

Python
解释性语言和编译性语言:
| 解释性语言和编译型语言 | ||
| 解释性语言 | 编译型语言 | |
| 概念 |
计算机不能直接的理解高级语言,只能直接理解机器语言,所以必须要把高级语言翻译成机器语言,计算机才能执行高级语言的编写的程序。 翻译的方式有两种,一个是编译,一个是解释。两种方式只是翻译的时间不同。 |
|
| 特征 |
解释性语言是指它常用的执行机制是使用一个“解释器”来执行,解释器对于程序是一句一句“翻译”成机器语言来一句一句执行,例如shell脚本语言。 Java、JavaScript、VBScript、Perl、Python、Ruby、Matlab |
编译型语言是指它常用的执行机制是使用一个“编译器”来编译成机器语言,然后你就可以直接运行(执行)这个编译成的“可执行文件”。 C/C++,Pascal/Object Pascal(Delphi) |
| 区别 | 不管是解释性语言还是编译型都可编译或解释,前提是有这样的编译器或解释器(比如你自己写一个),找不到这样的编译器你当然不能编译对于语言本身来说,各种编程语言本质没什么不同。所谓的“解释性”和“编译”指的是执行机制上的不同。 | |
__new__和__init__的主要区别在于:1.__new__是用来创造一个类的实例的(constructor),而__init__是用来初始化一个实例的(initializer)。 2.__init__不能有返回值__new__函数直接上可以返回别的类的实例。
python中的pass作用:在python中有时候能看到定义一个def函数,函数内容部分填写为pass。这里的pass主要作用就是占据位置,让代码整体完整。如果定义一个函数里面为空,那么就会报错,当你还没想清楚函数内部内容,就可以用pass来进行填坑。
引用所指判断 引用计数器机制:利用引用计数器方法,在检测到对象引用个数为0时,对普通的对象进行释放内存的机制
通过is进行引用所指判断,is是用来判断两个引用所指的对象是否相同。查看对象的引用计数:导入sys模块,sys.getrefcount()
整数
In [46]: a=1 In [47]: b=1 In [48]: print(a is b) True
短字符串
In [49]: c="good" In [50]: d="good" In [51]: print(c is d) True
长字符串
In [52]: e="very good" In [53]: f="very good" In [54]: print(e is f) False
列表
In [55]: g=[] In [56]: h=[] In [57]: print(g is h) False
由运行结果可知:
1、Python缓存了整数和短字符串,因此每个对象在内存中只存有一份,引用所指对象就是相同的,即使使用赋值语句,也只是创造新的引用,而不是对象本身;
2、Python没有缓存长字符串、列表及其他对象,可以由多个相同的对象,可以使用赋值语句创建出新的对象。
id方法:
In [35]: id(var2) Out[35]: 139697863383968
PS:id()是python的内置函数,用于返回对象的身份,即对象的内存地址。
增加引用个数的情况:1.对象被创建p = Person(),增加1; 2.对象被引用p1 = p,增加1; 3.对象被当作参数传入函数func(object),增加2,原因是函数中有两个属性在引用该对象; 4.对象存储到容器对象中l = [p],增加1
减少引用个数的情况:1.对象的别名被销毁del p,减少1; 2.对象的别名被赋予其他对象,减少1; 3.对象离开自己的作用域,如getrefcount(对象)方法,每次用完后,其对对象的那个引用就会被销毁,减少1; 4.对象从容器对象中删除,或者容器对象被销毁,减少1
垃圾回收:
1、垃圾回收时,Python不能进行其它的任务,频繁的垃圾回收将大大降低Python的工作效率;
2、Python只会在特定条件下,自动启动垃圾回收(垃圾对象少就没必要回收)
3、当Python运行时,会记录其中分配对象(object allocation)和取消分配对象(object deallocation)的次数。当两者的差值高于某个阈值时,垃圾回收才会启动。
何为分代回收?
