第七章 分布任务组件
Laxcus 2.0版本的分布任务组件,是在1.x版本的基础上,重新整合中间件和分布计算技术,按照新增加的功能,设计的一套新的、分布状态下运行的数据计算组件和数据构建组件,以及依此建立的新的运行框架、操作管理规范、API接口等。
新分布任务组件的改变主要体现在数据处理能力方面。经过重新调整后的运行架构,原来因为架构问题受到的诸多限制被全部取消,分布任务组件可以随着集群的不断扩充,同步提供无限制的数据处理能力。这足以满足我们当前以及未来相当长一段时间内,对各种大规模数据处理业务的需要。同时我们也把大量原来由集群管理员执行的管理工作给省略掉,交由系统来自主监管和执行,自动化管理能力因此大幅提高。
在Laxcus 2.0版本里,分布任务组件按照组件部署位置分为两种:内部组件和外部组件。内部组件在集群内部运行,执行大部分的分布处理工作;外部组件属于客户端组件,只在Front节点运行,根据用户需要反馈处理结果。
从程序员角度来说,新的分布任务组件是简单的,可以不必再去考虑与系统有关的各种操作,只要求调用几个API接口,就可以开发出符合要求的分布任务组件,这类似于一个本地的数据库开发过程,使很多有Java编程经验的人都可以掌握。
由于本文是介绍Laxcus大数据管理系统,编程部分不在其列,所以下述内容仍然循此惯例,介绍分布任务组件的相关概念和功能。希望通过介绍分布任务组件,使大家对Laxcus运行机理有进一步了解。
7.1 阶段命名
我们在第二章提到过“命名”的概念,它是对实体资源的抽象化表述。阶段命名是命名中的一种,它在命名的基础上,结合进分布数据处理中的“步骤”,加上用户签名引申而来,用于描述运行中的分布任务组件,当时所处的状态和位置。如图8.1所示,“step”用来说明当前分布组件的操作步骤,“root”是根命名,每个根命名必须全局唯一。判断根命名唯一性的工作可以联系系统管理员,或者直接让管理员提供。“sub”是子命名,用于迭代化的数据处理过程中。“issuer”是用户签名,是用户登录时输入的用户名称SHA1散列码,用于分布环境下的安全检查。
阶段命名是分布任务组件在Laxcus集群部署、运行时的唯一身份标识,数据计算和数据构建都要用到它。

图7.1 阶段命名参数
7.2. 数据计算和Conduct命令
数据计算组件在Diffuse/Converge算法基础上实现,在分布描述语言中的命令是Conduct。一个完整的数据计算组件由5个阶段组成,每个阶段是一个独立的子组件。数据计算各阶段的工作内容和处理范围,系统都做了明确的规定。Call节点处于中心位置,负责调配数据资源,和控制数据处理操作。
7.2.1 Init阶段
Init阶段是执行数据计算的初始化工作,按照Conduct命令中提供的参数和要求,为后续工作检查分布数据资源,调配运行参数。产生的计算结果,将成为后续数据计算的参考依据,被保存在Conduct命令中。Init阶段组件属于内部组件,指定部署到Call站点。
7.2.2 From阶段
From阶段对应Diffuse/Converge算法中的Diffuse。在这个阶段,将产生数据计算需要的原始数据。相对后续的To阶段组件,这些数据是它们的输入数据,对整个数据计算流程而言,属于中间数据。数据产生来源目前有三种:1. 使用SQL Select语句产生;2.根据自定义参数,按照用户解释规则生成;3. SQL Select语句和自定义参数结合产生。无论哪一种情况,这些原始数据最初都会保存在硬盘或者内存上(默认保存到硬盘,保存到内存需要程序员特别指定,同是视运行环境许可而定),然后产生数据位图返回给Call节点。数据位图是Laxcus系统的一种元数据,针对不同的需求有各种样式。为了规范化处理,目前已经定义了一个基础接口,各种应用可以在此基础上加入新的元素,实现用户自定义自解释。From阶段组件属于内部组件,指定部署到Data节点。
