

2022-6.824-Lab3:KVRaft
0. 准备工作
lab 地址:https://pdos.csail.mit.edu/6.824/labs/lab-kvraft.html
github 地址:https://github.com/lawliet9712/MIT-6.824
Lab3 需要基于之前实现的 Lab2 Raft 来实现一个可靠的 Key-Value Database,分别对 Client 和 Server 进行实现,Client 主要通过 3 种操作对 DB 进行操作:
- Put :对指定 Key 直接设置 Value
- Append :对指定 Key 追加 Value
- Get :获取指定 Key 的 Value
其整体结构大致如下: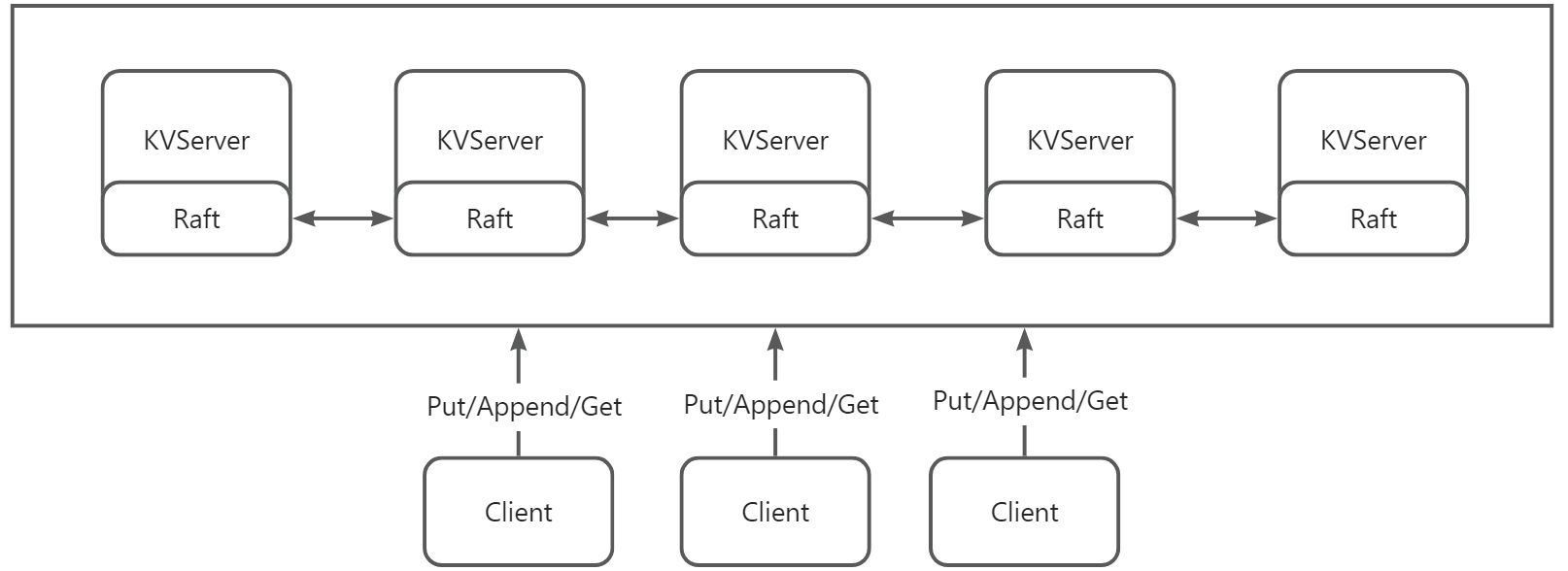
KVServer 除了提供 DB 的功能外,要保证可用性,一致性和安全性,因此要利用 Raft 来实现一个可靠的 KVServer。KVServer 以 5 个节点为一组,每组 KVServer(在该 Lab 只会有一组 KVServer)会有一个 Leader(只有 Leader 才会处理 Client RPC 请求),和四个 Follwer,每次收到 Client 端的 DB 操作时,需要将操作封装成 Command 后通过 Raft.Start 接口投递到 Raft 层,然后 Raft 层将操作通过基本的心跳同步给 Follwer 以增加安全性和可靠性。
1. Part A: Key/value service without snapshots (moderate/hard)
PartA 主要提供没有快照的键值服务,Client 将 Put,Append,和 Get RPC 发送到其关联的 Raft 是 Leader 的 KVServer。KVServer 代码将 Put/Append/Get 操作提交给 Raft,这样 Raft 日志就会保存一系列 Put/Append/Get 操作。所有的 kvservers 按顺序从 Raft 日志执行操作,将操作应用到它们的键/值数据库;目的是让服务器维护键/值数据库的相同副本。