Python将所有的对象分为0,1,2三代;
所有的新建对象都是0代对象;
当某一代对象经历过垃圾回收,依然存活,就被归入下一代对象。
In [93]: import gc In [94]: gc.get_threshold() #gc模块中查看阈值的方法 Out[94]: (700, 10, 10)
阈值分析:
700即是垃圾回收启动的阈值;
每10次0代垃圾回收,会配合1次1代的垃圾回收;而每10次1代的垃圾回收,才会有1次的2代垃圾回收;
当然也是可以手动启动垃圾回收: In [95]: gc.collect() #手动启动垃圾回收 Out[95]: 2
“静态类型”语言要求必须在变量定义时指定其类型,例如C、C++、Java、C#和Go等。
而动态类型语言中尽管也有类型的概念,但变量的类型是动态的。
a = 1
a = "foo"
在这个例子中,Python用相同的名字和str类型定义了第二个变量,同时释放了第一个a的实例占用的内存。
静态类型语言的设计目的并不是折磨人,这样设计是因为CPU就是这样工作的。如果任何操作最终都要转化成简单的二进制操作,那就需要将对象和类型都转换成低级数据结构。
python中常见的几种错误:
print默认是打印一行,结尾加换行。end=’ ‘意思是末尾不换行,加空格。
注:取消缩进 (👆+tab)
PyCharm的环境准备:https://www.bilibili.com/read/cv10380167/
这三种工具有什么差别呢?这是很多自学一段时间的同学依然很困惑的问题。这三种工具,对于刚接触pycharm的,选择Virtualenv就可以了。
基础版Virtualenv:Virtualenv本身是一款Python工具,具有Python所必须的依赖库,用于创建独立的Python虚拟环境,方便管理不同版本的python模块。零基础就选它。
加强版pipenv:讲到第二个选项pipenv,就要讲到pip,pip是个很长的故事,足够单独做一个专栏了,立个flag,后面做专栏。这里就用一句话,“Pip是早期Python官方推荐的包安装工具”。但这个工具对于包的版本和迁移非常不方便。pipenv可以说是virtualenv和pip的结合体,它不但会自动为你的项目创建和管理virtualenv(就是第一个选项),而且在安装/卸载软件包时通过Pipfile文件自动添加/删除软件包。所以对于管理包来说是非常好用的。pipenv我后面也会单独做一个专栏深度剖析(再立一个flag,这么多flag,不要打脸啊。)
但暂时作为初入门的人来说东西有点多,短时间是用不上的,所以不用纠结,不要选它。
专业版conda:第三个选项是conda,conda非常强大,conda是一个不仅支持Python,它还支持C或C ++库,R等许多语言的软件包、依赖库和环境管理的工具。