7.2.3 To阶段
To阶段对应Diffuse/Converge算法中的Converge。在这个阶段,将执行实际的计算工作。对应上述Converge介绍,To阶段是迭代的,要求发生最少一次,可以发生任意多次。如果是多次,分布描述语言中的子级To阶段语句要使用SubTo。对应SubTo,这个子命名在阶级集中也是唯一的。To阶段迭代次数是程序员指定,被写入到Conduct命令里面,由Call节点按照理解执行。To阶段最初用于计算的数据,来源于From阶段,以后是上一次的To阶段。To阶段迭代在Call节点控制下持续进行,直到最后完成,把数据计算结果输出给Call节点,如果没有完成,向Call节点返回数据位图。To阶段组件属于内部组件,指定部署到Work节点。
7.2.4 Balance阶段
Balance阶段存在于From/To/Subto阶段之间。它的工作是根据上个阶段返回的数据位图信息,为后续的To/Subto阶段调配分散在Data/Work节点上的数据资源,使每一个To/Subto任务尽可能获得相同的计算量,以尽可能相同的计算时间返回计算结果,达到节省总计算时间、提高计算效率的目的。对于数据位图,如果上个阶段是由系统生成,那么在Balance阶段,解释工作也由系统处理;如果是用户自定义规则生成,那么Balance阶段就就按照用户自定义规则来完成。Balance阶段组件属于内部组件,指定部署在Call节点。
7.2.5 Put阶段
Put阶段承接最后一次的To/Subto阶段计算工作,是对上述数据处理结果的最终输出。这些输出通常是以计算机屏幕和磁盘为目标,把数据存入磁盘,或者以文字、图形的方式显示在计算机屏幕上。Put阶段组件功能要求简单,属于外部组件,由用户部署在自己的Front站点上。
7.3 数据构建和Establish命令
数据构建组件在Scan/Sift算法基础上实现,对应分布描述语言命令Establish。一个完整的数据构建组件由7个阶段组成,和Conduct命令一样,每个阶段只处理一项规定工作,7个阶段衔接,形成一个完整的数据构建处理流程。数据构建是顺序执行的,不发生迭代现象,每个阶段的输出是下一个阶段的输入,或者引导下一个阶段输入方向。Call节点继续介于中心位置,负责调配数据构建的数据资源和监控数据处理流程。
7.3.1 Issue阶段
Issue阶段与Conduct.Init阶段有极大相似性,也是提供数据处理前的准备工作。这包括对Establish命令中的全部参数进行检查,为后续阶段检查和调配数据资源。如果指定的参数中存在错误,或者数据资源不满足要求,它将拒绝执行,并向用户返回错误报告。Issue阶段组件属于内部组件,指定部署在Call节点。
7.3.2 Scan阶段
Scan阶段执行数据扫描工作,它只发生在Data主节点,检查数据块的索引信息。因为只扫描数据块的索引,所以这个速度是非常快的。在Laxcus系统中,现在已经提供了一个标准化的Scan阶段组件接口,如果没有特殊需要,程序员只需要调用这个接口就可以了。如果有个性化需求时,也可以在这个接口基础进行再实现。Scan阶段工作完成后,会向Call节点返回一个数据位图,里面包含了下个阶段所需要的各种信息。Scan阶段组件属于内部组件,指定部署在Data节点。
7.3.3 Assign阶段
