[code] Transformer For Summarization Source Code Reading [3]
1. Label Smoothing
对于分类问题,我们希望模型输出的标签上概率分布,逼近于真实标签的one-hot representation。带来的问题是:
- 无法保证泛化
- one-hot表示鼓励将真实类别和其他类别之间的差距尽可能拉大,造成模型过分相信预测的类别
论文 When Does Label Smoothing Help? 中对label smoothing的数学描述:

- (多标签)交叉熵损失公式不变,源码中也有利用KL散度作为损失函数的,实际上最小化两种损失函数是等价的(多了一个常量,熵)
- 通常是利用真实y的one-hot representation与预测y的概率分布进行交叉熵计算;label smoothing用smooth过的y,与预测y的概率分布进行交叉熵计算
- 常引入uniform distribution作为u(k),进行label smoothing
引入一个与分布无关的u(k),可由先验概率充当,可以是均匀分布:

其中有两步操作:
- 确定真实标签的Dirac分布,以及分布u(k)
- 以(1-epsilon),epsilon分别作为两者的权重进行加权求和
对应代码实现:
def label_smoothing(inputs, epsilon=0.1):
K = inputs.get_shape().as_list()[-1] # number of labels
return ((1-epsilon) * inputs) + (epsilon / K)
效果就是,将原本one-hot的表示变得不那么绝对化,分出了一些概率给其他标签,留个模型泛化的空间。由于其主要的作用是防止过拟合,在过拟合严重的训练情况下,可以考虑加入label smoothing
2. Copy Mechanism
本实现中用到的copy mechanism与类似论文 Get To The Point: Summarization with Pointer-Generator Networks 一致。
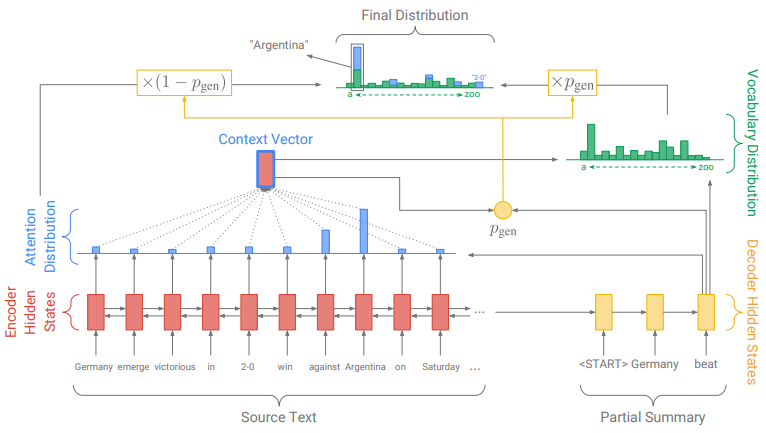
Copy mechanism的流程:
-
copy-mode:利用当前时间步的decoder-encoder attention weight来计算input article word list上概率分布的
-
generate-mode:利用decoder hidden states、decoder input、decoder-encoder context三者,来计算fixed vocabulary上的概率分布
-
gate:用于选择上述两种模式,利用decoder hidden states、decoder input、decoder-encoder context三者,来计算当前选择generate-mode的概率
-
计算联合概率(如下图):
![]()
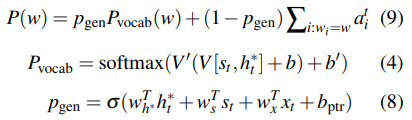
单词的属性有如下几种:
- fixed vocabulary V
- input word list X
- OOV (X - V)
- extended vocabulary X + V
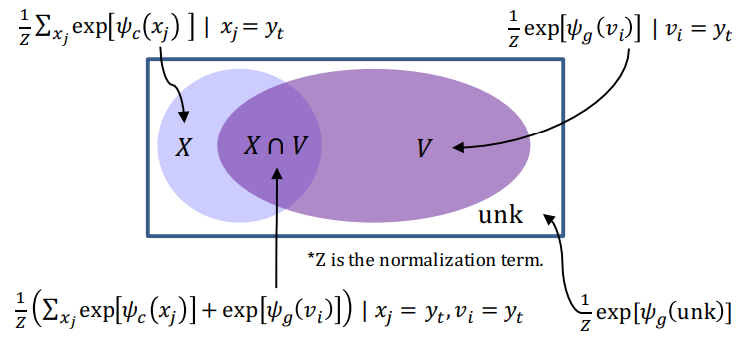
从上图可以看出如何计算单词的概率分布:
X中单词的概率由copy mode计算(乘上权重),V中单词的概率由generate-mode计算(乘上权重),X∩V中的单词的概率是两种模式下的概率的加权和。其中权重由另外一个神经网络计算得到gate。
原本我们只能得到fixed vocabulary中单词的概率分布,现在得到extend vocabulary上的概率分布(并且由于输入不同,X是动态的)。我们就可以解码输出在固定词表中没有出现,但是在输入此表中出现过的单词。
如果在解码的时候,从X中拷贝了一个单词y,但是是属于X-V集合中,即OOV单词。因为只有V中的单词有embedding,所以y单词并没有embedding,那么下一时刻的解码输入应该如何处理?参考李丕绩前辈的实现:
next_y = []
for e in last_traces:
eid = e[-1].item()
if eid in modules["i2w"]:
next_y.append(eid)
else:
next_y.append(modules["lfw_emb"]) # unk for copy mechanism
如果当前解码时刻的输出是从input word list中拷贝出来的OOV word的数,那么下一时刻的解码输入,就是
3. Recurrent Decoder?
在没有看Transformer在sequence generation任务上的具体实现的时候,一直好奇Decoder如果也是auto-regressive的话,那么是不是也是recurrent的?
在进行解码的时候(training 阶段使用teacher forcing,inference逐词输出),每次解码一个单词。在copy(pointer-generator network)机制下,当前decoder的输入如下:
y_pred, attn_dist = model.decode(ys, tile_x_mask, None, tile_word_emb, tile_padding_mask, tile_x, max_ext_len)
def decode(self, inp, mask_x, mask_y, src, src_padding_mask, xids=None, max_ext_len=None):
pass
可以看出decoder的输入对应关系:
-
解码输入就是[seq_len, beam_width],其中seq_len是beam search已经得到的部分解码序列的长度
-
不对input_y进行mask,计算attention的时候,考虑全部的input_y序列中的元素;故mask_y=None
-
src 是 tile_word_emb,输入序列的embedding,[max_x_len, beam_width, embedding_dim]
-
src_padding_mask 是 tile_padding_mask,[max_x_len, beam_width]
-
xid 是 tile_x,[max_x_len, beam_width]
x = torch.tensor([1, 2, 3]) x.shape Out[7]: torch.Size([3]) x.repeat(4,2).shape Out[8]: torch.Size([4, 6]) x.repeat(4,2,1).shape Out[9]: torch.Size([4, 2, 3])torch.Tensor.repeat函数,可以将指定维度进行复制。x的维度为[dx_0],
x.repeat(dy_3, dy_2, dy_1, dy_0),需要先进行unsequeeze操作,将x的维度数目拓展到与repeat函数中的参数数目相同。再对应每个维度进行repeat。
decoder内部需要进行基于解码输入的self-attention,以及基于编码输出的external attention,输出有二:
- y_dec 解码器的解码输出,形状为 [seq_y_len, beam_width, vocab_size]。
通过y_pred = y_pred[-1, :, :],取最后一个隐含状态作为当前的解码输出。 - attn_dist 是 word_prob_layer 计算出的,external attention的注意力权重,形状为 [seq_y_len, beam_width, max_x_len]
* Beam Search的Inference阶段,按照batch读取数据,进行编码,但是按照每个样本分别进行解码
In a nutshell,这不算recurrent,但还是auto-regressive的解码模式。recurrent指的是,当前时刻的解码,接受来自上一时刻的隐含状态。而Transformer decoder在解码每一个词的时候,不仅考虑了前一个词,还考虑了之前已经生成了的所有单词,并且利用其进行self-attention计算。
4. 参考资料
posted on 2019-07-24 13:31 LAUSpectrum 阅读(429) 评论(0) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号