Configure Always On Availability Group for SQL Server on Ubuntu——Ubuntu上配置SQL Server Always On Availability Group
下面简单介绍一下如何在Ubuntu上一步一步创建一个SQL Server AG(Always On Availability Group),以及配置过程中遇到的坑的填充方法。
目前在Linux上可以搭建两种类型的SQL Server AG,一种是高可用性的结构同时使用Cluster服务器提供业务连续性。这种结构包括read-scale节点。接下来就会介绍这种AG的搭建方法。另外一种是没有Cluster服务的read-scale AG,这种结构仅仅提供只读的可扩展性,不提供高可用性功能。关于如何创建这种简单的AG请参考:Configure read-scale availability group for SQL Server on Linux。
另外在CREATE AVAILABILITY GROUP时可以指定CLUSTER TYPE:
- WSFC:Windows server failover cluster。这个是Windows系统上的默认值;
- EXTERNAL:非Windows server上的failover cluster,比如Linux上的Pacemaker;
- NONE:不包含cluster manager,指的是创建read-scale类型的Availability Group。
其中Linux可以使用EXTERNAL或NONE,我理解的是EXTENRAL功能就是类似目前SQL Server中的AG,NONE则是一种新类型,没有Cluster功能的不支持高可用性和灾难恢复的AG。主要作用是分担主服务器的负载,支持多个只读备用节点,同时这种类型也支持Windows上使用,是SQL Server 2017新支持的功能。更多详细的信息请参考这里:Read-scale availability groups。
接下来进入主题主要介绍一下高可用性结构的Availability Group的搭建方法。
1. 安装及配置SQL Server
一个SQL AG至少有两个以上的节点,由于环境有限,这里只安装一个最简单的包含两个节点的AG。首先是按照SQL Server on Ubuntu——Ubuntu上的SQL Server(全截图)中的介绍,安装两个Ubuntu机器和SQL Server。
Note:同一个AG的多个节点必须都是实体机或者虚拟机,当都是虚拟机的时候也必须都在同一个虚拟化平台上,原因是由于Linux需要用fencing agent去隔离节点上的资源,不同平台fencing agent类型是不同的,详细参考Policies for Guest Clusters。
2. 创建AG
在Linux上,必须先创建AG才能把它当成一个资源加到Cluster中进行管理。下面介绍一下如何创建AG。
a) 准备工作:
更新每一个节点服务器的机器名符合这个要求:15个字符或者更少;网络上是唯一的。如果不符合要求可以使用如下命令更改机器名:
sudo vi /etc/hostname
使用如下命令修改Hosts文件以保证同一个AG中多个节点可以互相通信:
sudo vi /etc/hosts
这里一定注意:修改后可以用ping命令尝试ping hostname,必须返回对应的真正IP地址才行,也就是Hosts文件中不能包含类似hostname和127.0.0.1的对应记录,配置后如下,注意其中”127.0.1.1 Ubuntu1604Bob2”这行被我注释了,否则开启Cluster 服务的时候可能会有问题:

如果不注释,ping hostname的返回结果是127.0.1.1,注释后返回的是真正IP:

需要返回真正IP后期配置才好使。
另外可以用这个命令查看当前server的IP:
sudo ip addr show
b) 在所有节点SQL Server上开启Always On Availability Group功能并重启服务:
sudo /opt/mssql/bin/mssql-conf set hadr.hadrenabled 1 sudo systemctl restart mssql-server
c) 在所有节点上执行SQL语句开启AlwaysOn_health事件会话以方便诊断问题:
ALTER EVENT SESSION AlwaysOn_health ON SERVER WITH (STARTUP_STATE=ON); GO
更多关于Event Session信息可以参考:AlwaysOn Extended Events。
d) 创建db mirroring endpoint使用的用户:
