

线程池
为什么要线程池
多线程目的是用来最大化的发挥多核处理器的处理能力。但是线程是不能无限的进行创建,当线程创建数量比较多时,反而会消耗CPU和内存资源
- 线程的创建和销毁是需要时间的。加入一个服务完成需要的时间:T1表示创建线程时间,T2表示线程执行任务的耗时,T3表示线程消耗的时间,如果:T1+T3远大于T2,得不偿失
- 线程需要占用内存资源,大量线程的创建会占用宝贵内存资源,可以导致OOM(Out Of Memory)异常
- 大量的线程回收时也会给GC操作带来很大的压力,延长GC的停顿时间
- 线程抢占CPU资源,CPU不停的在各个线程中进行上下文切换,上下文的切换也是耗时的过程
多线程的创建不仅耗时,也占用资源,基于其缺陷提供了线程池的解决方案
什么是线程池
线程池就是事先创建若干个可执行的线程放入一个池中(容器),有任务需要执行时就从池中获取空闲的线程,任务执行完成后将线程放回池,而不用关闭线程,可以减少创建和销毁线程对象的开销,避免了频繁的创建和销毁线程,让创建的线程达到复用的目的,线程池的内部维护一部分活跃的线程,如果有需要就从线程中取线程使用,用完归还到线程池,线程池对线程的数量是有一定的限制。
线程池的本质就是使用了一个线程安全的工作队列连接工作者线程和客户端线程,客户端线程将任务放入工作队列后便返回,而工作者线程则不断地从工作队列上取出工作并执行。当工作队列为空时,所有的工作者线程均等待在工作队列上,当有客户端提交了一个任务之后会通知任意一个工作者线程,随着大量的任务被提交,更多的工作者线程会被唤醒。
本质是对线程资源的复用
线程池的优势
- 降低资源的消耗:通过复用已经创建的线程降低线程创建和销毁的消耗
