

CS144-Lab1-StreamReassembler
lab 地址 :lab1-doc
代码实现:lab1-code
0. ByteStream
1. StreamReassembler
2. TCPReceiver
3. TCPSender
4. TCPConnection
5. ARP
6. IP-Router
1. 目标
TCP 一个很重要的特性是可以实现顺序、无差错、不重复和无报文丢失的流传输。在 lab0 中我们已经实现了一个字节流 ByteStream,而在 lab1 我们需要保证传入 ByteStream 的字节流是有序可靠不重复的,在此之上需要封装实现一个 StreamReassembler。
为了确定每次 push 进来的字节流的顺序,每个字节流都有一个 index,如果完整字符串为:
“abcdefg”,然后拆分成 abc,bcd,efg 三个子串,则他们的 index 分别为 0,1,5,也就是首字符在 完整字节流中的位置,index 从 0 开始,参考下图:
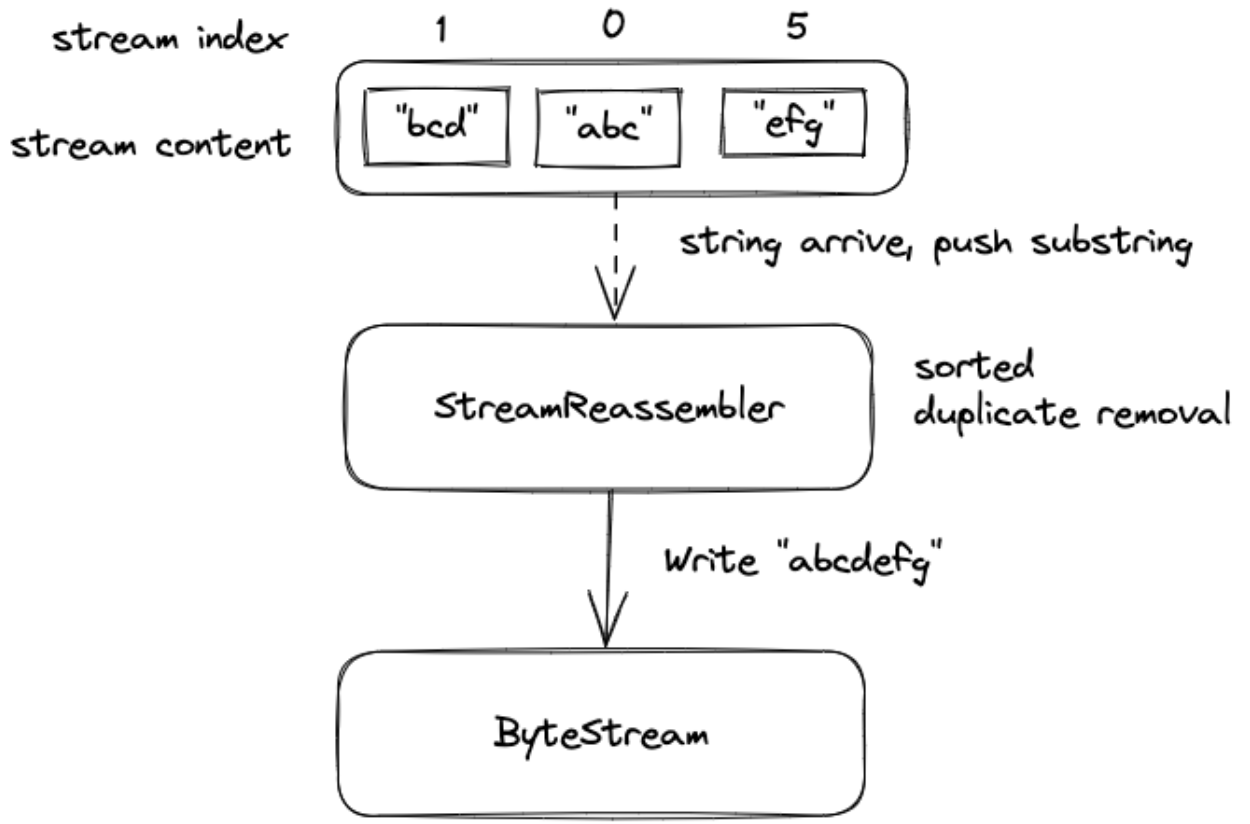
StreamReassembler 需要做到去重,比如 abc 和 bcd 两个子串重合了 bc 部分,那么需要合并,最终的字符串为 abcd。
2. 实现
StreamReassembler 的核心接口只有一个:
//! \brief Receive a substring and write any newly contiguous bytes into the stream. //! //! The StreamReassembler will stay within the memory limits of the `capacity`. //! Bytes that would exceed the capacity are silently discarded. //! //! \param