论文阅读: Shallow Semantic Parsing using Support Vector Machines
一、 摘要
目的: 用svm 做 浅层 semantic parsing
贡献: 加入了新feature和新分类器, 泛化更好
数据集: AQUAINT corpus
二、 介绍
浅层语义分析定义: 分析 who dit what to whom , when,where , how 。。。。etc
早期 : 利用tagging 的思想来解释
三、 semantic annotation and corpora
数据集结果选用propbank, 每个verb 被标注为ARG0 - ARG5 ,
ARG0 : PROTO-AGENT,动作主体
ARG1 : PROTO-PATIENT, 动作受体 等
训练集合 51000 句, 有13万成分
测试集合 2700句, 有7000成分
四、 问题定义
augument identification(成分获取):给定句法结构, 确定句子中每个部分的成分 (我的理解是类似于实体链指中的实体抽取, 就是确定是不是argument的候选)
argument classification(成分分类): 给定成分, 对成分进行分类
五、基线特征
predicate - predicate 自己用作特征
path - 句法路径, 应该是当前词-predicate 的路径, 组了个string
phrase type - 短语类型, NP 、 PP、 S等
position - 在 predicate 前还是后
voice - predicate 是否是主动词语
head word -
sub categorization - 联合predicate 和 其父节点组成的句法泛化成分
六、 训练
SVM 组多分类,
先训了一个NULL 、 NON-NULL的分类器(augument identification)
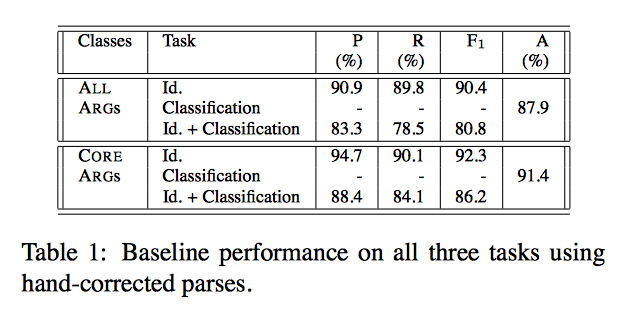
七、 基线效果
八 、 新feature
1. 实体信息
2. head word pos
3. verb clustering , 对verb 进行归纳(分为64类)
4. partial path , 保留最低节点的path
5. verb sense info- 动词消岐
6. head word of prep phrase
7. 短语开始结尾postag
等等, 不介绍了
九、 模型表现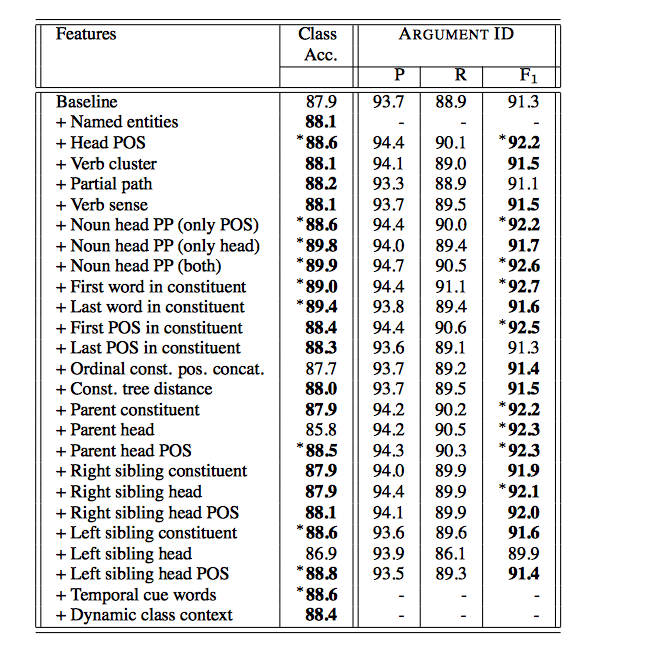
总结: 没啥总结的, 感觉方法都很基础, 实际泛化效果会下降20+个点, 主要是分析、和过拟合等问题导致的


 浙公网安备 33010602011771号
浙公网安备 33010602011771号