Client 有时不知道哪个 KVServer 是 Raft leader 。如果 Client 将 RPC 发送到错误的 KVServer,或者无法到达 KVServer,Client 应该通过发送到不同的 kvserver 来重试。如果键/值服务将操作提交到其 Raft 日志(并因此将操作应用于键/值状态机),Leader 通过响应其 RPC 将结果报告给 Client 。如果操作提交失败(例如,如果 Leader 被替换),服务器会报告错误,然后 Client 会尝试使用不同的服务器。
1.1 分析
- 当我们收到请求时,我们应该先通过
Start接口将请求的操作同步到各个节点,然后各个节点再根据请求具体的操作 (Put/Append/Get)来执行对应的逻辑,这样就可以保证各个节点的一致性- 这里有个问题,为什么 Get 也需要执行
Start同步,这是为了保证客户端操作的历史一致性,假设有如下情况:
- 这里有个问题,为什么 Get 也需要执行
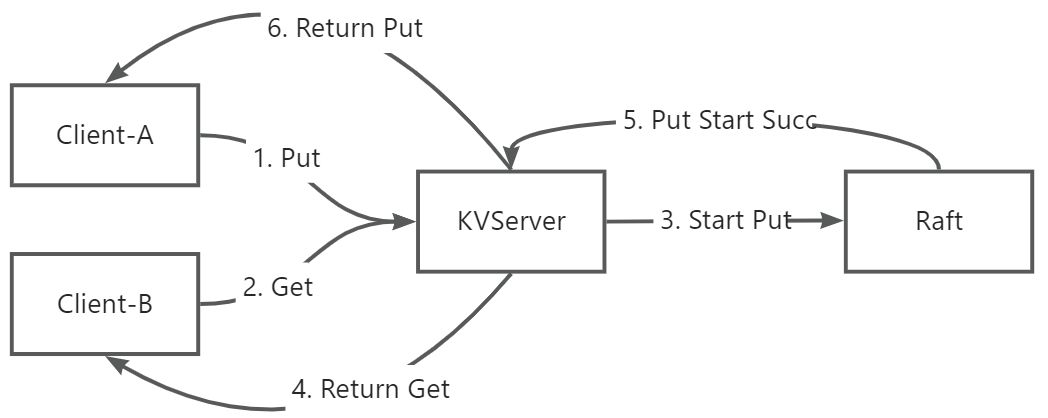
假设严格按照编号时序执行,理论上 Client-B 应该 Get 到 A 的 Put 操作结果,但是由于 Put 需要通过 Start 去同步给其他节点,同步成功后(超过半数节点顺利同步),才会返回给 KVServer,KVServer 才能返回给 Client-A,而如果 Get 操作不需要 Start,直接返回,就有可能导致历史一致性错误。
-
需要注意 Hint:
:::info
After calling Start(), your kvservers will need to wait for Raft to complete agreement. Commands that have been agreed upon arrive on the applyCh. Your code will need to keep reading applyCh while PutAppend() and Get() handlers submit commands to the Raft log using Start(). Beware of deadlock between the kvserver and its Raft library.
