最近《妇联4·终局之战》火爆全球,此部电影最早的首映是在...没有错就是我们的大中国,中国大陆首次早于北美,成为全球最早上映的国家地区之一。这一次,终于轮到我们给外国网友剧透了。因此我国还吸引了不少的国外漫威迷到中国来看首映,可想而知,这部电影是有多么的震撼!!!
妇联4的讨论热区莫过于我们的B站了并且观看前必不可少的就是回顾我们大漫威电影的剧情了,点开其全站榜,排行第一的就是我们的妇联444444!此处附上此视频链接(没去看的宝贝可以进行剧情回顾哇):https://www.bilibili.com/video/av49842011/
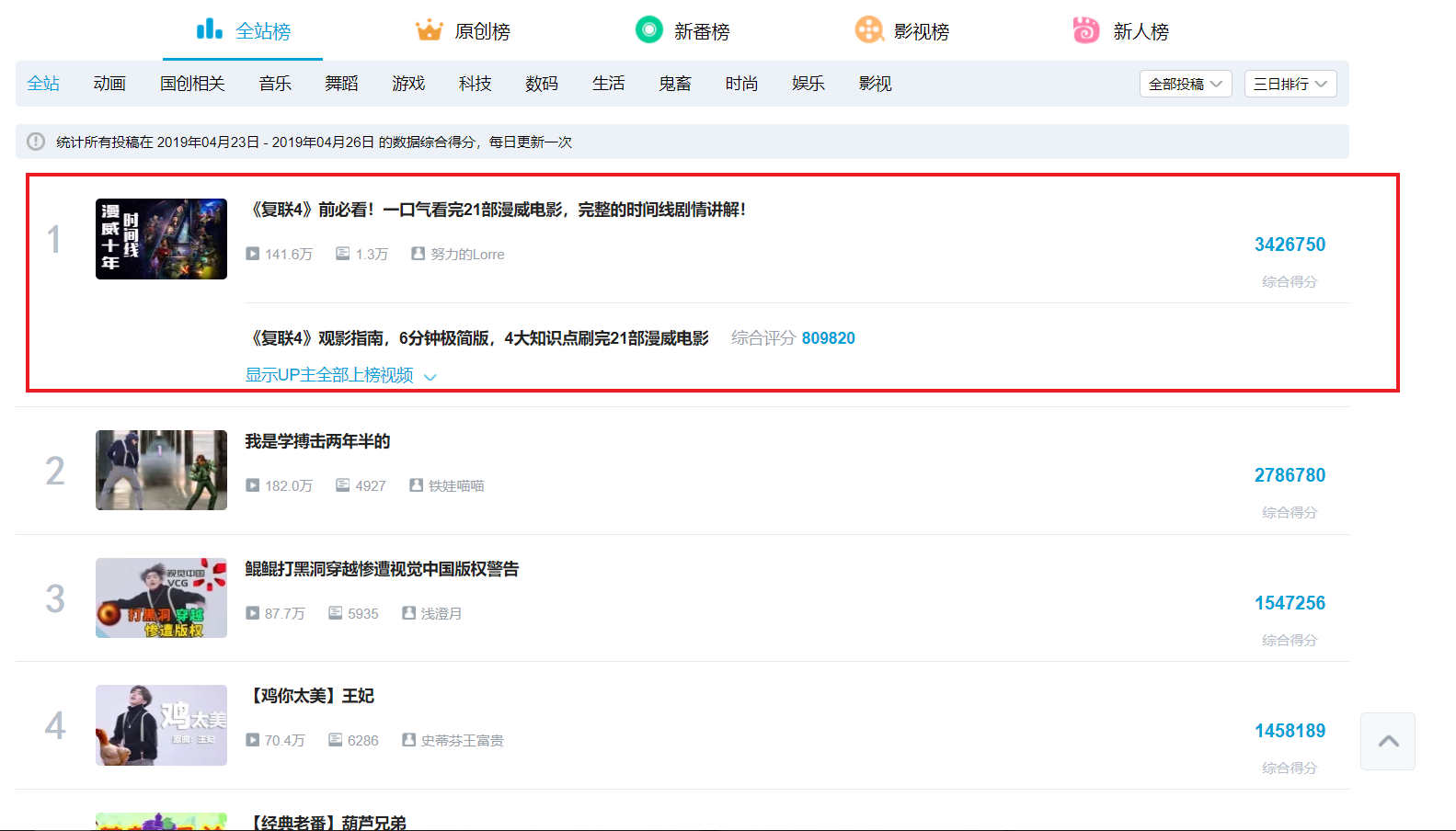
点击B站的影视专栏,更是10个视频9个都是谈论妇联4的,这热度谁顶得住啊~
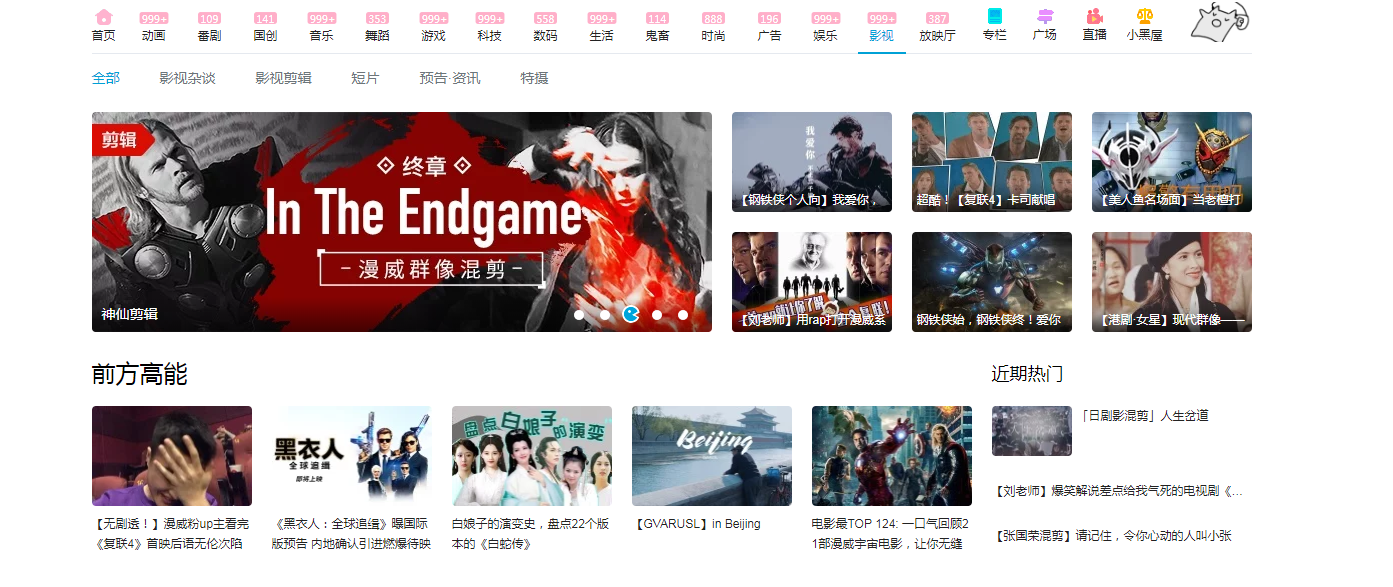
其中在漫威电影中,小编最喜欢的是钢铁侠,因此我们在b站中挑选了一篇与钢铁侠有关的视频进行爬取,得出网友们对钢铁侠的看法。具体操作如下:
- 找一篇与钢铁侠有关的视频:
【钢铁侠混剪】 爱你3000遍,漫威11年回忆杀 始于钢铁侠,终于钢铁侠, 你不需要很多人理解你https://www.bilibili.com/video/av50410947/?spm_id_from=333.788.videocard.8
- 抓取数据详细步骤
滑至评论区后可以看到评论总共有65页,因此爬取评论时,设置range(0,64)为循环爬取条件;使用f12打开开发者工具,可以看到一页总共有20条评论数据
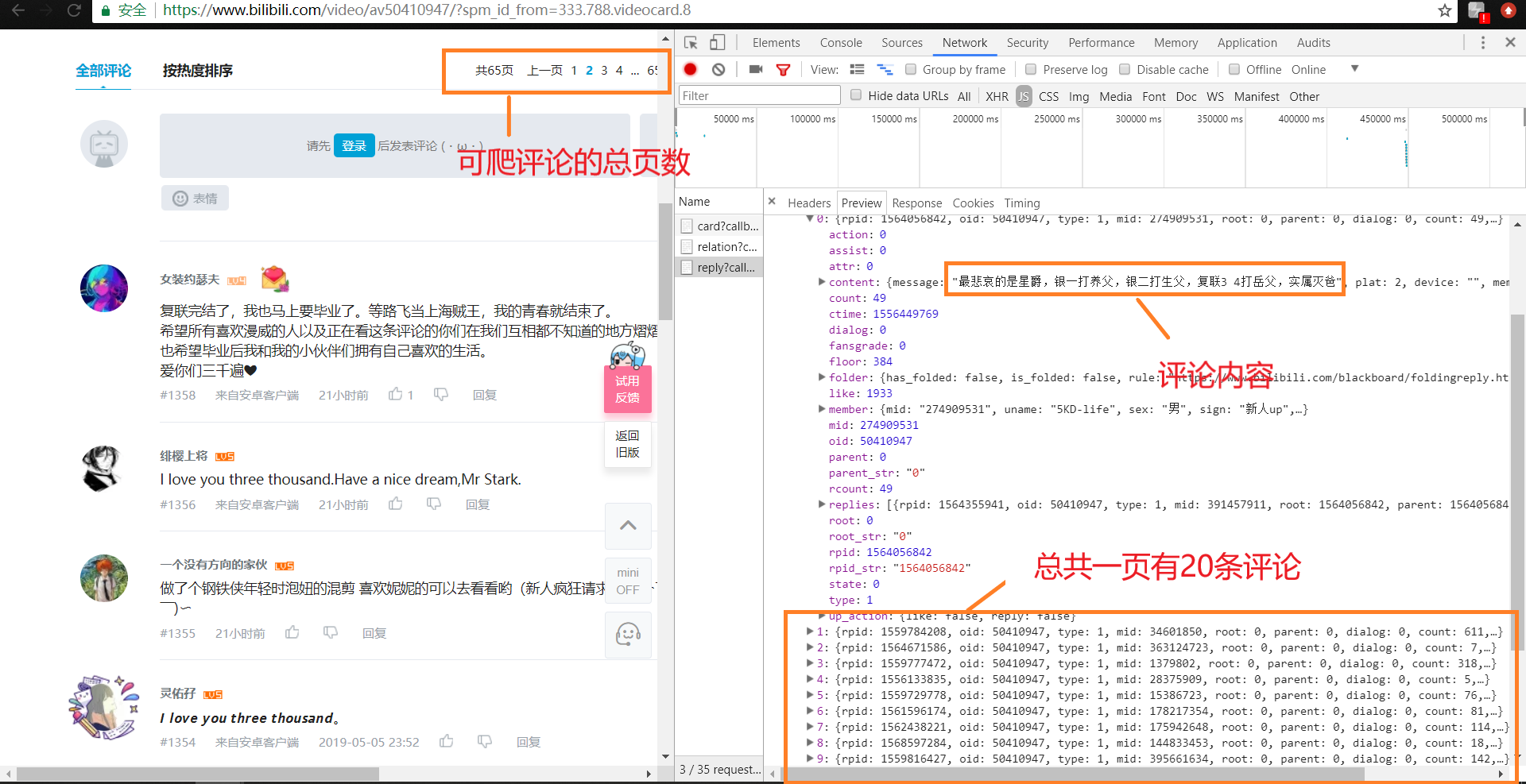
当翻页时,评论区将局部刷新,可以从Headers中得到服务器响应的url,分析url,得出评论页是根据pn而变化的,因此在爬取时设pn为未知,随着循环在每次循环时存入新的链接抓取数据,同时根据type,oid,sort得到对应的页面
for page in range(0,64):# 爬取评论总页数为65 url = 'https://api.bilibili.com/x/v2/reply?type=1&oid=50410947&sort=0&_=1557108277117&pn=' + str(page)
发送请求,抓取网页内容时注意需要设置合理的user-agent,模拟成真是的浏览器去抓取内容(一开始只设置了一个user-agent,被B站 BAN IP了,贼心累😭),同时要进行异常的处理哦~
def getURL(url): user_agent = [ 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.168 Safari/537.36', 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.835.163 Safari/535.1', 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0', 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50', 'Opera/9.80 (Windows NT 6.1; U; zh-cn) Presto/2.9.168 Version/11.50', 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; InfoPath.3)', 