- 提高响应速度:当任务到达时,任务直接从线程池中获取到一个线程就能立即执行
- 提高线程的可管理性:线程资源的管理,提高系统的稳定性
- 线程池可以进行统一的分配、调度和监控等功能
ThreadPoolExecutor类
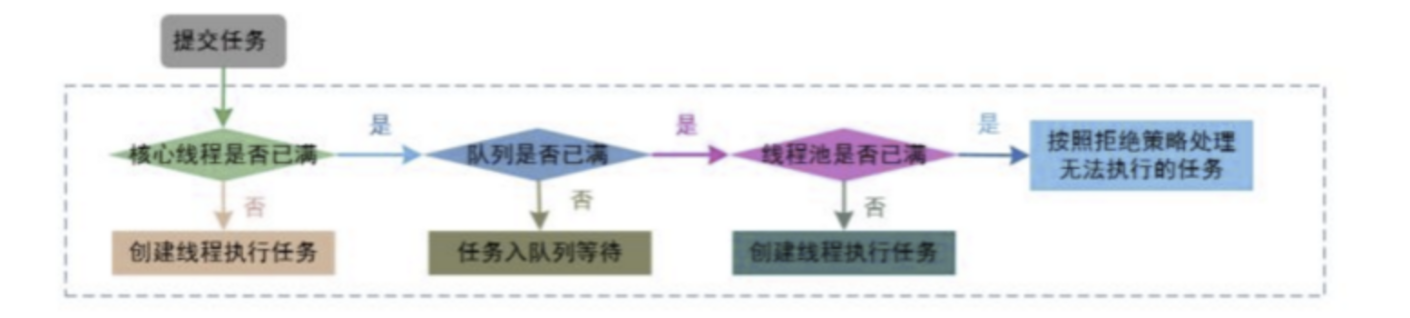
任务提交执行的步骤:
1、提交任务时,如果线程池中线程数量小于corePoolSize,即使线程池有空闲的线程不会执行,直接创建新的线程来执行提交的任务
2、如果线程池中线程数量大于等于corePoolSize,队列未满时,新任务的提交添加到任务队列workQueue,等待线程池中有空闲线程来执行
3、如果线程池线程数量大于等于corePoolSize,并且阻塞队列已满,当前线程池中线程数量小于maxinumPoolSize,创建新的线程来执行任务体
4、当线程池的线程数量大于maxinumPoolSize,新任务提交时就会执行拒绝策略
构造器中各个参数的含义:
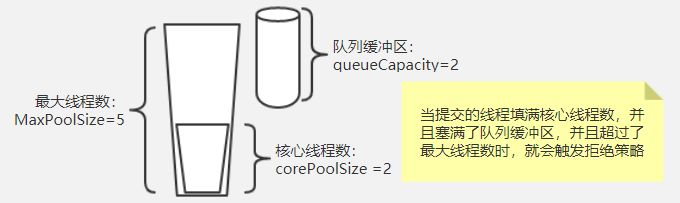
- corePoolSize:核心池的大小,这个参数跟后面讲述的线程池的实现原理有非常大的关系。在创建了线程池后,默认情况下,线程池中并没有任何线程,而是等待有任务到来才创建线程去执行任务,除非调用了prestartAllCoreThreads()或者prestartCoreThread()方法,从这2个方法的名字就可以看出,是预创建线程的意思,即在没有任务到来之前就创建corePoolSize个线程或者一个线程。默认情况下,在创建了线程池后,线程池中的线程数为0,当有任务来之后,就会创建一个线程去执行任务,当线程池中的线程数目达到corePoolSize后,就会把到达的任务放到缓存队列当中;