data the substring //! \param index indicates the index (place in sequence) of the first byte in `data` //! \param eof the last byte of `data` will be the last byte in the entire stream void push_substring(const std::string &data, const uint64_t index, const bool eof);
由于字节流可能为乱序 push,因此需要缓存还不能 push 到 ByteStream 的 string
大致流程如下:
- 检查是否为预期的字节流(维护一个当前预期接受的
_assemble_idx,只有传入的 string 的 index >_assemble_idx时,才为预期的字节流) - 如果为预期字节流,直接压入
ByteStream,更新_assemble_idx,合并缓存中满足合并条件的 string - 如果不是预期的字节流,则缓存起来,并且检查能否和缓存的字符串合并
code 如下(还能再简洁很多),完整 code 参考 (lab1-code):
void StreamReassembler::push_substring(const string &data, const size_t index, const bool eof) { if (eof) { _eof_idx = data.size() + index; } // not expect segement, cache it if (index > _assemble_idx) { _merge_segment(index, data); return; } // expect segment, write it to ByteStream int start_pos = _assemble_idx - index; int write_cnt = data.size() - start_pos; // not enough space if (write_cnt < 0) { return; } _assemble_idx += _output.write(data.substr(start_pos, write_cnt)); // search the next segment std::vector<size_t> pop_list; for (auto segment : _segments) { // already process or empty string if (segment.first + segment.second.size() <= _assemble_idx || segment.second.size() == 0) { pop_list.push_back(segment.first); continue; } // not yet if (_assemble_idx < segment.first) { continue; } start_pos = _assemble_idx - segment.first; write_cnt = segment.second.size() - start_pos; _assemble_idx += _output.write(segment.second.substr(start_pos, write_cnt)); pop_list.push_back(segment.first); } // remove the useless segment for (auto segment_id : pop_list) { _segments.erase(segment_id); } if (empty() && _assemble_idx == _eof_idx) { _output.end_input(); } }