:::
在 Start 过后需要等待 Start 结果,收到结果后才能返回给 Client 操作是否成功(这里单个 Client 的操作不会并发,只有上一个操作结束了才会继续执行下一个) -
由于 Start 操作是异步的,该操作无法保证成功(Leader 可能会 Change),因此在等待的过程中,需要设定一个等待超时时间,超时后需要检查当前是否还是 Leader,如果还是 Leader 则继续等待。
-
需要增加一个 Client Request Unique Id,或者说一个 Sequence Id,以保证 Client 的操作不会被重复执行。
基于上述分析,可以得到 KVServer 处理 Request 的大致流程: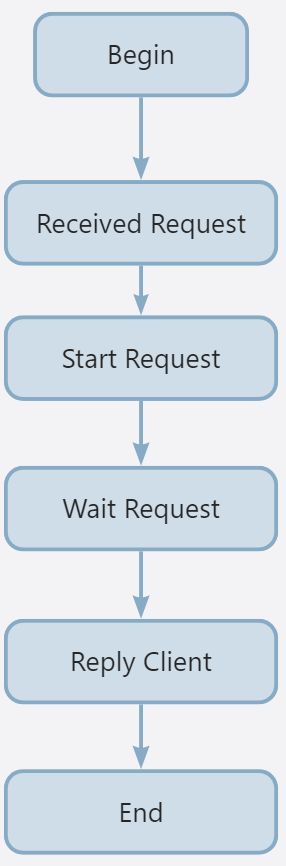
而需要有另一处地方去处理 Start 成功后,Apply Channel 返回的成功的 ApplyMsg,这里选择另起一个 processMsg 的 goroutine。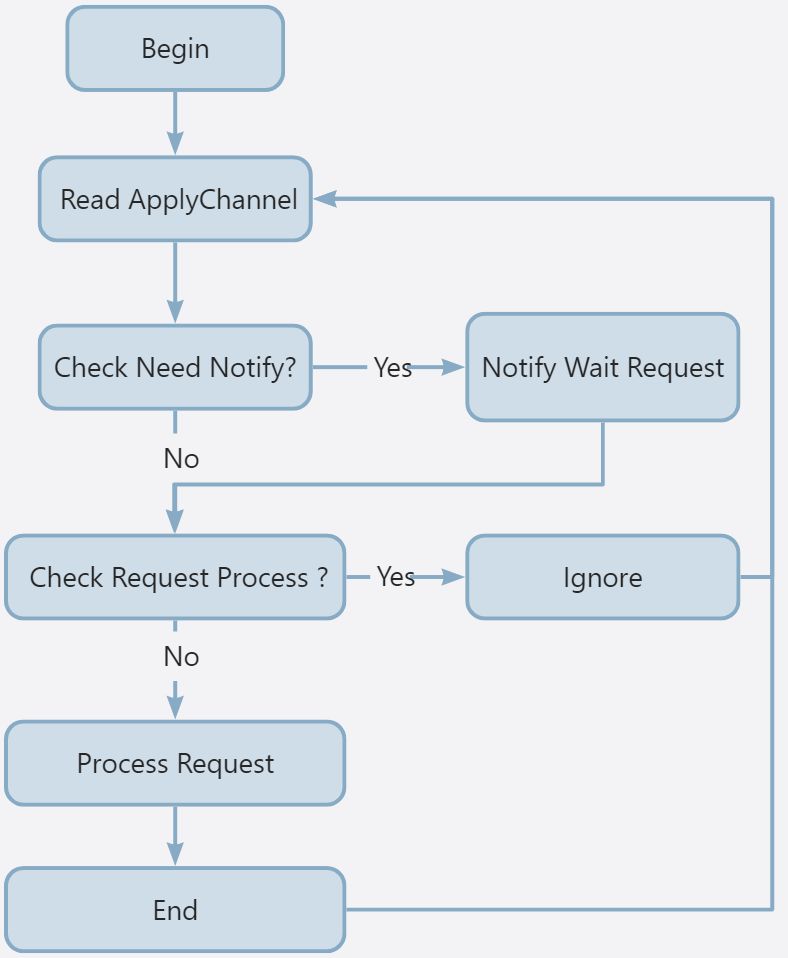
1.2 实现
1.2.1 各个 RPC 请求参数设计
如下,主要新增了 2 个参数,一个 SeqId,用来防止请求重复执行,另一个 ClerkId 用来标识唯一的客户端 UID,这里 Put/Append 在 Lab 中被合并为一个请求。
// Put or Append type PutAppendArgs struct { Key string Value string Op string // "Put" or "Append" // You'll have to add definitions here. // Field names must start with capital letters, // otherwise RPC will break. ClerkId int64 SeqId int } type PutAppendReply struct { Err Err } type GetArgs struct { Key string // You'll have to add definitions here. ClerkId int64 SeqId int } type GetReply struct { Err Err Value string }
1.2.2 Op 结构设计
这个 Op 结构主要封装需要用到的信息后投递给 Raft 层,用来同步使用。
type Op struct { // Your definitions here. // Field names must start with capital letters, // otherwise RPC will break. Key string Value string Command string ClerkId int64 SeqId int Server int // 基本无用 }
1.2.3 Clerk 结构
这里为了方便,为每个 Client 在 Server 端增加了一个结构,大致如下:
type ClerkOps struct { seqId int // clerk current seq id getCh chan Op putAppendCh chan Op msgUniqueId int // rpc waiting msg uid }
1.2.4 Client 请求实现
Client 请求实现很简单,基本模板就是 for loop 直到请求完成就退出。以 PutAppend 为例。
func (ck *Clerk) PutAppend(key string, value string, op string) { // You will have to modify this function. args := PutAppendArgs{ Key: key, Value: value, Op: op, ClerkId: ck.ckId, SeqId: ck.allocSeqId(), } reply := PutAppendReply{} server := ck.leaderId for { DPrintf("[Clerk-%d] call [PutAppend] request key=%s value=%s op=%s, seq=%d, server=%d", ck.ckId, key, value, op, args.SeqId, server%len(ck.servers)) ok := ck.SendPutAppend(server%len(ck.servers), &args, &reply) if ok { if reply.Err == ErrWrongLeader { server += 1 time.Sleep(50 * time.Millisecond) DPrintf("[Clerk-%d] call [PutAppend] faild, try next server id =%d ... retry args=%v", ck.ckId, server, args) continue } ck.leaderId = server DPrintf("[Clerk-%d] call [PutAppend] response server=%d, ... reply = %v, args=%v", ck.ckId, server%len(ck.servers), reply, args) break } else { // Send Request failed ... retry server += 1 DPrintf("[Clerk][PutAppend] %d faild, call result=false, try next server id =%d ... retry reply=%v", ck.ckId, server, reply) } time.Sleep(50 * time.Millisecond) } }
这里有一点特殊的是,每次请求成功后,会记录一下请求成功的 ServerId 作为 LeaderId,后续请求就直接请求该 Id 的 Server,这样可以减少一些无效请求。