CREATE LOGIN dbm_login WITH PASSWORD = '**<Your Password>**'; CREATE USER dbm_user FOR LOGIN dbm_login;
e) 创建证书:
Linux上的SQL Server Mirroring Endpoint是用证书去认证通信的。下面的命令创建一个master key和证书并备份。连接到Primary端SQL Server并执行如下命令:
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '**<Master_Key_Password>**'; CREATE CERTIFICATE dbm_certificate WITH SUBJECT = 'dbm'; BACKUP CERTIFICATE dbm_certificate TO FILE = '/var/opt/mssql/data/dbm_certificate.cer' WITH PRIVATE KEY ( FILE = '/var/opt/mssql/data/dbm_certificate.pvk', ENCRYPTION BY PASSWORD = '**<Private_Key_Password>**' );
f) 把证书的备份复制到所有的非Primary节点上,同时使用它创建证书:
先在Primary节点上执行如下命令复制证书的备份到其它节点上:
cd /var/opt/mssql/data scp dbm_certificate.* root@**<node2>**:/var/opt/mssql/data/
Note:如果遇到Permission denied,可以使用sz和rz命令通过主机来传输文件。
再在目的端Secondary节点上执行如下命令给用户mssql添加足够的权限:
cd /var/opt/mssql/data chown mssql:mssql dbm_certificate.*
最后在目的端Secondary节点上利用备份的证书创建证书:
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '**<Master_Key_Password>**'; CREATE CERTIFICATE dbm_certificate AUTHORIZATION dbm_user FROM FILE = '/var/opt/mssql/data/dbm_certificate.cer' WITH PRIVATE KEY ( FILE = '/var/opt/mssql/data/dbm_certificate.pvk', DECRYPTION BY PASSWORD = '**<Private_Key_Password>**' );
g) 在所有节点上创建database mirroring endpoint:
CREATE ENDPOINT [Hadr_endpoint] AS TCP (LISTENER_IP = (0.0.0.0), LISTENER_PORT = **<5022>**) FOR DATA_MIRRORING ( ROLE = ALL, AUTHENTICATION = CERTIFICATE dbm_certificate, ENCRYPTION = REQUIRED ALGORITHM AES ); ALTER ENDPOINT [Hadr_endpoint] STATE = STARTED; GRANT CONNECT ON ENDPOINT::[Hadr_endpoint] TO [dbm_login];
Note:这里Listener IP暂时不能修改,只能是0.0.0.0,目前有BUG,未来可能会修复。
h) 在Primary节点上创建AG:
CREATE AVAILABILITY GROUP [UbuntuAG] WITH (DB_FAILOVER = ON, CLUSTER_TYPE = EXTERNAL) FOR REPLICA ON N'**<node1>**' WITH ( ENDPOINT_URL = N'tcp://**<node1>**:**<5022>**', AVAILABILITY_MODE = SYNCHRONOUS_COMMIT, FAILOVER_MODE = EXTERNAL, SEEDING_MODE = AUTOMATIC ), N'**<node2>**' WITH ( ENDPOINT_URL = N'tcp://**<node2>**:**<5022>**', AVAILABILITY_MODE = SYNCHRONOUS_COMMIT, FAILOVER_MODE = EXTERNAL, SEEDING_MODE = AUTOMATIC ); ALTER AVAILABILITY GROUP [UbuntuAG] GRANT CREATE ANY DATABASE;
