
Oracle从入门到精通 限定查询和排序查询的问题
视频课程:李兴华 Oracle从入门到精通视频课程
学习者:阳光罗诺
视频来源:51CTO学院
知识点
- SQL语句的执行顺序
- 限定符号的使用。
具体内容:
如果想要对所选择的数据进行控制,就可以使用WHERE子句来完成,此时的语法结构为:
【③选出所需要的数据列】SELECT [DISTINCT] * 列[别名],列[别名],列[别名]······
【①确定数据来源】FROM 表名称 [别名]
【②筛选数据行】[WHERE 限定条件] 此时的条件可以是多个语法结构。
语法结构的执行顺序都是先执行FROM,其次就是WHERE,最后才是SELECT。SELECT子句在整个语法结构中是最后才会被执行到的子句。但是如果要进行数据的筛选,必须使用若干个条件判断符
关系运算:>、=、<、>=、<=、!=(<>)
范围运算:BETWEEN······AND
空判断:IS NULL、IS NOTNULL
IN判断:IN、NOT IN、exists()【复杂查询】
模糊查询:LIKE、NOT LIKE
这对于以上的限定符都只能够判断一次,如果现在有若干个限定符,就需要进行若干个限定符的连接,可以使用逻辑运算符。
逻辑运算符:
AND(与):与操作表示的所有的判断条件都满足时才返回真(true)
OR(或):或操作表示的若干个判断条件只要有一个满足就返回真(true)
NOT(非):表示两者都是FALSE,所以返回的时候,就是true。
以上的这些判断符号,都是SQL中的标准支持。其他的不同的数据库可能有自己的数据库扩充的内容。
关系运算符
关系运算符主要时进行大小的判断。
范例:查询工资低于1200的雇员(不包含1200)。
语法格式:
1 SELECT *
3 FROM emp
5 WHERE sal<1200;
此时的结果如下:
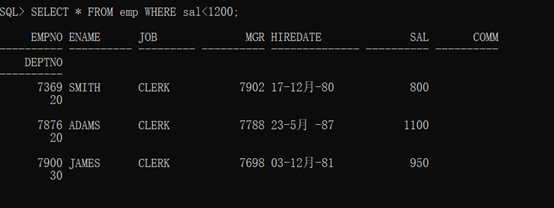
此时的数据行中的内容是有所减少。
范例:查询工资是3000的雇员
语法格式:
1 SELECT *
2 FROM emp
3 WHERE sal=3000;
查询结果如下:
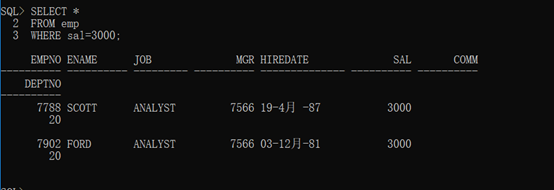
但是对于等号“=”而言,有一点需要注意,除了可以在数字上使用之外。在字符串的使用也是可以的。
范例:查询smith的雇员信息
