七、spark核心数据集RDD
简介
spark RDD操作具体参考官网:http://spark.apache.org/docs/latest/rdd-programming-guide.html#overview
RDD全称叫做Resilient Distributed Datasets,直译为弹性分布式数据集,是spark中非常重要的概念。
首先RDD是一个数据的集合,这个数据集合被划分成了许多的数据分区,而这些分区被分布式地存储在不同的物理机器当中,如图:
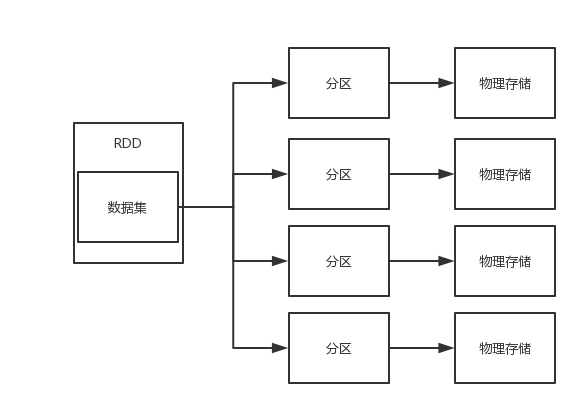
我们反过来想一下,RDD就是很多物理数据块的逻辑抽象。不仅如此,RDD还提供了一些列接口来操作这个逻辑抽象的数据集合。
我们把这些接口分成两大类:
1)transformation 转换
2)action 操作
transformation主要就是把一个RDD转换成另一个RDD,或者就是一开始把原始数据加载成为一个RDD;
注意:transformation并不会马上执行,只有等到action操作的时候才会执行。
action主要就是把一个RDD存储到硬盘,或者触发transformation的执行。
RDD转换和操作示例
我们先看一张图
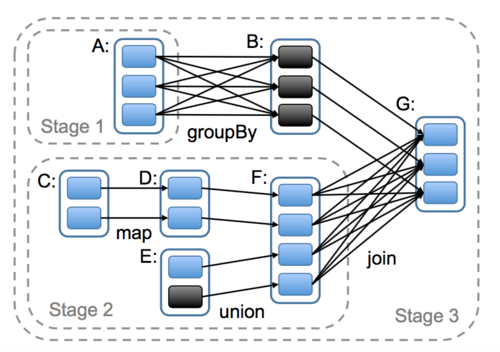
1)首先我们会从数据源中把数据加载成为RDD,也就是左边的RDDA和RDDC以及RDDE
2)RDDC经过map转换成为了RDDD
3)RDDE和RDDC经过union转换成为了RDDF
4)RDDA经过groupBy转换成为了RDDB
5)RDDB和RDDF经过join转换成为了RDDG
以上这些转换只是对整个过程进行一个描述,并没有立即执行,我们可以理解为对过程进行一个计划。直到我们调用一个saveAsSequenceFile持久化action操作的时候就会把上面的步骤催生出一个job,这个job根据是否shuffle(shuffle即宽依赖,下文提及)划分为了三个stage,并开始并行执行。
宽依赖和窄依赖
为了更加理解RDD,我们继续了解一下spark的核心原理
如图
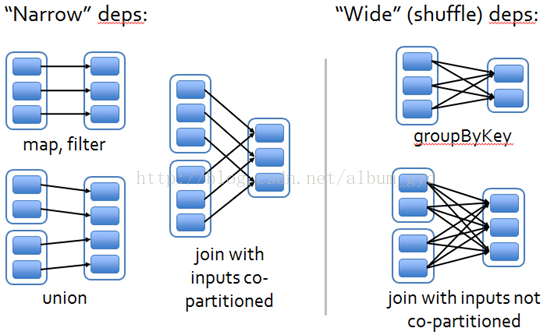
左边的部分是窄依赖,右边的部分是宽依赖即shuffle
上图的每一个蓝色块就是一个分区,而分区的集合就是一个RDD。同时RDD经过转换就会变成另一个RDD,那么也就会存在父子关系,由父RDD转换为子RDD。同时一个子RDD可能由多个父RDD转换而来。
那么,每个父RDD的分区都至多被一个子RDD的分区使用,即为OneToOneDependecies,我们就认为它是窄依赖;
而,每个父RDD的分区都被一个以上子RDD的分区使用,即为OneToManyDependecies,我们就认为它是宽依赖。
我们的程序代码被解析成dag有向无环图以后,DagScheduler根据是否shuffle宽依赖来划分stage,每一个shuffle之前都是一个stage。
这么做的理由是这样划分的话,每一个stage的task都可以独立并行计算,而TaskScheduler也不用去了解stage的存在只需要知道task即可,然后TaskScheduler把task分发给WorkNode节点的executor去执行。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号