
四、fork/join框架
一、简介
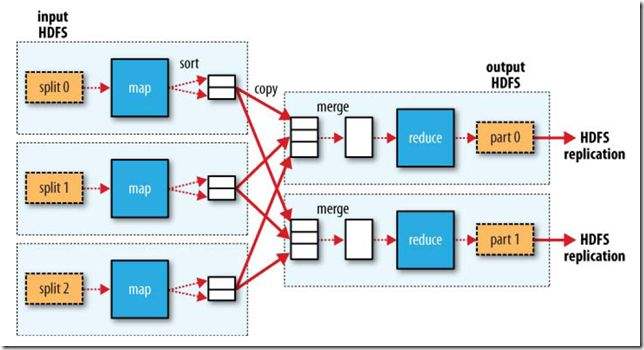
在hadoop的分布式计算框架MapReduce中,会经过两个过程Map过程和reduce过程。Map过程将任务并行计算,reduce汇总并行计算的结果,如图:
MapReduce是在分布式环境中做分布式计算的,JDK1.7+以后再单机环境中也可以做类似的操作,它提供了一种ForkJoin框架。
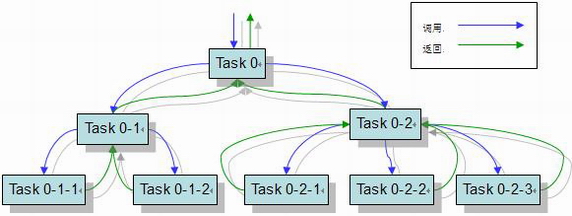
ForkJoin框架中,fork()操作将任务异步并行执行(类似生成一个Map操作),join()操作等待异步并行的结果,你可以将并行结果进行汇总(类似reduce操作),并通过Future等方式获取异步线程的执行结果,如图:
JDK文档:https://docs.oracle.com/javase/7/docs/api/java/util/concurrent/RecursiveTask.html
ForkJoin框架可以将一个任务通过不断地分解,并行地执行更多的任务。在这种方式下,你需要合理控制它的分解程度,因为你可能一次性爆发非常多的线程消耗大量的资源,会适得其反。
二、代码示例
以下代码示例对一个集合内的数据进行加法运算,我们将集合不断地拆分成两两加法,然后并行执行汇总结果。最后通过Future获取异步结果
这里我们采用继承RecursiveTask<T>的方式来编写实现类,因为我们需要返回值,其泛型即返回值。
如果你的任务不需要返回值,你可以继承RecursiveAction来实现。
import java.util.Arrays; import java.util.List; import java.util.concurrent.ExecutionException; import java.util.concurrent.ForkJoinPool; import java.util.concurrent.Future; import java.util.concurrent.RecursiveTask; public class ForkJoinDemo extends RecursiveTask<Integer> { private List<Integer> nums; public ForkJoinDemo(List<Integer> nums) { this.nums = nums; } @Override protected Integer compute() { // 如果只有一个数据,直接返回 if (nums.size() == 1) { return nums.get(0); // 如果两个数据,相加 } else if (nums.size() == 2) { return nums.get(0) + nums.get(1); // 否则拆分任务 } else { // 拆分成两个任务异步执行,并等待异步结果 int result1 = new ForkJoinDemo(nums.subList(0, nums.size()/2)).fork().join(); int result2 = new ForkJoinDemo(nums.subList(nums.size()/2, nums.size())).fork().join(); // 汇总结果 int total = result1 + result2; // 返回汇总结果 return total; } } public static void main(String[] args) throws ExecutionException, InterruptedException { // 数据准备 Integer[] nums = {1,2,3,4,5,6,7,8,9}; List<Integer> list = Arrays.asList(nums); // 初始化fork任务 ForkJoinDemo forkJoinDemo = new ForkJoinDemo(list); // 初始化线程池 ForkJoinPool pool = new ForkJoinPool(); // 提交任务 Future<Integer> future = pool.submit(forkJoinDemo); // 阻塞获取返回值 System.out.println(future.get()); } }
最后输出:
45
在实际应用场景中,最麻烦的地方可能会是在于如何对要处理的数据进行划分。以上示例中,我们可以对集合按照大小进行切分,但如果是字符串或者流等数据。你需要注意,如何划分,以及在划分过程中,不会让数据因为划分而导致部分或者全部失效

 浙公网安备 33010602011771号
浙公网安备 33010602011771号