Laxcus是Laxcus大数据实验室历时五年,全体系自主设计研发的国内首套大数据管理系统。能够支撑百万台级计算机节点,提供EB量级存储和计算能力,兼容SQL和关系数据库。最新的2.x版本已经实现对当前大数据主流技术和功能的完整覆盖和集成,并投入到国内多个超算项目中使用。Laxcus同时保持了使用和部署的极简性,这将使所有人都能很容易学习和掌握它。下面演示在一台Linux计算机上部署Laxcus demo系统的过程。根据我们的测试,这个部署过程大约需要三分钟,或者您熟悉Linux系统 ,也许不需要这个时间。关于Laxcus的介绍,详见产品论文:《Laxcus大数据管理系统》。
在实际部署前,请确定已经满足已下条件:
<1> 保证这台Linux计算机是处于独立且没有联网状态(因为配置默认使用自回路地址:127.0.0.1)。
<2> 用户能够以root身份登录Linux系统(Laxcus分布节点需要在root状态下工作)。
<3> 运行Laxcus需要Java环境支持,请首先安装一个JRE,Laxcus的最低版本要求是JRE1.6。
以下进入部署状态:
<1> 用户以root身份登录Linux计算机,然后打开一个终端窗口。
<2> 在根目录建立一个Laxcus目录,命令是:"mkdir laxcus"(注意是全小写,Linux对大小写敏感)。
<3> 将laxcus demo包从其它目录复制到这个目录下面。
<4> 将Laxcus demo包解压,命令是:“tar -xzf laxcus_demo_2.0.06_x32.tar.gz”,然后键入命令:"ls -ltr",可以看到它的下面分别出现了“top、home、log、aid、archive、data、work、call、build、watch、console、terminal”一系列目录及文件。见图1所示。

图1 Laxcus demo包(Linux 32位版本)
<5> 在“laxcus”目录下有一个"java.sh"文件,用vim或者其它文本编辑工具打开它,设置自己的JAVA_HOME目录(注意这里是大写)。图中是" JAVA_HOME=/home/jdk1.6.0_18"。然后键入“wq!”保存退出。见图2所示。

图2 修改JAVA_HOME目录
<6> 将“java.sh”文件复制到“/etc/profile.d”目录下,命令是:"cp java.sh /etc/profile.d/java.sh"。见图3所示。

图3 复制java.sh文件
<7> 在终端上键入命令:"echo $JAVA_HOME"查看,如果java.sh被启用,会显示JAVA_HOME目录的实际指向。如果没有,请重新启动计算机,再次以root身份登录查看。见图4所示。

图4 显示JAVA_HOME目录
<8> 将laxcus目录下面的全部".sh"后缀文件设为可执行,命令是:"chmod +x *.sh"。见图5所示。

图5 修改*.sh文件属性
<9> 进入“laxcus”目录下面的所有子目录,将这些目录下面的"bin"目录中的全部".sh"后缀文件设为可执行,命令同上。
<10> 以上操作完成后,键入命令:“cd /laxcus”回到laxcus目录,再键入命令:“./runbatch.sh”,laxcus节点将按命令顺序依次启动 。见图6所示。Laxcus已经在多地部署,为客户提供分布计算API接口,与用户合作开发了很多分布任务组件(基于Laxcus分布算法的中间件)。为保证软件运行过程中的安全,防止出现恶意破坏的情况,Laxcus提供了沙箱服务,对第三方发布、在Laxcus集群上运行的分布任务组件进行安全限制和检查。开启沙箱模式是在启动时,在“./runbatch.sh”后面加上“-sandbox”,这表示laxcus集群将在沙箱模式下运行。
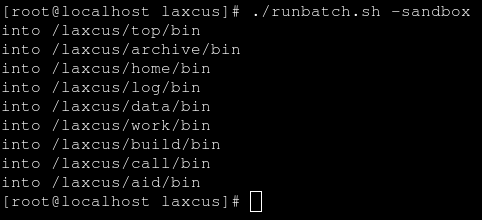
图6 以“沙箱”模式启动laxcus集群节点(分布任务组件被限制在沙箱中运行)
<10> 以上操作完成后,可以使用命令:"ps -ef | grep java" 查看,这里Laxcus各节点已经在Linux系统后台运行。
<11> 至此,Laxcus demo系统启动完毕。如果停止Laxcus集群节点,请回到laxcus根目录下键入命令:"./stopbatch.sh"。见图7所示。使用过程中如有任意问题和建议,请通过邮箱或者微博我们联系。联系邮箱:laxcus@163.com 或者微博:http://weibo.com/laxcus