- maximumPoolSize:线程池最大线程数,这个参数也是一个非常重要的参数,它表示在线程池中最多能创建多少个线程;
- keepAliveTime:表示线程没有任务执行时最多保持多久时间会终止。默认情况下,只有当线程池中的线程数大于corePoolSize时,keepAliveTime才会起作用,直到线程池中的线程数不大于corePoolSize,即当线程池中的线程数大于corePoolSize时,如果一个线程空闲的时间达到keepAliveTime,则会终止,直到线程池中的线程数不超过corePoolSize。但是如果调用了allowCoreThreadTimeOut(boolean)方法,在线程池中的线程数不大于corePoolSize时,keepAliveTime参数也会起作用,直到线程池中的线程数为0;
- unit:参数keepAliveTime的时间单位
方法:
当创建线程池后,初始时,线程池处于RUNNING状态;
如果调用了shutdown()方法,则线程池处于SHUTDOWN状态,此时线程池不能够接受新的任务,它会等待所有任务执行完毕;
如果调用了shutdownNow()方法,则线程池处于STOP状态,此时线程池不能接受新的任务,并且会去尝试终止正在执行的任务;
当线程池处于SHUTDOWN或STOP状态,并且所有工作线程已经销毁,任务缓存队列已经清空或执行结束后,线程池被设置为TERMINATED状态。
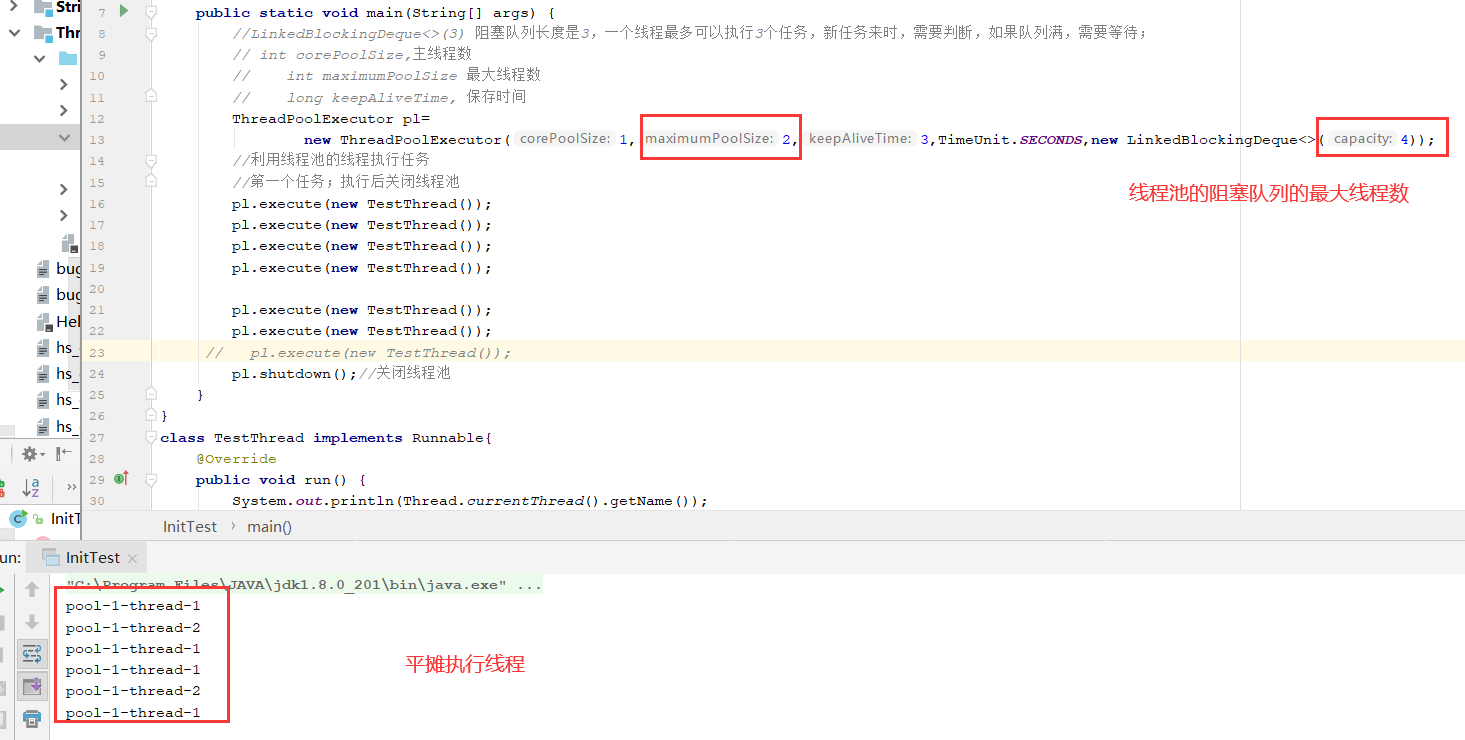
当线程池的线程数量大于maxinumPoolSize
