版本了,这里的需要给大家讲一下,当金丝雀全部发布完成之后,金丝雀所创建的Pod将会全部被删除,然后就是替换原来资源的信息,使得流量全部切换到新的版本。
# 下面看看发布的新版本后的资源情况
[root@k-m-1 rollouts]# kubectl get pod,svc,ingress
NAME READY STATUS RESTARTS AGE
pod/echoserver-64799fc45d-926kc 1/1 Running 0 2m29s
pod/echoserver-64799fc45d-9wkd8 1/1 Running 0 2m28s
pod/echoserver-64799fc45d-d65x6 1/1 Running 0 2m29s
pod/echoserver-64799fc45d-jrf46 1/1 Running 0 2m29s
pod/echoserver-64799fc45d-w58cc 1/1 Running 0 2m28s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/echoserver ClusterIP 10.96.1.94 <none> 8080/TCP 44m
service/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 41d
NAME CLASS HOSTS ADDRESS PORTS AGE
ingress.networking.k8s.io/echoserver nginx echo.k8s.local 10.0.0.11 80 44m
8.4:Kruise RolloutsA / B测试
A/B测试是一种常见的测试方法,它的原理是将用户分为几组,一组使用原来的版本,另一组使用新的版本,然后观察两组用户的行为,从而判断新版本是否更好,通常A/B测试的目的是为了验证新版本的功能是否可用,或者新版本是否能够带来更好的用户体验,需要结合具体的业务场景来进行。
目前 A/B Testing策略可以在CloneSet,StatefulSet,Advanced StatefulSet和Deployment上工作。
此外A/B Testing需要结合金丝雀或多批次发布策略
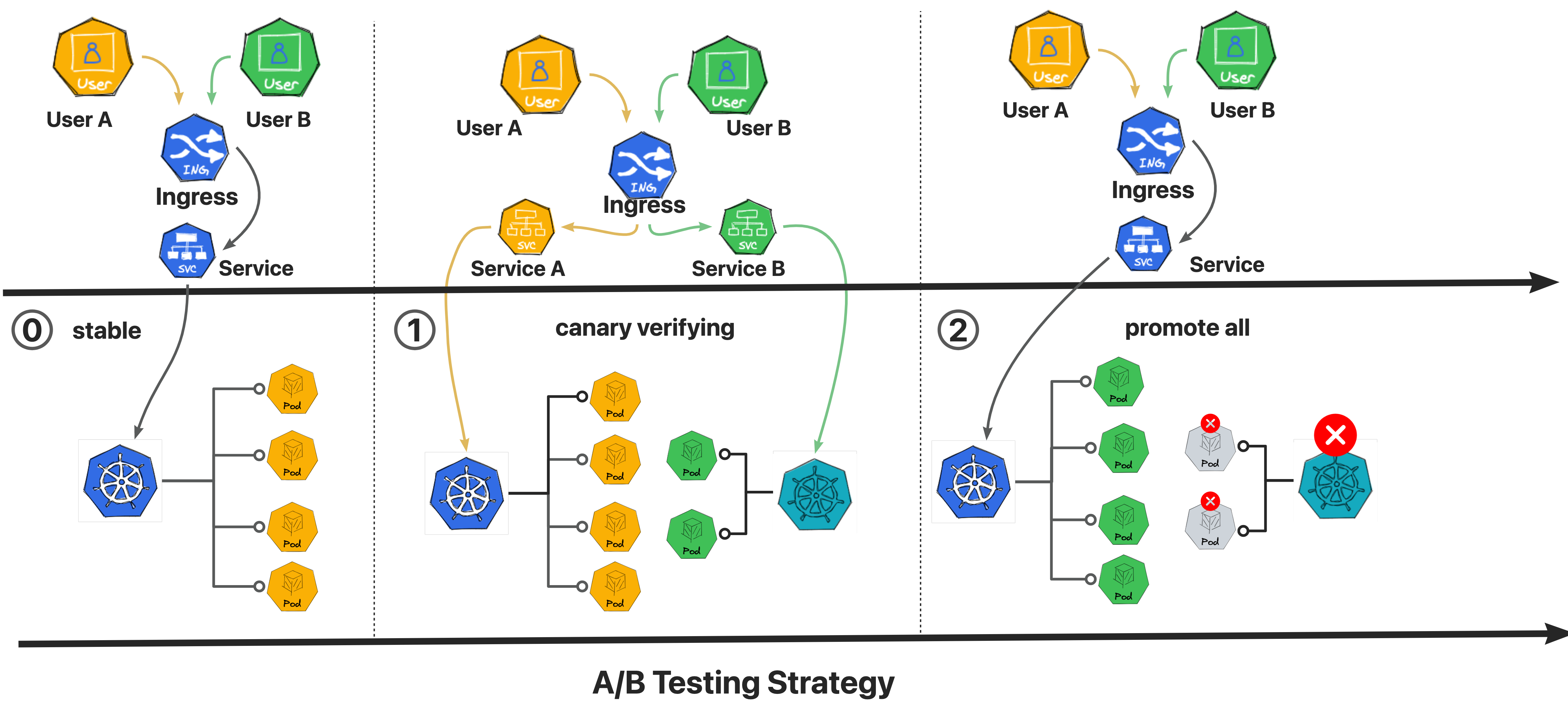
# 下面是一个A/B Testing的例子
apiVersion: rollouts.kruise.io/v1alpha1
kind: Rollout
metadata:
name: rollouts-demo
annotations:
rollouts.kruise.io/rolling-style: partition
spec:
objectRef:
workloadRef:
apiVersion: apps/v1
kind: Deployment
name: workload-demo
strategy:
canary:
steps:
- replicas: 3
matches: # 匹配规则
- headers: # HTTP Header匹配规则
- key: user-agent # HTTP Header名称
type: Exact # 匹配类型
value: pc # 匹配值
- replicas: 50%
- replicas: 100%
trafficRoutings:
- service: service-demo
ingress:
classType: nginx
name: ingress-demo
当使用该策略后:
1:第一批更新一个Pod,HTTP Header user-agent=pc的流量会被引导到新版本的Pod,其他流量会被引导到稳定版本Pod,需要人工确认下一批发布
2:第二批更新50%的Pod,Header匹配规则取消,所有流量将遵循原来的负载均衡规则,需要人工确认下一批发布
3:第三批更新100%的Pod,Header匹配规则取消,所有流量将遵循原来的负载均衡策略

 浙公网安备 33010602011771号
浙公网安备 33010602011771号