第五章 数据构建
在数据处理过程,我们经常会遇到这样的情况:大多数时候,用户最初输入的数据会含有大量无意义的、杂乱的信息,需要经过提炼、收集、汇总等一系列手段,才能产生有意义和用户可识别的数据内容;当数据长时间使用后,因为删除、更新操作的缘故,会在磁盘上产生大量数据碎片,这些数据碎片影响到正常的数据读写,为此需要做定时的数据整理工作,来保证一个高效的数据存取环境;有时候,出于便利和效率的需要,我们需要把多个表的不同字段组合到一起,形成一个宽表,来方便我们分析调用,或者能够清晰、直观地展示给客户;还有一些时候,我们需要按照某些特定的规则生成一些临时的、或者公共的数据,保存到磁盘上,来减少数据计算环节,加快数据计算速度。
如果仔细分析这些数据处理业务,可以发现它们都有一个共同的特点:重复执行概率强,不应该在数据计算时发生,最好提前提供数据准备。
基于这样的业务需求,我们提出了“数据构建”的概念,由它来统一完成这些工作。
在Laxcus 2.0版本,数据构建已经发展成一个独立的模块,有一套完整的实现方法和处理流程。因为它在Laxcus体系中的重要性,所以单独分出一章做介绍。
简单说明一下数据构建的特点:
1. 由一套API接口组成,需要程序员开发,被命令驱动。
2. 必须遵守这样一个基本准则:在既有数据基础上才能产生新的数据。
3. 与数据计算不一样的是,数据构建不直接向用户提供计算结果,只为提高数据计算效率而产生。
4. 在分类方面,数据构建属于ETL(Extract/Transform/Load)范畴,是数据计算的预处理措施和加速器,为数据计算提供快速处理通道。
5. 按照我们对数据构建的细化,它被分成两种操作:数据优化和数据重组。数据优化只执行数据清理工作;数据重组是对旧数据的再组织和再计算,并且衍生进化出新的数据。
5.1 数据优化
数据优化被设计成Laxcus系统的一个命令,用于整理磁盘上的数据碎片,删除其中的垃圾数据。命令可以是用户通过终端输入,也可以把命令保存到到Top站点上,由Top站点定期执行。由于Laxcus 2.0版本的事务加入,数据优化被定义为事务“写”操作,在执行过程中,全部数据块将处于“锁定”状态,不允许其它操作加入进来,直到全部完成被解锁。通常经过数据优化整理过的数据,它尺寸会更小,内聚更紧凑(这一点在列存储模型上尤其明显),有利于大批量的磁盘读写。数据优化只发生于Data主节点上,如前所述,每个数据块的执行时间大约是1.2秒左右。工作完成后,新的数据块会同步更新到备份节点上,替换旧的数据块。数据优化命令可以指定一个或者几个Data主节点,如果不指定,默认是集群上的全部Data主节点。鉴于数据优化过程中的“锁定”情况,建议把数据优化工作放在业务空闲时段,以减少因为数据锁定带来的负面影响。
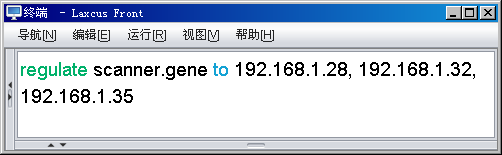
图5.1.1 数据优化命令
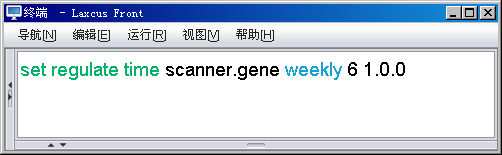
图5.1.2 定时优化命令(每周6凌晨1点开始)

图5.1.3 数据优化接口函数
5.2 数据重组
数据优化是由系统定义和执行的,只在一类节点上发生和并行执行,整理一个表的数据碎片。它的工作简单,执行速度快,存在时间短,是一种小规模的数据处理业务,对其它数据操作不构成太长时间的影响。数据重组则大不一样,根据我们的使用经验和跟踪调查,数据重组普遍会涉及到多个表、多种格式的数据计算和分析,数据量大,执行时间长,产生的数据量也大,而且结果也是多种多样,属于大规模的、复杂型数据处理工作。
鉴于这样的情况,系统无法做到对数据重组进行统一的处理,还有程序员任意编写数据重组代码可能导致的错误,以及希望减少用户工作量,规范处理流程等原因的考虑,我们针对数据重组设计了一套Scan/Sift算法,让用户按照规定流程和规定要求去参与数据重组工作,并以此起到简化编程工作、减少运行错误的作用,也希望能够达到提高处理效率和保证系统稳定性的目的。
另外,在我们内部,数据重组被称为“洗牌”,这也许可以更好地表达我们对“数据重组”的本来意思。
5.2.1 Scan/Sift算法
Scan/Sift是为大规模数据重组设计的算法,与Laxcus系统架构紧密结合,能够在多个子域集群中工作,具有操作多个表数据、产生任意组数据的能力。
同Diffuse/Converge算法一样,Scan/Sift算法的工作起点和输出点也是Call节点,Call节点在Scan/Sift算法中起协调和分配数据资源的作用,但是不去产生数据和重组数据。Scan被设计用来收集数据信息工作,它的作用点是Data主节点。主要是扫描磁盘上的数据索引,然后生成元数据,反馈给Call节点。Call节点汇总Scan收集来的元数据,在本地进行分析和调整后,分配给Build站点。Build节点执行Sift工作,它根据Call节点提供的信息,向Data主节点索取数据,然后放到本地磁盘上,通过各种手段重新组织后,产生新的数据,最后按照Call节点的要求,返回到指定的Data节点上。按照这样的流程走下来,就完成了一次Scan/Sift数据重组工作。
与Diffuse/Converge算法不一样的是,Sift不是迭代的,它在Call节点指挥下只是执行一次。实际上,Scan/Sift算法的大量工作都集中在Sift阶段。这个阶段的工作压力非常大,如果放在Data节点处理,会影响到Data节点的正常数据业务,所以需要把数据转移出来处理。这也是我们设计Scan/Sift算法和Build节点的主要原因之一。
如果不希望数据优化影响到Data主节点的工作,数据优化也可以按照数据重组的工作流程来处理,对此我们已经在分布描述语言中提供了标准化的操作语句。

图5.2.1 Scan/Sift处理流程
5.2.2 Marshal/Educe接口
所有数据重组的开始阶段(ETL Extract),都需要把数据从磁盘文件中提取出来,然后才能执行后续操作。根据我们的追踪调查,提取操作主要这样两种 方式:1.按照某种规则有选择地抓取;2.把全部数据输出再逐一排查或者分析。前者通过SQL select语句就可以做到,后一种我们实现了Marshal/Educe接口,来方便用户使用。
Marshal/Educe是把磁盘下一个表的数据全部排序和输出的过程,由三个函数组成。如图5.3.1所示,marshal负责把全部数据按照指定列进行排序,排序结果是生成一组镜像表,这是一种元数据,被保存在内存里。educe是在marshal之后的操作,它在镜像表的指引下,把数据从磁盘上抓取出来并输出。其中marshal只操作一次,educe可以任意多个。如果需要中途停止操作,就调用unmarshal函数,内存中的镜像表也将同步释放。
Marshal/Educe以“只读”方式进行,执行过程中不会修改磁盘上的数据内容,生成的镜像表数据量也很小,每个数据块只产生几十到几百字节的信息,所以它对系统性能影响不大,可以放心使用。

图5.2.2 Marshal/Educe接口函数

 浙公网安备 33010602011771号
浙公网安备 33010602011771号