Assign阶段工作承接Scan阶段,它保存来自Data节点的数据位图,直到全部收集完成。然后判断已经在Issue阶段定义的、所有关联Build节点在当时的有效性,并依此对数据位图进行综合比较和重组,按照平均分配的原则,把调整过的数据位图发给它们。Assign阶段的工作和Conduct.Balance有部分相似之处,都要考虑下一阶段的数据平衡问题。Assign阶段组件属于内部组件,指定部署在Call节点。
7.3.4 Sift阶段
Sift阶段是数据构建最重要的部分,所有数据构建的实质性工作都在Sift阶段执行和完成,是数据构建的核心阶段。在实际应用中,因为数据构建有太多的差异性,所以系统提供的Sift阶段接口也是宽范的。系统负责完成的只有从Data主节点下载数据块一项工作,剩下的工作,程序员可以在安全许可范围内,在Sift接口里执行各种数据操作。当Sift阶段工作完成后,它将产生新的数据块,这些数据块将生成一个固定格式的数据位图,并返回给Call节点。Sift阶段组件属于内部组件,指定部署在Build节点。
7.3.5 Each阶段
Each阶段接受Sift阶段返回的数据位图,它按照数据位图中提供的信息,结合关联的Data主节点,确认它们的存在,然后把数据位图进行重组和调配,产生新的数据位图,并传递给所有要求的Data主节点。由此可见,Each阶段这样的操作,从处理方式来说,和Assign阶段基本一致,不同之处是,Assign阶段是把元数据分配给Build节点,Each阶段是把Build节点返回的元数据再分配返回给Data主节点。这可以理解为是Assign阶段的反向操作。Each阶段组件属于内部组件,指定部署在Call节点。
7.3.6 Rise阶段
Rise阶段工作承接Each阶段,它的工作内容就是按照Each提供的数据位图,找到指定的Build节点和数据块,进行下载。当下载完成后,这些数据块将被转发给关联的其它Data从节点。因为Rise阶段工作的内容是固定的,所以象Scan阶段一样,系统也提供了一个标准化接口,程序员只需要调用这个接口,把工作交给系统处理就可以了。Rise阶段完成后,仍将返回一个数据位图,数据位图可以交给系统默认设置或者用户自定义组织。Rise阶段组件属于内部组件,指定部署在Data主节点。
7.3.7 End阶段
End阶段承接Rise阶段,是数据构建的最后一个环节。它的工作内容也与Conduct.Put类似,是显示数据构建的最终处理结果。由于End输出的内容远比Conduct.Put简单和标准,只是一种提示信息,所以通常程序员不需要太多处理,交给系统的标准化接口输出即可。End阶段组件属于外部组件,指定部署在Front节点上。
7.4 打包
一个项目的编程工作完成后,接下来的工作就是打包。打包是把已经编译好的代码文件放在一个文件里。打包操作可以使用Java运行环境提供的jar命令,或者Eclipse集成的ant工具来完成,这个过程和一般的Java打包操作完全一样。不一样的是,Laxcus系统要求打包后的分布任务组件文件名后缀是“.dtc”,Task节点需要根据这个后缀名来判断分布任务组件。另外,在每个分布任务组件包里,必须提供一个"tasks.xml"文件。这是一个XML格式的配置文件,放在文件包根目录的"TASK-INF"目录下面。它指定了一个组件包中,所有需要提供给系统识别和处理的数据。Task节点将根据这个文件中提供的参数,把每个分布任务组件推送到它的关联节点下面。这是一个很重要的文件,其中的配置和格式,系统都有明确规定,不允许出现任何错误。
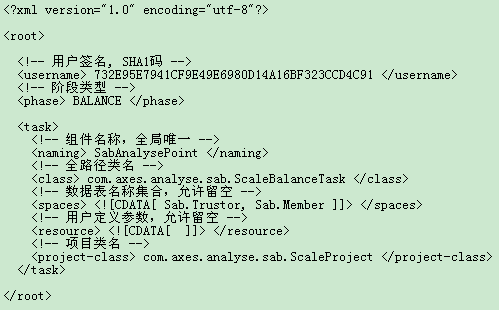
图7.4.1 tasks.xml配置文件

图7.4.2 分布任务组件目录
7.5 发布