1.2.5 Server 处理 RPC
1.2.5.1 Put/Append
RPC 处理主要分为两部分,第一部分收集必要的信息,投递到 Raft 层同步,第二部分等待同步结果并返回客户端。
func (kv *KVServer) PutAppend(args *PutAppendArgs, reply *PutAppendReply) { // Your code here. // step 1 : start a command, wait raft to commit command // not found then init // check msg kv.mu.Lock() ck := kv.GetCk(args.ClerkId) // already process if ck.seqId > args.SeqId { kv.mu.Unlock() reply.Err = OK return } DPrintf("[KVServer-%d] Received Req PutAppend %v, SeqId=%d ", kv.me, args, args.SeqId) // start a command logIndex, _, isLeader := kv.rf.Start(Op{ Key: args.Key, Value: args.Value, Command: args.Op, ClerkId: args.ClerkId, SeqId: args.SeqId, Server: kv.me, }) if !isLeader { reply.Err = ErrWrongLeader kv.mu.Unlock() return } ck.msgUniqueId = logIndex DPrintf("[KVServer-%d] Received Req PutAppend %v, waiting logIndex=%d", kv.me, args, logIndex) kv.mu.Unlock() // step 2 : wait the channel reply.Err = OK Msg, err := kv.WaitApplyMsgByCh(ck.putAppendCh, ck) kv.mu.Lock() defer kv.mu.Unlock() DPrintf("[KVServer-%d] Recived Msg [PutAppend] from ck.putAppendCh args=%v, SeqId=%d, Msg=%v", kv.me, args, args.SeqId, Msg) reply.Err = err if err != OK { DPrintf("[KVServer-%d] leader change args=%v, SeqId=%d", kv.me, args, args.SeqId) return } }
这里主要需要关注下等待部分,等待部分的思路是:
- 每个 Client 有个 Clerk 结构,其有两个关键字段:MsgUniqueId 和对应请求的 Channel(getCh/putAppendCh),处理 RPC 时先设置这个 Clerk.MsgUniqueId 为 Start 后返回的 LogIndex
- 随后 Read 对应操作的 Channel 进行阻塞等待。
- 在处理 Raft 层返回的结果时(在一个单独的 goroutinue 中执行),检查 Clerk.MsgUniqueId 是否与这个 ApplyMsg 的 CommandIndex 相等且当前节点为 Leader,是就表示需要通知。投递消息到 Clerk 的 Channel
其 Wait 和 Notify 的 Code 如下:
func (kv *KVServer) WaitApplyMsgByCh(ch chan Op, ck *ClerkOps) (Op, Err) { startTerm, _ := kv.rf.GetState() timer := time.NewTimer(1000 * time.Millisecond) for { select { case Msg := <-ch: return Msg, OK case <-timer.C: curTerm, isLeader := kv.rf.GetState() if curTerm != startTerm || !isLeader { kv.mu.Lock() ck.msgUniqueId = 0 kv.mu.Unlock() return Op{}, ErrWrongLeader } timer.Reset(1000 * time.Millisecond) } } } func (kv *KVServer) NotifyApplyMsgByCh(ch chan Op, Msg Op) { // we wait 200ms // if notify timeout, then we ignore, because client probably send request to anthor server timer := time.NewTimer(200 * time.Millisecond) select { case ch <- Msg: return case <-timer.C: DPrintf("[KVServer-%d] NotifyApplyMsgByCh Msg=%v, timeout", kv.me, Msg) return } }
1.2.5.2 Get
Get 操作与前者类似,不过多复述