语法格式:
SELECT * FROM emp WHERE ename=‘smith’;
查询结果如下:
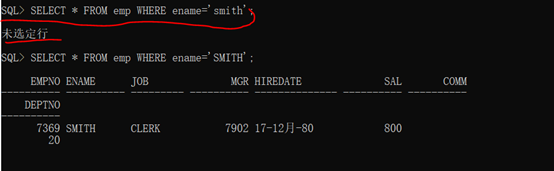
此时一定要注意的内容就是我画红线的部分的内容,在Oracle数据库中,数据都是区分大小写的。数据库不会自动转化大小写。
对于不等于的判断有两个符号:!=、<>。
范例:查询职位不是办事员的雇员(职位是JOB字段、办事员的职位名称CLERK)
语法格式:
SELECT * FROM emp WHERE JOB<>’CLERK’;
SELECT * FROM emp WHERE JOB!=’CLERK’;
逻辑运算
逻辑运算可以保证连接多个条件,如果要连接主要使用的是AND和OR两种来完成。
范例:要求查询出不是办事员,但是工资低于3000的雇员信息。
分析:第一个条件是:不是办事员,JOB<>’CLERK’
第二个条件是:工资低于3000,sal<3000
语法格式:
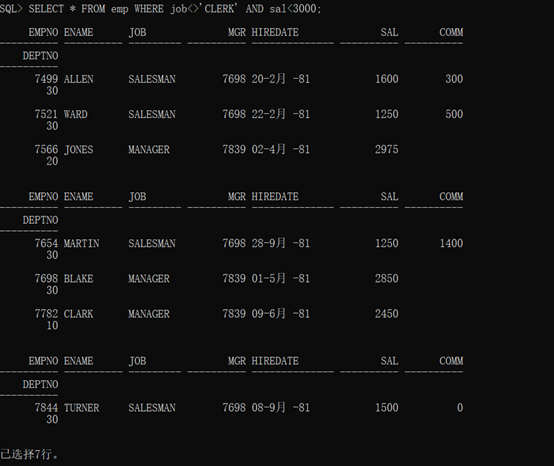
1 SELECT * FROM emp WHERE job<>’CLERK’ AND sal<3000;
查询结果如下:
范例:查询出职位不是办事员也不是销售的雇员信息。
分析:要同时两个结果都要满足,所以就使用AND来连接。
第一个条件:job<>‘CLERK’
第二个条件:job<>’SALESMAN’
语法格式:
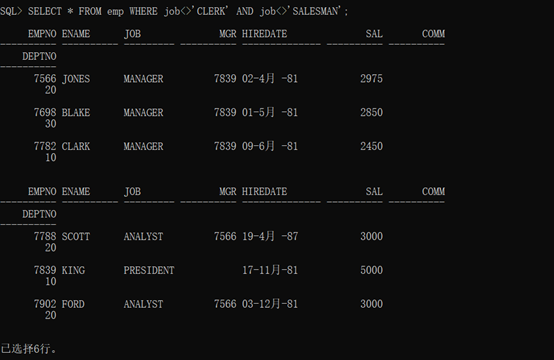
1 SELECT * FROM emp WHERE job<>’CLERK’ AND job<>’SALESMAN’;
查询结果如下:
范例:查询出职位是办事员或者是工资低于1200的所有雇员。
分析:由于要满足其中之一,所以就只能使用OR来连接。
第一个条件:job=’CLERK’
第二个条件:sal<1200
语法格式:
1 SELECT * FROM emp WHERE job=’CLERK’ OR sal<1200;
查询结果如下所示:

执行条件越多,那么速度就会越慢,数据优化就成为了公司必备的内容。
除了AND和OR之外,我们还可以使用NOT来进行求反。即:TRUE变为FALSE、FALSE变为TRUE
范例:观察NOT的变化
语法格式:
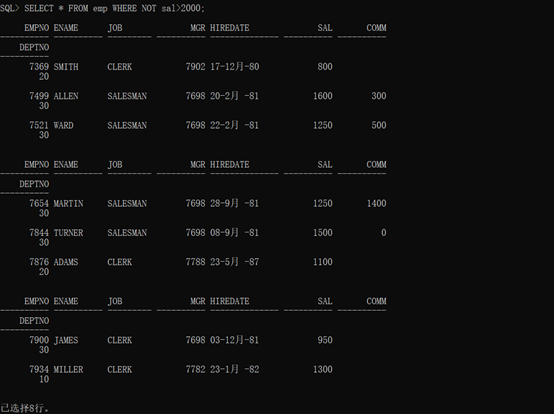