如果你选择conda的话,项目文件夹会在.conda下面,同时你还可以用Anaconda的非常受欢迎的数据科学、机器学习和AI框架的软件包。
当然PyPI上的150,000多个软件包是conda所不能比的。所以也有人把conda和pip这两个结合起来用。这个暂时也不适用于新手,也不选。
python的条件语句:https://www.runoob.com/python/python-if-statement.html
and和or:

数据结构:
列表的一般用法:
TypeError: can only concatenate str (not "list") to str

转化成str类型:
list1 = ['frui','male',1989,'python',[2016,2017],'c'] #list内元素的数据类型可以不同,也可以是另外一个list list2 = [''] print ('全部打印') print (list1) #使用下标索引来访问列表中的值,同样你也可以使用方括号的形式截取字符,如下所示: print ('全部打印') print (list1[:]) print (list1[0],list1[1]) print ('倒数第一个,第二个'+list1[-1],list1[-2]) print ('前三个' +str(list1[0:3])) #切片,此操作顾头不顾尾 print ('前三个'+str(list1[:3])) print (list1[-3:])#倒数三个 print (list1[0:-1:2]) #按步长切片 print (list1[::2]) #按步长切片 list1.append("linux") #在列表末尾追加元素 list1.insert(1,"linux") #直接把元素插入的指定位置 print (list1[:]) list1[0] = "jay" #(改)直接替换某个位置元素 print (list1[:]) #delete list1.pop() #删除list末尾的元素 list1.pop(1) #删除指定位置的元素 del list1[0] list1.remove("python") print (list1) print (list1.index(1989)) #查找已知元素的索引 print (list1[list1.index(1989)]) print (list1.count(1989)) #打印某元素在列表中的数量 list1.clear() #清除整个列表 list1.reverse() #反转整个列表 list1.sort() #排序 按ASCII码顺序排序,若元素中有list类型,则无法排序 list2 = [1,2,3,4] list1.extend(list2) #列表合并 print (list1) del list2 #删除整个变量 #列表的深浅copy #浅拷贝只能拷贝最外层,修改内层则原列表和新列表都会变化。 #深拷贝是指将原列表完全克隆一份新的。 import copy list1 = ['frui','male',1989,'python',[2016,2017],'c'] list2 = list1.copy() #浅copy list3 = copy.copy(list1) #浅copy,同list1.copy()效果相同 list4 = copy.deepcopy(list1) #深copy,会和list1占用同样大小的内存空间 list1[0] = '自由' list1[4][0] = 2015 print (list1,'\n',list2,'\n',list3,'\n',list4) #列表的循环:逐个打印列表元素 list1 = ['frui','male',1989,'python',[2016,2017],'c'] for i in list1: print (i)
元组
元组也是存一组数据,只是一旦创建,便不能修改,所以又叫只读列表。元组创建很简单,只需要在括号中添加元素,并使用逗号隔开即可。元组中的值不可删除,可以用del 删除整个元素
tup1 = (1,2,3,4,5) tup2 = ('frui', 27) tup3 = "a", "b", "c", "d"; tup4 = () #创建空元组 元组中只包含一个元素时,需要在元素后面添加逗号 tuple5 = (50,) #元组中只包含一个元素时,需要在元素后面添加逗号 tuple6 = (50) #如果不加逗号,则定义的不是tuple,是50这个数!这是因为括号()既可以表示tuple,又可以表示数学公式中的小括号,这就产生了歧义,因此,Python规定,这种情况下,按小括号进行计算。
元组只有两个方法:count()出现次数 和 index()位置
不可变的tuple有什么意义?因为tuple不可变,所以代码更安全。如果可能,能用tuple代替list就尽量用tuple。
com(tuple1,tup2) max(tuple1) min(tuple1) len(tuple) tuple(seq)将列表转换为元组
字典
3.1 字典的使用
字典是另一种可变容器模型,且可存储任意类型对象。
字典的每个键值对()用冒号(:)分割,每个对之间用逗号(,)分割,整个字典包括在花括号({})中 ,格式如下所示:
d = {key1 : value1, key2 : value2 }
键必须是唯一的,但值则不必。值可以取任何数据类型,但键必须是不可变的,如字符串,数字或元组。