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; GTB7.0)', 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)', 'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1)', 'Mozilla/5.0 (Windows; U; Windows NT 6.1; ) AppleWebKit/534.12 (KHTML, like Gecko) Maxthon/3.0 Safari/534.12', 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; InfoPath.3; .NET4.0C; .NET4.0E)', 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; InfoPath.3; .NET4.0C; .NET4.0E; SE 2.X MetaSr 1.0)', 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.3 (KHTML, like Gecko) Chrome/6.0.472.33 Safari/534.3 SE 2.X MetaSr 1.0', 'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; InfoPath.3; .NET4.0C; .NET4.0E)', 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/13.0.782.41 Safari/535.1 QQBrowser/6.9.11079.201', 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; InfoPath.3; .NET4.0C; .NET4.0E) QQBrowser/6.9.11079.201', 'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0)', 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.80 Safari/537.36', 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:34.0) Gecko/20100101 Firefox/34.0' ] thisua = random.choice(user_agent) headers = {'user-agent': thisua} try: r = requests.get(url, headers=headers) # 发送请求,获取某个网页 r.raise_for_status() # 如果发送了一个错误请求(客户端错误或者服务器错误响应),可以通过r.raise_for_status()来抛出异常 print(r.url) return r.text except requests.HTTPError as e: # 如果HTTP请求返回了不成功的状态码,r.raise_for_status()会抛出一个 HTTPError异常 print(e) print("HTTPError") except requests.RequestException as e: print(e) except: print("Unknown Error !")