图7 停止laxcus集群节点
Laxcus 图形终端/字符控制台
用户可以使用图形终端和字符控制台两种方式登录到Laxcus集群,通过在窗口中输入命令,来驱动集群工作。因为只是单机模式,laxcus demo集群的登录地址是:“localhost”,或者“127.0.0.1”,默认端口号是:5000(参数见conf/local.xml文件中配置)。系统管理员登录用户名是:“admin”,密码是:“laxcus”(密码区分大小写)。字符控制台启动命令是:“./console.sh”,图形终端启动命令是:“./terminal.sh”。见图8、图9、图10。进入登录状态后,键入"help"可以查看Laxcus支持的全部命令。 退出时,字符控制台使用"exit"或者"quit"命令退出,图形终端点击菜单或者关闭按纽退出。
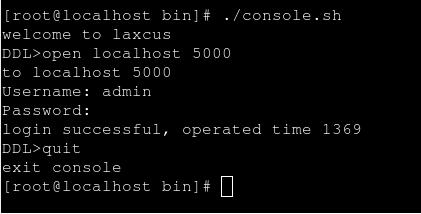
图8 字符控制台
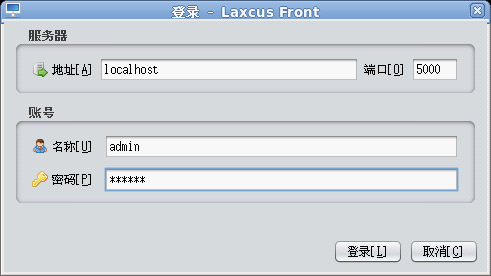
图9 图形终端登录窗口
图10 图形终端主操作界面
建立用户账号
Laxcus是多用户多集群的大数据管理系统,这意味着每个用户在操作数据前,必须拥有一个属于自己的账号。建立用户账号的过程由系统管理员来完成,并对这个账号的操作范围进行授权。在账号建立成功后,管理员将账号转交给用户,用户可以修改自己的账号密码,然后执行以后的数据操作,如建立数据库、建表、写入数据、查询等操作。这些操作和关系数据库的基本一致。在Laxcus demo系统里,已经内置了一个“demo”账号相关的分布计算服务。成功建立demo账号后,即可获得相关的业务操作能力。
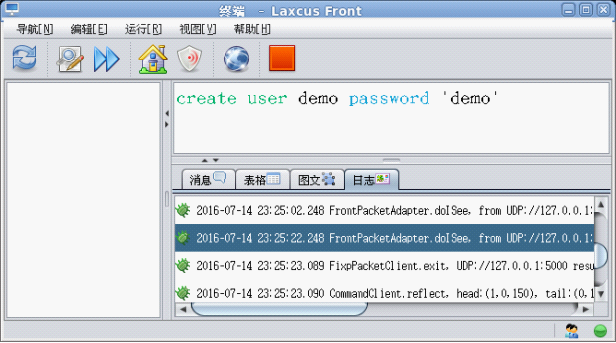
图11 系统管理员建立demo账号

图12 系统管理员对demo账号授权
demo用户操作
用户获得demo账号后,以“demo/demo”登录到localhost:7600。执行修改账号密码、建立数据库、建立数据表的操作。
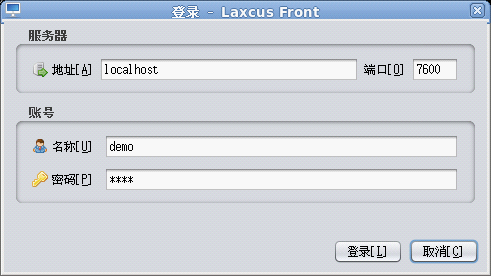
图13 demo用户登录到:localhost 7600 主机