func (kv *KVServer) Get(args *GetArgs, reply *GetReply) { // Your code here. // step 1 : start a command, check kv is leader, wait raft to commit command //_, isLeader := kv.rf.GetState() // check msg kv.mu.Lock() ck := kv.GetCk(args.ClerkId) DPrintf("[KVServer-%d] Received Req Get %v", kv.me, args) // start a command logIndex, _, isLeader := kv.rf.Start(Op{ Key: args.Key, Command: "Get", ClerkId: args.ClerkId, SeqId: args.SeqId, Server: kv.me, }) if !isLeader { reply.Err = ErrWrongLeader ck.msgUniqueId = 0 kv.mu.Unlock() return } DPrintf("[KVServer-%d] Received Req Get %v, waiting logIndex=%d", kv.me, args, logIndex) ck.msgUniqueId = logIndex kv.mu.Unlock() // step 2 : parse op struct getMsg, err := kv.WaitApplyMsgByCh(ck.getCh, ck) kv.mu.Lock() defer kv.mu.Unlock() DPrintf("[KVServer-%d] Received Msg [Get] args=%v, SeqId=%d, Msg=%v", kv.me, args, args.SeqId, getMsg) reply.Err = err if err != OK { // leadership change, return ErrWrongLeader return } _, foundData := kv.dataSource[getMsg.Key] if !foundData { reply.Err = ErrNoKey return } else { reply.Value = kv.dataSource[getMsg.Key] DPrintf("[KVServer-%d] Excute Get %s is %s", kv.me, getMsg.Key, reply.Value) } }
1.2.6 处理 Raft 层消息
该结构的主要逻辑与分析类似,无限循环去 Read Apply Channel,根据 Sequence Id 判断是否需要执行操作,根据 CommandIndex 的对比判断是否有等待通知的 Channel。
func (kv *KVServer) processMsg() { for { applyMsg := <-kv.applyCh if applyMsg.SnapshotValid { kv.readKVState(applyMsg.Snapshot) continue } Msg := applyMsg.Command.(Op) DPrintf("[KVServer-%d] Received Msg from channel. Msg=%v", kv.me, applyMsg) kv.mu.Lock() ck := kv.GetCk(Msg.ClerkId) // not now process this log if Msg.SeqId > ck.seqId { DPrintf("[KVServer-%d] Ignore Msg %v, Msg.Index > ck.index=%d", kv.me, applyMsg, ck.seqId) kv.mu.Unlock() continue } // check need snapshot or not _, isLeader := kv.rf.GetState() if kv.needSnapshot() { DPrintf("[KVServer-%d] size=%d, maxsize=%d, DoSnapshot %v", kv.me, kv.persister.RaftStateSize(), kv.maxraftstate, applyMsg) kv.saveKVState(applyMsg.CommandIndex - 1) } // check need notify or not needNotify := ck.msgUniqueId == applyMsg.CommandIndex //DPrintf("[KVServer-%d] msg=%v, isleader=%v, ck=%v", kv.me, Msg, ck) if Msg.Server == kv.me && isLeader && needNotify { // notify channel and reset timestamp ck.msgUniqueId = 0 DPrintf("[KVServer-%d] Process Msg %v finish, ready send to ck.Ch, SeqId=%d isLeader=%v", kv.me, applyMsg, ck.seqId, isLeader) kv.NotifyApplyMsgByCh(ck.GetCh(Msg.Command), Msg) DPrintf("[KVServer-%d] Process Msg %v Send to Rpc handler finish SeqId=%d isLeader=%v", kv.me, applyMsg, ck.seqId, isLeader) } if Msg.SeqId < ck.seqId { DPrintf("[KVServer-%d] Ignore Msg %v, Msg.SeqId < ck.seqId", kv.me, applyMsg) kv.mu.Unlock() continue } switch Msg.Command { case "Put": kv.dataSource[Msg.Key] = Msg.Value DPrintf("[KVServer-%d] Excute CkId=%d Put Msg=%v, kvdata=%v", kv.me, Msg.ClerkId, applyMsg, kv.dataSource) case "Append": DPrintf("[KVServer-%d] Excute CkId=%d Append Msg=%v kvdata=%v", kv.me, Msg.ClerkId, applyMsg, kv.dataSource) kv.dataSource[Msg.Key] += Msg.Value case "Get": DPrintf("[KVServer-%d] Excute CkId=%d Get Msg=%v kvdata=%v", kv.me, Msg.ClerkId, applyMsg, kv.dataSource) } ck.seqId = Msg.SeqId + 1 kv.mu.Unlock() } }