1 SELECT * FROM emp WHERE NOT sal>2000;
查询结果如图:
范围运算:BETWEEN···AND···
BETWEEN···AND···主要是进行范围的查询。
语法格式:
WHERE 字段|数值 BETWEEN 最小值 AND 最大值
范例: 查询出工资在1500~3000之间的所有雇员。
第一种实现方式:使用关系运算和逻辑运算一起来实现
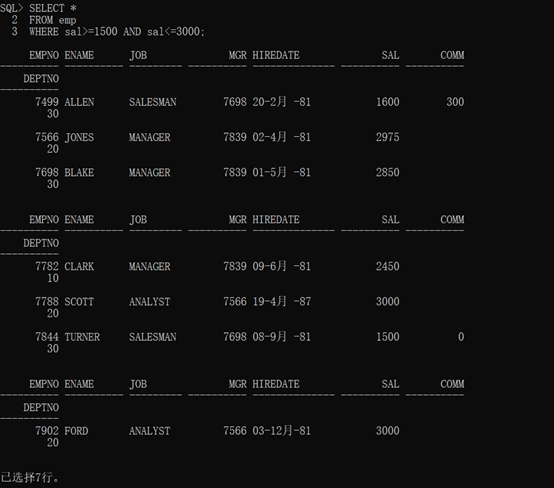
1 SELECT *
2
3 FROM emp
4
5 WHERE sal>=1500 AND sal<=3000;
第二种实现方式:使用BETWEEN···AND···查询
1 SELECT *
2
3 FROM emp
4
5 WHERE sal BETWEEN 1500 AND 3000;

使用BETWEEN···AND···是一个运算符,而且使用关系和逻辑的组合是属于两个运算符,自然效率会更好、更高。【性能优化】
在Oracle中你的所有运算符都是不受数据类型的控制,在之前使用的是数字进行了判断,那么除了数字之外,可以使用字符串或者是日期进行判断。字符串的意义不大,重点看日期的判断。
范例:查询出所有在1981年雇佣的雇员信息。
· 范围:1981-01-01~1981-12-31
语法格式:
1 SELECT *
2
3 FROM emp
4
5 WHERE hiredate BETWEEN '01-1月-81' AND '31-12月-1981';
查询结果如下:

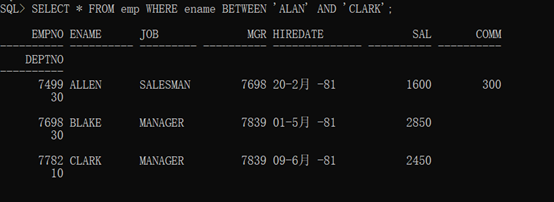
范例:查询字符串的范围
1 SELECT * FROM emp WHERE ename BETWEEN 'ALAN' AND 'CLARK';
查询结果如下:
空判断
Null从数据库定义上来讲属于一个未知的数据,在任何情况下,如果一个数字与null进行计算,那么结果依然是未知Null。
语法格式:
1 SELECT NULL+1 FROM emp;
结果如下:
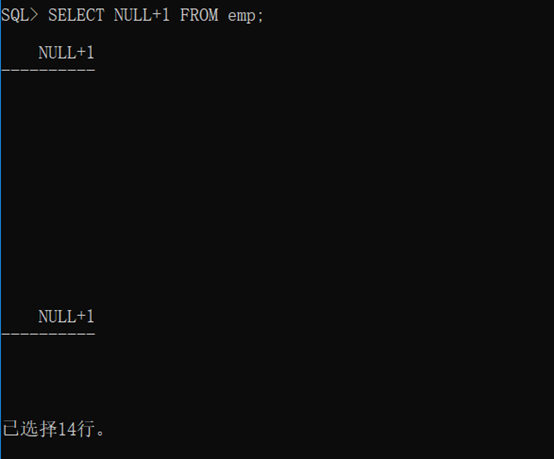
查询结果全是空的。
在某些数据列上是允许存在有null值得存在,但是对于null不能使用关系运算符判断。