图14 demo用户修改自己的登录密码

图15 建立数据库

图16 建立数据表
分布计算
Laxcus大数据管理系统的分布计算基于DIFFUSE/CONVERGE算法。关于算法和分布任务组件(中间件)的介绍详见《Laxcus大数据管理系统》一文,这里不再赘述。图11演示了一个在demo账号下,随机数的产生、排序、显示、保存的过程。
窗口文字解释:
<1>“conduct”,Laxcus系统命令,是diffuse/converge分布算法的语句化描述。
<2>“demo_sort”,分布计算的中间件命名(不区分大小写)。这个中间件已经集成在Laxcus demo系统中。
<3>“from、to、put”,conduct命令关键字,是diffuse/converge分布计算的阶段。
<4>“sites”,conduct命令关键字,要求的节点数目(节点是一台逻辑计算机)。
<5>“writeto”,conduct命令关键字,指示数据写入的磁盘文件。
<6> “begin、end、total、orderby”,自定义关键字,格式是“名称(数据类型)=参数”。这些关键字由用户定义,然后在自己的中间件中解析和处理。
命令说明:
这个命令遵循DIFFUSE/CONVERGE分布算法,通过操纵一个名为“demo_sort”的分布任务组件,由多个data节点产生随机数,然后把它们分散到多个work节点上,进行排序计算和输出的过程。在from阶段,要求系统启动6个data节点,每个节点平均分配2000(total)个数中的六分之一,产生从0到99999之间的随机数。to阶段要求3个work节点,它承接from阶段产生的数字,每个work节点平均分配2000(total)个数中的三分之一,并对分配到的数字进行排序,排序采用降序方式。数据结果在终端上显示,并写入一个名为"/tracking/rnd.bin"的本地文件中(Linux文件名,如果终端运行在Windows系统,需要改为对应的目录结构)。另:在demo_sort分布任务组件执行过程中,会对参数中要求的节点数进行检查,如果达不到指定要求,将自动降为实际可用数目。实际上,由于data、work节点达不到要求,demo_sort在执行过程中已经对此做了处理。
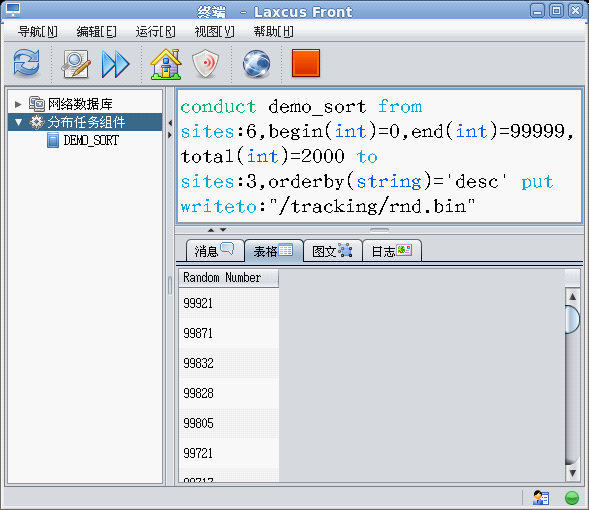
图17 conduct命令
SQL查询
Laxcus 2.x已经完全兼容SQL,包括SQL四个操纵语句:INSERT、DELETE、UPDATE、SELECT,以及对SQL函数、GROUP BY、ORDER BY、嵌套查询(Sub Select)、连接查询(Join)的支持。这些操作在内部都遵循Diffuse/Converge算法执行计算。在图形窗口上, 则与关系数据库表现完全一致。
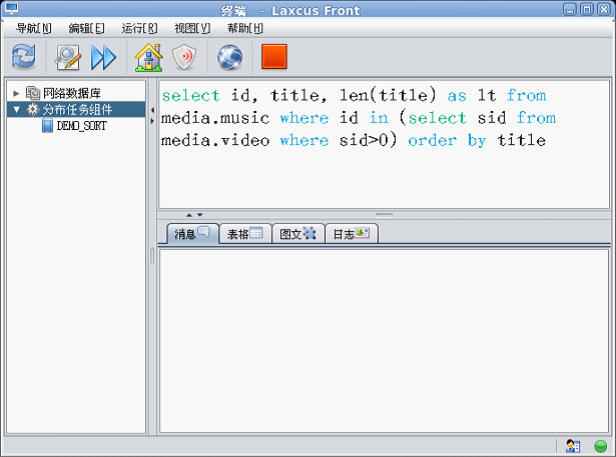
图18 嵌套查询(支持SQL函数)