info = { 'stu1':"Xiao Ming", 'stu2':"Xiao Liang", 'stu3':"Xiao Hong", 'stu4':"Xiao Rui", } print (info) #修改 info['stu2'] = "Xiao Hu" #增加 info['stu5'] = "Xiao Fang" #删除 info.pop('stu2') del info['stu1'] info.popitem() #随机删一个 print (info) info.clear() #清空字典所有条目 #查找 print ('stu2' in info) #判断是否存在,存在则返回True,否则返回False print (info['stu1']) #如果一个key不存在,就报错,get不会,不存在只返回None #dict.get(key, default=None) #返回指定键的值,如果值不在字典中返回default值 #比较安全的查找方法 print (info.get('stu6')) #其他 print (info.values()) #打印所有的值(即除了key) print (info.keys()) #打印所有的key print (info.items()) #把字典转化为列表 # dict.setdefault(key, default=None) # 和get()类似, 但如果键不存在于字典中,将会添加键并将值设为default info.setdefault ('class3',{'Xiao Rui', 15}) print (info) info.setdefault ('class1',{'Xiao Hong', 16}) print (info) #循环打印 for i in info: print (i,info[i]) for k,v in info.items(): print (k, v) #多级字典嵌套及操作 info = { 'class1':{ 'stu1':["Xiao Ming",16] }, 'class2':{ 'stu2':["Xiao Liang",17] } } info['class1']['stu1'][1] = 18 print (info) #dict.fromkeys(seq[, val])) # 创建一个新字典,以序列 seq 中元素做字典的键,val 为字典所有键对应的初始值 eg: print (dict.fromkeys([6,7,8],'test')) c = dict.fromkeys([6,7,8],[1,{'name':'frui'}]) c[6][1]['name'] = 'sorui' print (c) #update方法 info = { 'stu1':"Xiao Ming", 'stu2':"Xiao Liang", 'stu3':"Xiao Hong", 'stu4':"Xiao Rui", } b = { 'stu1': "Xiao Dong", 1:3, 2:4 } print (info) info.update(b)
集合