正常情况下符合预期的字节流我们可以直接 push 进 ByteStream,如果有重叠部分则从重叠部分后面开始 push,理论上只有这两种情况( 符合预期 这个前提剔除掉了麻烦的情况):
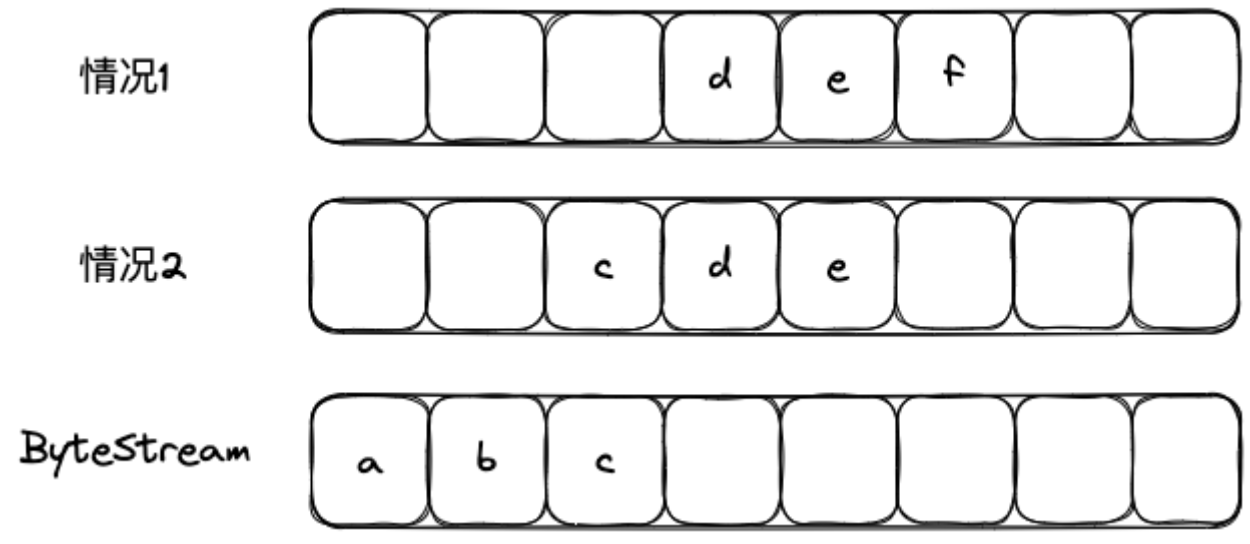
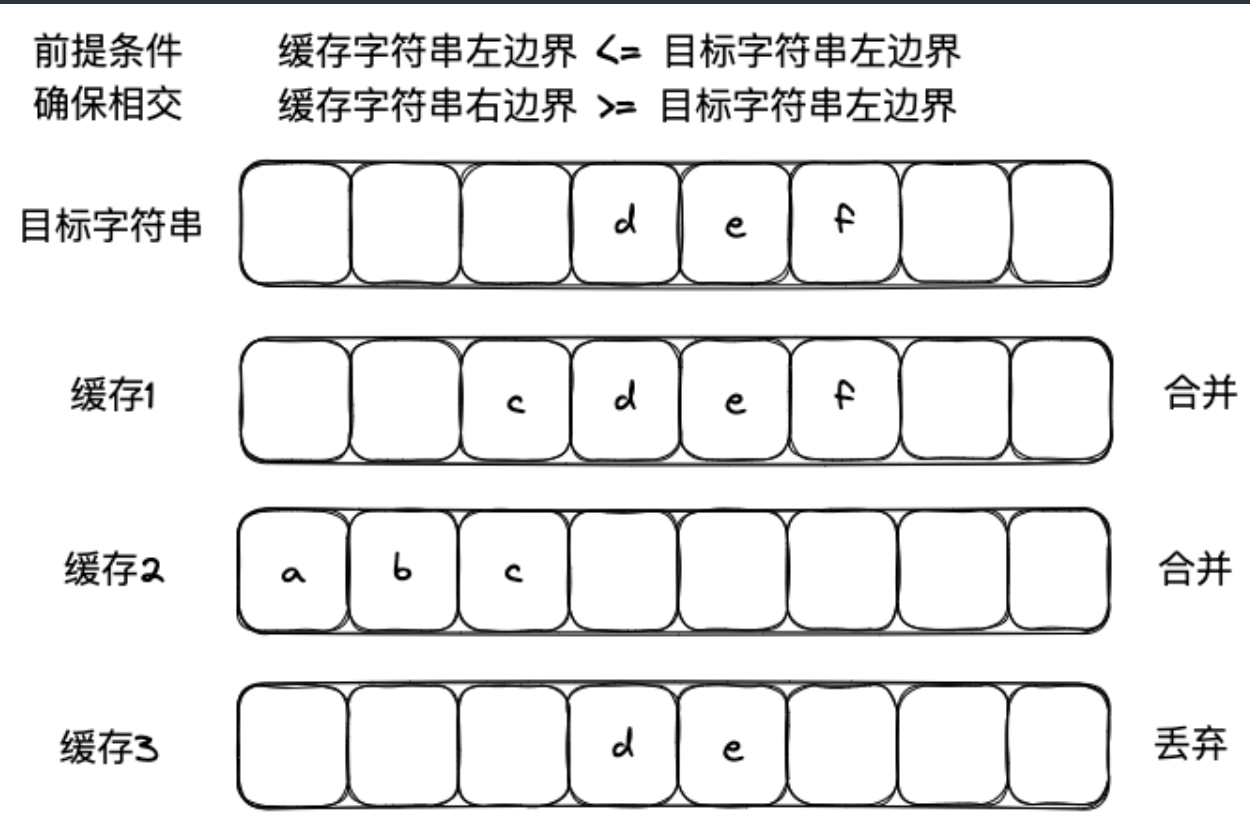
这里麻烦点主要在于,对于不符合预期的字符串,我们要缓存起来,并且合并缓存中的字符串,这里主要梳理好有几种情况即可,主要有如下情况:
缓存字符串在目标字符串左侧的
缓存字符串在目标字符串右侧的
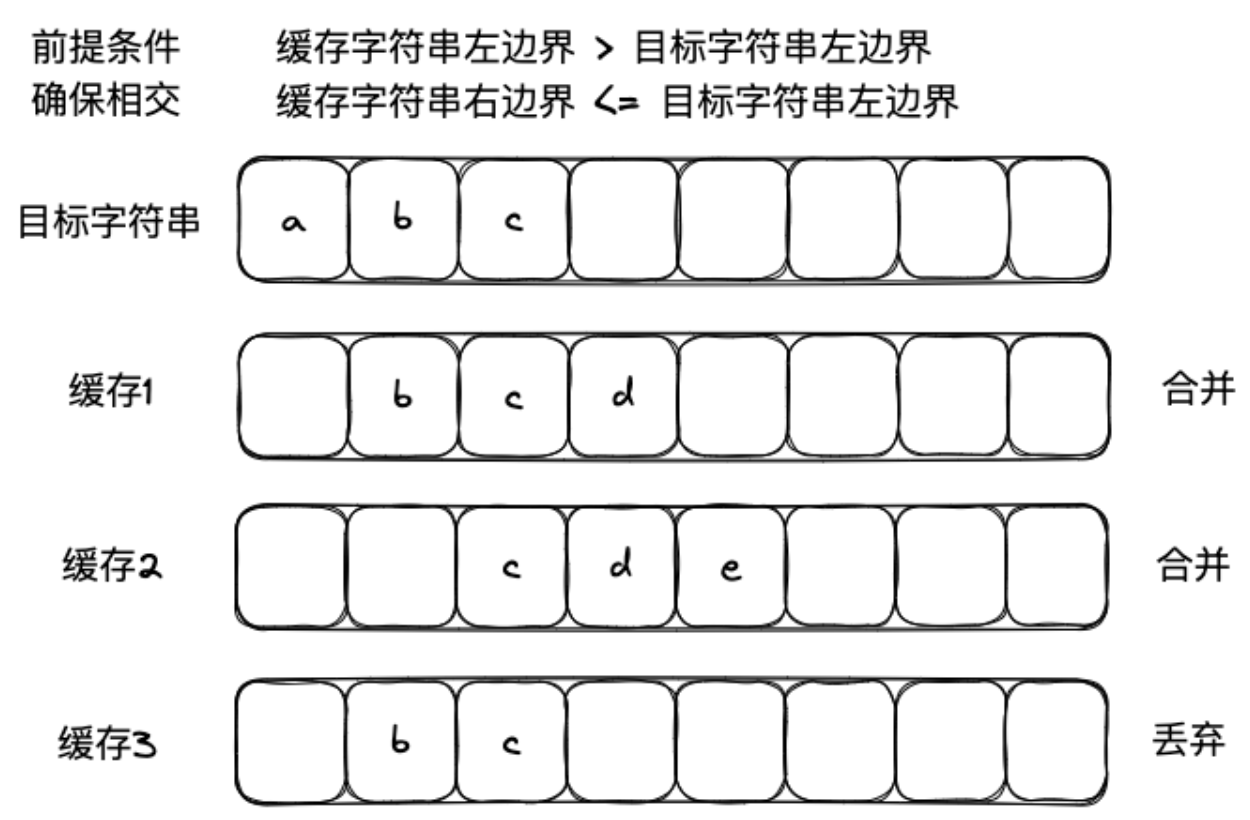
code 如下:
void StreamReassembler::_merge_segment(size_t index, const std::string& data) { size_t data_left = index; size_t data_right = index + data.size(); std::string data_copy = data; std::vector<size_t> remove_list; bool should_cache = true; for (auto segment : _segments) { size_t seg_left = segment.first; size_t seg_right = segment.first + segment.second.size(); //|new_index |segment.first |segment.second.size() |merge_segment.size if (data_left <= seg_left && data_right >= seg_left) { if (data_right >= seg_right) { remove_list.push_back(segment.first); continue; } if (data_right < seg_right) { data_copy = data_copy.substr(0, seg_left - data_left) + segment.second; data_right = data_left + data_copy.size(); remove_list.push_back(segment.first); } } if (data_left > seg_left && data_left <= seg_right) { if (data_right <= seg_right) { should_cache = false; } if (data_right > seg_right) { data_copy = segment.second.substr(0, data_left - seg_left) + data_copy; data_left = seg_left; data_right = data_left + data_copy.size(); remove_list.push_back(segment.first); } } } // remove overlap data for (auto remove_idx : remove_list) { _segments.erase(remove_idx); } if (should_cache) _segments[data_left] = data_copy; } }
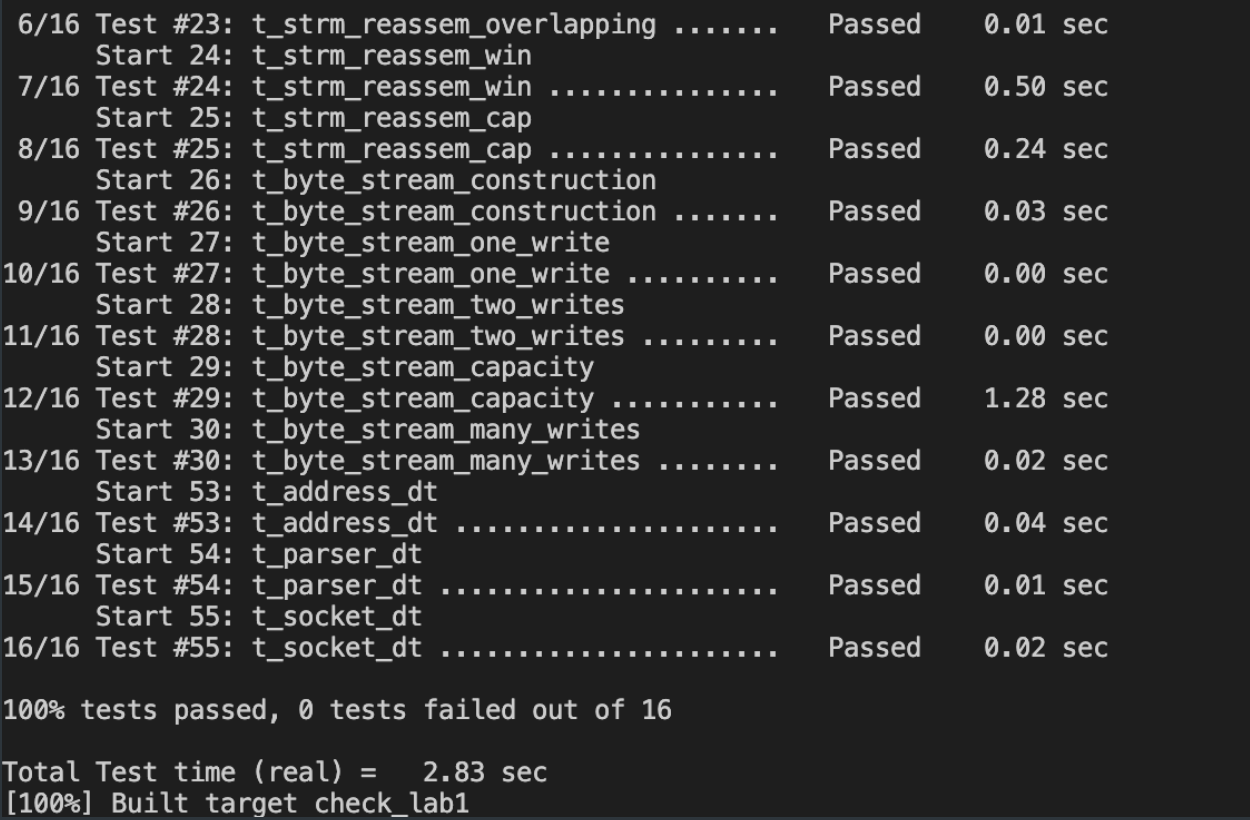
3. 测试


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本