💗 重头戏到了!!!→获取评论数据
根据fetchUrl()函数抓取到网页内容后,我们要做的就是对得到的数据进行分析,从而得到我们需要的评论数据,从下图中我们可以知道我们需要的数据在什么地方后我们才能将对我们有用的信息进行提取。
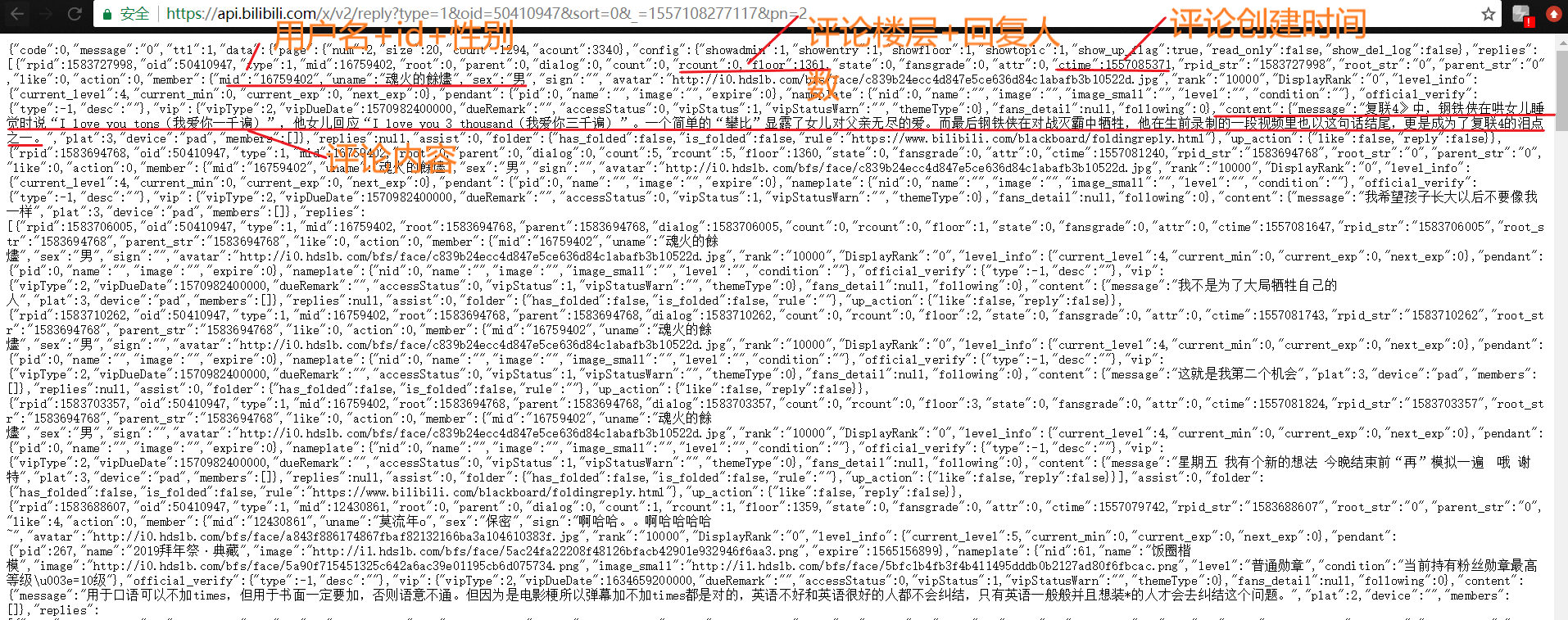
获取评论数据的详细代码如下:
# 功能:获取评论内容 def getComment(html): try: s = json.loads(html) # json.load()主要用来读写json文件函数:json.loads函数的使用,将字符串转化为字典 except: print('error') commentlist = [] for i in range(20): # 每页只有20条评论,循环20次 comment = s['data']['replies'][i] alist = [] floor = comment['floor'] ids = comment['member']['mid'] username = comment['member']['uname'] ctime = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(comment['ctime'])) content = comment['content']['message'] likes = comment['like'] rcounts = comment['rcount'] alist.append(floor) alist.append(username) alist.append(ctime) alist.append(content) alist.append(likes) alist.append(rcounts) commentlist.append(alist)
💗 获取用户个人信息
在网页中使用鼠标触摸用户头像时会出现一张小卡片,打开开发者工具,我们可以从中得到用户的一些信息,如性别,生日,所在地区等等。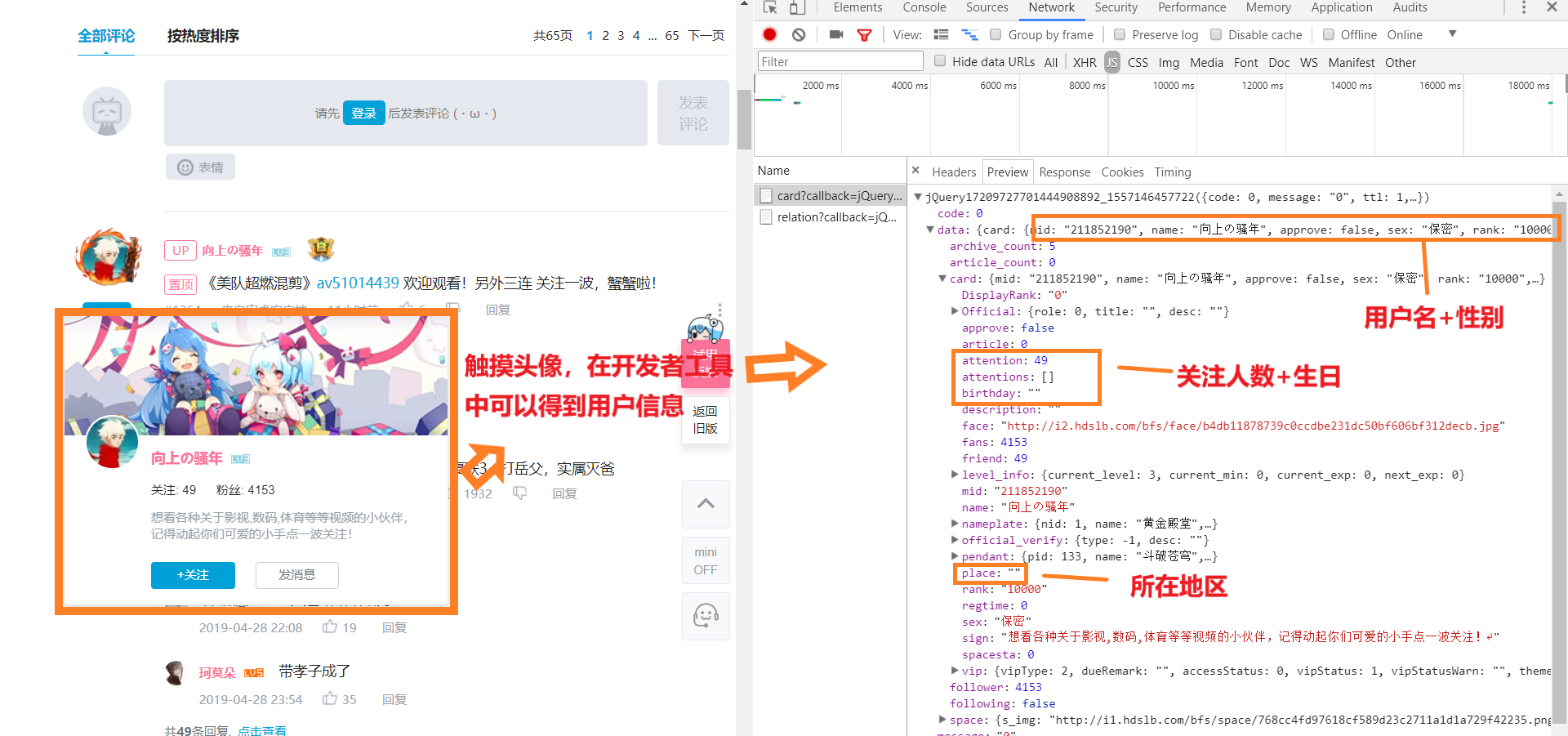
打开Headers,分析服务器响应的url,可以知道如果我们需要获取用户数据,那么我们就需要得到它的mid,根据mid再次去抓取网页的内容,然后分析数据得到我们需要的数据。
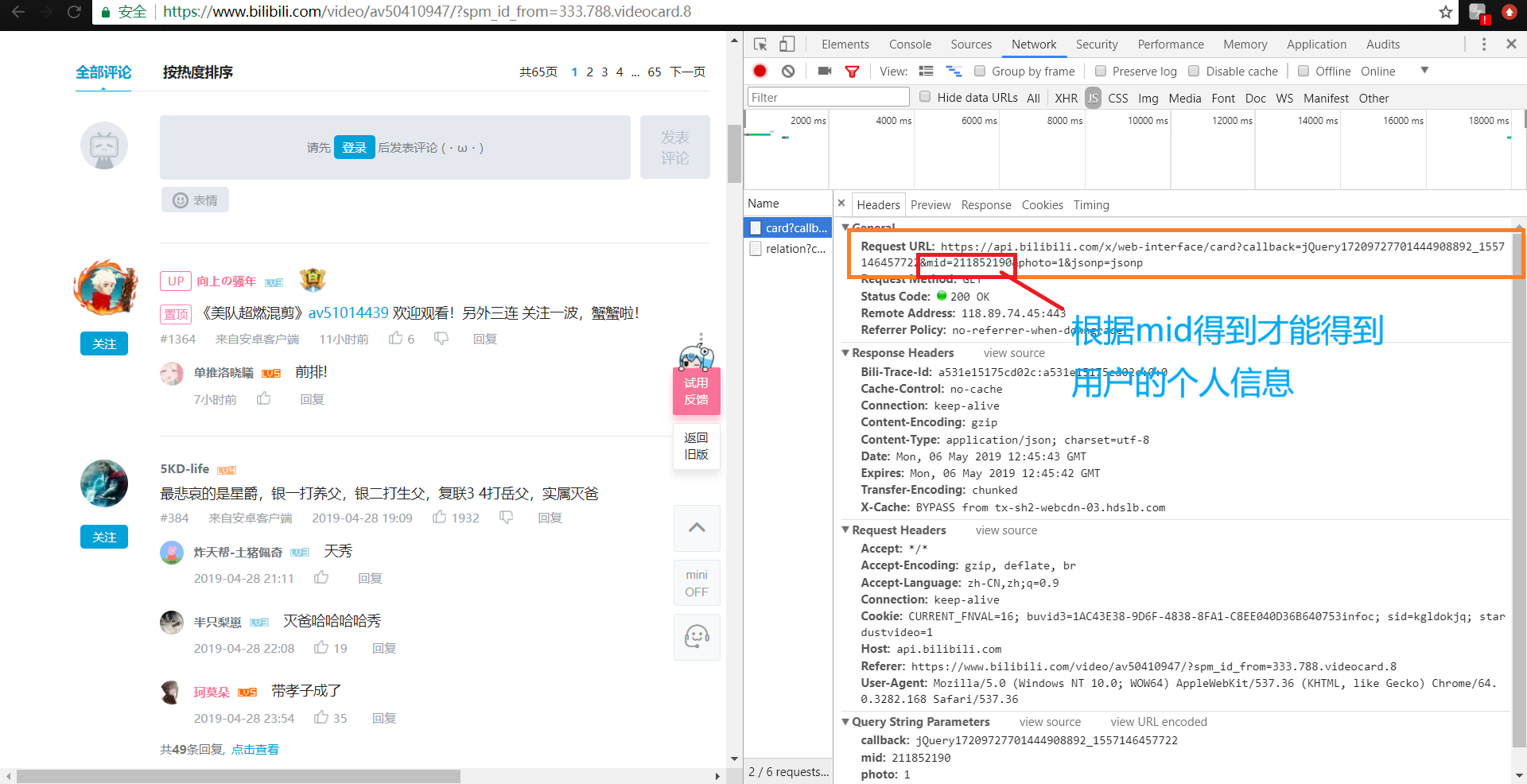
而mid我们需要从评论数据中获取,获取后直接调用函数进行获取用户个人数据。获取个人信息详细代码如下:
url1 = 'https://api.bilibili.com/x/web-interface/card?photo=1&jsonp=jsonp&mid=' + str(ids) #ids从评论数据mid中直接获取 html1 = getURL(url1) getPeasonal(html1)
def getPeasonal(html): try: s = json.loads(html) # json.load()主要用来读写json文件函数:json.loads函数的使用,将字符串转化为字典 except: print('error') pesonalList = [] comment = s['data'] blist = [] name = comment['card']['name'] sex = comment['card']['sex'] birthday = comment['card']['birthday'] city = comment['card']['place'] attentions = comment['card']['attention'] fans = comment['card']['fans'] friends = comment['card']['friend'] blist.append(name) blist.append(sex) blist.append(birthday) blist.append(city) blist.append(attentions) blist.append(fans) blist.append(friends) pesonalList.append(blist) writePeasonalPage(pesonalList)
还有很重要的一步是将数据写入到数据库以及生成csv文件便于在后面的可视化操作中可以直接操作数据:
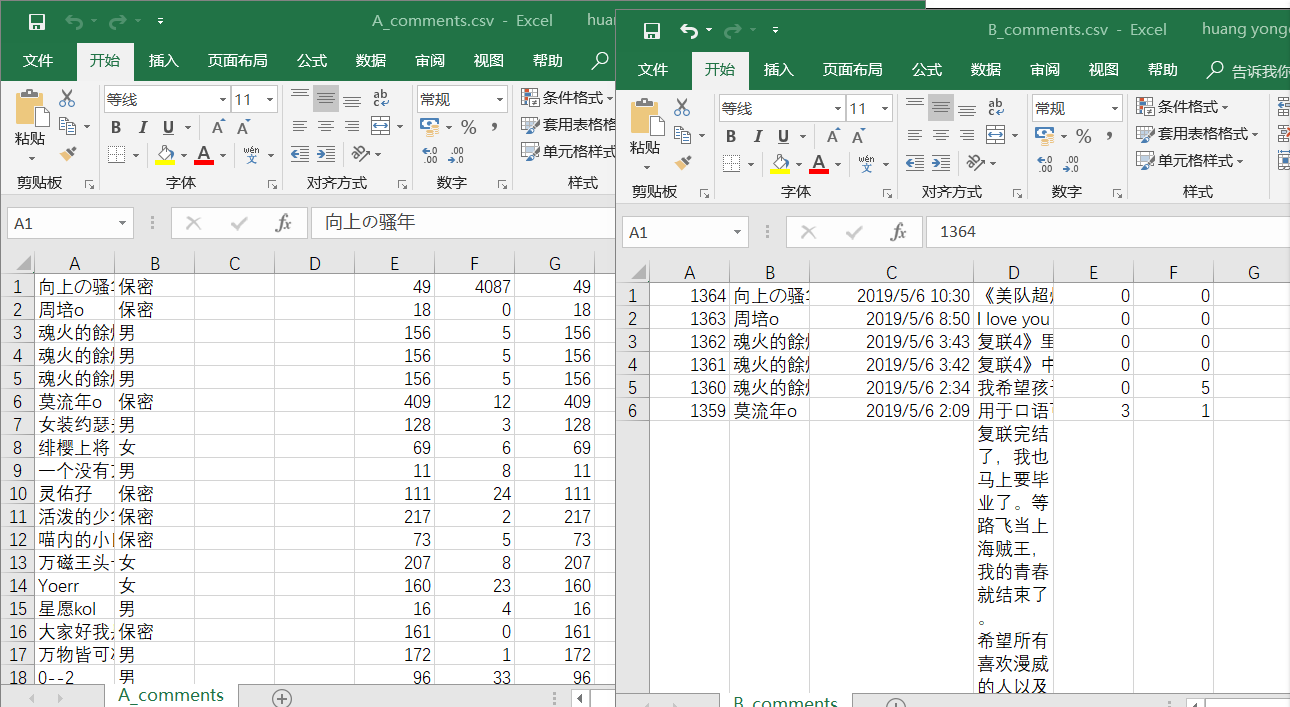
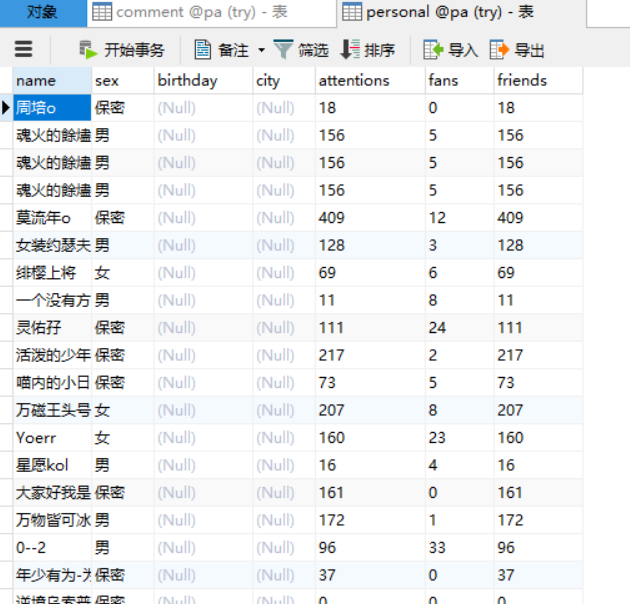
下面为评论内容写入数据库以及csv,(将个人信息写入为同理):
# 功能:写入评论内容至csv以及数据库 def writeCommentPage(urating): # Pandas读取本地CSV文件并设置Dataframe(数据格式),将爬取数据保存到本地CSV文件。加上mode='a' 追加写入数据;sep=','表示数据间使用逗号作为分隔符;不保存列名和行索引 dataframe = pd.DataFrame(urating) dataframe.to_csv('B_comments.csv', mode='a', index=False, sep=',',encoding='utf-8-sig', header=False) # 将爬取数据保存到数据库中 conInfo = "mysql+pymysql://user:passwd@localhost:port/pa?charset=utf8" engine = create_engine(conInfo, encoding='utf-8') df = pd.DataFrame(urating) df.to_sql(name='pa', con=engine, if_exists='append', index=False) pymysql.connect(host='localhost', port=3306, user='root', passwd='497497', db='pa', charset='utf8')
设置合理的抓取时间:
if page % 5 == 0: time.sleep(random.random() * 5)
💫因为在B站中获取用户个人信息时,其地区获取皆为空。因此,小编在豆瓣中进行了用户地区的抓取统计,使用可视化分析得出观看《妇联4》的观众集中在哪些地方。
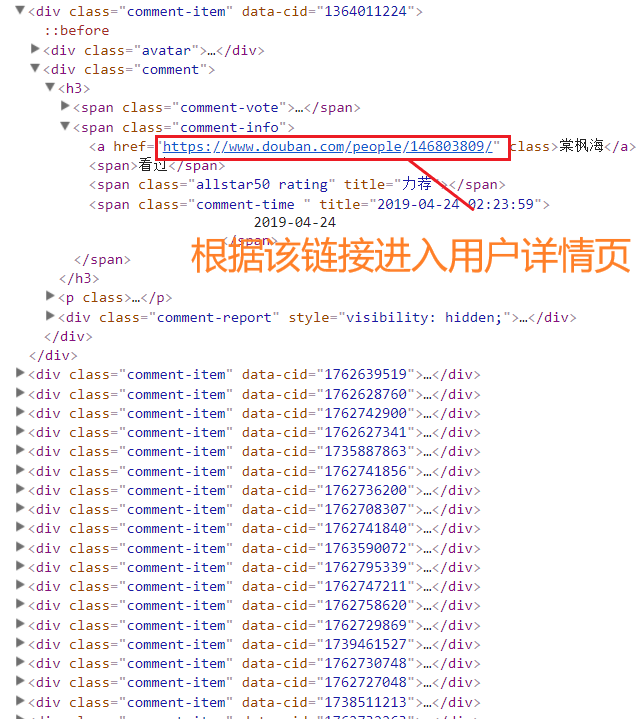
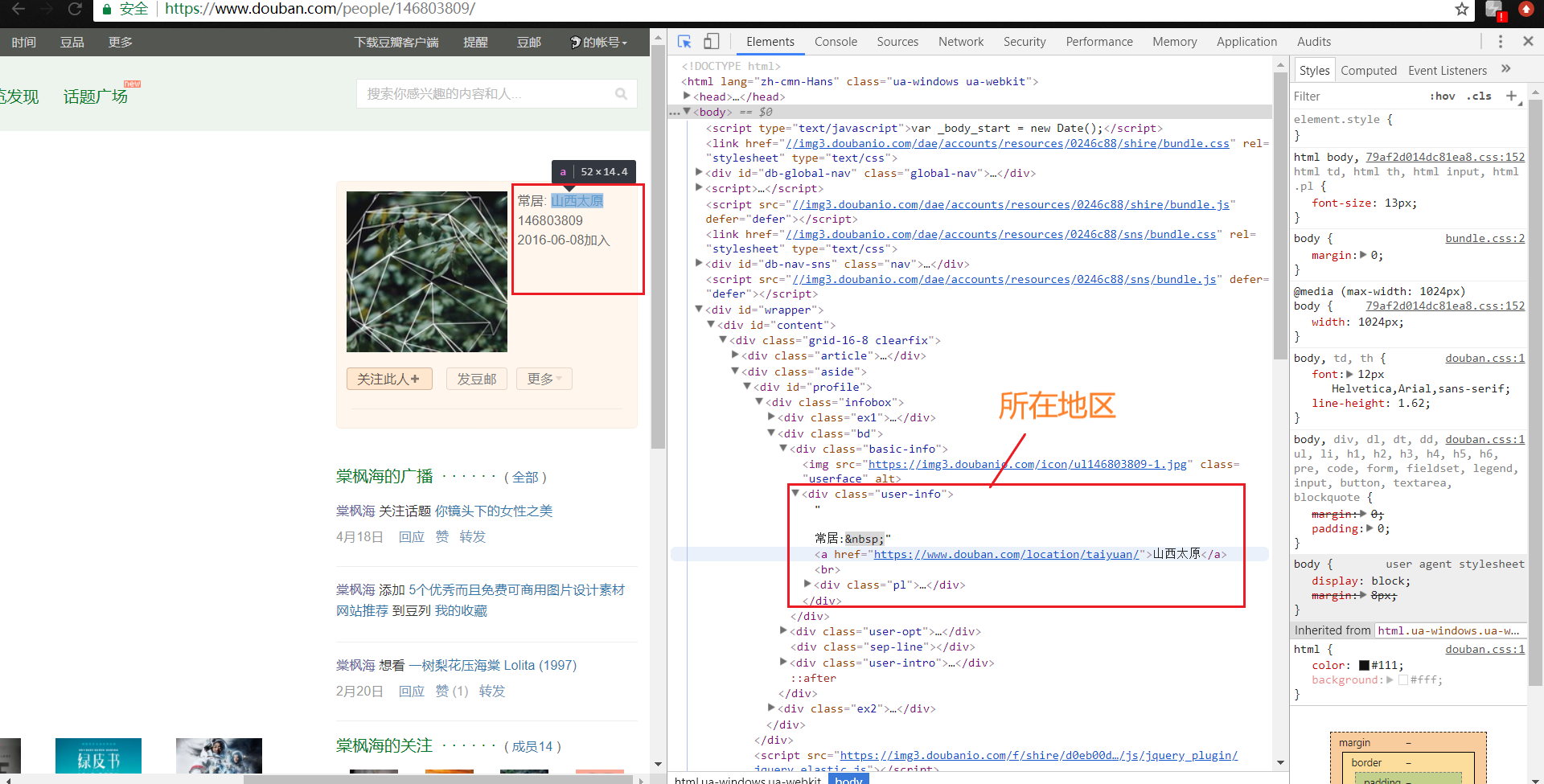
详细代码如下:
import requests import json import random import pymysql import pandas as pd from sqlalchemy import create_engine import time from bs4 import BeautifulSoup # 功能:访问 url 的网页,获取网页内容并返回 def getURL(url): user_agent = [ 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6', 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.168 Safari/537.36', 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.835.163 Safari/535.1', 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0', 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50', 'Opera/9.80 (Windows NT 6.1; U; zh-cn) Presto/2.9.168 Version/11.50', 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; InfoPath.3)', 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; GTB7.0)', 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)', 'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1)', 'Mozilla/5.0 (Windows; U; Windows NT 6.1; ) AppleWebKit/534.12 (KHTML, like Gecko) Maxthon/3.0 Safari/534.12', 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; InfoPath.3; .NET4.0C; .NET4.0E)', 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; InfoPath.3; .NET4.0C; .NET4.0E; SE 2.X MetaSr 1.0)', 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.3 (KHTML, like Gecko) Chrome/6.0.472.33 Safari/534.3 SE 2.X MetaSr 1.0', 'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; InfoPath.3; .NET4.0C; .NET4.0E)', 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/13.0.782.41 Safari/535.1 QQBrowser/6.9.11079.201', 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; InfoPath.3; .NET4.0C; .NET4.0E) QQBrowser/6.9.11079.201', 'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0)', 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.80 Safari/537.36', 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:34.0) Gecko/20100101 