1.3 注意点
- 对比 2021 的 6.824,这里主要新增了一个 TestSpeed3A 的 Test Case,该 Case 在最开始的情况下很难 Pass,因为他要求 30ms 完成一个 Op,而 Raft 的心跳是 100ms 一次,如果直接去调整 Raft 心跳时长感觉也不太合适,最开始的时候,是直接在 Start 的时候直接发起心跳,但是这样在后续多客户端同步的时候,会有很多 重复 Commit,因此做了一次调整,直接 Reset Raft 层的心跳为 10ms,这样如果有多客户端同时请求,可以合批到一次心跳。其次调整了 ApplyChannel 的大小为 1000,测试的时候发现有很多 Goroutine 卡在 Msg->ApplyChannel 上,因此通过调整该 Channel 的缓冲大小,提高消费速率。
- 在测试最开始的时候,一直以为 Raft 层不会重复 Commit 同一条 Log,后面调试打印日志时才发现有很多重复的 Log,重复的 Log 会影响消费效率,主要原因如下:
- 同一个 Req 重发 + leader 重新选举导致有重复 op
- 原来发心跳后,每同步成功一次(AppendEntries)就会检查能不能提交,假如有 5 个 server 都同步成功,那么 3,4,5 都会提交一次,raft 没有禁止重复提交
- Start 后会马上执行发心跳(为了 TestSpeed),有可能出现处理速度过快,两次 start 的 log 发了 2 次心跳,然后第一次还没提交(rf.lastApplied 未设置),后者也同步成功了,然后两次心跳都会执行一次提交,导致重复提交,因此后面调整成 Reset 心跳时长为 10ms。
1.4 测试结果
➜ kvraft git:(main) go test -race -run 3A && go test -race -run 3B Test: one client (3A) ... labgob warning: Decoding into a non-default variable/field Err may not work ... Passed -- 15.2 5 2904 572 Test: ops complete fast enough (3A) ... ... Passed -- 30.8 3 3283 0 Test: many clients (3A) ... ... Passed -- 15.7 5 2843 850 Test: unreliable net, many clients (3A) ... ... Passed -- 17.3 5 3128 576 Test: concurrent append to same key, unreliable (3A) ... ... Passed -- 1.6 3 152 52 Test: progress in majority (3A) ... ... Passed -- 0.8 5 76 2 Test: no progress in minority (3A) ... ... Passed -- 1.0 5 98 3 Test: completion after heal (3A) ... ... Passed -- 1.2 5 66 3 Test: partitions, one client (3A) ... ... Passed -- 22.9 5 2625 321 Test: partitions, many clients (3A) ... ... Passed -- 23.3 5 4342 691 Test: restarts, one client (3A) ... ... Passed -- 19.7 5 3229 564 Test: restarts, many clients (3A) ... ... Passed -- 21.3 5 4701 815 Test: unreliable net, restarts, many clients (3A) ... ... Passed -- 21.1 5 3670 611 Test: restarts, partitions, many clients (3A) ... ... Passed -- 27.2 5 3856 601 Test: unreliable net, restarts, partitions, many clients (3A) ... ... Passed -- 29.1 5 3427 384 Test: unreliable net, restarts, partitions, random keys, many clients (3A) ... ... Passed -- 33.4 7 7834 498 PASS ok 6.824/kvraft 283.329s
2. Part B: Key/value service with snapshots (hard)
该 Part 主要在前者的基础上,实现 Snapshot 的功能,通过检查 maxraftstate 检查是否需要 Snapshot,其实感觉该 Part 相对反而更简单一些。
2.1 分析
主要需要注意如下的点:
- Snapshot 的 Test case 主要检查 Raft 层的 Log 是否超标了,因此 DoSnapshot 的操作放在了
