作业要求:
1.列表,元组,字典,集合分别如何增删改查及遍历?
1)列表
- 增:
- append() :在列表末尾增加一个元素

-
- insert() : 在指定的列表位置添加一个元素
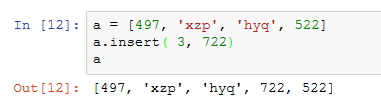
-
- extand() : 在列表末尾一次性追加另一个序列中的多个值

- 删:
- pop() : 移除列表中的最后一个元素,并且返回该元素的值

-
- remove() : 用于移除列表中某个值的第一个匹配项
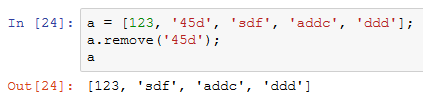
-
- del() : 根据元素下标删除列表的元素
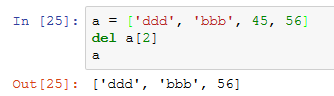
- 改:
- 根据列表下标对元素进行重新赋值即可
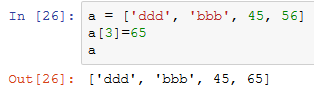
- 查:
a = ['sss','bbb','dd','sdf'] print(a[2]) ##根据下标直接查找列表元素 print(a[1:3])##通过切片方式进行取值 print(a[:])##获取列表所有元素 print(a[-1])##取列表最后一个值 print(a[2:])##取下标后面所有的值 print(a[:3])##取下标前面所有的值 print(a[:1:2])##隔位取值
运行结果截图:

- 遍历
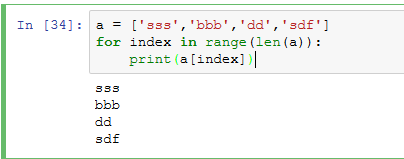
2)元组
- 增:元组不支持修改,只能通过连接组合方式进行元组的增加

- 删:元组的删除不能删除某个元素,只能整个元组一起删除,删除后输出报错,因为该元组已删除,输出则定义为未定义
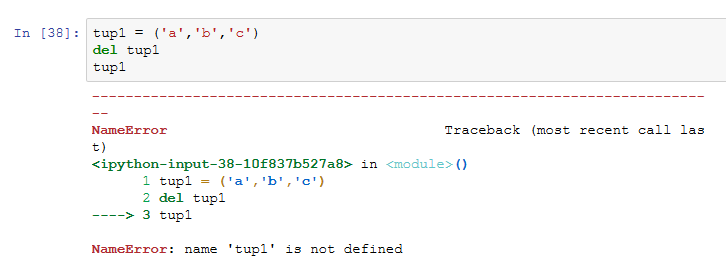
- 改:元组中的元素值是不允许修改的,和增加元组一样,对元组进行修改只能通过连接结合
- 查:因为元组也是一个序列,因此我们可以查找元组中指定位置的元素,也可以截取索引中的一段元素
a = ('sss','bbb','dd','sdf')
print(a[2]) ##根据下标直接查找列表元素
print(a[1:3])##通过切片方式进行取值
print(a[:])##获取列表所有元素
print(a[-1])##取列表最后一个值
print(a[2:])##取下标后面所有的值
print(a[:3])##取下标前面所有的值
print(a[:1:2])##隔位取值
运行截图如下:

- 遍历
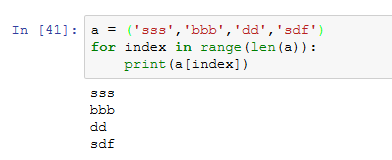
3)字典
- 增:以同时添加键值的方式进行字典元素的添加

- 删
- del dict['a']:删除键是‘a’的条目

-
- clear() : 清空词典所有条目
- del dict : 删除词典
- 改

- 查:根据相应的键对其值进行查找
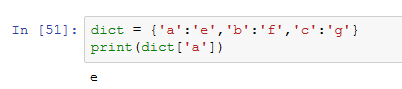
- 遍历:
字典提供items方法可以获取字典所有的项集合;
字典提供vlaues方法可以对字典中的值进行遍历;
字典提供keys方法对字典中的键进行遍历
4)集合
- 增:使用add()方法进行集合中元素的添加
- 删:
使用remove()或者pop()方法可以对集合中的某个元素进行删除;
clean()方法用于清空集合中的元素;
del方法可以将整个集合进行删除。
- 改:根据集合中的元素下标进行修改该元素的值
- 查:根据集合中的元素下标进行查找元素的值
- 遍历:
可以使用for循环对集合中的每个元素进行遍历;
可以使用迭代器迭代集合中的元素进行遍历。
2.总结列表,元组,字典,集合的联系与区别
1)列表
- 列表是使用 “ [ ] ”中括号对列表元素括起来,用逗号间隔每一个元素
- 列表时有序的,可以根据索引来访问列表中的值
- 列表是可变的,可以对列表中的值进行增删改查
- 列表中的值是可以重复的
- 列表的存储是根据索引进行存储的,查找时可以根据索引查找出值
2)元组
- 元组是使用 “ () “小括号将元组的值括起来,用逗号间隔每一个元素
- 元组是有序的
- 元组一经初始化后便不能修改
- 元组中的元素是可以重复的
- 元组的存储同样根据索引进行存储,查找时根据索引进行查找
3)字典
- 每个键值对用冒号 :进行 分割,每个键值对之间用逗号 进行分割,整个字典包括在花括号 ” { } “ 中
- 字典是有序的
- 字典中的值是可以改变的
- 键一般是唯一的,值不需要唯一
- 字典是另一种可变容器模型,且可存储任意类型对象
3.词频统计
详细代码:
#打开歌词文档
f = open(r'E:\\red.txt', 'r')
#定义列表,用于排除语法型词汇,代词、冠词、连词等无语义词
stop={'a','the','and','i','you','in','but','not','with','by','its','for','of','an','to','my','myself','we','our','ours','ourelves','about','no','nor'}
#打开歌词文档,将歌词中的标点符号用空格代替
def gettext():
sep=",.? ?':' !--\!_:"
text=f.read().lower()
for c in sep:
textx=text.replace(c,' ')
return textx
#对文档中的句子进行分解成一个个单词并输出
aList=gettext().split()
#把分解后的词语放在字典中
worddict=set(aList)
#把停用词放在另外一个字典中
aStop=set(stop)
#去掉停用词
worddict=worddict-aStop
#定义字典,对单词数目进行统计
aDict={}
for word in worddict:
aDict[word]=aList.count(word)
print(aDict.items())
word=list(aDict.items())
#对统计出来的结果进行排序
word.sort(key=lambda x:x[1],reverse=True)
print(word)
#输出使用次数最多的前20的单词
for i in range(20):
print(word[i])
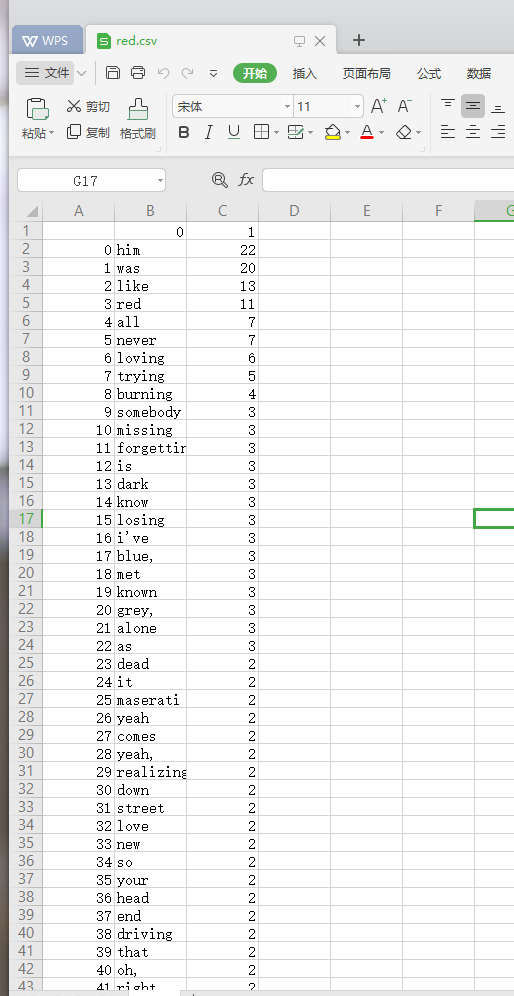
#对结果输出到red.csv中
import pandas as pd
pd.DataFrame(data=word).to_csv("E:\\red.csv",encoding='utf-8')
运行结果截图:
- 输出字典中所有的item

- 输出使用次数最多的前20的单词

- red.csv
- 可视化词云


 浙公网安备 33010602011771号
浙公网安备 33010602011771号