Note:执行过程中可能会出现这个警告”Attempt to access non-existent or uninitialized availability group with ID”,暂时忽略即可,未来版本可能会修复。
下图中UbuntuAG2是新创建的AG,Secondary节点还处于OFFLINE状态:
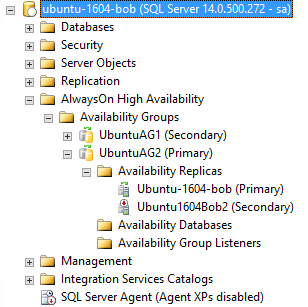
i) 把其它Secondary节点加入到AG中:
ALTER AVAILABILITY GROUP [UbuntuAG] JOIN WITH (CLUSTER_TYPE = EXTERNAL); ALTER AVAILABILITY GROUP [UbuntuAG] GRANT CREATE ANY DATABASE;
下图为添加完节点后的状态:
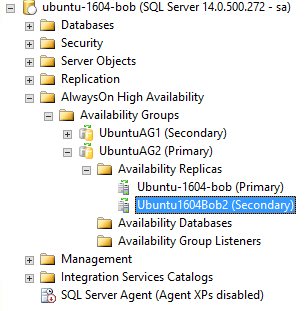
j) 测试:创建一个DB并加入到刚刚创建的AG中:
CREATE DATABASE [db1]; ALTER DATABASE [db1] SET RECOVERY FULL; BACKUP DATABASE [db1] TO DISK = N'var/opt/mssql/data/db1.bak'; ALTER AVAILABILITY GROUP [UbuntuAG] ADD DATABASE [db1];
k) 验证:在Secondary端查看DB是否已经成功同步过去了:
SELECT * FROM sys.databases WHERE name = 'db1'; GO SELECT DB_NAME(database_id) AS 'database', synchronization_state_desc FROM sys.dm_hadr_database_replica_states;
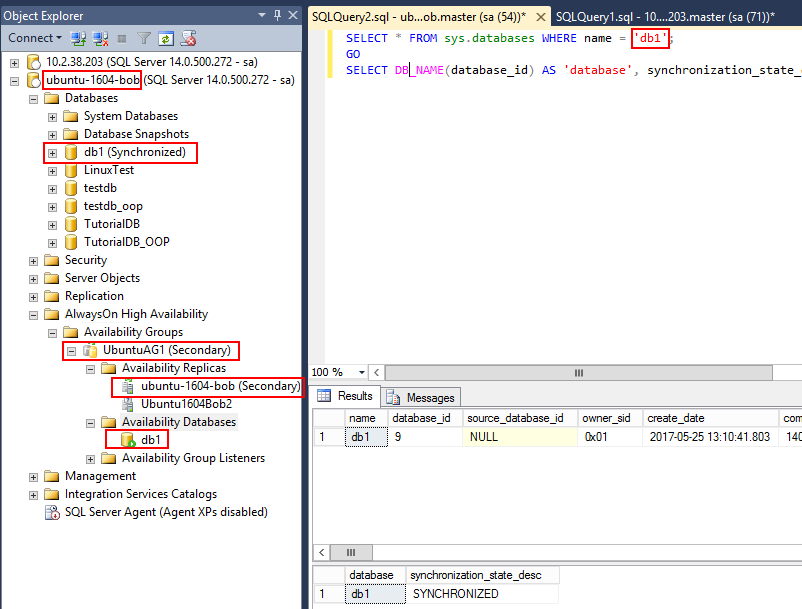
这时,一个简单的AG就创建好了,但是它不能提供高可用性和灾难恢复功能,必须配置一个Cluster技术才能好使。如果上述h)和i)步骤的TSQL更换成以下两个,则创建出来的就是read-scale类型的AG。
- 创建AG命令:
CREATE AVAILABILITY GROUP [UbuntuAG] WITH (CLUSTER_TYPE = NONE) FOR REPLICA ON N'**<node1>**' WITH ( ENDPOINT_URL = N'tcp://**<node1>**:**<5022>**', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, FAILOVER_MODE = MANUAL, SEEDING_MODE = AUTOMATIC, SECONDARY_ROLE (ALLOW_CONNECTIONS = ALL) ), N'**<node2>**' WITH ( ENDPOINT_URL = N'tcp://**<node2>**:**<5022>**', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, FAILOVER_MODE = MANUAL, SEEDING_MODE = AUTOMATIC, SECONDARY_ROLE (ALLOW_CONNECTIONS = ALL) ); ALTER AVAILABILITY GROUP [UbuntuAG] GRANT CREATE ANY DATABASE;
把Secondary节点加到AG中命令:
ALTER AVAILABILITY GROUP [UbuntuAG] JOIN WITH (CLUSTER_TYPE = NONE); ALTER AVAILABILITY GROUP [UbuntuAG] GRANT CREATE ANY DATABASE;
Note:这时的AG是没有Listener的,目前版本也暂时无法创建Listener。
3. 配置一个集群资源管理器,如Pacemaker
具体步骤如下:
a) 在所有的Cluster节点上安装和配置Pacemaker:
先设置防火墙允许相关端口通过(包括Pacemaker high-availability service、SQL Server Instance和Availability Group Endpoint),
