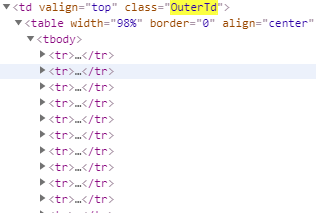
今天在抓取一个网站,我想抓取所有的tr,xpath配置完全正确,但是就是抓取不到数据
他的html结构是这样的,后来我就去问度娘,看到别人的解决方案是将tbody删除,因为这个是浏览器会对html文本进行一定的规范化
最后可以正确的抓取到了我想要的数据。
如果不能解决还望指正我的错处。