关系判断的是数据,null值不是空的字符串也不是数字0,所以在SQL、之中能够通过IS NULL 来判断为空,以及IS NOT NULL(NOT字段 IS NULL)判断不为空。
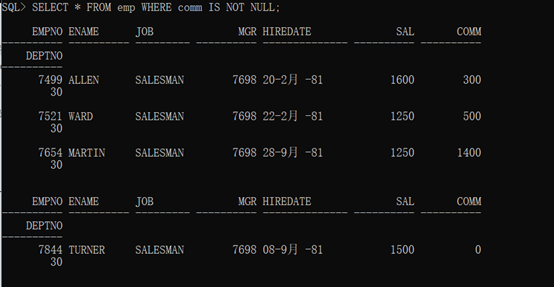
范例:查询出所有领取佣金的雇员信息。(comm字段表示的是佣金,如果领取,则comm的内容不是null)
语法格式:
1 SELECT * FROM emp WHERE comm IS NOT NULL;
查询结果:
IN操作符(谓词IN)
IN指的是根据一个指定的的范围进行数据的查询。
范例:查询出雇员编号是7369、7566、7788、9999的雇员信息。
- 利用关系运算符进行操作:
语法格式:
1 SELECT * FROM emp WHERE empno=7369 OR empno=7566 OR empno=7788 OR empno=9999;
查询结果如下:

此时并没有雇员9999,所以最终的内容只返回了3行数据。此种方式的代码执行了四次,这种方式在很多性能优化是很差的。所以在对指定数据范围的时候就可以使用IN操作符。
范例:利用IN操作符
语法格式:
1 SELECT * FROM emp WHERE empno IN (7369,7566,7788,9999);

查询结果上是没有差别的,只是在执行的问题上作了相应的优化处理。在代码上不仅很短,但是性能方面也很好。
注意点:在使用IN操作符的时候,也可以使用NOT IN,那么就表示不在这个范围之内的。
例如:
1 SELECT * FROM emp WHERE empno NOT IN (7369,7566,7788,9999);
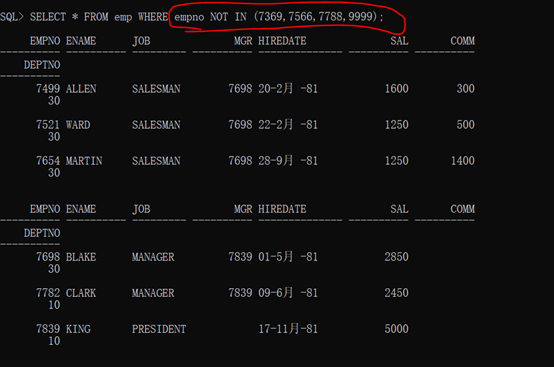
数据内容显示较多,就不一一地进行截图。
问题就从NOT IN开始,在使用NOT IN地时候,如果查找地数据范围之中包含有NULL值,那么就不会有任何的查询结果返回。IN操作符无此限制。
范例:观察IN操作符中出现NULL
语法格式:
1 SELECT * FROM emp WHERE empno IN (7369,7566,7788,NULL);
查询结果如下:
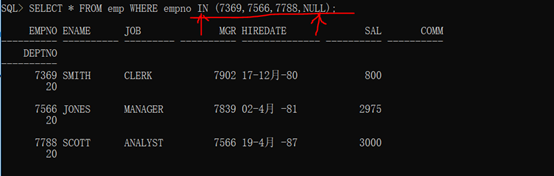
数据结果和之前9999不存在的结果是一样的。
范例:观察NOT IN 中出现NULL。