sudo ufw allow 2224/tcp sudo ufw allow 3121/tcp sudo ufw allow 21064/tcp sudo ufw allow 5405/udp sudo ufw allow 1433/tcp # Replace with TDS endpoint sudo ufw allow 5022/tcp # Replace with DATA_MIRRORING endpoint sudo ufw reload
或者也可以直接禁用防火墙:
sudo ufw disable
在所有节点上安装Pacemaker软件包:
sudo apt-get install pacemaker pcs fence-agents resource-agents
设置Pacemaker和Corosync软件包在安装时创建的默认用户的密码,需保证所有节点上密码一样:
sudo passwd hacluster
b) 启用并开启pcsd和Pacemaker服务:
sudo systemctl enable pcsd sudo systemctl start pcsd sudo systemctl enable pacemaker
执行过程中可能出现这个错误”pacemaker Default-Start contains no runlevels, aborting.”,可以暂时忽略。
c) 创建Cluster并启动:
首先为了防止有Cluster的残余配置文件影响后期搭建,可以先执行如下命令删除已经存在的Cluster:
sudo pcs cluster destroy # On all nodes sudo systemctl enable pacemaker
然后创建并配置Cluster:
sudo pcs cluster auth **<nodeName1>** **<nodeName2>** -u hacluster -p **<password for hacluster>** sudo pcs cluster setup --name **<clusterName>** **<nodeName1>** **<nodeName2…>** sudo pcs cluster start --all
这时可能会出现这个错误”Job for corosync.service failed because the control process exited with error code. See "systemctl status corosync.service" and "journalctl -xe" for details.”诊断解决方法如下:
- 根据2-a)中的描述查看是否有问题;
- 使用如下命令查看配置文件中的Log路径是什么。
vi /etc/corosync/corosync.conf
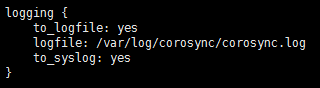
- 查看相关文件是否存在,如不存在,则创建相关文件,假设上图中logfile路径为/var/log/cluster/corosync.log同时该文件还不存在,则执行如下命令,
sudo mkdir /var/log/cluster sudo chmod 777 /var/log/cluster sudo echo >> /var/log/cluster/corosync.log
d) 配置隔离:STONITH。目前测试环境为了简单,暂时不配置了,以后会更新。正常来说生产环境需要一个fencing agent去隔离资源,关于支持信息请参考这里:Support Policies for RHEL High Availability Clusters - Virtualization Platforms。
另外我们这里先执行以下命令禁用隔离:
sudo pcs property set stonith-enabled=false
e) 设置start-failure-is-fatal为false:
pcs property set start-failure-is-fatal=false
默认值是true,当为true的时候,如果Cluster第一次启动资源失败,在自动Failover操作后,需要用户手动清空资源启动失败的数量记录,使用这个命令重置资源配置:
pcs resource cleanup <resourceName>
4. 添加AG到Cluster集群中
具体步骤如下:
a) 在所有节点上安装与Pacemaker集成的SQL Server资源包:
sudo apt-get install mssql-server-ha
b) 在所有节点上创建Pacemaker用的SQL Server登录用户:
USE [master] GO CREATE LOGIN [pacemakerLogin] with PASSWORD= N'<Your Password>' ALTER SERVER ROLE [sysadmin] ADD MEMBER [pacemakerLogin]
也可以不给sysadmin权限,给上如下足够的权限即可:
GRANT ALTER, CONTROL, VIEW DEFINITION ON AVAILABILITY GROUP::UbuntuAG TO pacemakerLogin
c) 在所有节点上,保存SQL Server Login的信息:
echo 'pacemakerLogin' >> ~/pacemaker-passwd echo '<Your Password>' >> ~/pacemaker-passwd sudo mv ~/pacemaker-passwd /var/opt/mssql/secrets/passwd sudo chown root:root /var/opt/mssql/secrets/passwd sudo chmod 400 /var/opt/mssql/secrets/passwd # Only readable by root
d) 在Cluster中Primary节点上创建AG的资源:
sudo pcs resource create ag_cluster ocf:mssql:ag ag_name=UbuntuAG --master meta notify=true
e) 在Cluster中Primary节点上创建虚拟IP资源:
sudo pcs resource create virtualip ocf:heartbeat:IPaddr2 ip=**<10.2.38.204>**
f) 配置Cluster资源的依赖关系和启动顺序:
sudo pcs constraint colocation add virtualip ag_cluster-master INFINITY with-rsc-role=Master sudo pcs constraint order promote ag_cluster-master then start virtualip
g) 最后查看Cluster状态如下:
sudo pcs status
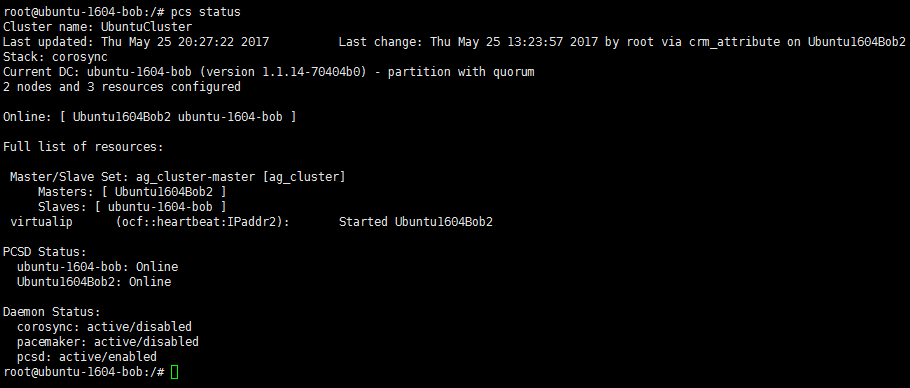
可以用虚拟IP(10.2.38.204)访问这个AG:
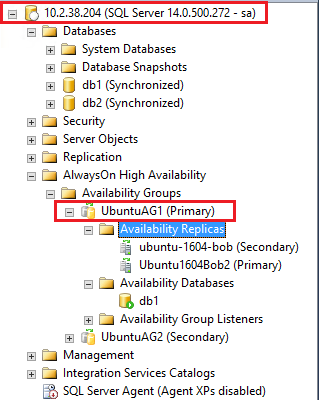
至此,Ubuntu上的Cluster管理的SQL Server Always On Availability Group就搭建完成了。
Note:
- 当把AG加入到Cluster中作为一个资源的时候,就不能再使用TSQL去failover AG了。SQL Server服务端是不知道Cluster的存在的,整个系统是通过Linux Cluster来控制的,在Ubuntu和RHEL中用pcs命令,在SLES中用crm命令。
- 全部配置完成后,可以使用虚拟IP去访问整个AG,这时可以在DNS中手动注册一个Listener名字指向这个虚拟IP,就可以当成Windows中的AG Listener使用了。
- SQL Server 2017 CTP 1.4中新引入了一个sequence_number的概念防止数据丢失,详细参考Understand SQL Server resource agent for pacemaker(https://docs.microsoft.com/en-us/sql/linux/sql-server-linux-availability-group-cluster-ubuntu)。
参考链接:
- Configure Always On availability group for SQL Server on Linux
- Configure Ubuntu Cluster and Availability Group Resource
- Configure read-scale availability group for SQL Server on Linux
- Overview of Always On Availability Groups (SQL Server)
本文主要介绍了如何配置AG以及如何解决配置过程中遇到的问题,关于AG的管理使用上以后再详细介绍,如有错误或者介绍不够,敬请见谅。
[原创文章,转载请注明出处,仅供学习研究之用,如有错误请留言,如喜欢请推荐,谢谢支持]
[原文:http://www.cnblogs.com/lavender000/p/6906280.html,来自永远薰薰]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号