processMsg接口中判断,主要做两个事情,一个是检查 ApplyMsg 是否为 SnapshotMsg,另一个是判断当前persister.RaftStateSize是否超标了(大于maxraftstate) - 当从 ApplyChannel 中 Read 出来的 Msg 为 Snapshot 时,就直接采用 Snapshot 中的数据覆盖原生的数据即可
- 需要考虑将一些状态持久化,比如 Clerk 的 SeqId,防止重复执行。
2.2 实现
2.2.1 保存状态
这里主要需要注意持久化当前 KVServer 的状态,主要为 DB 数据和 Client 的 SeqId
func (kv *KVServer) saveKVState(index int) { w := new(bytes.Buffer) e := labgob.NewEncoder(w) cks := make(map[int64]int) for ckId, ck := range kv.messageMap { cks[ckId] = ck.seqId } e.Encode(cks) e.Encode(kv.dataSource) kv.rf.Snapshot(index, w.Bytes()) DPrintf("[KVServer-%d] Size=%d", kv.me, kv.persister.RaftStateSize()) }
2.2.2 检查是否需要 Snapshot
这里 /4 主要还是看到了 test case 中计算 size 时也做了除法,因此模拟了下。
func (kv *KVServer) needSnapshot() bool { return kv.persister.RaftStateSize()/4 >= kv.maxraftstate && kv.maxraftstate != -1 }
2.2.3 读取快照
读取快照的时机只有两处:
processMsg读到了 Snapshot Msg- 启动初始化 KVServer
func (kv *KVServer) readKVState(data []byte) { if data == nil || len(data) < 1 { // bootstrap without any state? return } DPrintf("[KVServer-%d] read size=%d", kv.me, len(data)) r := bytes.NewBuffer(data) d := labgob.NewDecoder(r) cks := make(map[int64]int) dataSource := make(map[string]string) //var commitIndex int if d.Decode(&cks) != nil || d.Decode(&dataSource) != nil { DPrintf("[readKVState] decode failed ...") } else { for ckId, seqId := range cks { kv.mu.Lock() ck := kv.GetCk(ckId) ck.seqId = seqId kv.mu.Unlock() } kv.mu.Lock() kv.dataSource = dataSource DPrintf("[KVServer-%d] readKVState messageMap=%v dataSource=%v", kv.me, kv.messageMap, kv.dataSource) kv.mu.Unlock() } }
2.3 注意点
2.4 测试结果
Test: InstallSnapshot RPC (3B) ... labgob warning: Decoding into a non-default variable/field Err may not work ... Passed -- 3.1 3 255 63 Test: snapshot size is reasonable (3B) ... ... Passed -- 13.4 3 2411 800 Test: ops complete fast enough (3B) ... ... Passed -- 17.0 3 3262 0 Test: restarts, snapshots, one client (3B) ... ... Passed -- 19.2 5 4655 788 Test: restarts, snapshots, many clients (3B) ... ... Passed -- 20.7 5 9280 4560 Test: unreliable net, snapshots, many clients (3B) ... ... Passed -- 17.6 5 3376 651 Test: unreliable net, restarts, snapshots, many clients (3B) ... ... Passed -- 21.5 5 3945 697 Test: unreliable net, restarts, partitions, snapshots, many clients (3B) ... ... Passed -- 28.3 5 3213 387 Test: unreliable net, restarts, partitions, snapshots, random keys, many clients (3B) ... ... Passed -- 31.4 7 7083 878 PASS ok 6.824/kvraft 173.344s
3. 小结
对比 lab2,这里新增了一些调试的方式:
- 新增了一个 healthCheck 的 Goroutine,当目标数据超过一定时间不更新时,直接 panic 检查所有 goroutine 的堆栈,需要在 go test 的最前面加上 GOTRACEBACK=1
- 后面 go test 加上 test.timeout 30s ,如果在指定时间内没有 pass,则会退出 test 并打印堆栈
上述的方式对于查询死锁等问题非常有效。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本