语法格式:
1 SELECT * FROM emp WHERE empno NOT IN (7369,7566,7788,NULL);
查询结果:无任何的数据返回。

模糊查询:LIKE(核心)
Like可以实现数据的模糊查询操作,如果要想使用LIKE则必须使用如下的两个匹配符号:
1.“_”:匹配任意的一位符号
2.“%”:匹配任意的符号(包含匹配1位,1位,多位)
范例:查询所有雇员中姓名以A字母开头的雇员信息。
分析:第一个字母A是固定的,后面的内容是随意。
语法格式:
1 SELECT * FROM emp WHERE ename LIKE ‘A%’;

范例:查询所有雇员姓名中第二个字母是A的所有雇员
分析:第一位可以是任意的字符,但是必须指出占一位,所以就使用“_”;后面的位置随意。
语法格式:
1 SELECT * FROM emp WHERE ename LIKE ‘_A%’;
结果如图所示:
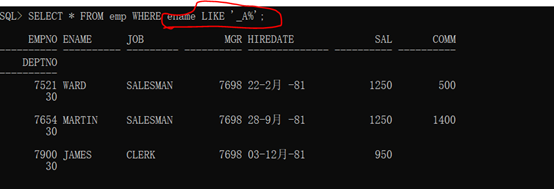
范例:查询雇员姓名中任意位置上存在有字母A的雇员信息
分析:开头、结尾、中间都可以。其他的位置随意。则使用“%A%”。
语法格式:
1 SELECT * FROM emp WHERE ename LIKE ‘%A%’;
查询结果如下:
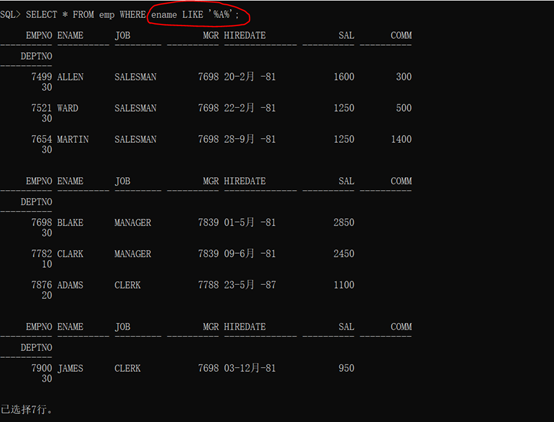
关于LIKE的两点说明:
1.如果在使用LIKE进行限定查询的时候,没有设置任何的关键字,那么就表示查询全部内容。
例如:
1 SELECT * FROM emp WHERE ename LIKE '%%';
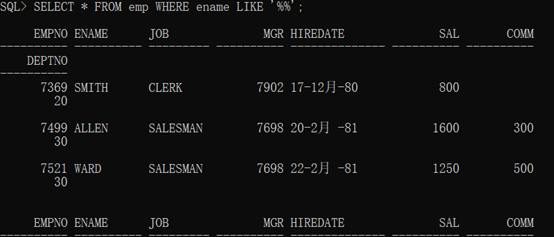
2.LIKE可以在任意的数据类型上使用(原生支持)。
语法格式:
1 SELECT * FROM emp WHERE ename LIKE '%A%' OR sal LIKE '%1%' OR hiredate LIKE '%81%';
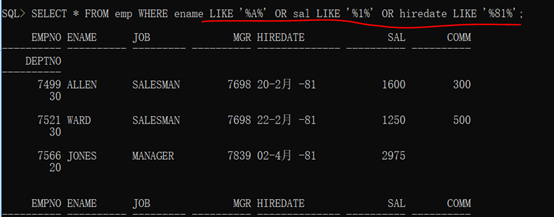
例如:
虽然所有的数据类型都是支持LIKE,但是往往会在字符串上使用。目前所可以见到的大部分的系统搜索引擎功能,都是通过此语句实现。但是不包含搜索引擎的实现。
查询排序 ORDER BY子句(重点部分)
