dubbo系列--集群容错
作为一个程序员,咱们在开发的时候不仅仅是完成某个功能,更要考虑其异常情况程序如何设计,比如说:dubbo的消费端调用服务方异常的情况,要不要处理?如何处理?
dubbo提供了多种集群容错机制,默认是failover,也就是失败后重试。可以自行扩展集群容错策略,参见:dubbo官网
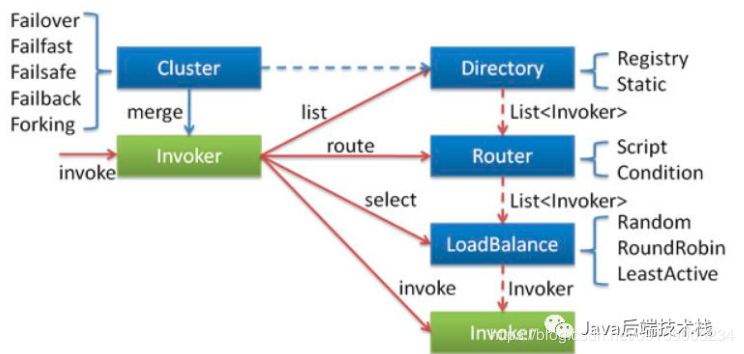
图中各节点关系:
这里的 Invoker 是 Provider 的一个可调用 Service 的抽象,Invoker 封装了 Provider 地址及 Service 接口信息
Directory 代表多个 Invoker,可以把它看成 List<Invoker> ,但与 List 不同的是,它的值可能是动态变化的,比如注册中心推送变更
Cluster 将 Directory 中的多个 Invoker 伪装成一个 Invoker,对上层透明,伪装过程包含了容错逻辑,调用失败后,重试另一个
Router 负责从多个 Invoker 中按路由规则选出子集,比如读写分离,应用隔离等
LoadBalance 负责从多个 Invoker 中选出具体的一个用于本次调用,选的过程包含了负载均衡算法,调用失败后,需要重选
先来了解一下dubbo提供的六种集群容错机制。
failover :失败自动切换,当出现失败,重试其他服务器,通常用于查询操作,但重试会带来更长的延迟,可以通过以下配置
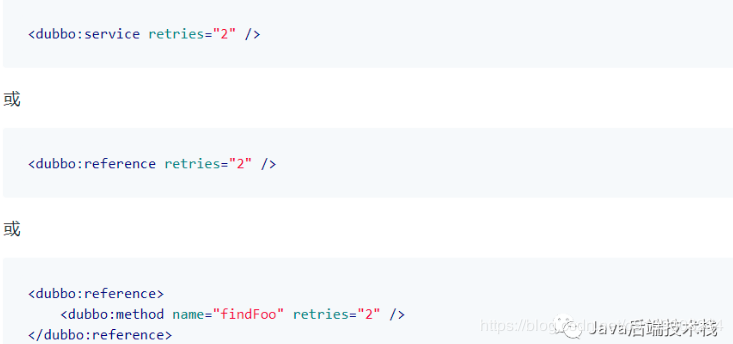
来设置重试次数,不包含第一次 ,调用次数=1+重试次数,通常用与读操作或者具有幂等的写操作
failfast :快速失败,只发起一次调用,失败就报错,通常用于新增记录的操作,通常用于非幂等性的写操作
failsafe :失败安全,出现异常直接忽略,也就是对数据的完整性要求不高,通常用于写入审计日志等操作
failback :失败自动恢复,失败后后台记录失败的请求,定时重发,通常用于实时性要求不高的通知类操作 ,通常用于消息通知操作
forking :并行调用,同时调用多个服务器,只要有一个返回成功即可,通常用于实时性要求高的查询操作,但是对资源的浪费更大,具体并行几个可以根据forks=n设置
broadcast :广播调用所有提供者,逐个调用,有一台报错就报错,通常用于更新所有提供者缓存或者日志等本地资源信息,用的机会较少,并且更新失败的话对系统影响很小的资源
集群模式配置
按照以下示例在服务提供方和消费方配置集群模式
<dubbo:service cluster="failsafe" />
或
<dubbo:reference cluster="failsafe" />
由于默认是failover,所以我们在这里分析一下dubbo源码中是怎么设计的。
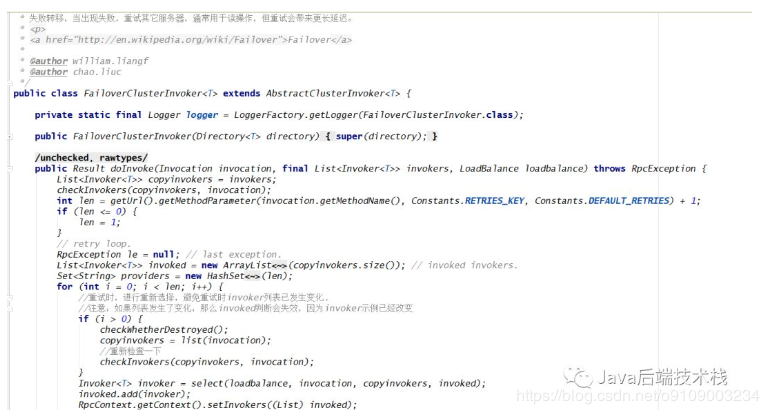
从 url 参数里面获取设置的重试次数,如果用户没有设置则取默认的值,默认是重试2,这里需要注意的是获取配置重试次数又+1了。这说明总共调用次数=重试次数+1(1是正常调用)。
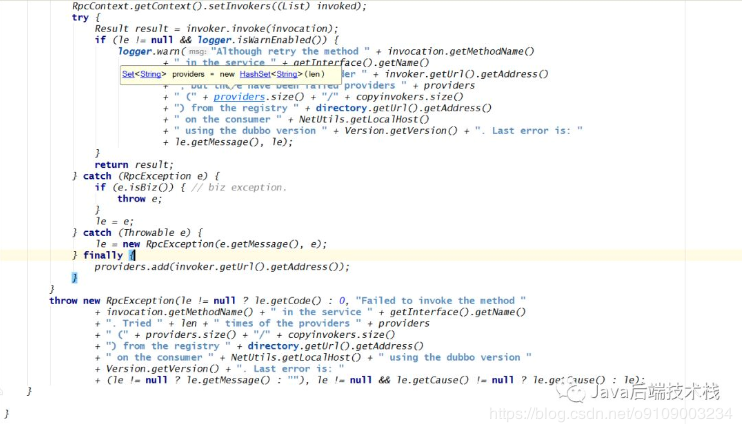
循环重试调用,如果第一次调用成功则直接跳出循环返回,否则循环重试。如果第一次调用出现异常,则会循环,这时候i=1,所以会检查是否有线程调用了当前 ReferenceConfig 的 destroy() 方法,销毁了当前消费者。如果当前消费者实例已经被消费,那么重试就没意义了,所以会抛出 RpcException 异常。
如果当前消费者实例没被销毁,则重新获取当前服务提供者列表,这是因为从第一次调开始到线程可能提供者列表已经变化了,获取列表后,然后又一次进行了校验。校验通过则选择负责均衡策略,根据负载均衡策略选择一个服务提供者,再次尝试调用。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号