图19 group by 、order by 查询(支持SQL函数)
数据构建
数据构造对各种数据再处理业务的综合。同分布计算一样,数据可以通过窗口命令进行。关于数据构建的详见介绍,还是请见《Laxcus大数据管理系统》一文。在laxcus 2.x版本中,系统提供了两个数据构建命令“regulate、modulate”,它们分别是对一个节点或者几个节点的数据,以及一个Laxcus集群的数据进行数据优化和重新整理。同分布计算一样,laxcus也提供了数据构建的API接口,帮助用户实现自己的数据构建业务。
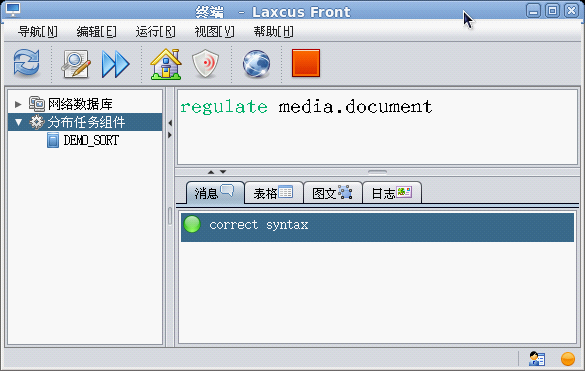
图20 regulate命令
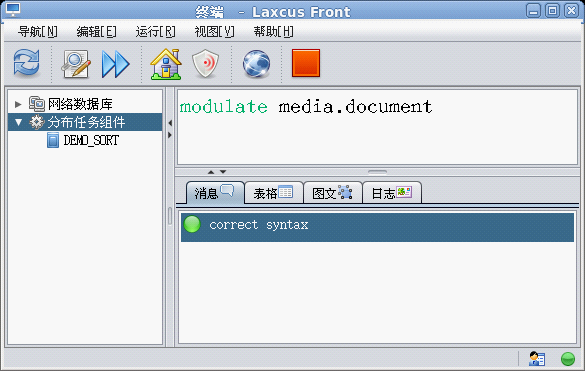
图21 modulate 命令
流式处理
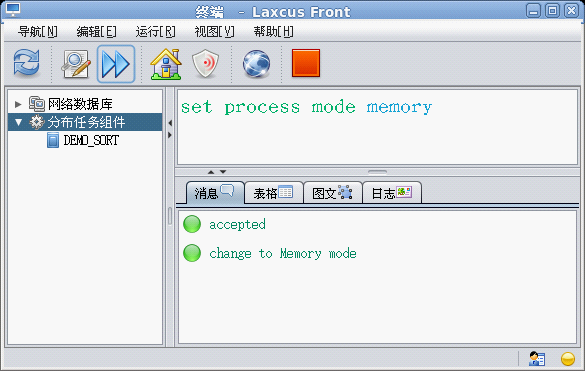
流式处理是laxcus 2.x版本一项新的功能。它将原来基于硬盘的数据处理过程,转移到内存上进行,能够获得了数十倍的效率提升。Laxcus流式处理很简单,只要在图形窗口上设置这个命令,以后所有的命令操作,都将默认为流式处理方式。反之,如果将命令改为“set process mode disk”, 以后的命令处理,都将是磁盘处理模式。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号