Firefox/34.0' ] thisua = random.choice(user_agent) headers = {'user-agent': thisua} try: r = requests.get(url, headers=headers) # 发送请求,获取某个网页 r.encoding='utf-8' soup = BeautifulSoup(r.text,'html.parser') r.raise_for_status() # 如果发送了一个错误请求(客户端错误或者服务器错误响应),可以通过r.raise_for_status()来抛出异常 print(r.url) return soup except requests.HTTPError as e: # 如果HTTP请求返回了不成功的状态码,r.raise_for_status()会抛出一个 HTTPError异常 print(e) print("HTTPError") except requests.RequestException as e: print(e) except: print("Unknown Error !") def getLink(soup): for user in soup.select('.comment-item'): print(user) avatar = user.select('.avatar > a')[0]['href'] # 抓取用户主页的链接数据 s = getURL(avatar) # 发送请求,抓取网页 if s!=None: # 当抓取网页数据成功时才进行抓取用户所在城市的数据 getCity(s) def getCity(s): clist = [] for city in s.select('.user-info'): citys = city.select('.user-info > a') try: # 当抓取信息list超过index时抛出异常 a = ",".join('%s' %id for id in citys) #将list中的信息转换为字符串 # 分割出地区 b = a.split(">")[1] c = b.split("<")[0] # 将地区加入列表中 clist.append(c) writeCity(clist) except: continue if __name__ == '__main__': i=0 while i<220: url = 'https://movie.douban.com/subject/26100958/comments?limit=20&sort=new_score&status=P&start=' + str(i) i=i+20 soup = getURL(url) if soup!=None: # 当抓取页面不为none时才进行抓取用户主页链接 getLink(soup) if i % 5 == 0: time.sleep(random.random() * 5
- 数据可视化
- 用户评论本番的时间大多在4月28日,而妇联4于24日上映,也就是说4月28日是B站用户大多数都观看完毕,并对钢铁侠有着喜爱之情。
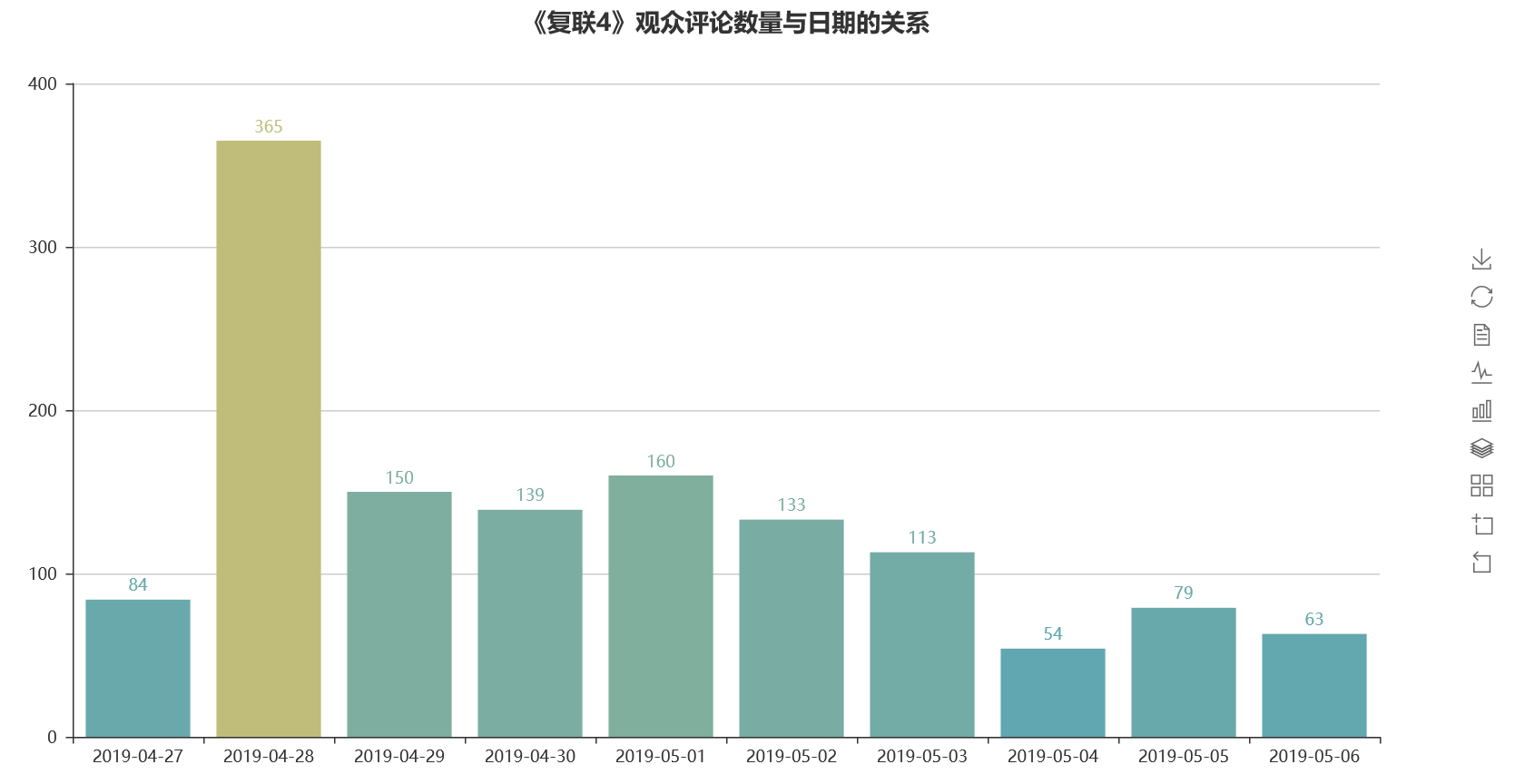
详细代码:
import matplotlib.pyplot as plt from wordcloud import WordCloud from collections import Counter from pyecharts import Bar import time import pandas as pd def read_csv(filename, titles): comments = pd.read_csv(filename, names = titles, low_memory = False) return comments def draw_data_bar(comments): time1 = comments['ctime'] time_data = [] for t in time1: if pd.isnull(t) == False and 'ctime' not in t: #如果元素不为空 date1 = t.replace('/', '-') date2 = date1.split(' ')[0] current_time_tuple = time.strptime(date2, '%Y-%m-%d') #把时间字符串转化为时间类型 date = time.strftime('%Y-%m-%d', current_time_tuple) #把时间类型数据转化为字符串类型 time_data.append(date) data = Counter(time_data).most_common() #data形式[('2019/2/10', 44094), ('2019/2/9', 43680)] data = sorted(data, key=lambda data : data[0]) #data1变量相当于('2019/2/10', 44094)各个元组 itemgetter(0) bar =Bar('《复联4》观众评论数量与日期的关系', title_pos = 'center', width = 1200, height = 600) attr, value = bar.cast(data) #['2019/2/10', '2019/2/11', '2019/2/12'][44094, 38238, 32805] bar.add('', attr, value, is_visualmap = True, visual_range = [0, 1000], visual_text_color = '#fff', is_more_utils = True, is_label_show = True) bar.render('./观众评论日期-柱状图.html') print('观众评论数量与日期的关系已完成') if __name__ == '__main__': filename = 'E:\\NOthree\\python\\B_comments.csv' titles = ['floor', 'username', 'ctime', 'content', 'likes', 'rcounts'] comments = read_csv(filename, titles) draw_data_bar(comments)
2.除去性别保密的用户外,男性用户观看这篇视频的人数居多,同时也反应出漫威迷较多为男生,而观看这篇视频的人都是对钢铁侠有着喜爱的人,也反映出男生对钢铁侠,漫威第一阶段终结之神的兴趣较大,
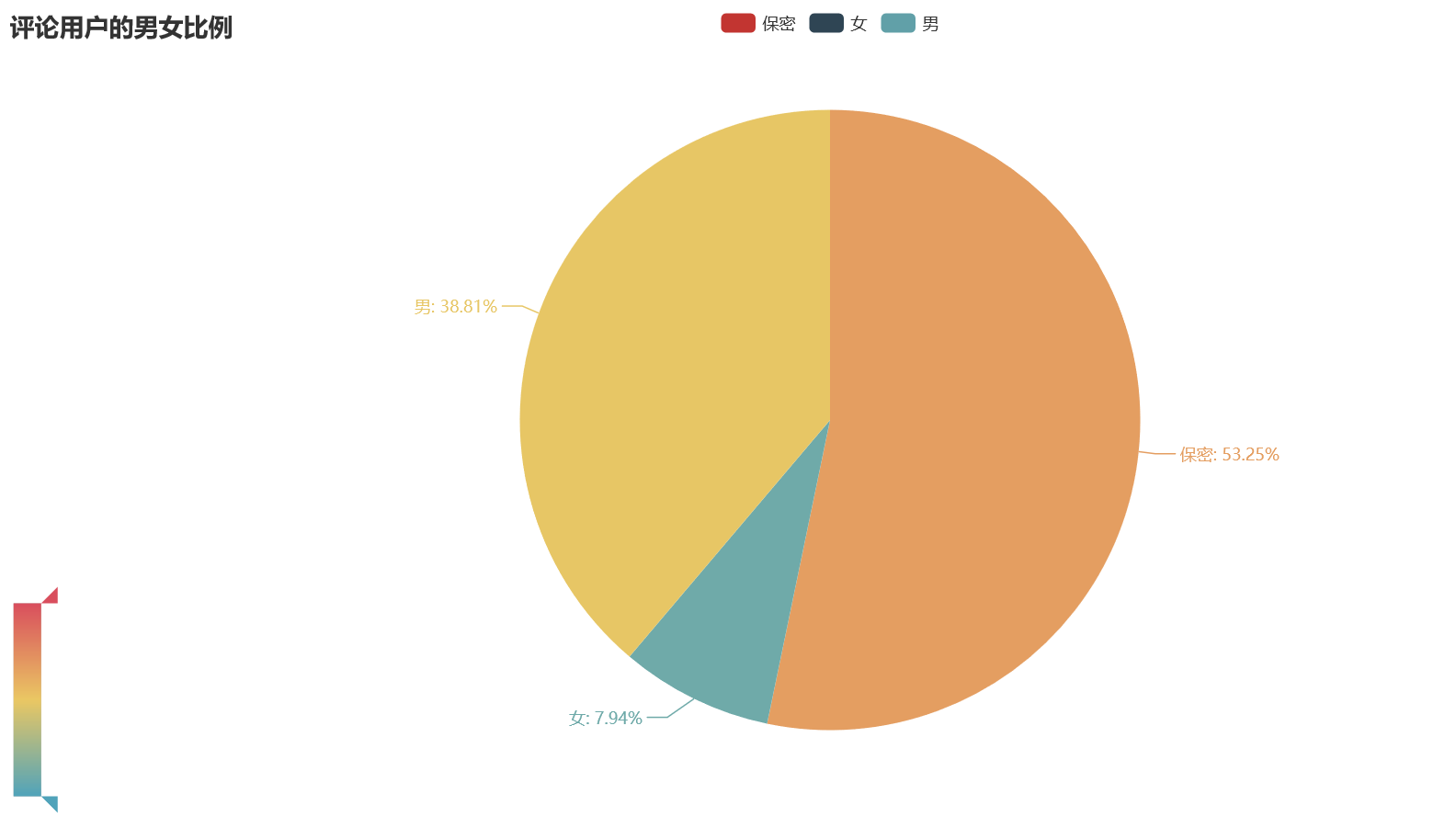
详细代码如下:
from collections import Counter from pyecharts import Pie import time import pandas as pd def read_csv(filename, titles): comments = pd.read_csv(filename, names = titles, low_memory = False) return comments def draw_data_bar(comments): sex = comments['sex'] data = Counter(sex).most_common() #data形式[('2019/2/10', 44094), ('2019/2/9', 43680)] data = sorted(data, key=lambda data : data[0]) #data1变量相当于('2019/2/10', 44094)各个元组 itemgetter(0) pie =Pie('评论用户的男女比例', title_pos = 'left', width = 1200, height = 600) attr, value = pie.cast(data) #['2019/2/10', '2019/2/11', '2019/2/12'][44094, 38238, 32805] pie.add('', attr, value, is_visualmap = True, visual_range = [0, 1000], visual_text_color = '#fff', is_more_utils = True, is_label_show = True) pie.render('./评论用户的男女比例饼图.html') print('评论用户的男女比例饼图已完成') if __name__ == '__main__': filename = 'E:\\NOthree\\python\\A_comments.csv' titles = ['username', 'sex', 'birthday', 'city', 'attentions', 'fans',"friends"] comments = read_csv(filename, titles) draw_data_bar(comments)
3.分析评论中出现最多的词语,其中”钢铁“一词出现得最多,同时”奇异博士“出现的次数也较多,看来观看完的用户对奇异博士也有着相当的喜爱,”love you three thousand“是妇联4中钢铁侠女儿的一句台词,其出现在评论的次数也相对较多,看来这句话也是漫威迷想对钢铁侠说的一句话呢~

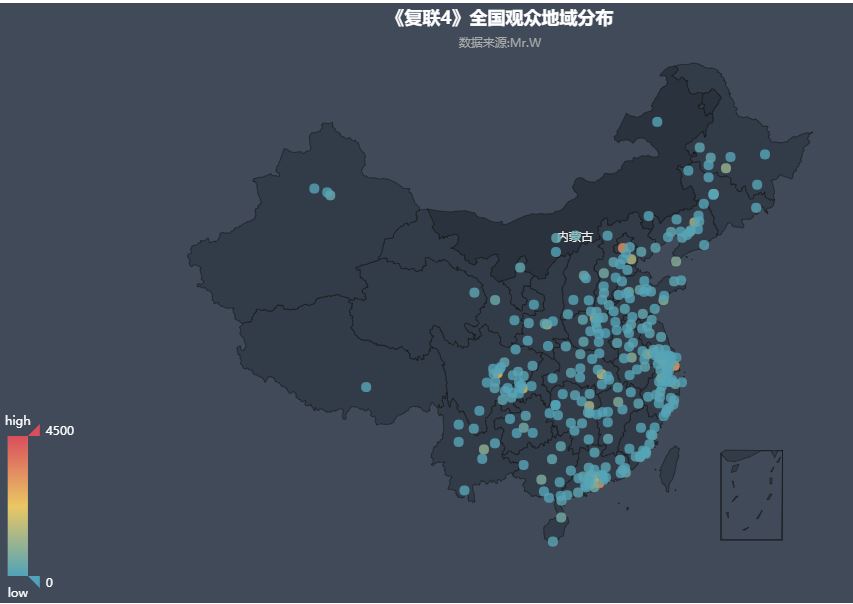
4.根据观看妇联的观众地域分布图可以看出,大多数观众来自中部及沿海地区,也反映出西部地区的发展还需加油~
- 总结
在此次作业中,遇到了不少的问题,从一开始的抓取网页内容失败到安装pyechart,安装版本出错,再到各种异常没有及时抛出。此次作业花费了不少的时间,但收获也是巨大的,复习回顾前半个学期学习的python的同时也在做作业时学习到新的python的内容,在一次次的报错中成长。
在学习的过程中,发现python是一门很好玩的语言,可以说很适合女生吧,可以用来爬取购物数据,商品的热销度,电影的热度,让我乐在其中。分析的过程中还能将自己融入在大数据的海洋中,同时经过学习pyechart,发现数据的可视化给我们带来了更多的乐趣。
在做此次作业的过程中,发现了”猫眼电影专业版“ ,非常非常牛批的大数据分析应用在我们的生活中,大家可以去观看参考,了解大数据的妙处→https://piaofang.maoyan.com/movie/248172?_v_=yes

 浙公网安备 33010602011771号
浙公网安备 33010602011771号