所有的自然排序都是不可控的,所以往往都是用户自己来进行排序操作,那么这个时候就可以使用ORDER BY
语法格式:
【③选出所需要的数据列】SELECT [DISTINCT] * 列[别名],列[别名],列[别名]······
【①确定数据来源】FROM 表名称 [别名]
【②筛选数据行】[WHERE 限定条件] 此时的条件可以是多个语法结构。
【④数据排序】[ORDER BY 排序字段 [ASC|DESC] 可以设置多个]
既然ORDER BY 是在SELECT子句之后执行的,那么就意味着ORDER BY可以使用SELECT子句定义的别名。
对于字段的排序有两种形式:
升序:ASC,默认不写排序也是升序
降序:DESC,由高到低进行排序。
范例:按照工资由高到低排序。此时应该使用的是降序排序。
语法格式:
1 SELECT * FROM emp ORDER BY sal DESC;
查询结果:
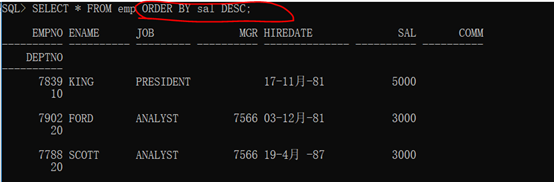
排序可以在任意数据类型上执行,包括字符串、日期都可以。
范例:按照雇佣日期由早到晚排序。
语法格式:
1 SELECT * FROM emp ORDER BY hiredate ASC;
查询结果:
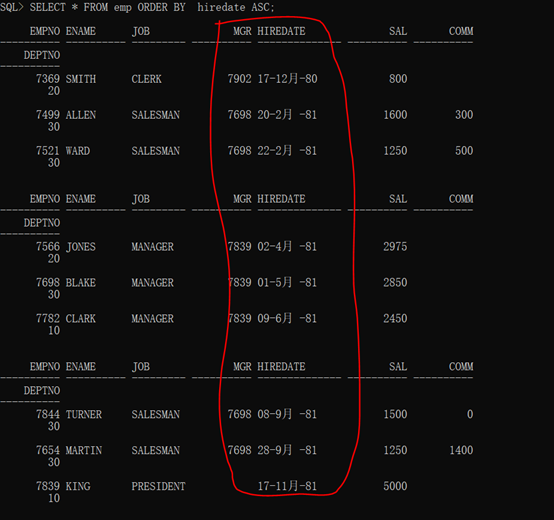
除了可以进行单一字符的排序,也可以进行字段的混合排序操作。指的是可以进行若干个字段的排序。
范例:按照工资由高到低排序,如果工资相同,则按照雇佣日期由早到晚排序。
语法格式:
1 SELECT * FROM emp ORDER BY sal DESC,hiredate ASC;
查询结果:
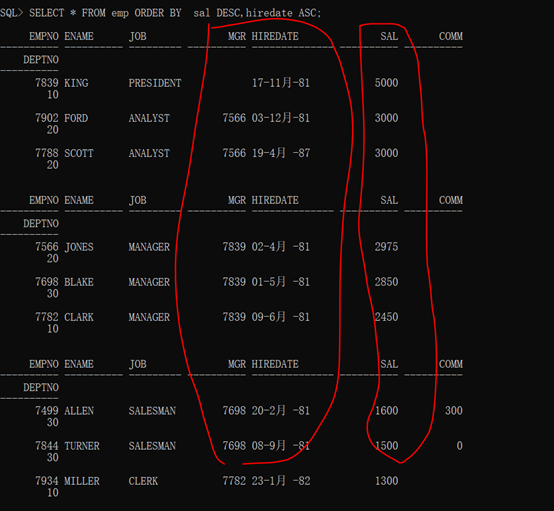
所有的排序操作都是在WHERE筛选之后进行的。
范例:查询出所有办事员的编号,职位,年薪,按照年薪由高到低排序。
语法格式:
1 SELECT empno,job,sal*12 income FROM emp WHERE job='CLERK' ORDER BY income ASC;
查询结果:
总结:
- 1. SELECT子句确定数据列
- 2. WHERE子句控制数据行
- 3. ORDER BY子句永远摆在最后去执行。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号