
collection集合--set
Set(无序、不能重复)
通过元素的equals方法,来判断是否为重复元素,
Lis是存放有序的,可重复的;
Set里存放的对象是无序,不能重复的,集合中的对象不按特定的方式排序,只是简单地把对象加入集合中。
不能存储相同的元素。
Set集合由Set接口和Set接口的实现类组成
同时因为其是一个抽象的接口:所以不能直接实例化一个set对象。(Set s = new Set() )错误
该接口主要继承于Collections接口,所以具有Collection的一些常见的方法。
Set接口继承了Collection接口,因此包含Collection接口的所有方法
(Set 的构造有一个约束条件,传入的Collection对象不能有重复)
Set 接口常用的实现类 有 HashSet 类 与LinkedHashSet类
HashSet:为快速查找设计的Set。存入HashSet的对象必须必须重写:hashCode()与equals()方法。
为什么重写hascode和equals:
1.Set不存重复元素
2.让equals方法和hashCode方法始终在逻辑上保持一致性。
其底层实现是一个哈希表,存入HashSet中的元素没有顺序性。它不保证Set的迭代顺序,特别是它不保证该顺序恒久不变,此类允许使用 null 元素
程序向HashSet中添加一个对象时,先用hashCode方法计算出该对象的哈希码。比较:
(1),如果该对象哈希码与集合已存在对象的哈希码不一致,则该对象没有与其他对象重复,添加到集合中!
(2),如果存在于该对象相同的哈希码,那么通过equals方法判断两个哈希码相同的对象是否为同一对象(判断的标准是:属性是否相同)
1>,相同对象,不添加。
2>,不同对象,添加!
这时有两个疑问:1,为什么哈希码相同了还有可能是不同对象?2,为什么经过比较哈希码还需要借助equals方法判断?
答:首先:按照Object类的hashCode方法,是不可能返回两个相同的哈希码的。(哈希码唯一标志了对象) 然后:Object类的hashCode方法返回的哈希码具有唯一性(地址唯一性),但是这样不能让程序的运行逻辑符合现实生活。(这个逻辑就是:属性相同的对象被看作同一个对象。)为了让程序的运行逻辑符合现实生活,Object的子类重写了hashCode的方法(基本数据类型的实现类都已经重写了两个方法,自定义的类要软件工程 师自己重写。)
个人理解:
add()方法先调用hashCode方法进行比较,结果为相同对象在调用eques()方法比较
那么:重写的宗旨是什么?重写就是为了实现这样的目的:属性相同的不同对象在调用其hashCode方法后,返回的是同样的哈希码。但是我们在重写的时候,发现几乎所有的写法都无法避免一个bug:有一些属性不同的对象(当然是不同的对象),会返回相同的哈希码。(即 重码)
最后:为了解决这个问题:在哈希码相同的时候,再用equals方法比较两个对象的对应属性是否相同,这样,确保了万无一失。这样:上面两个问题得到解决。
原文链接:https://blog.csdn.net/qq_38704184/article/details/81511695
LinkedHashSet:具有HashSet的查询速度,且内部使用链表维护元素的顺序(插入的次序)。于是在使用迭代器遍历Set时,结果会按元素插入的次序显示。
存入和取出的顺序一致(有序)
HashSet
哈希表如何确定元素是否相同?
- 判断两个元素的哈希值是否相同,其实判断的是对象的 hashCode() 方法
- 如果哈希值相同,再判断两个对象的内容是否相同,用的是 equals() 方法
- 如果哈希值不同,是不需要判断 equals() 方法的
HashSet是基于HashMap来实现的,操作很简单,更像是对HashMap做了一次“封装”,而且只使用了HashMap的key来实现各种特性,而HashMap的value始终都是PRESENT。
HashSet不允许重复(HashMap的key不允许重复,如果出现重复就覆盖),允许null值,非线程安全。
HashSet:
,(哈希值存入数组,链表存元素)
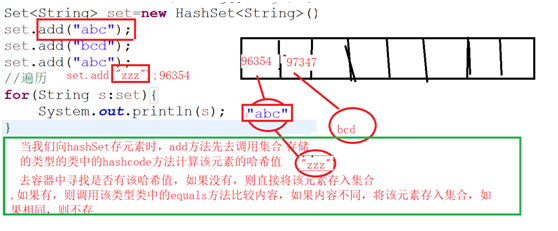
*当我们向集合 中存元素时,Add方法先去调用集合存储的类型的类中的hashcode
*方法计算该元素的哈希值,计算结束去寻找是否有该哈希值,如果没有,直接存如该元素到集合中。如果有,则调用该类型的
*eques方法比较内容,如果内容不相同,将该元素存入集合链表中,如果相同,则不存。。相同哈希值,则挂到最下面
构造方法
HashSet()
构造一个新的空 set,其底层 HashMap 实例的默认初始容量是 16,加载因子是 0.75。
HashSet(Collection<? extends E> c)
构造一个包含指定 collection 中的元素的新
set。
HashSet(int initialCapacity)
构造一个新的空 set,其底层 HashMap 实例具有指定的初始容量和默认的加载因子(0.75)。
HashSet(int initialCapacity, float loadFactor)
构造一个新的空 set,其底层 HashMap 实例具有指定的初始容量和指定的加载因子。
方法
boolean add(E e)
如果此 set 中尚未包含指定元素,则添加指定元素。
void clear()
从此 set 中移除所有元素。
** Object clone()
返回此 HashSet 实例的浅表副本:并没有复制这些元素本身。
boolean contains(Object o)
如果此 set 包含指定元素,则返回
true。
boolean isEmpty()**
如果此 set 不包含任何元素,则返回 true。
** Iterator iterator()
返回对此 set 中元素进行迭代的迭代器。
boolean remove(Object o)
如果指定元素存在于此 set 中,则将其移除。
int size()**
返回此 set 中的元素的数量(set 的容量)。
遍历(和list相似)
对 set 的遍历 迭代遍历: Set<String> set = new HashSet<String>(); Iterator<String> it = set.iterator(); while (it.hasNext()) { String str = it.next(); System.out.println(str); }
2.增强for
3.HashSet
public static void main(String[] args) {
Set<String> set =new HashSet<String>();
set.add("abc");
set.add("bcd");
set.add("abc");
for(String s:set) {
System.out.println(s);
}//结果bcd,abc
}
package com.oracle.Demo02; import java.util.HashSet; import java.util.Set; public class demo02 { public static void main(String[] args) { /*int s1="abc".hashCode(); int s2="abc".hashCode(); int s3="bcd".hashCode(); *,(哈希值存入数组,链表存元素) *当我们向集合 中存元素时,Add方法先去调用集合存储的类型的类中的hashcode *方法计算该元素的哈希值,计算结束去寻找是否有该哈希值,如果没有,直接存如该元素到集合中。如果有,则调用该类型的 *eques方法比较内容,如果内容不相同,将该元素存入集合链表中,如果相同,则不存。。相同哈希值,则挂到最下面 System.out.println(s1); System.out.println(s2); System.out.println(s3);*/ Set<Person> set =new HashSet<Person>(); set.add(new Person("a",10)); set.add(new Person("b",9)); set.add(new Person("a",8)); for( Person p:set) { System.out.println(p); } /* Person [name=熊二, age=28] Person [name=熊大, age=18] Person [name=熊大, age=18] 不重写hashcode,调用 重复元素 } }