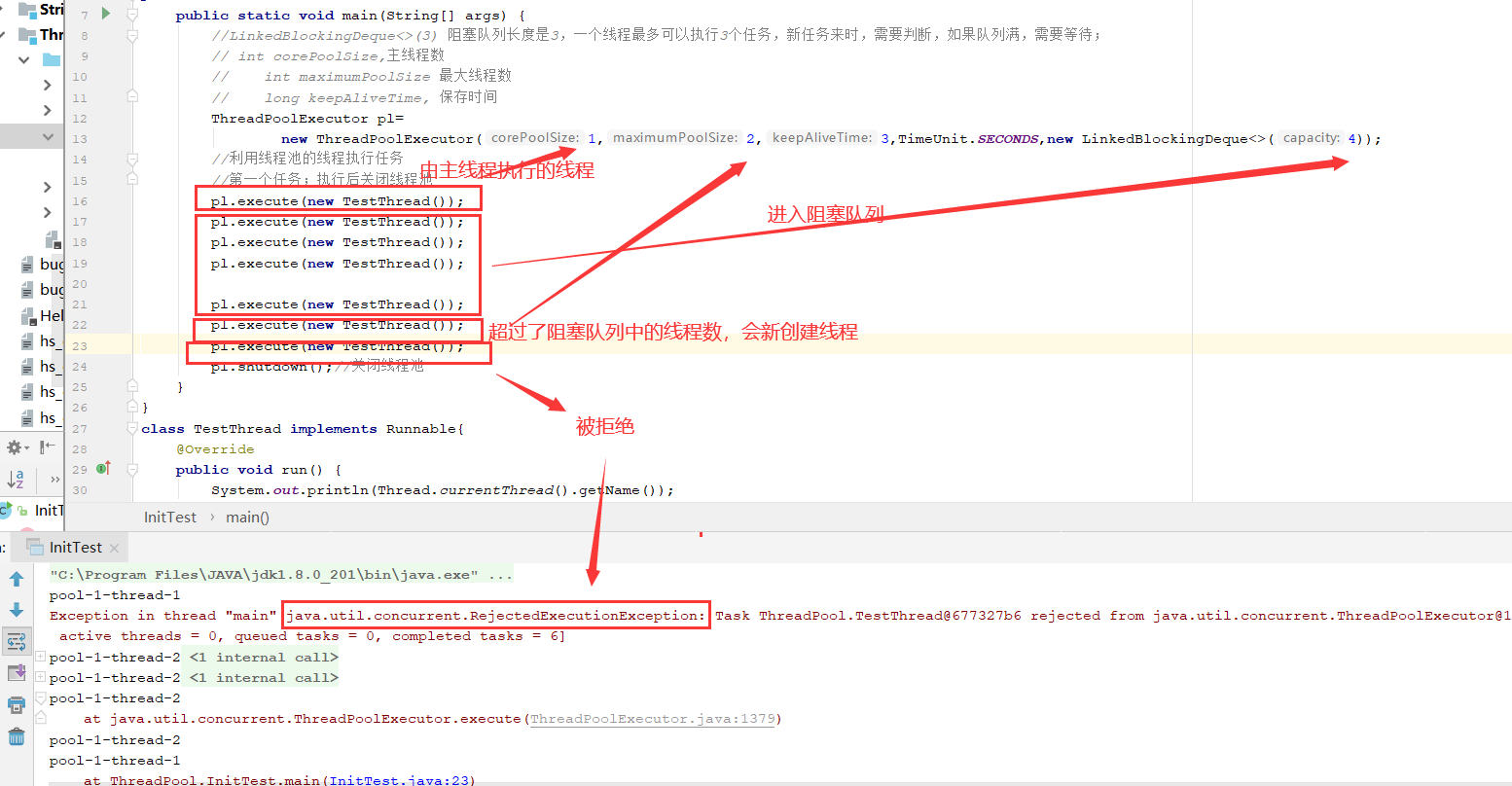
任务缓存队列及排队策略
在前面我们多次提到了任务缓存队列,即workQueue,它用来存放等待执行的任务。
workQueue的类型为BlockingQueue<Runnable>,通常可以取下面三种类型:
1)ArrayBlockingQueue:基于数组的先进先出队列,此队列创建时必须指定大小;
2)LinkedBlockingQueue:基于链表的先进先出队列,如果创建时没有指定此队列大小,则默认为Integer.MAX_VALUE;
3)synchronousQueue:这个队列比较特殊,它不会保存提交的任务,而是将直接新建一个线程来执行新来的任务。
任务拒绝策略
当线程池的任务缓存队列已满并且线程池中的线程数目达到maximumPoolSize,如果还有任务到来就会采取任务拒绝策略,通常有以下四种策略
ThreadPoolExecutor.AbortPolicy:丢弃任务并抛出RejectedExecutionException异常。
ThreadPoolExecutor.DiscardPolicy:也是丢弃任务,但是不抛出异常。
ThreadPoolExecutor.DiscardOldestPolicy:丢弃队列最前面的任务,然后重新尝试执行任务(重复此过程) ThreadPoolExecutor.CallerRunsPolicy:由调用线程处理该任务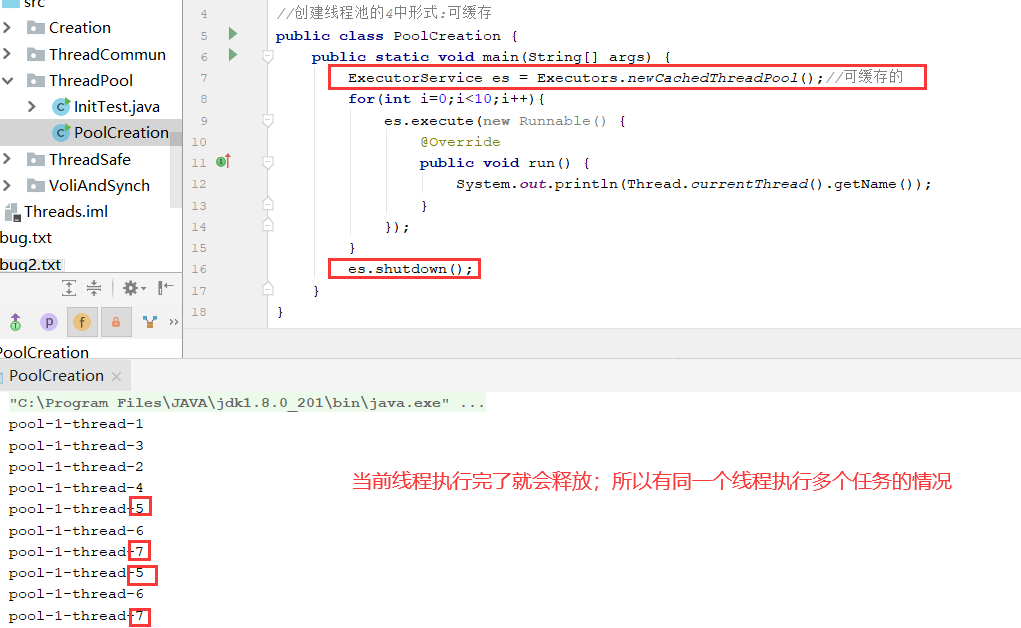