打包工作完成后,接下来就要执行分布任务组件的发布工作。为了不影响集群正常运行,在将分布任务组件正式提交到集群之前,我们提供了一个测试环境,供程序员检查自己的分布任务组件。由于这是测试环境,通常不具备运营环境所拥有的各种资源(用户可以在测试环境里搭建),所以在这个测试环境里,主要是对分布任务组件的格式、配置、运行流程进行检查。当这些都确认正确后,就可以提交给集群了。
Laxcus大数据系统支持“热发布”,分布任务组件在进入集群的几分钟内,经过识别和处理,就可以生效。它首先会被投递到Task节点,Task节点将根据“tasks.xml”文件中提供的配置参数,对分布任务组件进行一系列的检查,在确认无误后,分发给关联节点。如果在检查过程中发现错误,Task节点将拒绝分发,并把分布任务组件和出现的错误推送给Watch节点,由管理员去联系用户。为避免热发布过程中发生版本冲突错误,用户在发布前和发布过程中,应该停止工作,等待新的发布操作完毕。
分布任务组件投递到Task节点的工作,有两种操作方式:一种是用户联系集群管理员,让他代为完成;另一种是用户通过一个Web发布接口,跳过集群管理员,让Web程序直接投递到Task节点下面。事实上,集群管理员也主要是使用这个Web接口来发布分布任务组件的。只是Web发布接口的管理权由集群管理员掌握,他是否愿意承接安全风险,开放这个接口,就由集群管理员来决定了。
7.6 分区
无论是数据计算还是数据构建,它们本质都是分布处理。都存在着在计算中间数据过程中,如何把一大块数据分割成多个小块数据的问题。按照数据的不同特性建立对应的分割规则,就是“分区”要做的工作。
分区一般首先按照后续的节点数目划分。这样当把一块数据分割后,后续每一个节点都能得到其中一小块数据。更多时候要考虑数据属性,按照数据属性进行分割。比如执行带order by、group by子句的select检索时,就要根据排列、分组的数据类型,把数据划到不同的类别中。另外一些个性化的分割要求,因为系统无法实现统一处理,就留出了API接口,让程序员去自主完成。
目前From/To、Scan阶段的分布任务组件都提供了默认的分割数据处理。
7.7 数据平衡
在分区基础上,如果让数据计算时间最短、计算效率最大化,还要进一步考虑平衡分布数据问题。
事实上,为了实现数据平衡处理,在分区时就已经准备了平衡处理参数。在执行过程中,数据计算的数据平衡工作由Balance阶段负责,数据构建的数据平衡工作由Each阶段负责。当不考虑计算机性能的时候,简单的数据平衡是按照数据长度处理,这个参数已经在数据位图中提供。理论上,相同内容和长度的两组数据,在两台相同硬件配置的计算机上,它们的执行时间是一样的。比较复杂的时候,就要考虑到数据类型和处理的内容,比如加减计算肯定比乘除要快,整数计算肯定比浮点数计算要快,多媒体的音频、视频数据肯定比文本数据计算密度大。与分区一样,更多复杂的、个性化的数据平衡计算也通过API接口的方式,交给程序员处理。
7.8 内存模式
分布任务组件在运行过程中,会产生大量的中间数据。在默认条件下,这些中间数据会被系统保存到硬盘上,并在使用结束后被系统释放。此前已经多次提过,由于磁盘的读写效率很低,系统对此做了很多优化处理。在分布任务组件这一环节,为了满足一些用户的快速数据处理要求,加速数据处理速度,提升处理效率,系统提供了一个接口选项,允许中间数据保存到内存里。这项功能要求用户在调用数据写入接口时显示指定,系统会根据当时的资源使用情况,有选择地分配。在实际使用时,这项功如果与数据存取中的“内存计算”结合使用,将会使数据处理完全跳过硬盘这道瓶颈,把数据处理变成一次纯粹的流式处理,并带来数十倍的效率提升。流式数据处理方案,是那些对时间有敏感性的数据业务迫切需要的。

图7.8 数据写入内存接口

 浙公网安备 33010602011771号
浙公网安备 33010602011771号