#去重 list1 = [3,2,1,4,5,6,5,4,3,2,1] print (list1, type(list1)) list1 = set(list1) print (list1, type(list1)) list2 = set([4,5,6,7,8,9]) #交集 print (list1.intersection(list2)) #并集 print (list1.union(list2)) #差集 print (list1.difference(list2)) print (list2.difference(list1)) #子集、父集 print (list1.issubset(list2)) print (list1.issuperset(list2)) list3 = set([4,5,6]) print (list3.issubset(list2)) print (list2.issuperset(list3)) #对称差集 print (list1.symmetric_difference(list2)) #Return True if two sets have a null intersection list4 = set([1,2,3]) print (list3.isdisjoint(list4)) #交集 print (list1 & list2) #union print (list2 | list1) #difference print (list1 - list2) #对称差集 print (list1 ^ list2) #添加 list1.add(999) #添加一项 print (list1) list1.update([66,77,88]) #添加多项 print (list1) print (list1.add(999)) #猜猜打印什么?为什么 #删除 list1.remove(999) print (list1) #remove and return arbitrary set element print (list1.pop()) #Remove an element from a set if it is a member.If the element is not a member, do nothing. print (list1.discard(888))
python中面向对象三大特征的体现:
1.封装:
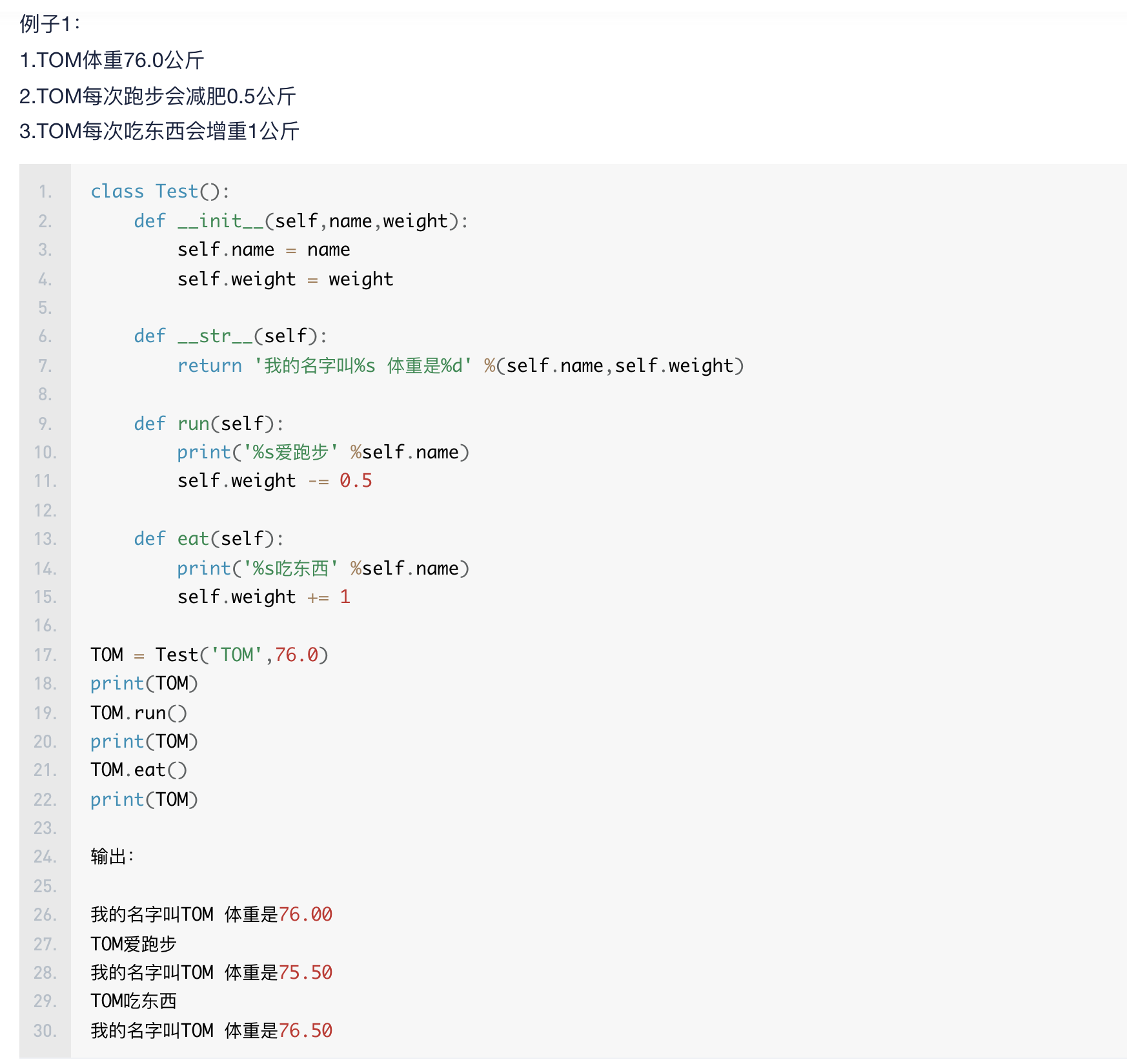
set方法:

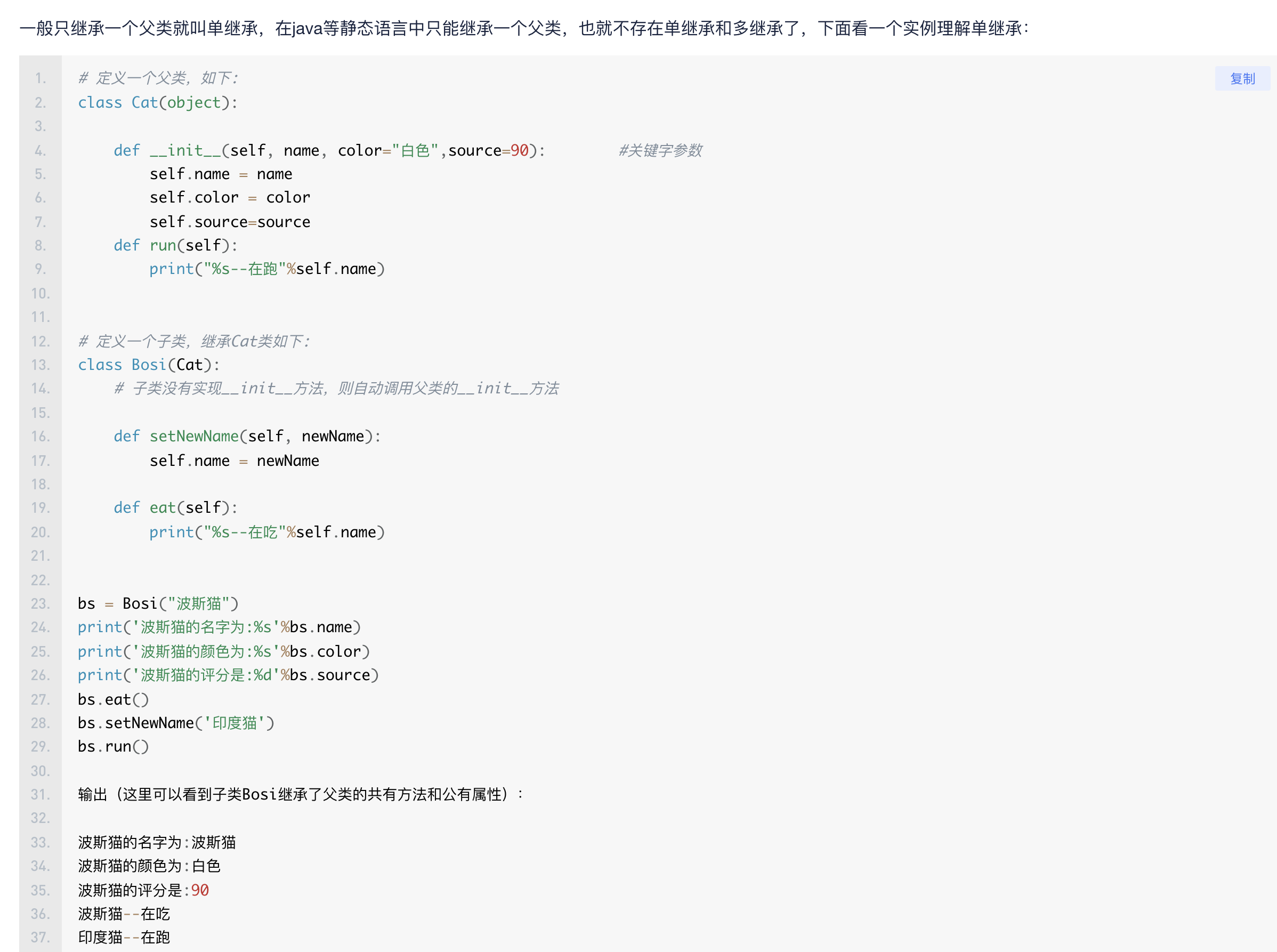
2.继承
单继承:
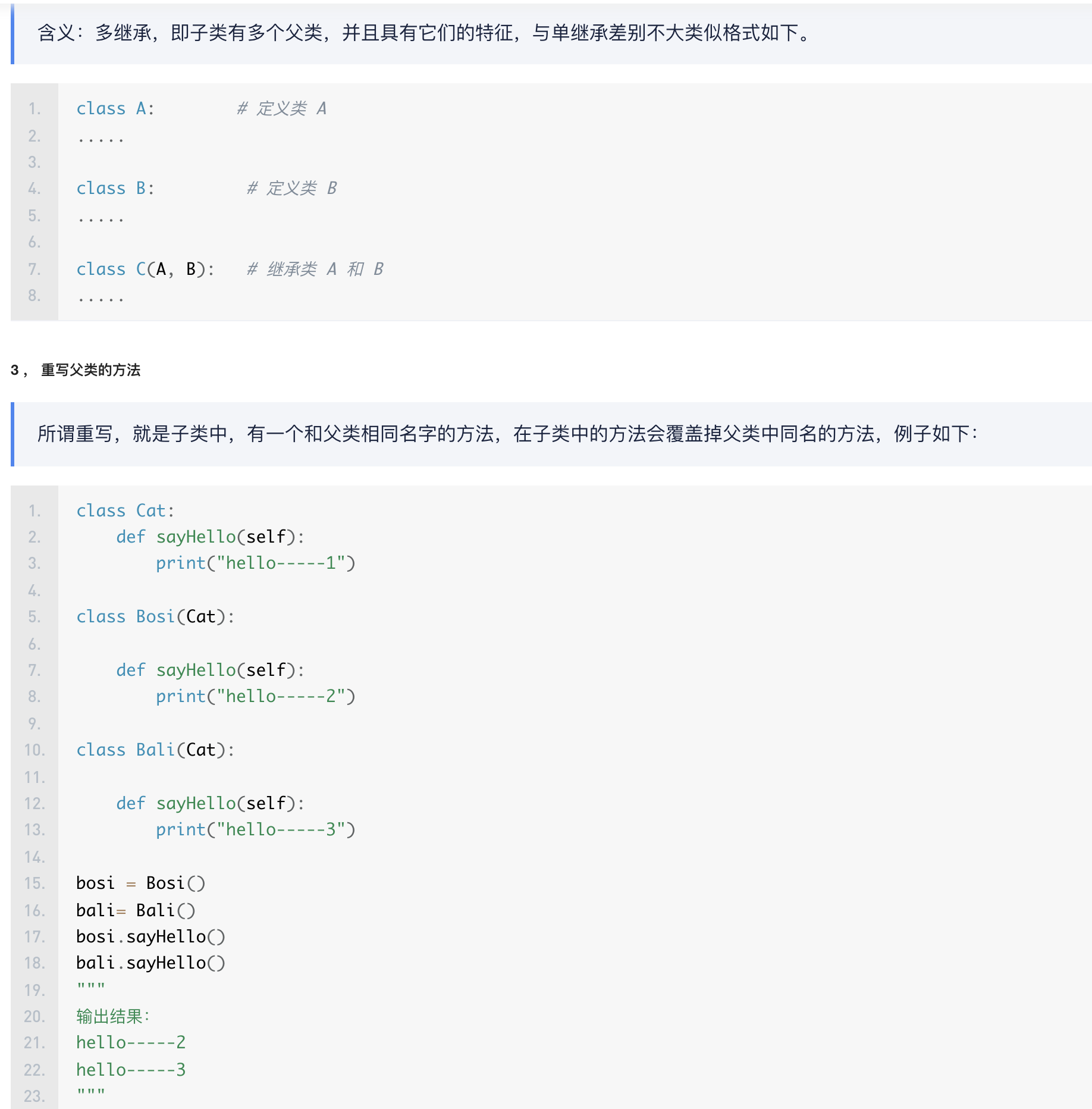
多继承:
多态:

Web框架:Django https://blog.51cto.com/u_15077548/4199893