public static ExecutorService newCachedThreadPool() { return new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60L, TimeUnit.SECONDS, new SynchronousQueue<Runnable>()); }
一个不存储元素的阻塞队列。
2.定长(核心线程数定)
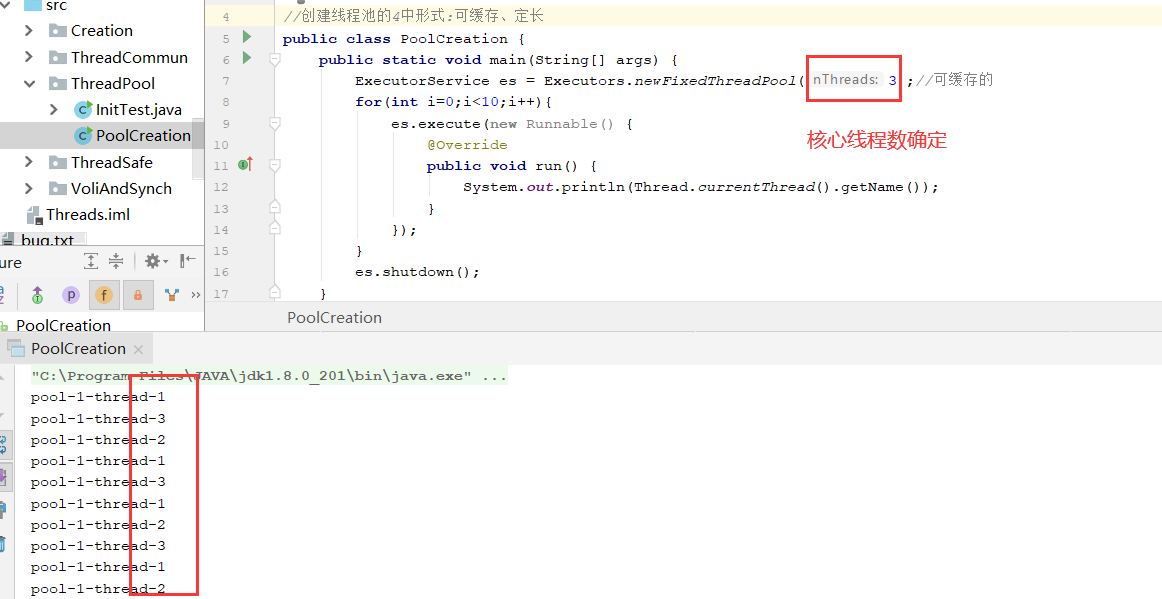
public static ExecutorService newFixedThreadPool(int nThreads) { return new ThreadPoolExecutor(nThreads, nThreads, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>()); }
基于链表实现的一个有界阻塞队列,内部维持着一个数据缓冲队列(该队列由链表构成),此队列按照先进先出的原则对元素进行排序。
3.定时
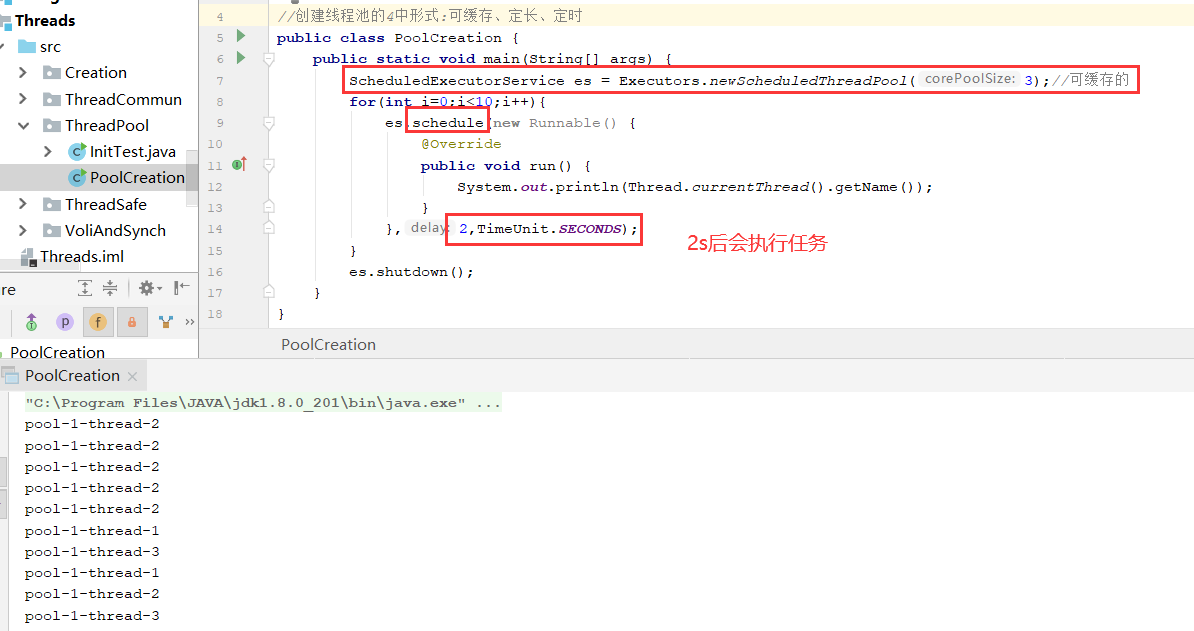
public ScheduledThreadPoolExecutor(int corePoolSize) { super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS, new DelayedWorkQueue()); }
一种支持延时的获取元素的无界阻塞队列,DelayQueue中的元素只有当其指定的延迟时间到了,才能够从队列中获取到该元素。DelayQueue也是一个无界队列
4.单例:只有一个线程执行
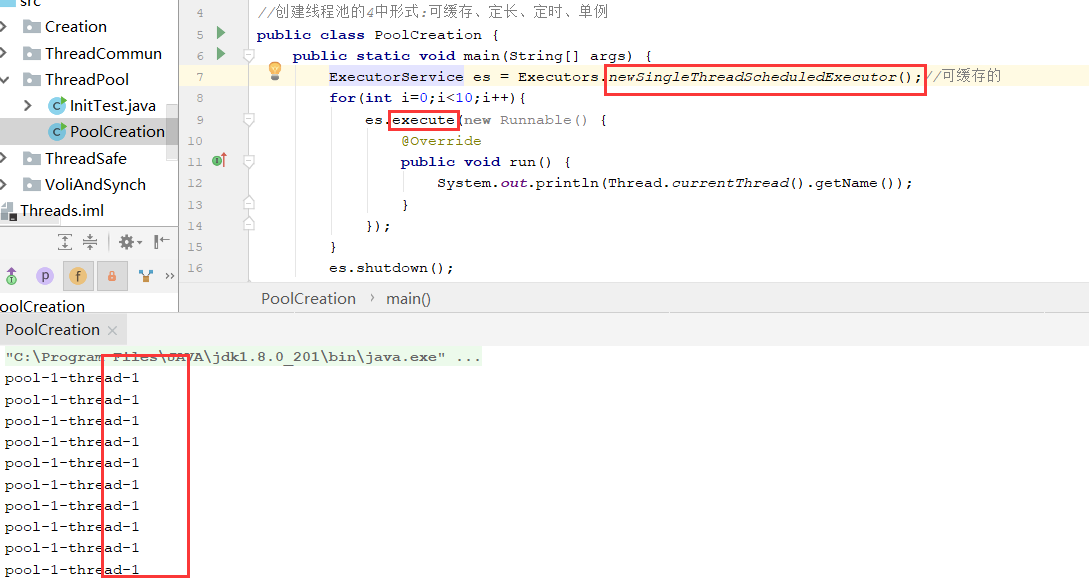
核心线程和最大线程数都是1;
public static ScheduledExecutorService newSingleThreadScheduledExecutor() { return new DelegatedScheduledExecutorService (new ScheduledThreadPoolExecutor(1)); } public ScheduledThreadPoolExecutor(int corePoolSize) { super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS, new DelayedWorkQueue()); }
三种常见阻塞队列:
ArrayBlockingQueue:基于数组实现的有界阻塞队列
LinkedBlockingQueue:基于链表实现的无界阻塞队列
SynchronousQueue:同步阻塞队列
ArrayBlockingQueue的阻塞队列实现是基于数组实现,内部使用个一个ReentrantkLock锁和两个Condition实例,通过ReentrantkLock实现线程安全的操作,两个Condition用来进行添加/删除的则塞和唤醒的通知;
LinkedBlockQueue的实现有两个ReentrantLock和两个Condition,LinkedBlockQueue底层结构为链表,采用的头尾节点,每一个节点执行下一个节点,数据都存储在node中
引入了两个锁,一个是入队列锁,一个是出队列锁(两把锁的原因?出队和入队可以并发处理);
SynchronousQueue同步队列:每个插入数据操作必须等待另一个移除操作,队列中最多只能有一个元素,快速的传递元素的一种实现方式
